JavaEE ——多线程的线程安全集合类
线程安全的集合类
原来的集合类,大部分都不是线程安全的.
Vector, Stack, HashTable, 是线程安全的(不建议用),其他的集合类不是线程安全的.
多线程环境使用ArrayList
1. 自己使用同步机制(synchronized或者ReentrantLock)
分析清楚一定,要把那些代码打包到一起,成为一个‘’
2.Collections.synchronizedList(new ArrayList);
. synchronizedList 是标准库提供的⼀个基于synchronized及逆行线程同步的List.synchronizedList 的关键操作上都带有synchronized
迭代操作(如 for-each、iterator)本身不自动同步
List<String> syncList = Collections.synchronizedList(new ArrayList<>());
// 迭代时手动同步
synchronized (syncList) {for (String s : syncList) {// 迭代操作}
}3. 使用CopyOnWriteArrayList CopyOnWrite容器即写时复制的容器。
• 当我们往⼀个容器添加元素的时候,不直接往当前容器添加,而是先将当前容器进行Copy,复制 出⼀个新的容器,然后新的容器里添加元素,
• 添加完元素之后,再将原容器的引用指向新的容器。
这样做的好处是我们可以对CopyOnWrite容器进行并发的读,而不需要加锁,因为当前容器不会添 加任何元素。 所以CopyOnWrite容器也是⼀种读写分离的思想,读和写不同的容器。
优点: 在读多写少的场景下,性能很高,不需要加锁竞争.
缺点:
1. 占用内存较多.
2. 新写的数据不能被第⼀时间读取到
多线程读取~~一旦某个线程进行写操作,比如修改 1 -> 100复制过程中,如果其他线程在读,就直接读取旧版本的数据虽然复制过程不是原子的 (消耗一定的时间)
由于提供了旧版本的数据,不影响其他线程读取新版本数组复制完毕之后,直接进行引用的修改.引用的赋值是 "原子"
专为读多写少的场景设计,具有以下特点:
核心原理
-
写操作时复制:
- 内部维护一个
volatile修饰的数组(array),保证读操作的可见性。 - 当执行 写操作(如
add、set、remove)时,不直接修改原数组,而是先复制一份新数组,在新数组上完成修改,最后将原数组的引用指向新数组。 - 伪代码逻辑:
- 内部维护一个
public boolean add(E e) {final ReentrantLock lock = this.lock;lock.lock(); // 写操作加锁,保证并发写时的线程安全try {Object[] elements = getArray();int len = elements.length;// 复制原数组到新数组(长度+1)Object[] newElements = Arrays.copyOf(elements, len + 1);newElements[len] = e; // 新数组添加元素setArray(newElements); // 原数组引用指向新数组return true;} finally {lock.unlock();}
}-
读操作无锁:
- 读操作(如
get、iterator)直接访问当前数组,无需加锁,因此效率极高。 - 迭代器(
Iterator)是基于快照的,迭代过程中即使原数组被修改,迭代器也不会抛出ConcurrentModificationException(因为它遍历的是修改前的旧数组)。
- 读操作(如
核心特性
- 线程安全:写操作通过独占锁(
ReentrantLock)保证原子性,读操作无锁且通过volatile保证可见性。 - 读写分离:读操作不阻塞写操作,写操作也不阻塞读操作(读的是旧数据)。
- 最终一致性:写操作完成后,新的读操作才能看到最新数据,适合对实时性要求不高的场景。
适用场景
- 读多写少的并发场景(如缓存、配置列表):读操作频繁且性能要求高,写操作很少(因为写操作需要复制数组,成本较高)。
- 不需要实时一致性的场景:因为读操作可能读取到旧数据(写操作未完成时)。
局限性
- 内存开销:写操作时会复制整个数组,若数组容量大,可能导致内存占用翻倍,甚至触发 GC。
- 写操作性能差:复制数组和加锁会导致写操作(
add、remove等)效率低,不适合写频繁的场景。 - 迭代器不可修改:迭代器不支持
remove、add等修改操作,否则会抛出UnsupportedOperationException。
应用场景:
配置文件在服务器中的加载与更新机制,可以从以下几个维度整理思路:
1. 配置的存储形式
配置被读取到服务器内存后,以 ** 数组或哈希(类似键值对结构)** 的形式存储,供服务器代码中的其他逻辑读取(且这些逻辑仅读不修改)。
2. 配置的更新流程
- 修改触发:程序员手动修改配置文件后,手动触发
reload功能。 - 新配置加载:服务器会创建新的数组 / 哈希结构,加载新的配置内容。
- 切换生效:新配置加载完毕后,直接用新配置替代旧配置,完成更新。
多线程环境使用队列
1. ArrayBlockingQueue
基于数组实现阻塞队列实现
2. LinkedBlockingQueue
基于链表实现的阻塞队列
3. PriorityBlockingQueue
基于堆实现的带优先级的阻塞队列
4. TransferQueue 最多只包含⼀个元素的阻塞队列
多线程环境使用哈希表
HashMap本身不是线程安全的. 在多线程环境下使用哈希表可以使用
• Hashtable
• ConcurrentHashMap
1) Hashtable
Java 任意一个对象都可以作为 锁对象.在这个逻辑中不需要额外创建这么多对象作为锁直接使用每个链表的头结点作为 synchronized 的锁对象
只是简单的把关键方法加上了synchronized关键字.
这相当于直接针对Hashtable对象本身加锁.
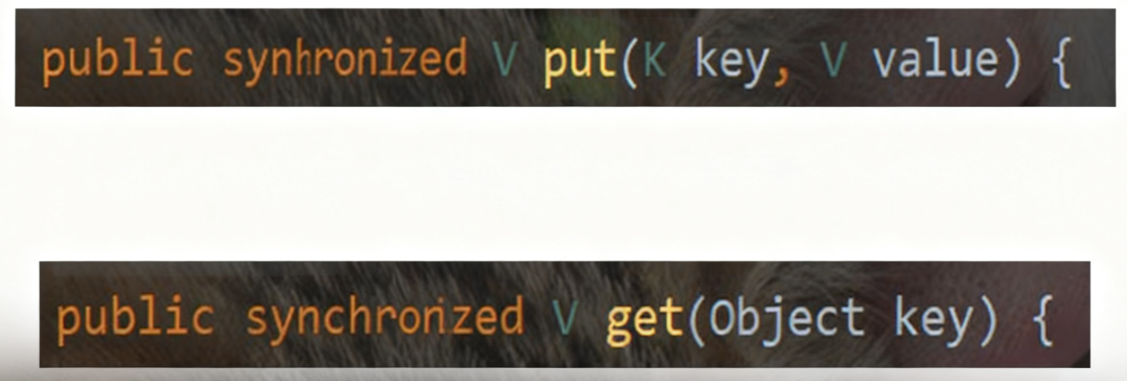
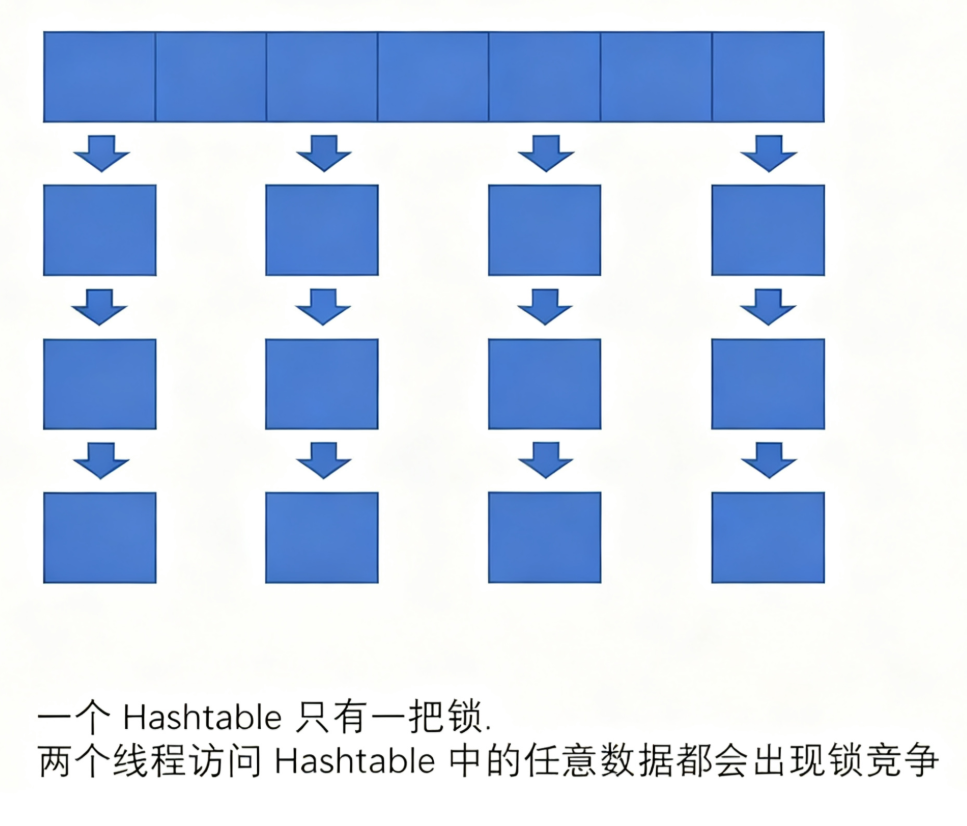
• 如果多线程访问同一个Hashtable就会直接造成锁冲突.
• size属性也是通过synchronized来控制同步,也是比较慢的
• ⼀旦触发扩容,就由该线程完成整个扩容过程.这个过程会涉及到大量的元素拷贝,效率会非常低.
2) ConcurrentHashMap
Java 任意一个对象都可以作为 锁对象.在这个逻辑中不需要额外创建这么多对象作为锁直接使用每个链表的头结点作为 synchronized 的锁对象
相比于Hashtable做出了⼀系列的改进和优化.以Java1.8为例
• 读操作没有加锁(但是使用了volatile保证从内存读取结果),只对写操作进行加锁.加锁的方式仍然 是是用synchronized,但是不是锁整个对象,而是"锁桶"(用每个链表的头结点作为锁对象),大大降低了锁冲突的概率.
• 充分利用CAS特性.比如size属性通过CAS来更新.避免出现重量级锁的情况.
• 优化了扩容方式:化整为零
- 发现需要扩容的线程,只需要创建⼀个新的数组,同时只搬几个元素过去.
- 扩容期间,新老数组同时存在.
- 后续每个来操作ConcurrentHashMap的线程,都会参与搬家的过程.每个操作负责搬运一小部分元素
- 搬完最后⼀个元素再把老数组删掉.
- 这个期间,插入只往新数组加.
- 这个期间,查找需要同时查新数组和老数组

参考资料:https://blog.csdn.net/u010723709/article/details/48007881
相关面试题
1. ConcurrentHashMap的读是否要加锁,为什么?
读操作没有加锁.目的是为了进⼀步降低锁冲突的概率.为了保证读到刚修改的数据,搭配了volatile 关键字.
2. 介绍下ConcurrentHashMap的锁分段技术?
这个是Java1.7中采取的技术.Java1.8中已经不再使用了.简单的说就是把若干个哈希桶分成⼀个 "段"(Segment),针对每个段分别加锁. 目的也是为了降低锁竞争的概率.当两个线程访问的数据恰好在同⼀个段上的时候,才触发锁竞争.
3. ConcurrentHashMap在jdk1.8做了哪些优化?
取消了分段锁,直接给每个哈希桶(每个链表)分配了⼀个锁(就是以每个链表的头结点对象作为锁对 象). 将原来数组+链表的实现方式改进成数组+链表/红黑树的方式.当链表较长的时候(大于等于8个 元素)就转换成红黑树.
4. Hashtable和HashMap、ConcurrentHashMap之间的区别?
HashMap:线程不安全.key允许为null
Hashtable: 线程安全.使用synchronized锁Hashtable对象,效率较低.key不允许为null. ConcurrentHashMap: 线程安全.使使用synchronized锁每个链表头结点,锁冲突概率低,充分利用 CAS机制.优化了扩容方式不允许为null
死锁
死锁是什么?
死锁是这样⼀种情形:多个线程同时被阻塞,它们中的⼀个或者全部都在等待某个资源被释放。由于 线程被无限期地阻塞,因此程序不可能正常终止。
举个例子理解死锁 滑稽老哥和女神⼀起去饺子馆吃饺子在.吃饺子需要酱油和醋.
滑稽老哥抄起了酱油瓶,女神抄起了醋瓶.
滑稽:你先把醋瓶给我,我⽤完了就把酱油瓶给你.
女神你先把酱油瓶给我,我⽤完了就把醋瓶给你.
如果这俩人彼此之间互不相让,就构成了死锁.
酱油和醋相当于是两把锁,这两个⼈就是两个线程.
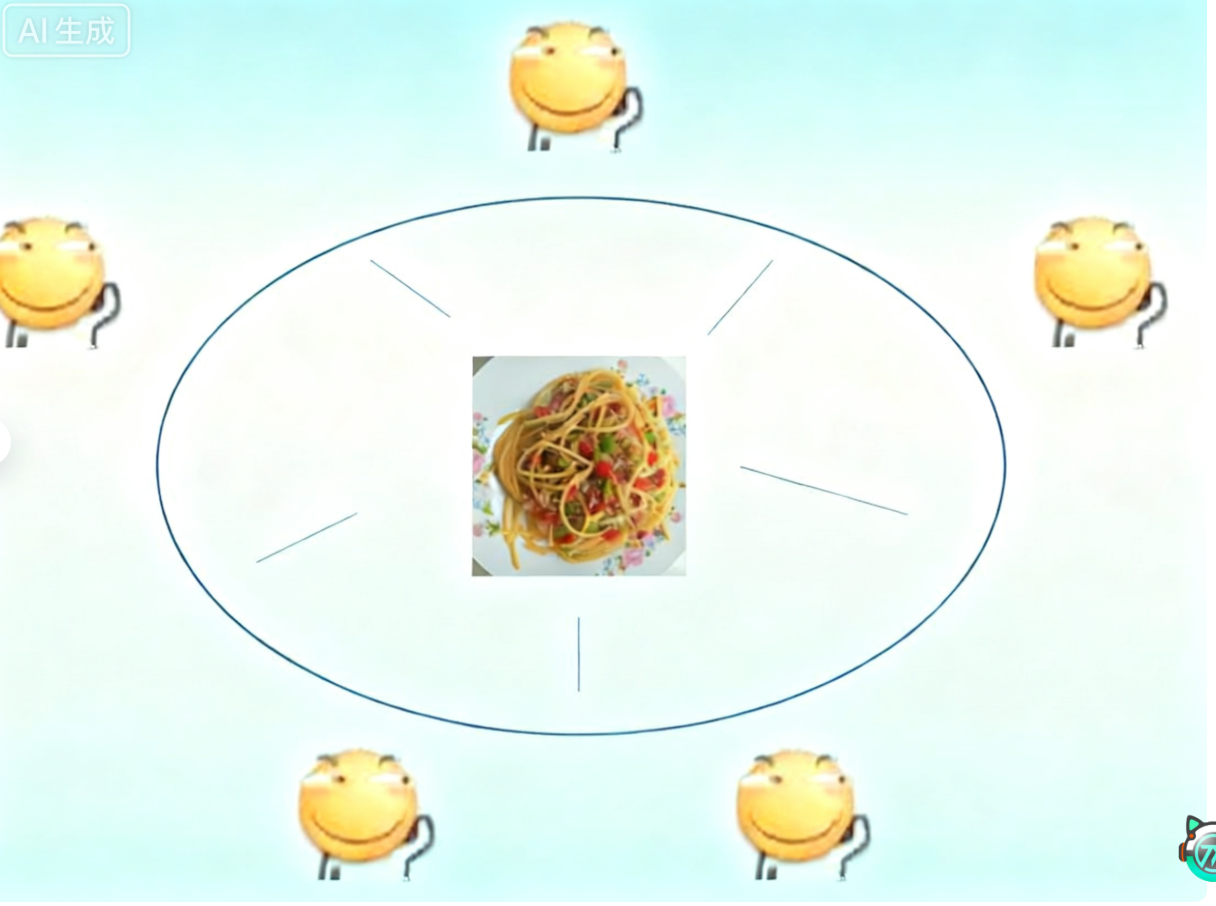
为了进⼀步阐述死锁的形成,很多资料上也会谈论到"哲学家就餐问题".
• 有个桌子,围着⼀圈哲♂家,桌子中间放着⼀盘意大利面.每个哲学家两两之间,放着⼀根筷子
• 每个哲♂家只做两件事:思考人生或者吃面条.思考人生的时候就会放下筷子.吃面条就会拿起左 右两边的筷子(先拿起左边,再拿起右边)
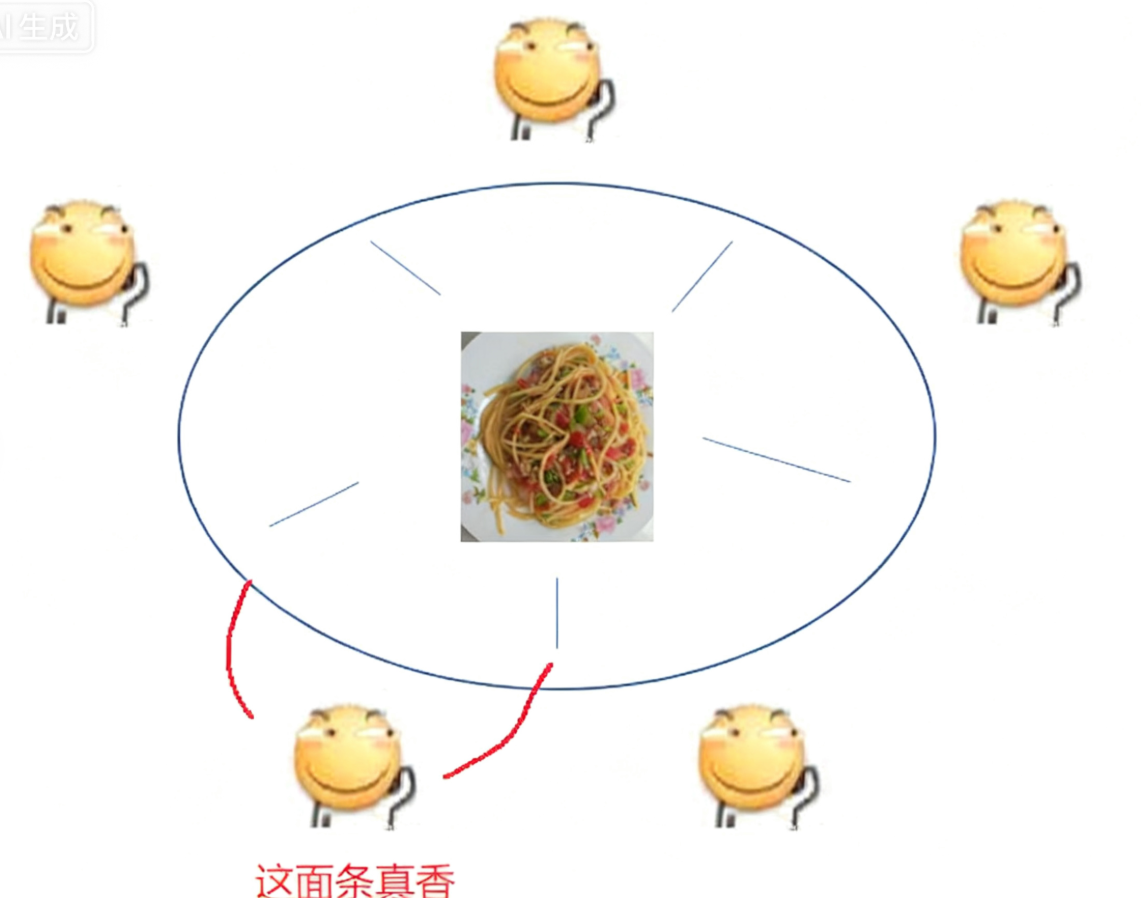
• 如果哲♂家发现筷子拿不起来了(被别人占用了),就会阻塞等待
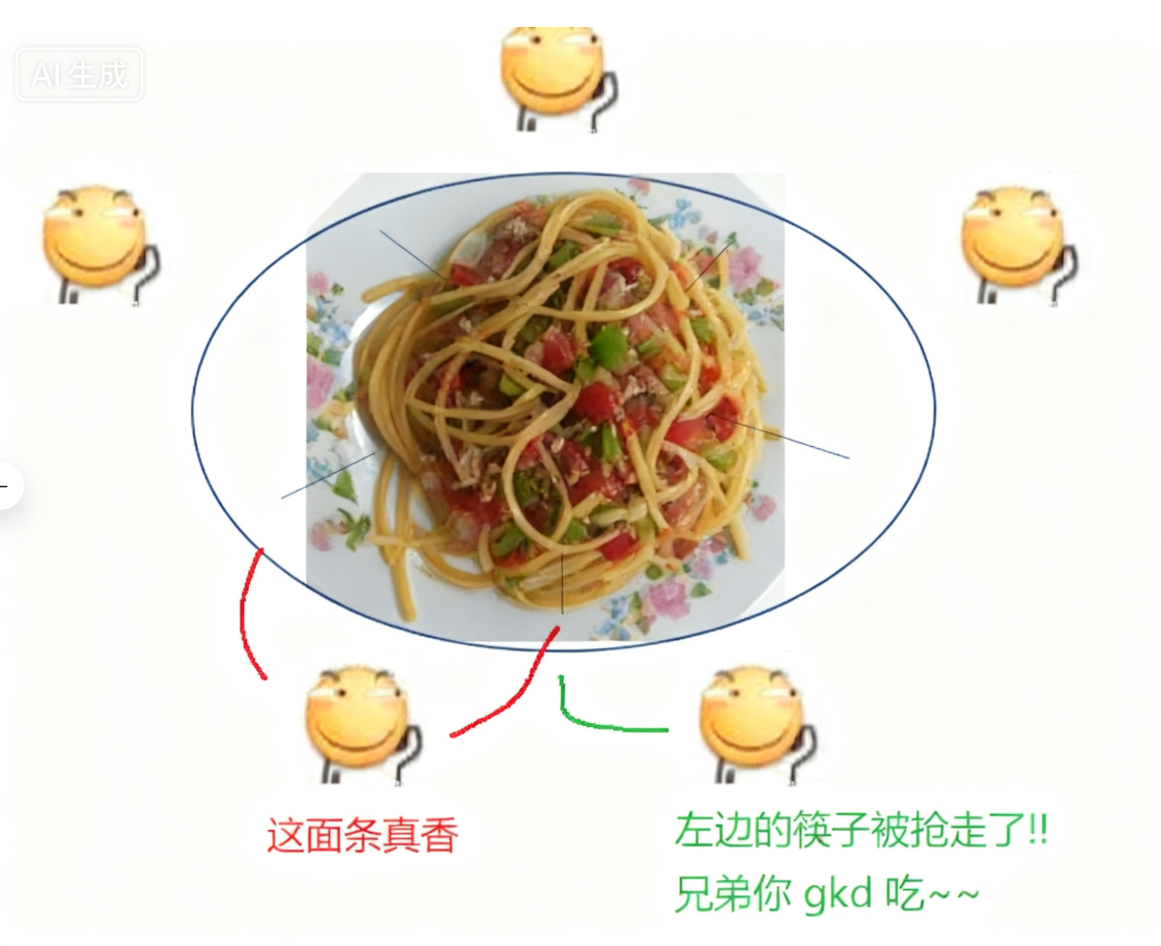
• [关键点在这]假设同⼀时刻,五个哲♂家同时拿起左手边的筷子,然后再尝试拿右手的筷子,就会发现右手的筷子都被占用了.由于哲♂家们互不相让,这个时候就形成了死锁
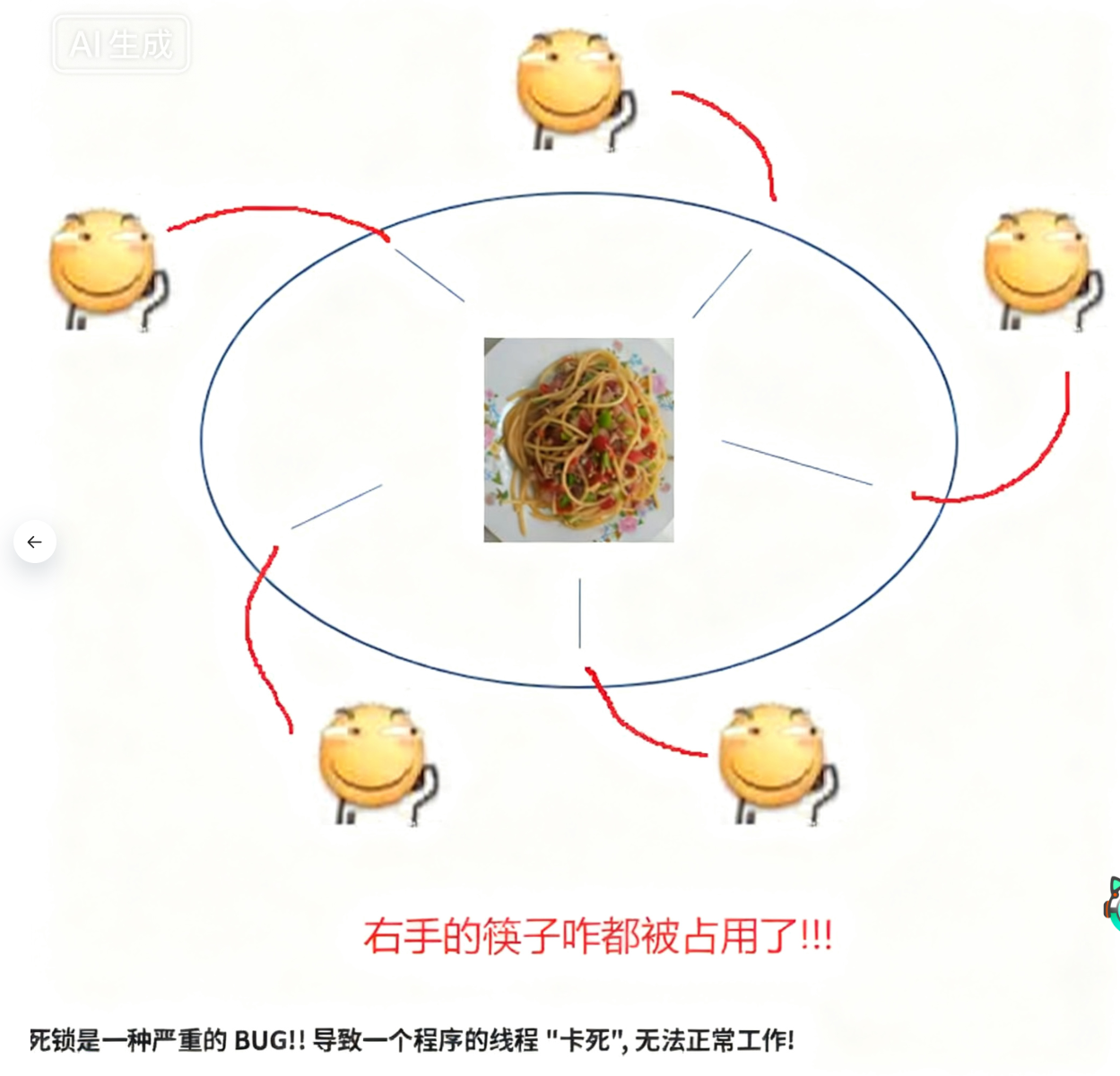
如何避免死锁
死锁产生的四个必要条件:
• 互斥使用,即当资源被⼀个线程使⽤(占有)时,别的线程不能使⽤
• 不可抢占,资源请求者不能强制从资源占有者⼿中夺取资源,资源只能由资源占有者主动释放。 • 请求和保持,即当资源请求者在请求其他的资源的同时保持对原有资源的占有。
• 循环等待,即存在⼀个等待队列:P1占有P2的资源,P2占有P3的资源,P3占有P1的资源。这样就 形成了一个等待环路。
当上述四个条件都成立的时候,便形成死锁。当然,死锁的情况下如果打破上述任何⼀个条件,便可 让死锁消失。
其中最容易破坏的就是"循环等待"
破坏循环等待
最常用的⼀种死锁阻止技术就是锁排序.假设有N个线程尝试获取M把锁,就可以针对M把锁进行编 号(1,2,3...M).
N个线程尝试获取锁的时候,都按照固定的按编号由小到大顺序来获取锁.这样就可以避免环路等待. 可能产生环路等待的代码:
两个线程对于加锁的顺序没有约定,就容易产生环路等待
Object lock1 = new Object();
Object lock2 = new Object();Thread t1 = new Thread() {@Overridepublic void run() {synchronized (lock1) {synchronized (lock2) {// do something...}}}
};
t1.start();Thread t2 = new Thread() {@Overridepublic void run() {synchronized (lock2) {synchronized (lock1) {// do something...}}}
};
t2.start();不会产生环路等待的代码: 约定好先获取lock1,再获取lock2,就不会环路等待
Object lock1 = new Object();
Object lock2 = new Object();Thread t1 = new Thread() {@Overridepublic void run() {synchronized (lock1) {synchronized (lock2) {// do something...}}}
};
t1.start();Thread t2 = new Thread() {@Overridepublic void run() {synchronized (lock1) {synchronized (lock2) {// do something...}}}
};
t2.start();其他常见问题
一、volatile关键字
- 作用:保证内存可见性,能使变量修改后立刻刷新到主内存,其他线程读取时从主内存获取最新值;但不保证原子性。
二、Java 多线程数据共享原理
JVM 内存分为方法区、堆区、栈区、程序计数器。其中堆区和方法区是多线程共享的,若将数据存于这两个区域,多个线程可访问到。
三、Java 线程池
- 创建方式:
- 方式 1:通过
Executors工厂类(如Executors.newFixedThreadPool()),创建简单但定制能力弱。 - 方式 2:通过
ThreadPoolExecutor手动创建,步骤多但定制能力强(可指定核心线程数、最大线程数、队列等)。
- 方式 1:通过
LinkedBlockingQueue作用:作为线程池的任务队列,用于存储用户通过submit()/execute()提交的任务,供线程池中的工作线程获取并执行。
四、Java 线程状态
包含以下 5 种状态,状态间切换由线程行为触发:
NEW:线程已创建但未调用start()。RUNNABLE:线程可运行(包含 “正在 CPU 执行” 和 “就绪待执行” 两种子状态),调用start()后进入。BLOCKED:因synchronized锁被占用而阻塞等待。WAITING/TIMED_WAITING:调用wait()(或带超时的wait()、sleep())进入等待状态。TERMINATED:线程执行完毕(run()方法结束)。
五、多线程下变量原子性保证
- 方案 1:使用
synchronized或ReentrantLock加锁,保证操作的原子性。 - 方案 2:使用
AtomicInteger等原子类(基于 CAS 机制),实现无锁的原子操作。
六、Servlet 线程安全性
Servlet 本身运行在多线程环境中。若在 Servlet 中定义成员变量,多请求并发时会因线程共享成员变量导致线程安全问题(如数据错乱)。
七、Thread和Runnable的区别与联系
- 联系:
Runnable是 “任务” 的描述,Thread是 “线程” 的载体;创建线程时可通过Runnable传递任务(也可直接重写Thread的run()方法)。 - 区别:
Thread类继承自Thread,Runnable是接口;用Runnable更易实现多线程间资源共享(多个线程可共享一个Runnable实例)。
八、线程start()方法
- 第一次调用
start():线程启动,进入RUNNABLE状态。 - 后续再次调用
start():抛java.lang.IllegalThreadStateException异常(线程状态非法)。
九、synchronized方法的锁竞争
synchronized修饰非静态方法时,锁是当前对象实例:
- 若两个方法属于同一个实例:线程 1 执行时,线程 2 会阻塞等待,直到线程 1 释放锁。
- 若两个方法属于不同实例:两个线程可并行执行,互不干扰。
十、进程和线程的区别
