Restormer: Efficient Transformer for High-Resolution Image Restoration
Abstract
由于卷积神经网络(CNN)在从大规模数据中学习可概括的图像先验方面表现良好,这些模型已被广泛应用于图像恢复和相关任务。最近,另一类神经架构Transformers在自然语言和高级视觉任务上表现出显着的性能提升。虽然Transformer模型减轻了CNN的缺点(即,有限的感受域和对输入内容的不适应性),其计算复杂度随着空间分辨率的二次增长,因此使得其不适于应用于大多数涉及高分辨率图像的图像恢复任务。在这项工作中,我们提出了一个有效的Transformer模型,通过在构建模块(多头注意力和前馈网络)中进行几个关键设计,使其可以捕获长距离像素交互,同时仍然适用于大图像。我们的模型名为Restoration Transformer(Restormer),在多个图像恢复任务上实现了最先进的结果,包括图像去噪,单图像运动去模糊,散焦去模糊(单图像和双像素数据)和图像去噪(高斯灰度/彩色去噪和真实的图像去噪)。
Introduction

自我注意力SA:是Transformer模型[34,77]中的核心组件,但具有独特的实现,即,该算法针对并行化和有效表示学习进行了优化。transformer已经在自然语言任务[10,19,49,62]和高级视觉问题[11,17,76,78]方面表现出了最先进的性能。虽然SA在捕获长距离像素交互方面非常有效,但其复杂度随着空间分辨率的二次增长,因此使得其不适合应用于高分辨率图像(图像恢复中的常见情况)。
Method
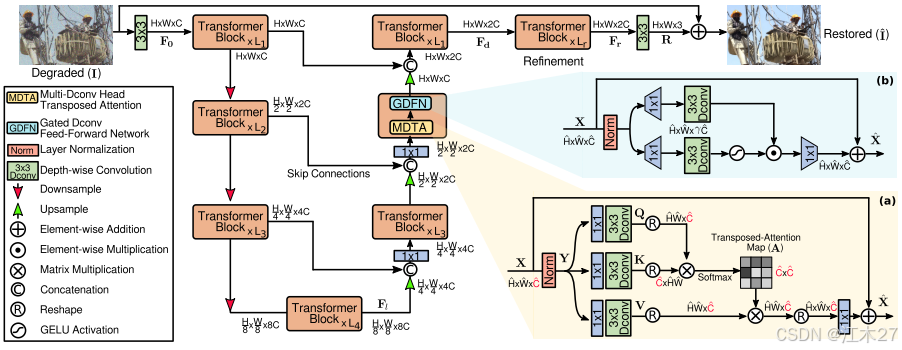
- Pipeline
- 给定退化图像I ∈ RH×W×3,Restormer首先应用卷积来获得低层特征嵌入F0 ∈RH×W×C;
- 接着,这些浅层特征F0通过4级对称编码器-解码器,并被变换为深层特征Fd ∈ RH×W×2C。
- 编码器分级地减小空间大小,同时扩展信道容量。该解码器以低分辨率特征Fl ∈ RH/8 × W/8 ×8C为输入,逐步恢复高分辨率特征。
- 级联操作之后是1×1卷积,以减少所有级别的通道(减少一半),除了顶部的通道。在第一级,我们让Transformer块聚合编码器的低级图像特征和解码器的高级特征。该方法有利于保留恢复图像中的结构和纹理细节。接下来,在以高空间分辨率操作的细化阶段中进一步丰富深层特征Fd。
- 最后,对细化后的特征进行卷积处理,得到残差图像R ∈ RH×W×3,并将其与退化图像相加,得到复原图像:I = I +R。接下来,我们介绍Transformer块的模块。
Multi-Dconv Head Transposed Attention
- 提出MDTA:让SA可以在高分辨率图像上使用,其复杂度是线性的,通常情况随分辨率增长复杂度二次增长
- 关键要素是跨渠道而非空间维度应用SA,即:以生成隐式编码全局上下文的注意力图。
- 作为MDTA的另一个重要组成部分,我们在计算特征协方差以产生全局注意力图之前,引入了深度卷积来强调局部上下文。
- 它是通过应用1×1卷积来聚合像素方向的跨通道上下文,然后应用3×3深度卷积来编码通道方向的空间上下文,得到Q=WQ d WQ p Y,K=WK d WK p Y和V=WV d WV p Y。其中W(·)p是1×1的逐点卷积,W(·)d是3×3的逐深度卷积。我们在网络中使用无偏置卷积层。
- 接下来,我们对查询和关键词投射进行重新view,使得它们的点积交互生成大小为R C× C的转置注意力图A,而不是大小为R H W× H W的巨大的常规注意力图[17,77]。
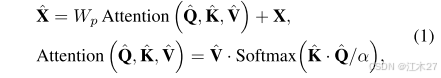
其中 Q ∈ R H W× C; K ∈ R C× H W; V ∈ R H W× C矩阵是从原始大小R H × W× C整形张量后获得的。这里,α是一个可学习的缩放参数,用于在应用softmax函数之前控制K和Q的点积的大小。与传统的多头SA [17]类似,我们将通道的数量划分为“头”,并行学习单独的注意力图。
Gated-Dconv Feed-Forward Network
前馈网络的作用:用于对每个 token 进行特征变换,通常位于注意力层(Self-Attention)之后;
- 自注意力(Self-Attention)负责长距离依赖关系。
- 前馈网络(FFN)在每个 token 位置上独立应用,用于特征变换和增强表达能力。
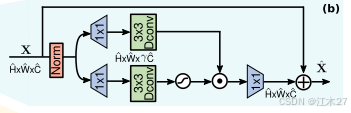
- Restormer 论文使用了一种改进的前馈网络 GDFN引入门控机制(Gating Mechanism):增强重要特征,抑制无关特征使用深度可分离卷积(Depthwise Convolution):结合局部和全局信息,提高效率
-
它使用两个1×1卷积,一个用于扩展特征通道(通常以因子γ=4),第二个用于将通道缩减回原始输入维度。
-
在隐藏层中应用非线性。在这项工作中,我们提出了两个基本的修改FN,以改善表示学习:(1)门控机制;(2)依赖卷积。
-
选通机制被公式化为线性转换层的两个平行路径的元件式乘积,其中一个路径由GELU非线性激活。
-
与MDTA一样,我们也在GDFN中加入了深度卷积,以编码来自空间相邻像素位置的信息,这对于学习局部图像结构以进行有效恢复是有用的。
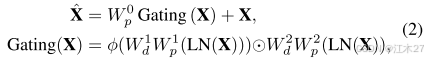
其中,λ表示逐元素乘法,φ表示GELU非线性,LN是层归一化[9]。 -
总的来说,GDFN控制着通过我们的管道中各个层次的信息流,从而允许每个层次关注与其他层次互补的细节。(个人理解所谓的门控机制即激活函数进行筛选,这里采用的GELU)
-
也就是说,与MDTA相比,GDFN提供了一个独特的角色(专注于使用上下文信息丰富特性)。由于与常规FN [17]相比,所提出的GDFN执行更多的操作,因此我们降低了扩展比γ,以便具有相似的参数和计算负担。
扩展比:扩展通道数,这种扩展是为了增强非线性变换能力,本文意思是扩展通道数不会像通常transformer那样扩展很多倍例如256→1024
Progressive Learning
基于CNN的恢复模型通常在固定大小的图像块上训练。然而,在小的裁剪块上训练Transformer模型可能不会对全局图像统计进行编码,从而在测试时在全分辨率图像上提供次优性能。为此,我们执行渐进式学习,其中在早期阶段在较小的图像块上训练网络,而在后期训练阶段在逐渐较大的块上训练网络。通过渐进式学习在混合大小的补丁上训练的模型在测试时显示出增强的性能,其中图像可以具有不同的分辨率(图像恢复中的常见情况)。渐进式学习策略以与课程学习过程类似的方式工作,其中网络从较简单的任务开始,并逐渐移动到学习较复杂的任务(其中需要保留精细图像结构/纹理)。由于大补丁的训练需要较长的时间,因此我们会随着补丁大小的增加而减少批处理大小,以保持与固定补丁训练相似的每个优化步骤的时间。
Experiments
