2020年SCI1区TOP:自适应粒子群算法MPSO,深度解析+性能实测
目录
- 1.摘要
- 2.改进策略
- 3.结果展示
- 4.参考文献
- 5.代码获取

1.摘要
在专家系统中,复杂的优化问题通常具有非线性、非凸、多模态和不连续的特点。粒子群算法(PSO)作为一种高效且简单的优化算法,已广泛应用于解决这些实际问题。然而,如何避免早熟收敛并平衡PSO的全局探索能力和局部开发能力,仍然是一个待解决的挑战。因此,本文提出了一种自适应策略粒子群算法(MPSO),MPSO通过引入基于混沌的非线性惯性权重来平衡全局探索和局部开发能力,避免早熟收敛。MPSO采用了随机和主流学习策略,以及自适应位置更新策略和终止替换机制,从而增强了其解决复杂优化问题的能力。
2.改进策略
混沌惯性权重
在PSO中,惯性权重
w
w
w作为一个重要参数,能够根据不同环境动态调整粒子的行为,从而实现探索和开发之间的平衡。通常,惯性权重采用线性方法,但非线性惯性权重具有更强的拟合和模拟能力。混沌作为一种非线性映射,能够生成具有良好随机性和无序性的随机数,因此在进化计算领域得到了广泛应用,本文将Logistic混沌引入惯性权重,从而构建了非线性惯性权重:
r
(
t
+
1
)
=
4
r
(
t
)
(
1
−
r
(
t
)
)
,
r
(
0
)
=
r
a
n
d
r(t+1)=4r(t)(1-r(t)),r(0)=rand
r(t+1)=4r(t)(1−r(t)),r(0)=rand
ω
(
t
)
=
r
(
t
)
⋅
ω
m
i
n
+
(
ω
m
a
x
−
ω
m
i
n
)
⋅
t
T
m
a
x
\omega(t)=r(t)\cdot\omega_{min}+\frac{(\omega_{max}-\omega_{min})\cdot t}{T_{max}}
ω(t)=r(t)⋅ωmin+Tmax(ωmax−ωmin)⋅t
随机学习策略和主流学习策略
在PSO中,粒子通过个体最佳解
P
b
e
s
t
Pbest
Pbest和全局最佳解
G
b
e
s
t
Gbest
Gbest进行学习,更新其速度和位置。随机学习策略使粒子能够从种群中其他优秀个体中学习,从而增加粒子运动的多样性。在每次迭代中,随机选择种群中两个互不相同的个体最佳粒子,并将更优的个人最佳解作为候选个人最佳解
C
P
b
e
s
t
CPbest
CPbest,通过比较当前个体最佳解
P
b
e
s
t
i
Pbest_i
Pbesti与
C
P
b
e
s
t
CPbest
CPbest的适应度值,选择更优的解作为最终的随机个人最佳解
S
P
b
e
s
t
SPbest
SPbest。
C
P
b
e
s
t
(
t
)
=
a
r
g
m
i
n
{
f
i
t
(
P
b
e
s
t
a
(
t
)
)
,
f
i
t
(
P
b
e
s
t
b
(
t
)
)
}
,
a
≠
b
∈
{
1
,
2
,
⋯
,
N
}
\begin{array} {c}CPbest(t)=argmin\{fit(Pbest_a(t)),fit(Pbest_b(t))\}, \\ a\neq b\in\{1,2,\cdots,N\} \end{array}
CPbest(t)=argmin{fit(Pbesta(t)),fit(Pbestb(t))},a=b∈{1,2,⋯,N}
S P b e s t i ( t ) = { C P b e s t ( t ) if f i t ( C P b e s t ) < f i t ( P b e s t i ) P b e s t i ( t ) otherwise \begin{equation} SPbest_i(t) = \begin{cases} CPbest(t) & \text{if } fit(CPbest) < fit(Pbest_i) \\ Pbest_i(t) & \text{otherwise} \end{cases} \end{equation} SPbesti(t)={CPbest(t)Pbesti(t)if fit(CPbest)<fit(Pbesti)otherwise
本文引入了一个全局粒子
M
b
e
s
t
Mbest
Mbest,它被定义为所有粒子个体最佳位置的均值:
M
b
e
s
t
(
t
)
=
m
e
a
n
{
P
b
e
s
t
1
,
P
b
e
s
t
2
,
…
,
P
b
e
s
t
N
}
Mbest(t)=mean\{Pbest_1,Pbest_2,\ldots,Pbest_N\}
Mbest(t)=mean{Pbest1,Pbest2,…,PbestN}
速度更新:
V
i
(
t
+
1
)
=
ω
(
t
)
V
i
(
t
)
+
r
1
c
1
⊗
(
S
P
b
e
s
t
i
(
t
)
−
X
i
(
t
)
)
+
r
2
c
2
⊗
(
M
b
e
s
t
(
t
)
−
X
i
(
t
)
)
V_i(t+1)=\omega(t)V_i(t)+r_1c_1\otimes(SPbest_i(t)-X_i(t))+r_{2}c_{2}\otimes(Mbest(t)-X_{i}(t))
Vi(t+1)=ω(t)Vi(t)+r1c1⊗(SPbesti(t)−Xi(t))+r2c2⊗(Mbest(t)−Xi(t))
自适应位置更新策略
为了更好地平衡局部开发和全局探索,本文提出了一种自适应位置更新机制,粒子可以根据相应的条件选择不同的位置更新策略,从而更好地平衡探索与开发:
p
i
=
e
x
p
(
f
i
t
(
X
i
(
t
)
)
)
e
x
p
(
1
N
∑
i
=
1
N
f
i
t
(
X
i
(
t
)
)
)
p_i=\frac{exp(fit(X_i(t)))}{exp\left(\frac{1}{N}\sum_{i=1}^Nfit(X_i(t))\right)}
pi=exp(N1∑i=1Nfit(Xi(t)))exp(fit(Xi(t)))
X
i
(
t
+
1
)
=
{
ω
(
t
)
X
i
(
t
)
+
(
1
−
ω
(
t
)
)
V
i
(
t
+
1
)
+
G
b
e
s
t
(
t
)
p
i
>
r
a
n
d
X
i
(
t
)
+
V
i
(
t
+
1
)
o
t
h
e
r
w
i
s
e
X_i(t+1)= \begin{cases} \omega(t)X_i(t)+(1-\omega(t))V_i(t+1)+Gbest(t) & \quad p_i>rand \\ X_i(t)+V_i(t+1) & \quad otherwise & \end{cases}
Xi(t+1)={ω(t)Xi(t)+(1−ω(t))Vi(t+1)+Gbest(t)Xi(t)+Vi(t+1)pi>randotherwise
终止替换机制
为了增强种群的多样性并提高MPSO在复杂问题上的表现,引入了终止更新机制,该机制灵感来源于自然界中的优胜劣汰规则,在每次迭代中,全局最差粒子
G
w
o
r
s
t
Gworst
Gworst将被替换:
G
w
o
r
s
t
(
t
)
=
a
r
g
m
a
x
{
f
i
t
(
P
b
e
s
t
1
(
t
)
)
,
f
i
t
(
P
b
e
s
t
2
(
t
)
)
,
⋯
,
f
i
t
(
P
b
e
s
t
N
(
t
)
)
}
Gworst(t)=argmax\{fit(Pbest_1(t)),fit(Pbest_2(t)),\cdots,fit(Pbest_N(t))\}
Gworst(t)=argmax{fit(Pbest1(t)),fit(Pbest2(t)),⋯,fit(PbestN(t))}
N
b
e
s
t
(
t
)
=
G
b
e
s
t
(
t
)
+
r
a
n
d
⋅
(
P
b
e
s
t
j
(
t
)
−
P
b
e
s
t
k
(
t
)
)
,
j
≠
k
∈
{
1
,
2
,
⋯
,
N
}
\begin{aligned} Nbest(t) & =Gbest(t)+rand\cdot\left(Pbest_j(t)-Pbest_k(t)\right), \\ j & \neq k\in\{1,2,\cdots,N\} \end{aligned}
Nbest(t)j=Gbest(t)+rand⋅(Pbestj(t)−Pbestk(t)),=k∈{1,2,⋯,N}
$$
\begin{equation}
Gworst(t) =
\begin{cases}
Nbest(t) & \text{if } fit(Nbest(t)) < fit(Gworst(t)) \
Gworst(t) & \text{otherwise}
\end{cases}
\end{equation}
$$
伪代码

3.结果展示
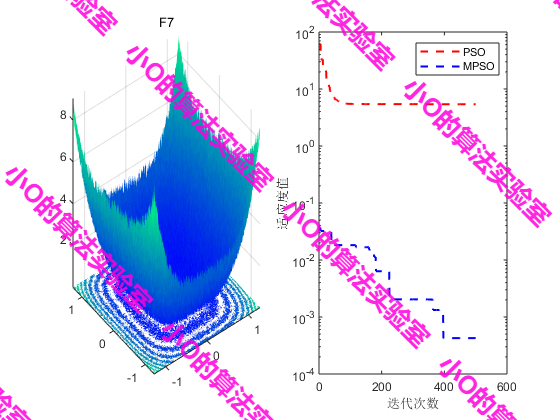
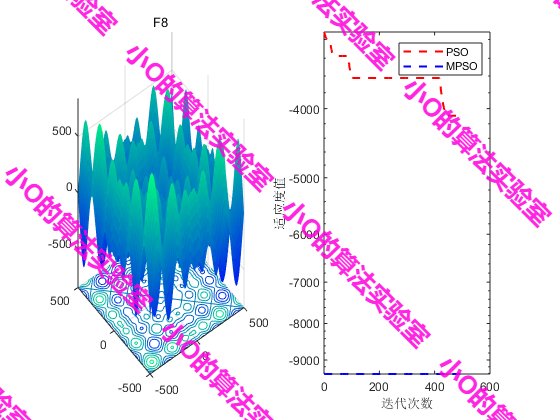
4.参考文献
[1] Liu H, Zhang X W, Tu L P. A modified particle swarm optimization using adaptive strategy[J]. Expert systems with applications, 2020, 152: 113353.