模型训练和推理
- 训练时需要梯度,推理时不需要
- 怎么理解“梯度”?
- 计算图以及前向后向传播
训练时需要梯度,推理时不需要
| 阶段 | 是否计算梯度 | 是否反向传播 | 是否更新参数 | 用例 | 写法 |
|---|---|---|---|---|---|
| 训练 | ✅ | ✅ | ✅ | loss 训练 | 默认即可,requires_grad=True |
| 推理 | ❌ | ❌ | ❌ | 采样、预测、部署 | 用 @torch.inference_mode() 或 with torch.no_grad() |
-
训练阶段必须开启梯度计算:
- 要 计算 loss(损失函数)
- 然后通过
loss.backward()做 反向传播(backpropagation) - 更新模型参数(
optimizer.step())
-
推理阶段(inference)不需要梯度计算,关闭它可以节省内存、提高速度:
- 只需要执行
forward,得到模型输出(如预测轨迹、采样结果) - 不再需要
loss,也不需要更新模型参数
- 只需要执行
@torch.inference_mode()是 PyTorch 中用于 推理模式(inference mode) 的一个装饰器,主要功能是:临时关闭梯度计算(比torch.no_grad()更高效),用于模型推理阶段,加快速度、降低显存占用。
它和@torch.no_grad()类似,但更彻底:
torch.no_grad()禁用梯度计算(不会构建计算图)torch.inference_mode()也禁用梯度计算,但还能避免某些内部缓冲区的额外开销,性能更好@torch.inference_mode() def predict(model, inputs): return model(inputs)
- PyTorch 会在每次
forward过程中,构建一棵 计算图(computation graph),记录每一步的操作,方便后面loss.backward()自动求导。
- 一旦调用
loss.backward(),它会从最后一层反推回去,自动算出所有参数的梯度。- 而
@torch.inference_mode()或with torch.no_grad()会告诉 PyTorch:我只是forward看看结果,不要帮我建计算图了!
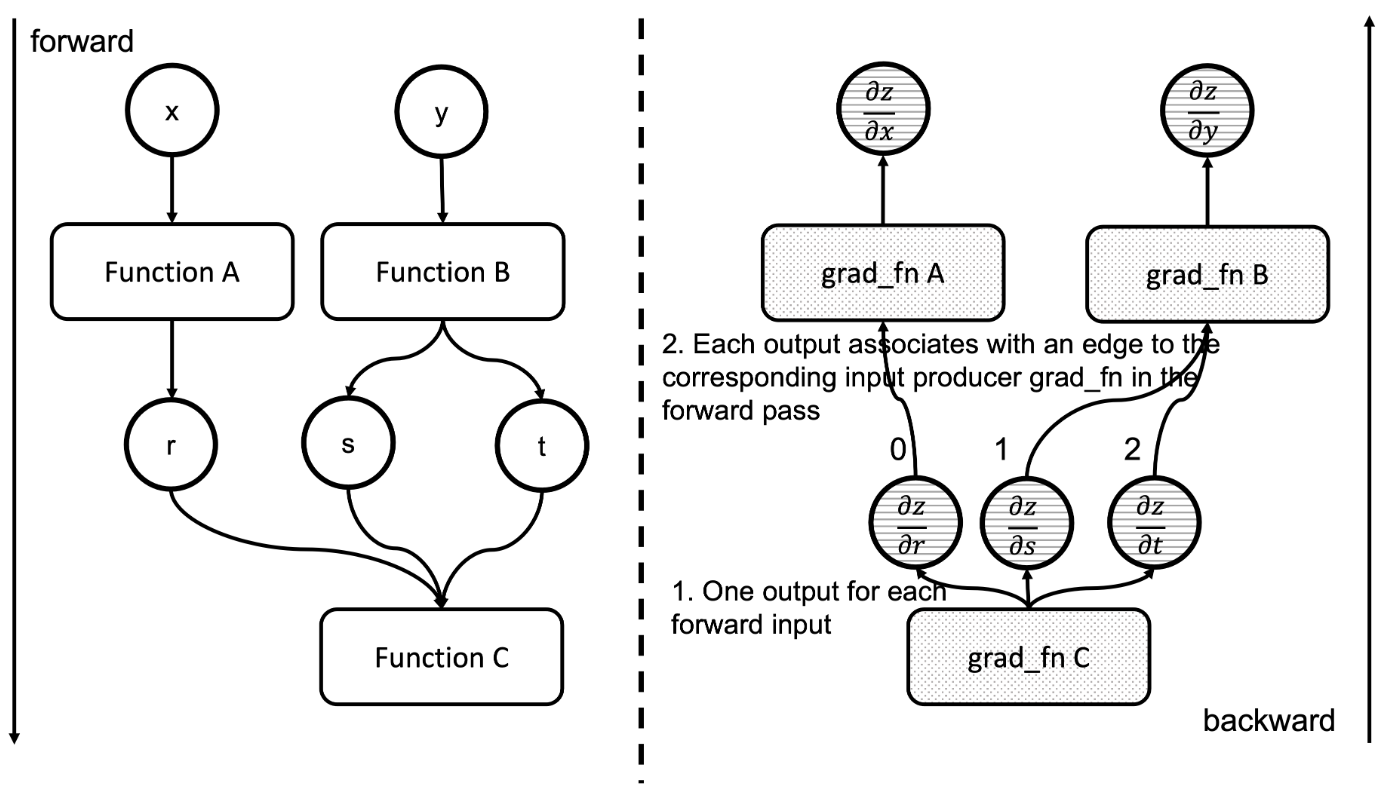
扩展:How Computational Graphs are Executed in PyTorch
怎么理解“梯度”?
可以用一个简单直觉的比喻,把模型看成一个“函数机器”:它输入是数据(如图片、状态),输出是预测结果(如轨迹、控制信号)。
梯度 = 模型输出对参数的敏感程度(变化率)
比如:模型预测错了,就会计算:
loss = 模型输出 - 真实值
此时我们想知道:
如果我改变模型的参数,loss 会变大还是变小?
这就需要计算 loss 对模型参数的导数 —— 这就是梯度。
举个例子:
loss = (y_pred - y_true)**2
我们希望让 loss 趋近于 0。那我们就问:
loss对模型参数 θ的梯度是多少?- 梯度大 -> 表示参数的变化对
loss影响大 - 梯度小 -> 表示参数已经趋于最优了
然后 用这些梯度反过来更新模型:
θ_new = θ_old - learning_rate * gradient
这就是 “梯度下降” 的核心思想。
用 PyTorch 来举个最简单的例子:
import torch
# 模拟一个参数 θ
theta = torch.tensor([2.0], requires_grad=True)
# 输入数据
x = torch.tensor([3.0])
# Forward:计算 y = theta * x
y = theta * x
# 假设目标输出是 y_true
y_true = torch.tensor([10.0])
# 计算 loss
loss = (y - y_true) ** 2
# 反向传播
loss.backward()
# 查看梯度
print("梯度:", theta.grad) # 显示 ∂loss/∂theta # 梯度: tensor([-48.])
说明此时:
- 当前
θ是 2 时,loss对θ的导数是 -48,代表 “要往更大的方向调θ”。
计算图以及前向后向传播

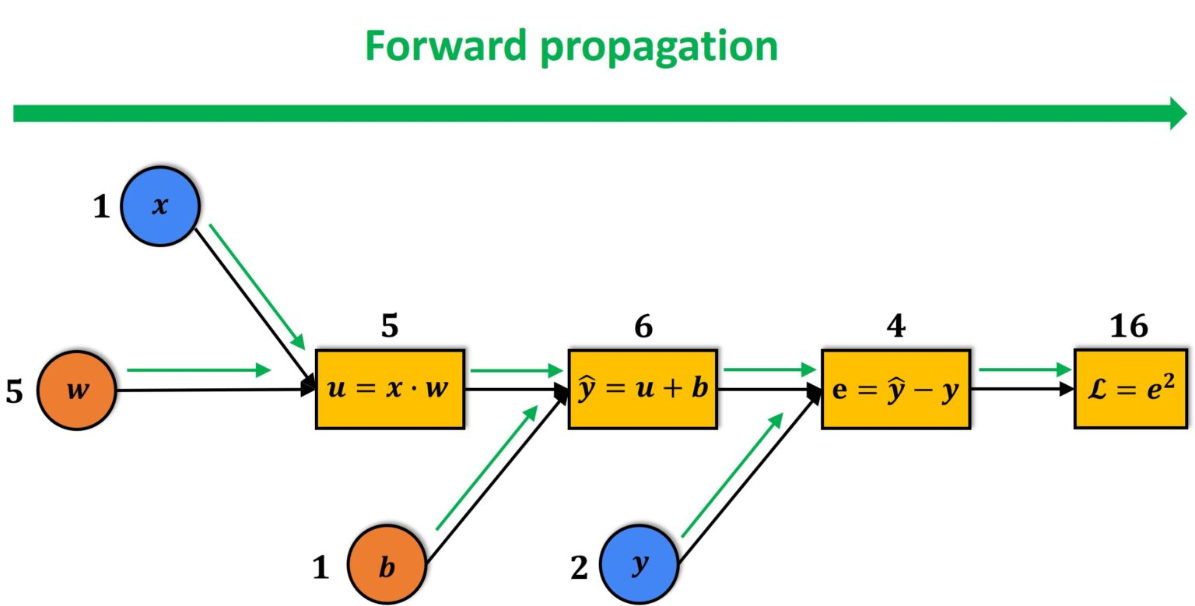

扩展:PyTorch – Computational graph and Autograd with Pytorch