3种数据模型的演变
数据模型的发展也是不断演变的,常见的数据模型有层次模型(Hierarchical Model),网状模型(Network Model)和关系模型(Relational Model)。
层次模型
层次模型中,实体用记录表示,实体的属性对应记录的字段,两条记录之间是一对多的关系。层次模型是数据库系统中最早出现的数据模型,典型代表是 IBM 公司 1968 年推出的 IMS(Information Management System)。
层次模型的数据集合满足以下两个条件:
- 有且只有一个结点没有双亲结点,称为根结点;
- 根以外的其他结点有且只有一个双亲结点。
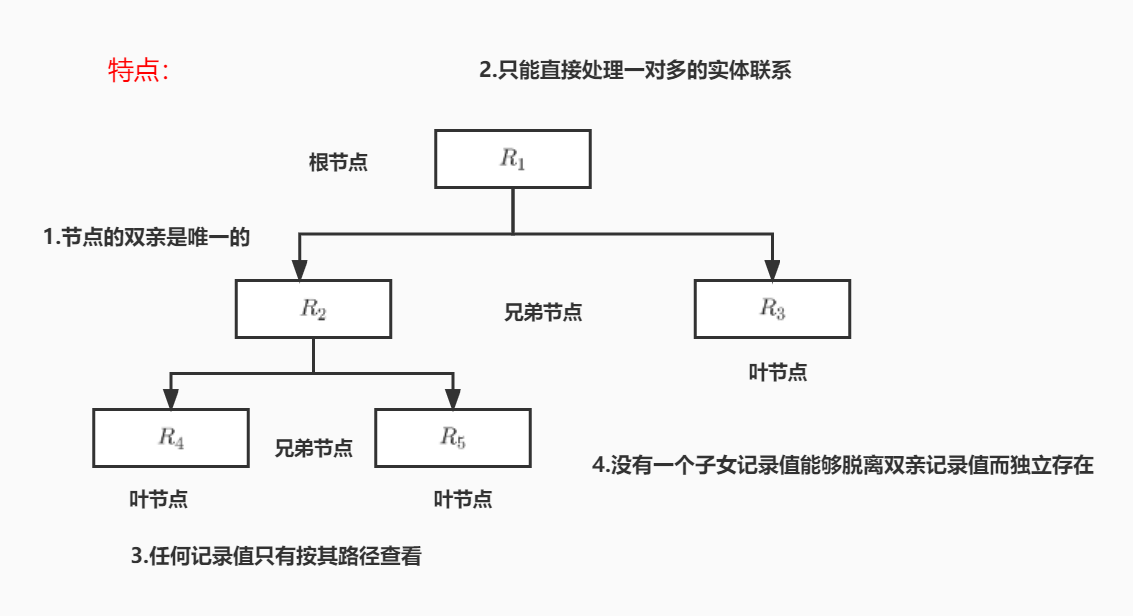
熟悉索引的同学应该能看出来,这种结构和索引的结构非常相似。从数据查询和操作的角度看,存在以下的优缺点。
层次模型的优点
- 层次模型的数据结构比较简单清晰;
- 层次数据库的查询效率高;
- 层次数据模型提供了良好的完整性约束支持。
层次模型的缺点
- 现实世界很多联系是非层次的,如多对多的联系;
- 如果一个结点具有多个双亲结点,用层次模型表示就会很复杂;
- 查询子女结点必须通过双亲结点。
网状模型
网状数据库系统采用网状模型作为数据组织方式,这是数据系统语言会议(Conference on Data System Language)下属的数据库任务组(Database Task Group)提出的一个系统方案,因此这个系统也称为 DBTG 系统或 CODASYL 系统。以 DBTG 思想为核心构建的网状数据库产品有,Cullinet Software 公司的 IDMS、Univac 公司的 DMS-1100 等。
网状模型的数据集合满足以下两个条件:
- 允许一个以上的结点无双亲结点;
- 一个结点可以有多于一个双亲结点。
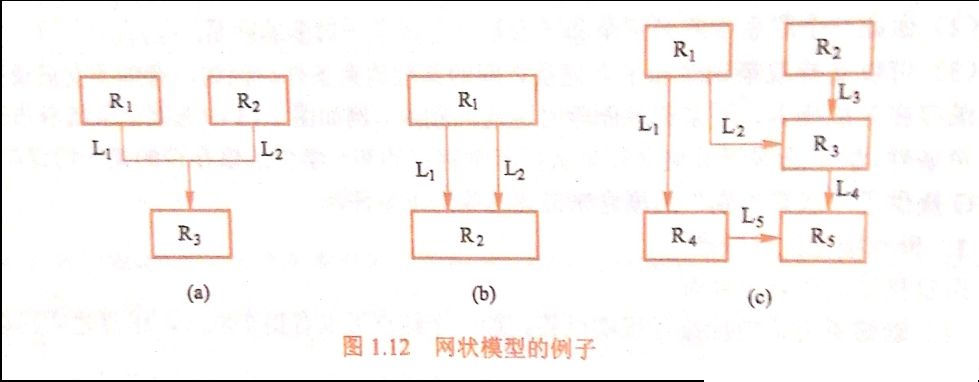
网状模型的优点
- 能够更直接的描述现实世界;
- 具有良好的性能,存取效率较高。
网状模型的缺点
- 结构比较复杂,特别是在大型数据库中网状关系的维护变得困难,不利于最终用户掌握;
- 数据定义语言和数据操作比较复杂,进入的门槛比较高;
- 由于记录类型之间的联系是通过存取路径来实现的,用户必须了解系统结构的细节,从而选择适当的存取路径来访问数据,加重了编写应用程序的负担。
关系模拟
关系模型是 1970 年 IBM 公司研究员 F.Codd 首次提出,开创了数据库关系方法和关系数据理论的研究,其本人页因此获得了 1981 年的图灵奖。我们今天看到的市面上流行的绝大部分数据库都支持关系模型,这类数据库也称为关系型数据库。
关系模型由一组关系组成,每个关系的数据结构是一张规范化的二维表。
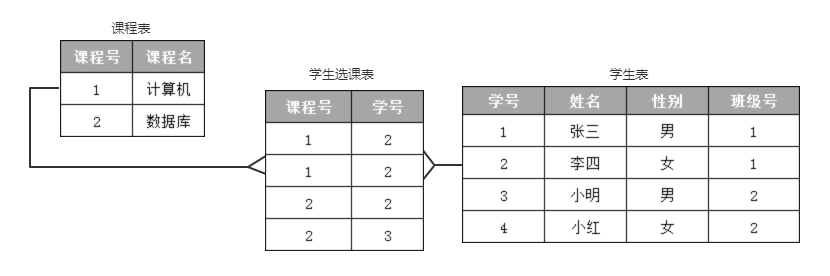
关系模型要求关系必须满足一定的规范条件,其中最基本的一条是,关系的每个分量必须是一个不可分的数据项,也就是说,不允许表中还有表。
关系模型的优点
- 关系模型建立在严格的数学概念基础上;
- 关系模型的概念单一;
- 关系模型的存取路径对用户隐蔽。
存取路径隐蔽导致其查询效率不如层次和网状模型,现代关系型数据库通过索引等技术手段优化查询性能,由此又带来了管理难度的增加。
课程总结
上述三种数据模型的是依次演进的,每种模型解决了上一代模型存在的问题,同时自身也存在优化的空间,因此也在不断演进。关系模型以一种简单的方式描述现实世界,因此在推出后受到了广泛的关注,由此发展成为当下最重要的数据模型。
但对于当前非结构化的数据,关系模型仍然存在不小的局限,因此近些年又演进出面向对象数据模型、半结构化的 XML 数据模型、键值对数据模型、文档和图数据模型等等,由此也涌现了种类繁多的新型数据库,在各种不同的应用场景中发挥自己的作用。