递归算法精讲:从汉诺塔到反转链表
本篇章将深入讲解递归,碰到一道题怎么知道使用递归,以及递归该如何书写
汉诺塔问题
面试题 08.06. 汉诺塔问题 - 力扣(LeetCode)

算法原理讲解:
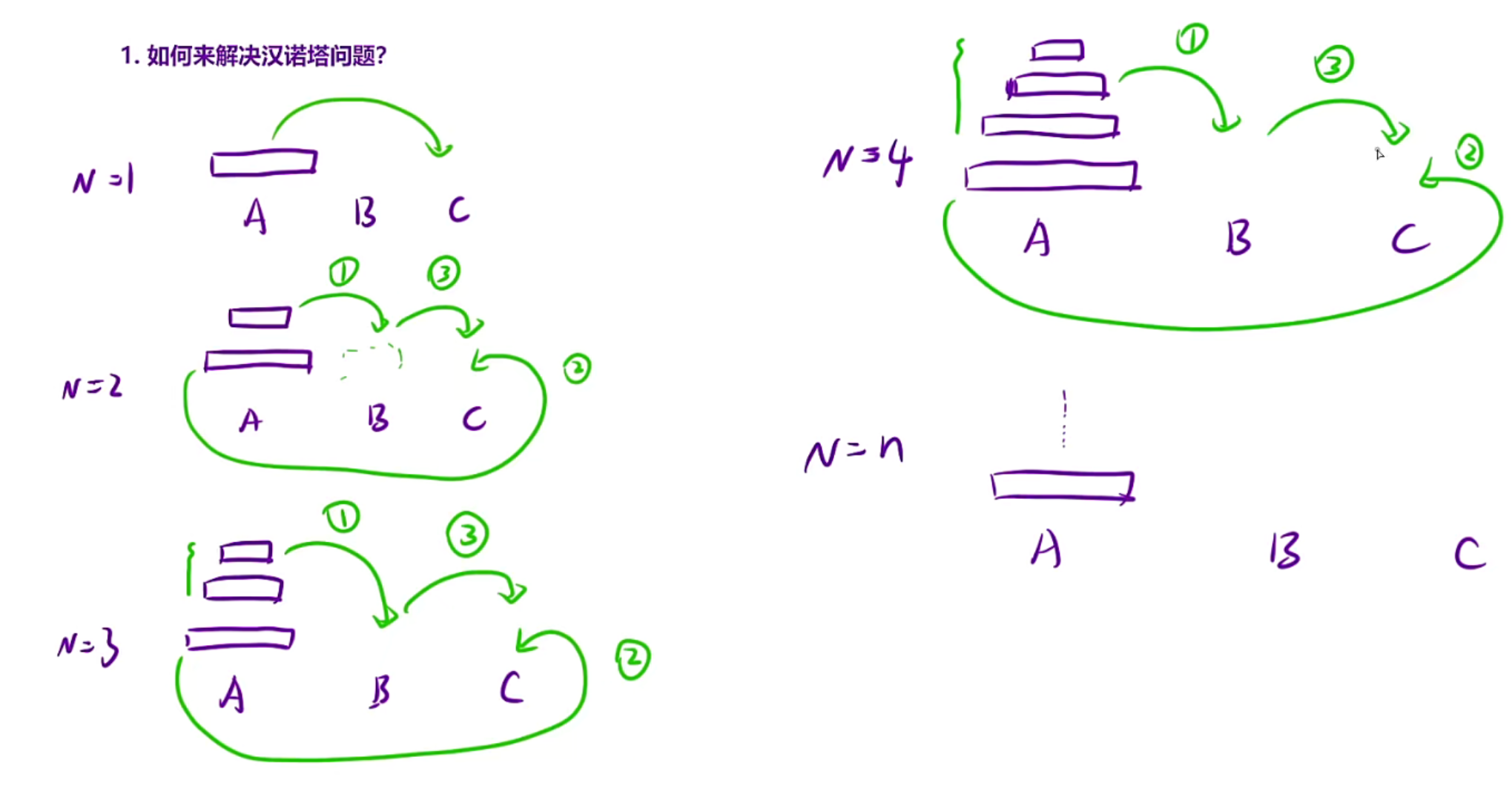
每次只需要借助一个盘,把上面的所有盘都移动到A\B,然后把最大的移动C,然后借助别的盘再把上面所有的移动到C即可
解决这个大问题的时候发现出现相同的子问题,出现子问题的时候又出现相同的子问题这时候就可以使用递归
如何书写递归?
重复子问题->函数头:将x柱子上的盘子借助y柱子转移到z柱子上
关心某个子问题在做什么->函数体:先把n-1的盘子移到某个柱子上,在将最大的移到目标上,然后再移n-1的
递归出口:发现n=1的时候是特殊的,所以当n=1的时候直接移动到c即可

代码编写
class Solution {
public:void hanota(vector<int>& A, vector<int>& B, vector<int>& C) {dfs(A, B, C, A.size());}void dfs(vector<int>& x, vector<int>& y, vector<int>& z, size_t n) {// 递归出口if (n == 1) {z.push_back(x.back());x.pop_back();return ;}dfs(x, z, y, n - 1);z.push_back(x.back());x.pop_back();dfs(y, x, z, n - 1);}
};dfs第一步:将x上的n-1个盘子借助z移动到y,第二步:移动最大的盘子,第三步移动n-1个盘子
合并两个有序链表
21. 合并两个有序链表 - 力扣(LeetCode)
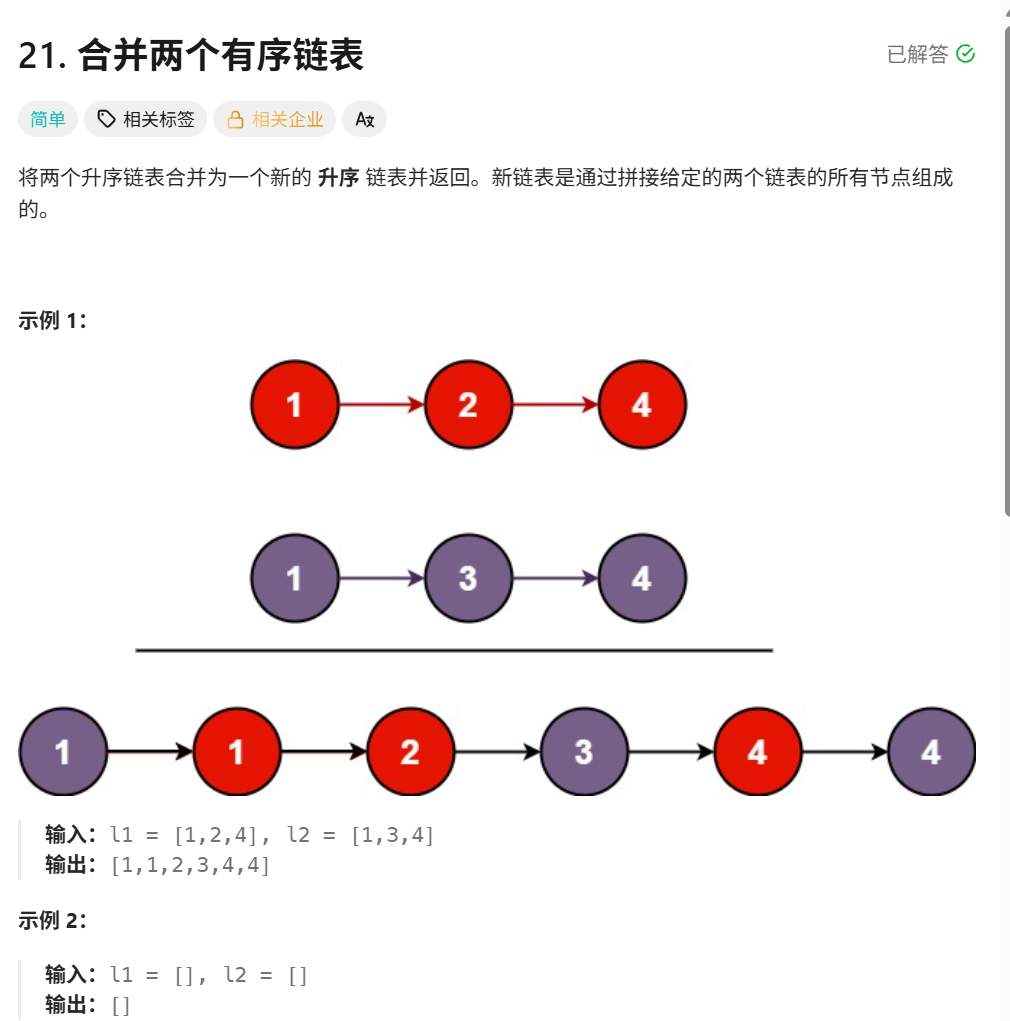
算法原理讲解:
合并成升序的时候就是上下两个结点进行比较,谁小谁当头结点,然后指针往下移动
发现处理问题的时候出现了重复的子问题:dfs函数就是给两条链表合并成升序
所以我们可以选出来一个头节点,后面的交给dfs函数,头节点链接后面合并好的即可
注意递归出口:无论哪边的指针跑到nullptr了,就返回另一边即可
代码编写
class Solution {
public:ListNode* mergeTwoLists(ListNode* list1, ListNode* list2) {return dfs(list1, list2);}ListNode* dfs(ListNode* list1, ListNode* list2) {// 给两条链表,自动排升序if(list1==nullptr) return list2;if(list2==nullptr) return list1;if (list1->val <= list2->val) {list1->next = dfs(list1->next, list2);return list1;} else {list2->next = dfs(list1, list2->next);return list2;}}
};循环vs递归 递归vs深搜(重点)
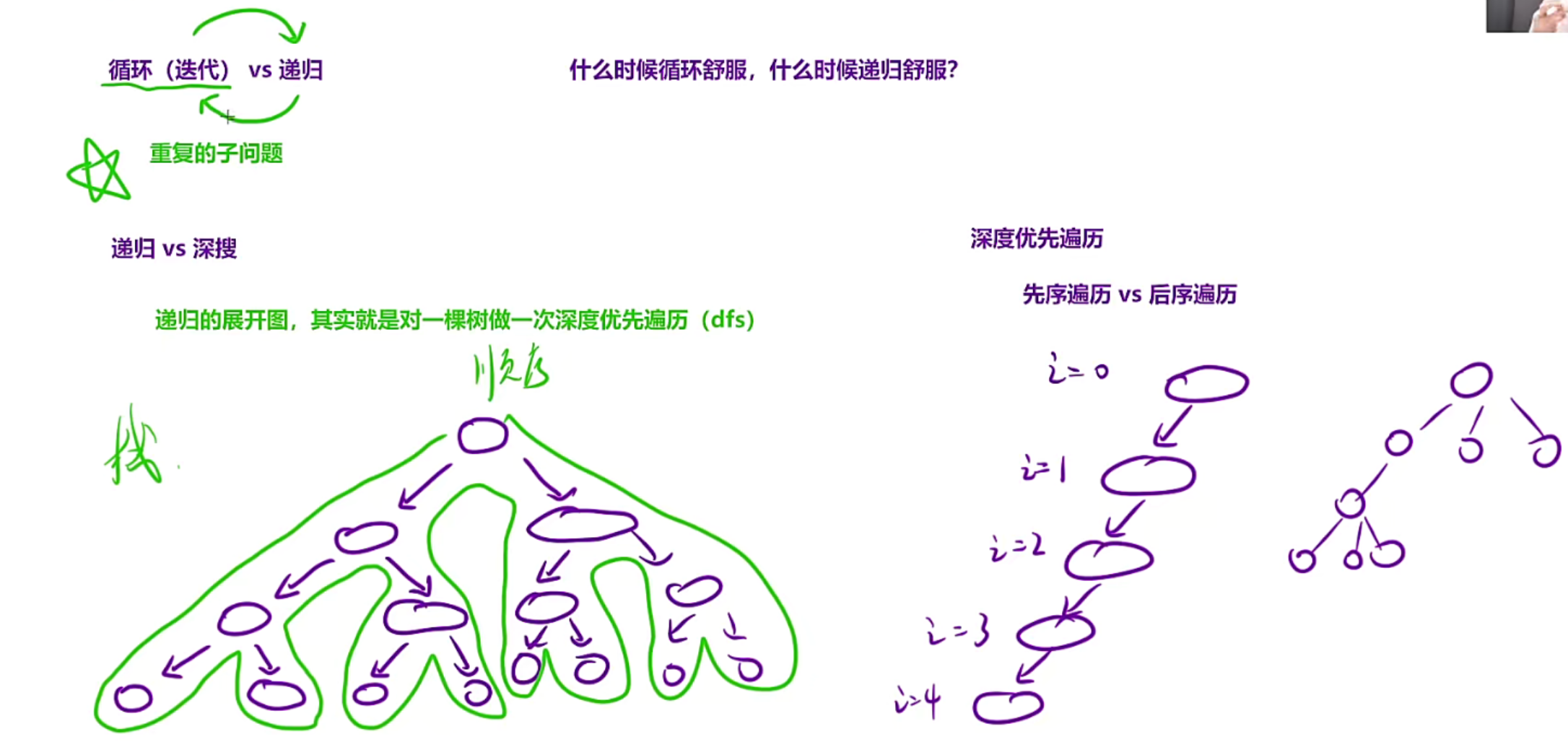
循环的本质就是再做一件重复的事情,递归的本质也是做一件重复的事情
所以循环和递归是可以互相转换的
递归本质就是深搜dfs,例如汉诺塔问题,把递归图画出来就是一颗二叉树的形状,先递归到左子树,然后回溯到根,再到右子树
如果这个汉诺塔问题要转换成循环是可以的但是麻烦,需要借助栈,因为要保存上一层的信息,否则回溯不到上一层,也就是递归是一个函数,如果是进程自己调用的话,它就会再自己的栈空间中堆栈,如果递归没有出口就会进行死循环,递归转换成循环的本质就是我们需要手动模拟这个栈帧
因为你每次进入下一次函数可能都会改变,所以你需要记录本次函数的局部变量、参数等本层的信息
如果树的形状只有一个分支的时候此时适合利用循环,因为不需要保存函数信息,不需要借助栈,此时适合循环解决,所以本质就是循环和递归可以相互转换
深度优先遍历(先序和后序)
先序就是先干完本层的事情,再递归进入下一层
后序就是先递归,先递归,到不能再递归,然后向上返回,返回后处理本层事情
这里的递归是后序遍历,也就是一直往下递归,然后再返回处理事情
反转链表
206. 反转链表 - 力扣(LeetCode)
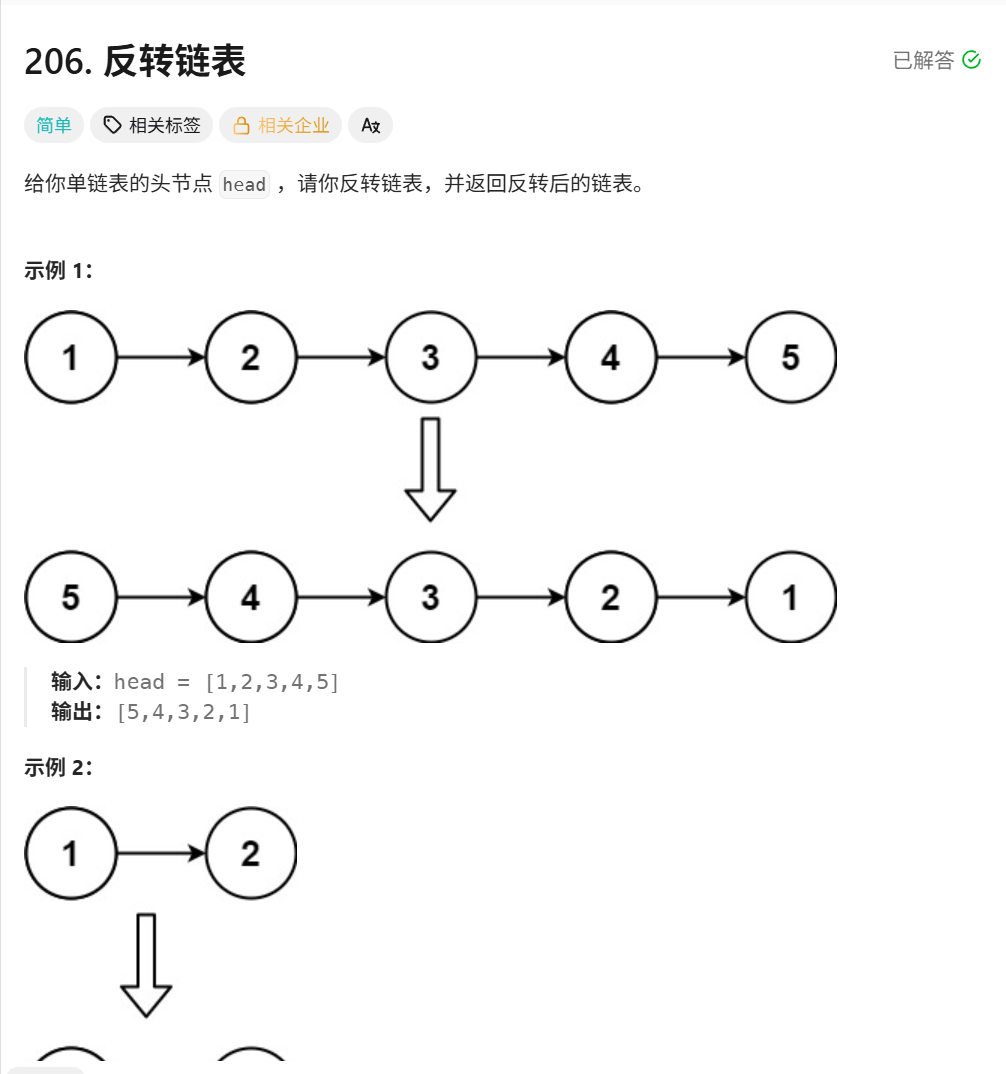
两个视角看待:
1.从宏观角度看待问题
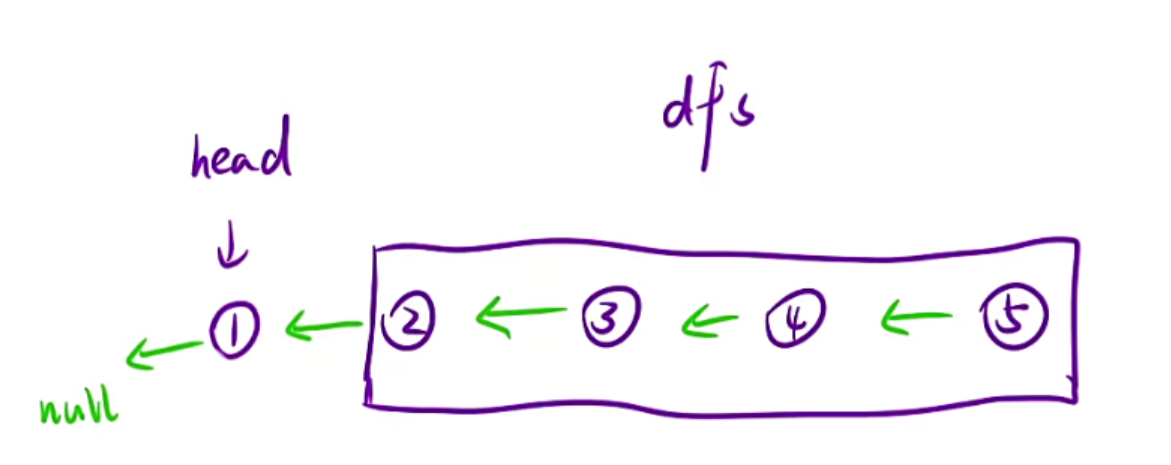
对于一个结点无非就是做把当前结点的next的next指向head,head的next指向nullptr
dfs黑盒的任务就是把head的后面的结点逆序并且返回头节点,所以我们只需要处理好当前结点即可
2.将链表看成一棵树,链表的本质就是一颗单分支的树,
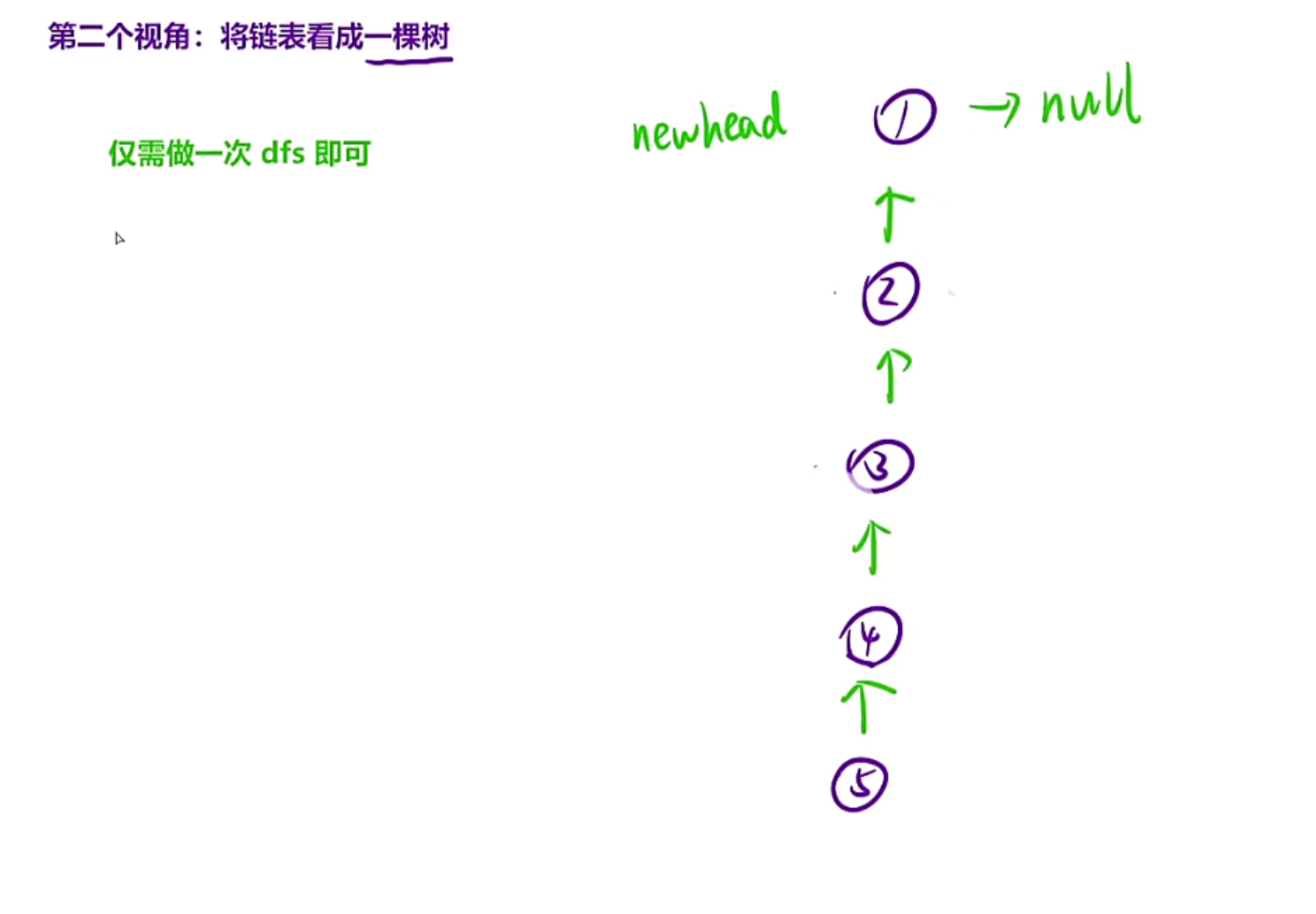 那么我们就可以对树进行后序遍历,先递归到最底下,然后逐层干完每层的事情后再向上放回
那么我们就可以对树进行后序遍历,先递归到最底下,然后逐层干完每层的事情后再向上放回
代码编写
class Solution {
public:ListNode* reverseList(ListNode* head) {if (head == nullptr)return nullptr;if (head->next == nullptr) {return head;}ListNode*newhead=reverseList(head->next);head->next->next = head;head->next = nullptr;return newhead;}
};两两交换链表中的结点
24. 两两交换链表中的节点 - 力扣(LeetCode)
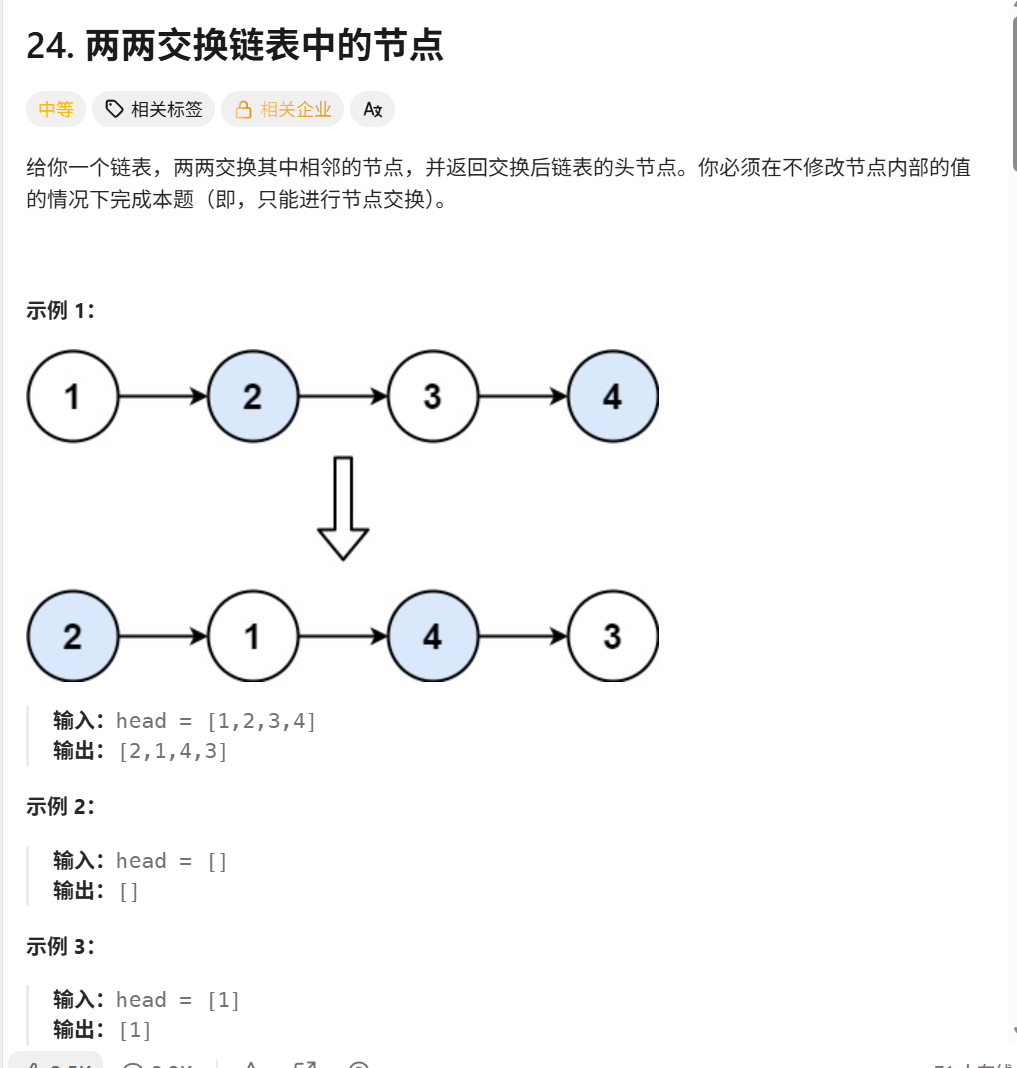
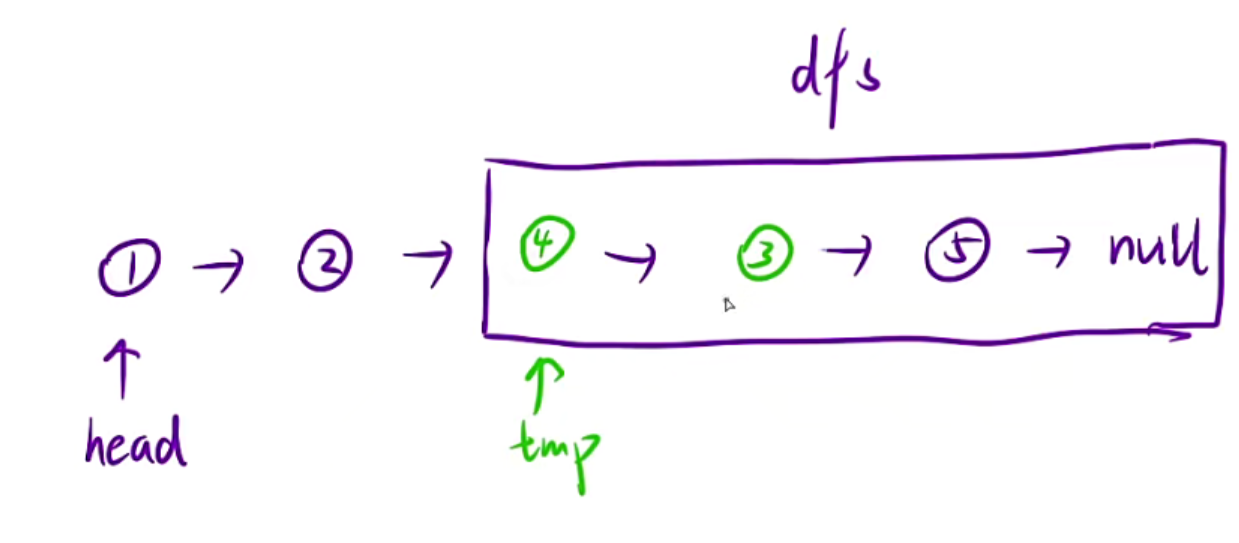
直接宏观看待:dfs就是给一个头节点,然后返回处理好了之后的链表
那我们只需要处理结点1和结点2,后面的都处理好了,所以链接起来就行,这里dfs也不需要返回新的头节点,因为它不像上一道题那样翻转,所以直接返回原来头节点的位置即可
代码编写
class Solution {
public:ListNode* swapPairs(ListNode* head) {if(head==nullptr||head->next==nullptr) return head;ListNode*next=head->next;head->next=swapPairs(next->next);next->next=head;return next;}
};Pow的n次幂
50. Pow(x, n) - 力扣(LeetCode)
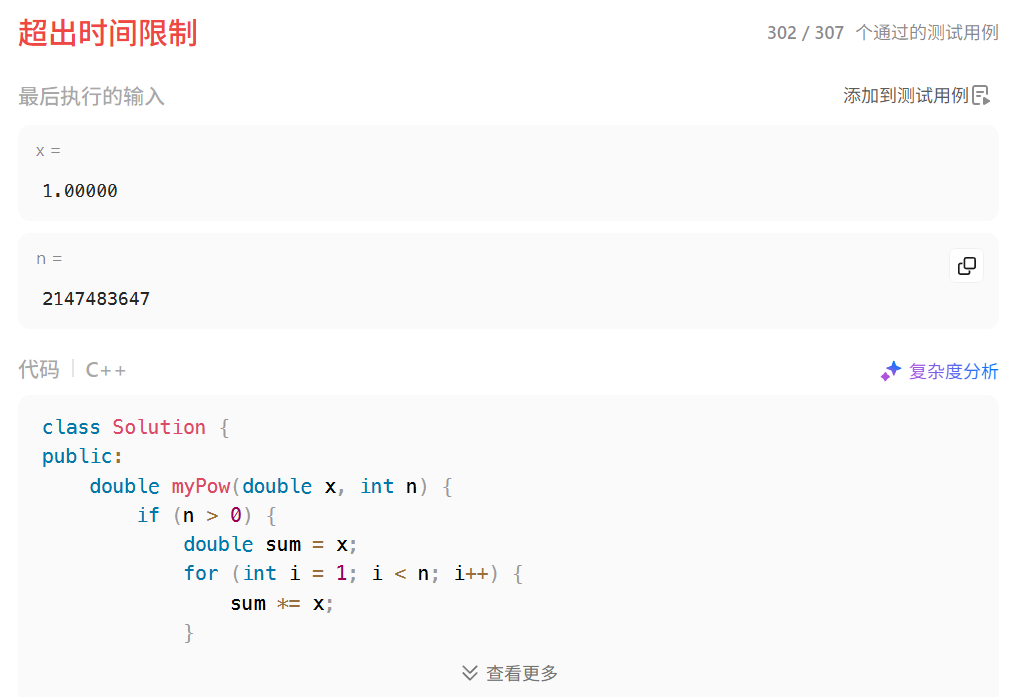
循环的写法是会超时的
快速幂
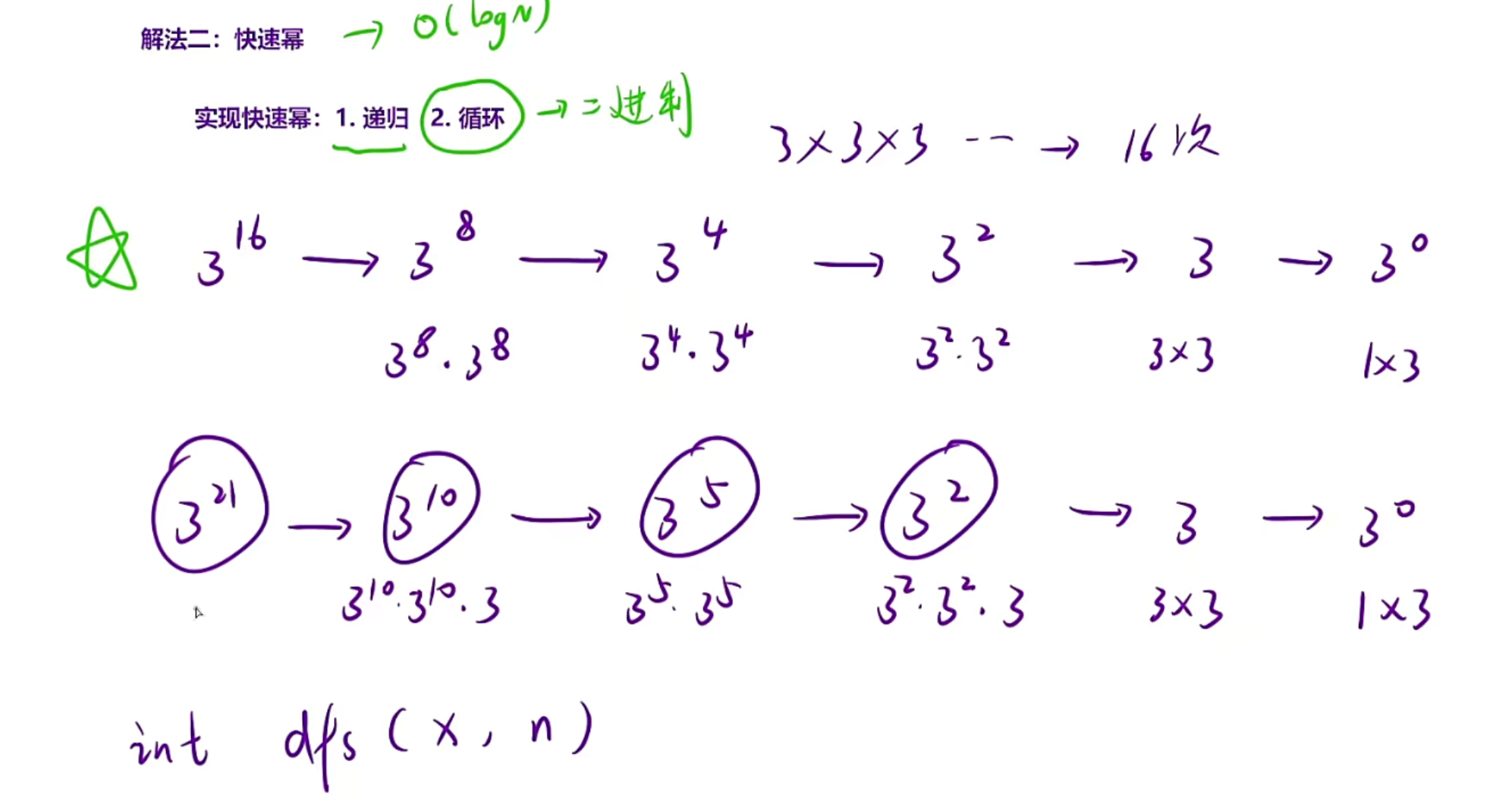
代码编写
class Solution {
public:double myPow(double x, int n) {return n<0?1.0/pow(x,-(long long)n):pow(x,n);}double pow(double x,long long n){if(n==0){return 1;}else {double tmp= pow(x,n/2);return n%2==0?tmp*tmp:tmp*tmp*x;}}
};注意这里强转成long long是因为负数转正数可能会溢出
总结
至此递归以完结,注意如果题目是在做重复的事情,那就可以用,并且递归和循环是可以互相转换的,递归的本质就是进程调用栈帧给我们保存了一些局部变量的信息,书写递归的时候要主要函数头,函数体和递归出口