免费网站部署杭州制作网站个人
Task07:第三章 预训练语言模型PLM
(这是笔者自己的学习记录,仅供参考,原始学习链接,愿 LLM 越来越好❤)
本篇介绍3种很典的decoder-only的PLM(GPT、LlaMA、GLM)。目前火🔥的LLM基本都是用解码器的架构
什么是Decoder-Only的PLM?
就是Transformer的decoder层堆叠,或者在此基础上改进而来的。
对NLG,生成任务比较牛,这也是为什么用来做LLM生成文本。
GPT
GPT-123如何一步步超越BERT
= Generative Pre-Training Language Model 生成式预训练语言模型
1. 历程:
- 2018年OpenAI就已经发了GPT,但是那时候性能还不行,比BERT差。
- –>通过增大数据集、参数,(认为的“体量即正义”)让模型能力得到了突破【
涌现能力:不知怎的当年的小黑变身了】 - –> 2020年 GPT-3 就BOOM💣了
2. GPT-123的对比
主打一个越来越大,最终 GPT-3 达到了百亿级别参数量和百GB级别的语料规模。(这里对数量级有个认知就差不多了)
| 模型 | Decoder Layer | Hidden Size | 注意力头数 | 注意力维度 | 总参数量 | 预训练语料 |
|---|---|---|---|---|---|---|
| GPT-1 | 12 | 3072 | 12 | 768 | 0.12B | 5GB |
| GPT-2 | 48 | 6400 | 25 | 1600 | 1.5B | 40GB |
| GPT-3 | 96 | 49152 | 96 | 12288 | 175B | 570GB |
GPT-2比1的变化:
规模变大 + 尝试 zero-shot(这种方式GPT-3都不太行,2的效果肯定一般)
GPT-3比2的变化:
规模疯狂大 + few-shot(这个不是预训练+微调 范式了)
注:GPT-3 要在1024张 A100(80GB显存)显卡上分布式 训1个月(显卡要千张,时间要几十天)
chatGPT:
模型:GPT-3
方法:预训练+指令微调+RLHF(人类反馈强化学习)
什么是zero-shot?什么是few-shot?
零样本学习:就是预训练训完PLM就用来做任务了,不再进行微调;
少样本学习:是零样本学习和微调的偏0的折中,一般在prompt里面给3-5个例子(让PLM稍微知道我说的任务是怎么个回事)。
如:
zero-shot:请你判断‘这真是一个绝佳的机会’的情感是正向还是负向,如果是正向,输出1;否则输出0few-shot:请你判断‘这真是一个绝佳的机会’的情感是正向还是负向,如果是正向,输出1;否则输出0。你可以参考以下示例来判断:‘你的表现非常好’——1;‘太糟糕了’——0;‘真是一个好主意’——1。
GPT的预训练任务CLM
CLM = Casual Language Modeling 因果语言建模
(ps:这里原文写的是模型model,但我觉得这是一个任务,所以我喜欢把它理解成是modeling建模)
什么是CLM?
可以看出是N-gram的拓展。
前面所有token 预测 下一个token,补全。
一直重复这个训练过程,模型渐渐就能预判了。
(比之前其他PLM的预训练任务MLM掩码的、NLP下一句,更直接)
input: 今天天气
output: 今天天气很input: 今天天气很
output:今天天气很好
GPT模型架构
- 位置编码:
GPT 沿用transformer典的Sinusoidal(三角函数绝对位置编码)BERT用的可训练的全连接层 - 注意力:
和tran的不一样了,因为前面无encoder了,反而变得类encoder了。只有一次掩码自注意。 - 归一化:
采用pre-norm,很典的 - FNN:
用的2个一维卷积核而不是tran的线性矩阵
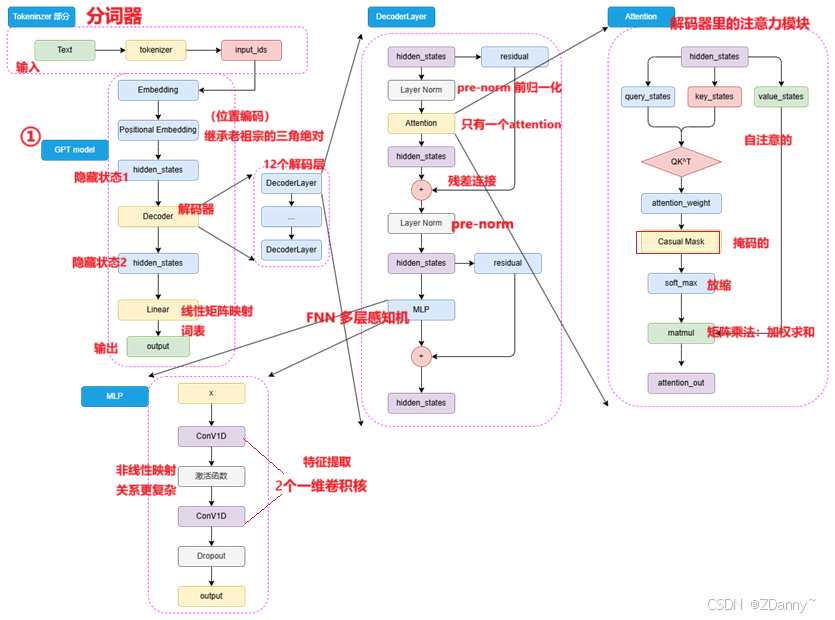
卷积核咋用的?
卷积核就是一个滑动的窗口,可以和输入点积计算,提取局部特征
x = [1, 2, 3, 4, 5, 6] #输入序列
w = [0.2, 0.5, 0.3] #一个大小为 3 的一维卷积核#就是每次取输入的3个数一起看,如:
输出第一个位置:0.2×1 + 0.5×2 + 0.3×3 = 2.6
输出第二个位置:0.2×2 + 0.5×3 + 0.3×4 = 3.6y = [2.6, 3.6, 4.6, 5.6]
卷积核的数值很有讲究的,可以看出这个核的偏好
这个也有些抽象
- w = [0.2, 0.5, 0.3] 说明每次取输入序列的3个数中更关注中间的=帮助模型理解一个词与前后词之间的平衡关系
- w = [0.1, 0.8, 0.1] =强调中间词(当前 token),但也考虑前后词

序列长度:词的个数
10个词128维词向量,矩阵形状:(10,128)
256个卷积核,nn.Conv1d(in_channels=128, out_channels=256, kernel_size=3)
in_channels=128 :填的是输入一个词向量的维度
out_channels=256:说明用了256个一维卷积核
kernel_size=3:说明卷积核大小是3,三个数字
ps:(这里还有一点问题)
NLP一行是一个token, DL中一行是一维词向量
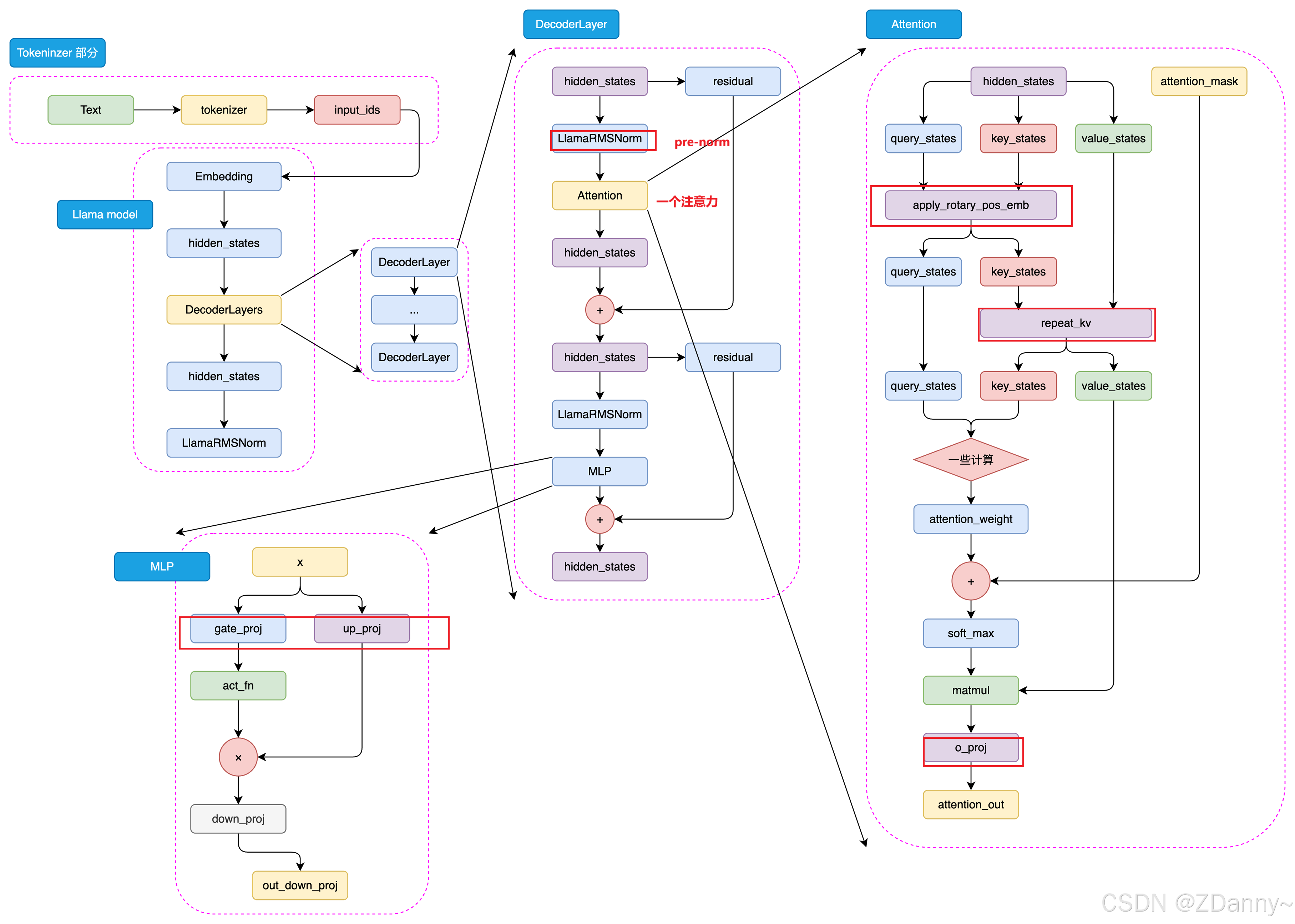
LLaMA
模型系列(开源但还要到它官网去申请)
参数:从几亿 7B 到几十、几百亿
数据:从 1T → 15T
上下文长度:2K → 8K
架构的优化:tokenizer+大词表、分组查询注意力机制GQA
LLaMA-123 一路走来
Meta的(前脸书Facebook的)
| 版本 | 发布时间 | 参数规模 | 训练语料规模 | 上下文长度 | 核心改进 |
|---|---|---|---|---|---|
| LLaMA-1 | 2023年2月 | 7B / 13B / 30B / 65B | >1T tokens | 2048 | 2048 张 "GPT-3" 训21天 |
| LLaMA-2 | 2023年7月 | 7B / 13B / 34B / 70B | >2T tokens | 4096 | 引入 GQA(Grouped-Query Attention),推理更高效 |
| LLaMA-3 | 2024年4月 | 8B / 70B /400B | >15T tokens | 8K | 优化tokenizer:词表扩展至 128K,编码效率更高 |
LLaMA的架构
下面是LlaMA3的结构,和GPT挺像,但是有些地方有差异,这里不展开了。
GLM
智谱的,清华计算机的,2023年国内首个开源中文LLM。
GLM也是一个任务名称
GLM系列
看下来发现:
数据直接用T级别的
对架构、训练策略等有一些改变
| 模型 | 时间 | 上下文长度 | 语料规模 | 架构/特点 | 关键能力 |
|---|---|---|---|---|---|
| ChatGLM-6B | 2023年3月 | 2k | 1T 中文语料 | 参考 ChatGPT 思路,SFT + RLHF | 中文 LLM 起点 |
| ChatGLM2-6B | 2023年6月 | 32k | - | LLaMA 架构 + MQA 注意力机制 | - |
| ChatGLM3-6B | 2023年10月 | - | - | 架构无大改,多样化训练数据集 + 训练策略 支持函数调用 & 代码解释器 | 语义、数学、推理、代码、知识达到当时 SOTA;可用于 Agent开发 |
| GLM-4 系列 | 2024年1月 | 128k | - | - | 新一代基座 |
| GLM-4-9B | 2024年1月 | 8k | 1T 多语言语料 | 与 GLM-4 方法一致 | 在同规模上超越 LLaMA3-8B |
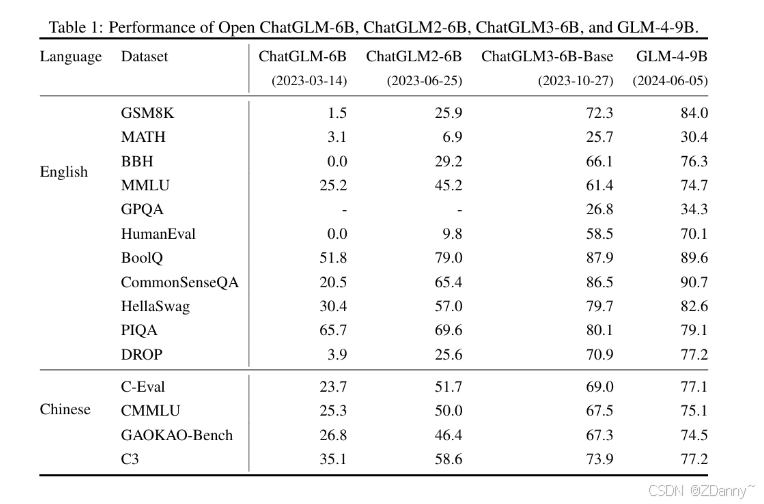
GLM用的预训练任务
GLM既是模型名字,又是这个模型用的预训练任务的名字
GLM=general language model 通用语言模型任务
GLM任务是怎么做的呢?
=CLM(因果)+MLM(掩码)的结合,
ps:感觉也是为啥它是G,general,可能就是因为融合了两种学习语言的任务。掩码让你会用词,因果让你会表达,这也是人可以用来学习语言的抽象任务吧。
一个序列进行随机位置的几个token掩码,然后让模型预测被遮蔽的部分+这个序列的下一token。
GLM任务的效果?
使用时间:GLM在预训练模型时代比较火,只第一代用,后来GLM团队自己也还是回到了传统的CLM任务。
效果:对增强模型理解能力比较好
【模型性能与通体了BERT(encoder-only)的性能对比】
GLM的模型架构
和GPT架构很像(咱就是说,毕竟大佬,所以咱也得respect一下)
差异点一:用Post-Norm = 后归一化
如下公式很直观了
LayerOutput = LayerNorm(x + Sublayer(x))
post-norm和pre-norm的区别?
这两个是有顺序差别的归一化方法。
计算差别: (在计算残差链接的时候,)
- post归一化顾名思义,残差计算之后再归一化。
- pre归一化就是先进行归一化,再残差连接。
效果差别:
- post归一化对参数整体的正则化效果更好,模型的鲁棒性更好(泛化能力更强,在面对不同场景的时候)。
- pre自然的是有一部分参数加载参数正则化之后,所以可以防止模型梯度失控(消失或者爆炸)
二者如何选择?
- 对很大的模型,一般默认觉得pre会好一点(防梯度失控)
- 但GLM里提出说post可以避免LLM数值错误,可能就是post就让参数整体进到归一化里,所以比较不割裂吧 。
差异点二:减少输出参数量
做法:MLP --> 单个线性层
作用:输出层参数量少了,参数都在模型本身
ps:
- 输出层参数量少了有什么用?
输出层参数并不是模型掌握的知识,他是最终生成文本的数字表示。所以量少了转成文本就简单了- 参数都在模型本身有什么用?
模型的参数就是模型学到的能力的数字抽象,输入进来的内容经过和这些参数的计算,就可以运用到模型能力
(这里可能涉及到大模型参数的可解释性问题,大家可以再去看看别的资料讲解)
差异点三:激活函数换成GeLUs
- 传统的激活函数——ReLU,就是保留正的数(传播),负的为0
- GLM的激活函数——GeLUs,在0附近做软过渡,非线性映射(更柔)
可能后期出一个激活函数的合集吧,大家想看也可以评论区催更