从一到无穷大 #58 构建 Lakehouse 通用 Compaction 框架
 本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
文章目录
- 引言
- Motivating Scenario
- AutoComp Architecture
- Generation and Filtering of Candidates
- Trait Generation
- Candidate Ranking and Selection
- Compaction Scheduling & Trigger
- Evaluation
引言
Influxdb IOX作为先锋,验证了基于FDAP建立时序数据库是一条可行的道路,任何组织以极小的代价就可以搭建一个基本可用的自研时序数据库,一众以Rust为核心构建的时序数据库犹如雨后春笋。
从历史看现在,InfluxData选择这条路径的原因在于InfluxDB1.x的存储结构与随着时序数据的多基数化(支付数据,Trace数据,日志数据,容器数据,流媒体数据)等已不再适用;自研的计算引擎又是基于火山模型,性能不足;项目架构又存在很多实现弊端(go语言编写(资源隔离问题,内存限制问题),依赖于mmap,不支持sql)等。
另外其发现开源的存储格式Parquet对于高基数场景同样适用,又在正确的时间拥抱Arrow,DataFusion与Rust,鉴于InfluxData在时序数据库领域的话语权,其选择的这条路径将时序数据库的“主流”实现完全Lakehouse化。
这个前提就引出了一个问题,时序数据库相比于Lakehouse的优势到底是什么?是否可以互相替代?
以我的经验,专有模态之于Lakehouse的优势本质在于数据特征带来的数据自治,例如数据分布,数据格式,存储介质,缓存等。而Lakehouse面对Raw Data就不能做这样的假设。
书回正传,既然优势在于数据自治,事实上很多模块其实是可以共用的,不区分模态,计算引擎就是一个很好的例子,其主要需求均为对列存数据的计算过程。这个思考驱使我们团队使用Velox为核心构建时序数据库计算模块,以支持实时交互场景与大规模分析负载;而Presto,Spark也使用Velox,而这两款产品又向上支持Graph processing,Interactive querying,ad-hoc analysis, ETL负载。
除此之外,我认为Compaction模块也可以共用,因为其本质都在于对数据的重整。
将Compaction按照功能模块细化,我的设计中可分为如下几个步骤:
- Compaction触发
- Compacion计划生成
- Compacion计划优先级排序
- Compacion任务调度
- Compacion任务执行
当然论文中起了个更加学术的名字:OODA Decision-Making Model (Observe, Orient, Decide, Act):
- Observe:候选者生成与筛选
- Orient:利用在观察阶段收集的统计数据来计算所谓的特征,这些特征作为决策辅助工具
- Decide:对候选对象进行优先级排序和排名
- Act:调度Compaction任务,包含卸载专用集群,按顺序调度压缩任务以缓解资源竞争,如果使用模式可预测,还可以将压缩任务推迟到非高峰时段执行等
论文中还分析了触发Compaction的时机。
可以看到,时序数据库专用的Compaction模块和Lakehouse中的Compaction模块没什么不同。
接下来我们详细的过一遍论文,看看其场景,动机与解决方案。
Motivating Scenario
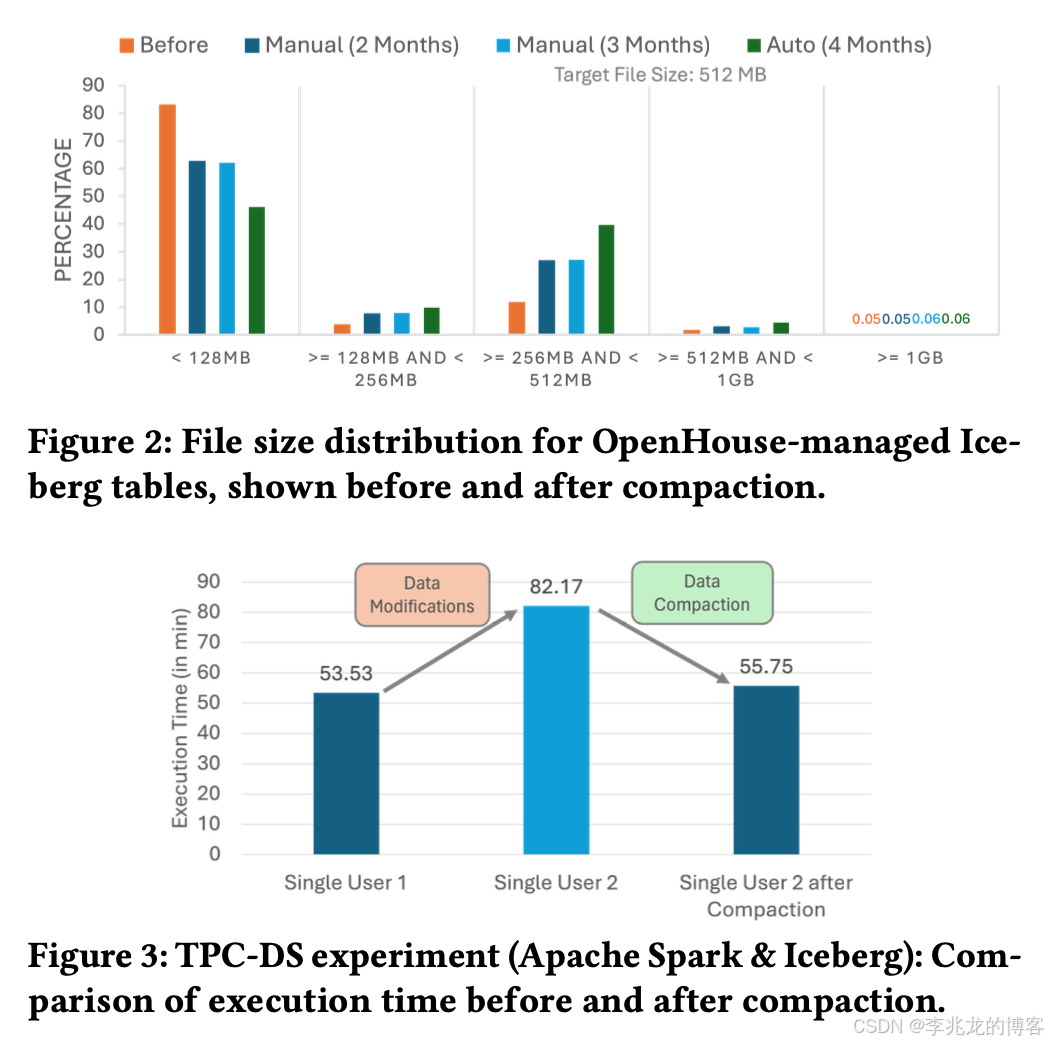
大量小文件的积累在以数据湖为中心的架构中带来了重大挑战,这种小文件的激增增加了开销,因为管理的对象数量更多,IO请求更频繁,这可能会给支撑数据湖的分布式存储系统带来压力,并影响其性能和可扩展性。例如,HDFS面临可扩展性挑战,因为维护文件系统元数据的NameNode只能管理有限数量的对象。随着文件数量的增长,管理的对象数量也成比例增加,给NameNode带来额外压力,并且通常需要联邦来分担负载。此外,小文件产生的大量RPC流量给HDFS带来了进一步负担,需要额外的观察者NameNode(即只读副本)来有效管理增加的流量。
存储有限行数的小文件还会降低列存格式的效率,这类格式依赖完善的编码和压缩来优化数据访问与存储。此外,这些文件的存在会导致LST( log-structured tables IceBerg,hudi,delta lake)中的元数据臃肿。每个事务都会在日志或checkpoint中追加对文件的引用,这会使元数据规模扩大,增加查询处理和维护操作所需的时间,进而影响整体性能和效率。
潜在的资金成本加剧了这一问题,因为云服务提供商通常会根据IO请求和数据传输量收费。
Hudi,IceBerg,Delta lake都实现了自己版本的Compaction机制[3][4][5],Hudi是为了处理MOR带来的查询性能衰减,后两者为了处理小文件,使用spark执行引擎计算。
而时序数据库中主要是为了去重,删除,和数据分布。
AutoComp Architecture

论文首先定义了这个框架的功能需求与非功能需求:
功能需求:
- FR1:细粒度工作单元。AutoComp 应基于动态数据分析自动选择压缩候选对象。它还应识别细粒度工作单元,以便在最佳粒度级别执行压缩,从而最大限度地发挥潜在效益。
- FR2:支持多种压缩策略。该框架应支持各种压缩策略,这些策略可以根据优化目标体现收益、成本或两者的结合。例如,为了减轻存储层的负载,基于收益的触发器可以优先处理包含更多小文件的表。此外,在资源受限的情况下,该触发器可以增强成本感知能力,以优先处理那些以较低成本产生较高收益的操作。在不同触发器之间切换可确保对各种场景的适应性,并保持性能与资源使用之间的平衡。
- 功能需求3:周期性和写入后执行触发。该框架应支持周期性触发执行和大型写入操作后立即触发执行。周期性执行可确保定期优化数据布局,防止随着时间推移出现过度碎片化,并提供可预测的成本管理。写入后执行能够实现即时重组,在大量数据摄入后提升性能并抑制文件激增。
非功能需求:
- NFR1:可扩展性。该框架的设计应考虑未来的可扩展性,使其能够集成额外的压缩策略,并根据需要适应新的工作负载。
- NFR2:可解释性。该框架应在相同输入条件下(例如,文件大小分布、工作负载特征)做出一致的压缩决策。
- NFR3:跨平台兼容性。该框架的设计应能在不同的LST和目录实现之间无缝运行。这种方法将其效用从LinkedIn的用例扩展到其他以数据湖为中心的平台,如Fabric[46]。
除了兼容性之外基本上和我之前的设计目标一致,当然我的设计中因为与时序模态强绑定,有一些额外的需求。
接下来主要介绍下策略:
Generation and Filtering of Candidates
- 压缩候选生成:将 “候选” 定义为待压缩的文件集合,其范围可灵活调整为整个表、分区或快照 —— 例如对大表采用分区级候选,支持并行处理;对需高频访问的新鲜数据采用快照级候选,保障性能。
- 候选过滤机制:通过平台特定规则精炼候选池,避免无效或冲突压缩。例如在 LinkedIn 的 OpenHouse 环境中,会过滤 “创建时间在预设窗口内的新表”,防止浪费计算资源在不影响系统长期健康的表上;同时规避存在频繁写入的候选,减少压缩与业务写入的冲突。
- 统计信息提取:定义标准化的统计信息布局,包含 “通用指标”(如候选内文件数量、单个文件大小)与 “自定义指标”(如候选的访问模式、使用频率,视系统能力而定),确保后续阶段可基于统一数据格式分析。
Trait Generation
第二阶段为定向阶段,它利用在观察阶段收集的统计数据来计算所谓的特征,这些特征作为决策辅助工具,用于在下一步对候选对象进行优先级排序和排名。论文主要关注两类特征:

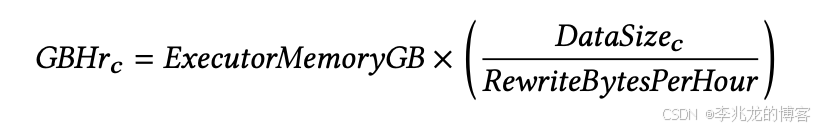
非常简单,压缩的收益定义为文件数量减少,压缩的成本定义为压缩时间*内存占用(这里提一点工程问题,Compact执行过程的内存是开始就分配好的,主要在文件的page缓存和列计算的Vector预分配)。
Candidate Ranking and Selection
无资源约束场景:
采用 “阈值触发” 逻辑,当候选的某类特征超过预设阈值时直接选中。例如为优化查询性能,可设置 “文件计数减少量≥10%” 的阈值 —— 当候选满足该条件时,直接进入行动阶段执行压缩,实现小文件的主动治理。此模式简单高效,但可能存在资源浪费(如非关键表的频繁压缩)。
资源受限场景。
将排序转化为 “多目标优化问题(MOOP)”,通过 “归一化 + 加权评分” 实现单目标排序,步骤如下:
采用 min-max 归一化将特征值缩放至 [0,1] 区间,公式为:

然后定义权重,把压缩收益和压缩成本带入:
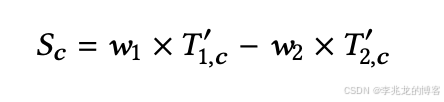
之前做副本调度的时候就是用这种方案去归一化存储,内存,CPU,副本数,任务数等多种指标,在归一化后越接近就是在多维空间中越靠近,差值大就需要调度。但是这种方法有个最大的问题就是阈值很难设置,也就是公式2中的w。论文中简单的把w1,w2设置为0.7和0.3。
论文的未来工作中提到Navigating Multi-Objective Trade-offs是一项独立的研究领域。其实Compaction问题也视为一项多目标优化任务,主要有两个目标:最大化文件数量减少量和最小化压缩过程中的计算成本。
当前的方法通过应用加权目标来计算单一解决方案,其中权重反映了选择的优先级。这个单一解决方案代表了一种特定的权衡,在给定当前目标权重和约束条件的情况下,提供了认为的最佳答案。虽然这种方法在实践中已显示出良好的效果。
但它将多个目标简化为单一加权分数,本质上存在过分强调某一指标而牺牲另一指标的风险。在某些情况下,所选解决方案可能无法很好地适应不断变化的系统条件或不同的操作要求,因为文件数量减少量和计算成本之间的最佳平衡会根据工作负载模式、资源可用性或特定数据库需求而变化。
论文中也提到这个问题可以使用Pareto frontier[6]来解决。
Compaction Scheduling & Trigger
自动压缩过程的最后一步是在执行阶段将选定的压缩候选对象进行调度。根据集群配置,压缩操作既可以在同一集群上调度,也可以卸载到专用的压缩集群,以最大程度减少高写入操作量和资源占用对用户性能造成的影响。
实际上,AutoComp允许用户自定义调度器,以适应特定的集群需求。例如,当压缩操作与用户事务在同一集群上运行时,可以按顺序调度压缩任务以缓解资源竞争;如果使用模式可预测,还可以将压缩任务推迟到非高峰时段执行。
触发有两点:
- 写后优化。一些现有架构利用集成在引擎内的钩子,在写入修改时实现自动压缩,将压缩决策“推”给引擎。
- 定期压缩。我们可以选择将自动压缩作为一项独立服务来实现,而不是直接修改引擎驱动程序,这一服务可能会集成到Catalog或控制平面中。该服务独立运行,会定期评估是否满足压缩条件,“获取”集群状态信息并相应地安排压缩工作。这在压缩周期可预测的场景中尤为有利,例如在非高峰时段集群利用率较低时安排压缩,或者确保压缩不会干扰其他活跃的工作负载。
Evaluation
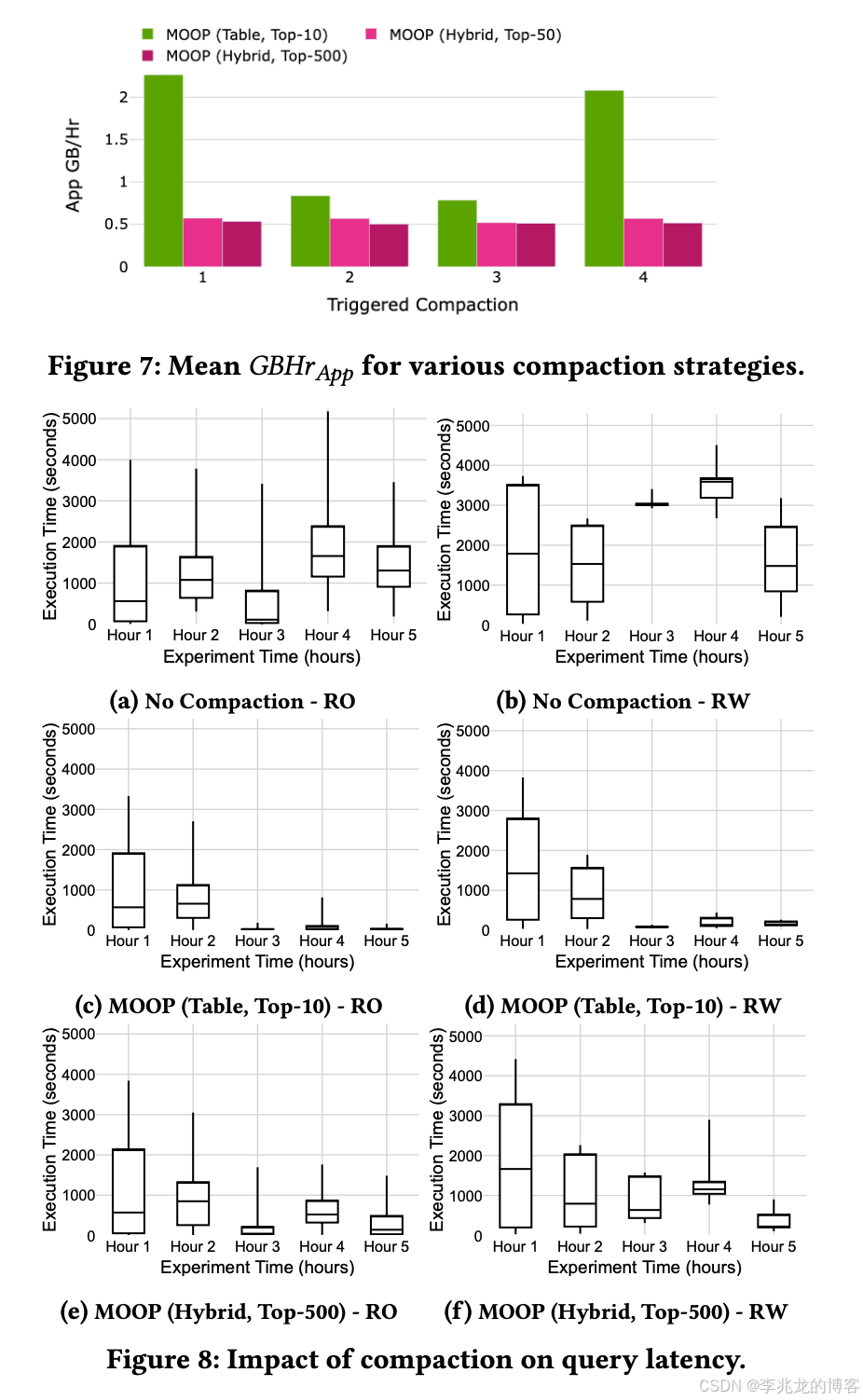
Compact调度的效果其实没什么意外,Compact计算的成本高查询时延就低,都是读写放大的Trade-Off。有无限的资源谁都想让读放大变小一点,可惜很多时候资源才是瓶颈。
参考
- Flight, DataFusion, Arrow, and Parquet: Using the FDAP Architecture to build InfluxDB 3.0
- 从一到无穷大 #26 Velox:Meta用cpp实现的大一统模块化执行引擎
- AutoComp: Automated Data Compaction for Log-Structured Tables in Data Lakes vldb2025
- Hudi Compaction
- IceBerg Compaction
- Pareto frontier