Generative Image Dynamics(动态图像生成)
机构:谷歌研究所
年份:2024 CVPR
项目地址页面:Generative Image Dynamics

摘要:论文提出了一种建立图像空间运动先验的方法。其核心思想是从真实视频中提取运动轨迹,并在傅里叶域中对这种长期、密集的运动进行建模,形成一种称为“光谱体(spectral volume)”的表示。给定一幅静态RGB图像,模型通过频率协调的扩散采样过程预测出光谱体,然后将其转换为运动纹理,进而生成一段平滑、循环的动画视频或实现交互式的动态模拟。该方法能够捕捉自然界中树木、花朵、蜡烛等物体在风中摇曳的振荡动态,并在图像动画和视频合成上展现出优异的效果。
论文在引言部分指出:
- 自然运动的普遍性:现实世界中即使看似静止的场景也存在微妙的运动(如风吹树摇、花瓣颤动等),而人类对这些运动的敏感性使得没有运动或运动不自然的图像容易显得诡异。
- 挑战与动机:尽管人类能够想象出合理的动态效果,但如何让计算模型学习并生成自然的场景运动一直是一个困难的问题。传统的视频生成方法往往在长时序一致性和物理合理性上存在不足。
- 方法创新:作者借鉴了傅里叶域表示和模态分析的思想,通过将像素轨迹的时间演化看作若干谐振分量的叠加,将运动转换到频率域中来建模,并利用扩散模型(特别是latent diffusion models, LDM)对这种低维的运动先验进行预测。
- 下游应用:利用所学运动先验,论文展示了如何将单张静态图像转换为无缝循环的视频,或在交互式动态模拟中,根据用户输入(如拖拽、释放等)产生逼真的物体动态响应。
2. 实现原理与实现流程
论文的整体系统分为两个主要模块:运动预测模块与基于图像的渲染模块。
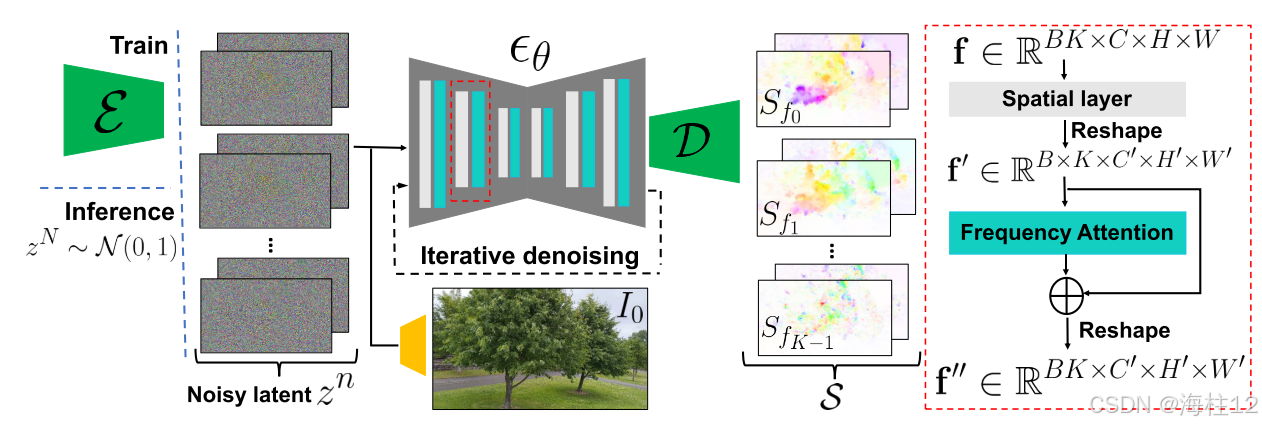
一、运动预测模块
-
运动表示:
- 将每个像素在时间上的运动轨迹表示为一个二维位移序列
。
- 采用傅里叶变换将这些时域轨迹转换为频域表示,即“光谱体”
。(公式2)
- 公式2推导过程

- 利用公式 (1) 表示前向映射:
表示利用位移场
将输入图像
重映射生成未来帧。
- 将每个像素在时间上的运动轨迹表示为一个二维位移序列
-
扩散模型预测:
- 使用latent diffusion model(LDM)作为骨干,对低维的光谱体进行预测。LDM包括一个变分自编码器(VAE)和基于U-Net的扩散网络。
- 模型通过迭代去噪过程,预测每个频率下的傅里叶系数。由于每个频率分量需用4个标量(分别对应x和y方向的实部和虚部)来描述,因此输出通道数为4K(K表示频率数量)。
- 为了提高各频率分量间的协调性,论文提出了频率协调去噪策略,即在传统的2D空间层之间插入注意力层,统一协调不同频率间的信息流。
-
频率自适应归一化:
- 由于不同频率下傅里叶系数的幅度差异很大(低频部分幅值较大,高频部分幅值较小),直接训练会使得高频系数接近于零。
- 论文提出一种自适应归一化方法:对每个频率
计算其95百分位的统计值
,并利用如下公式对系数进行归一化(公式 (4)):
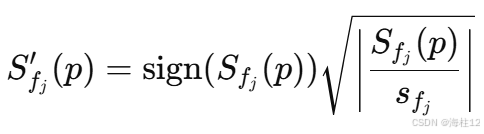
公式推导过程:

训练目标:
- 利用标准扩散模型的均方误差去噪损失进行训练(公式 (3)):
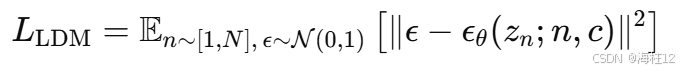
- 条件 c 即为输入的首帧
二、基于图像的渲染模块
- 运动纹理生成:
- 将预测得到的光谱体
通过逆傅里叶变换转换为时域的运动纹理
。
- 将预测得到的光谱体
- 图像重渲染:
- 采用基于神经网络的图像渲染方法,根据运动纹理
。
- 为了解决前向映射过程中可能出现的空洞问题,论文采用多尺度特征提取和softmax splatting策略,从而使得多个源像素映射到同一目标像素时能够融合成合理的结果。
- 采用基于神经网络的图像渲染方法,根据运动纹理
- 下游应用:
- 无缝循环视频:引入运动自指导(motion self-guidance)策略,在每一步去噪过程中附加一个引导项,确保视频开始与结束帧在像素位置及梯度上的连续性(公式 (5))。
- 交互式动态模拟:利用光谱体作为图像空间模态基,通过公式 (6) 表示:
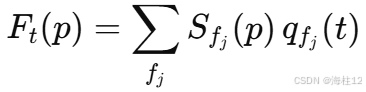
- 其中
表示各模态随时间变化的系数,通过显式欧拉方法求解一个质量-弹簧-阻尼系统的运动方程,从而模拟用户作用下的动态响应。
三、实验结果

结论:
我们提出了一种从单张静态图片中建立自然振荡动态模型的新方法。我们的图像空间运动先验使用频谱卷来表示,频谱卷是每像素运动轨迹的频率表示,我们发现它在使用扩散模型进行预测时效率高、效果好,而且我们是从真实世界的视频集合中学习的。我们使用频率协调的潜在扩散模型预测频谱量,并通过基于图像的渲染模块将其用于未来视频帧的动画制作。