大模型的On-Policy Distillation(在线蒸馏策略)
总结一下Thinking Machines发表的《On-Policy Distillation》,文章探讨了一种名为“On-Policy Distillation”的后训练方法,结合了RL的在线策略(on-policy)和知识蒸馏的密集奖励信号。
原文链接:https://thinkingmachines.ai/blog/on-policy-distillation/
参考中文博客:https://www.mlpod.com/1217.html
大模型后训练范式的优劣对比
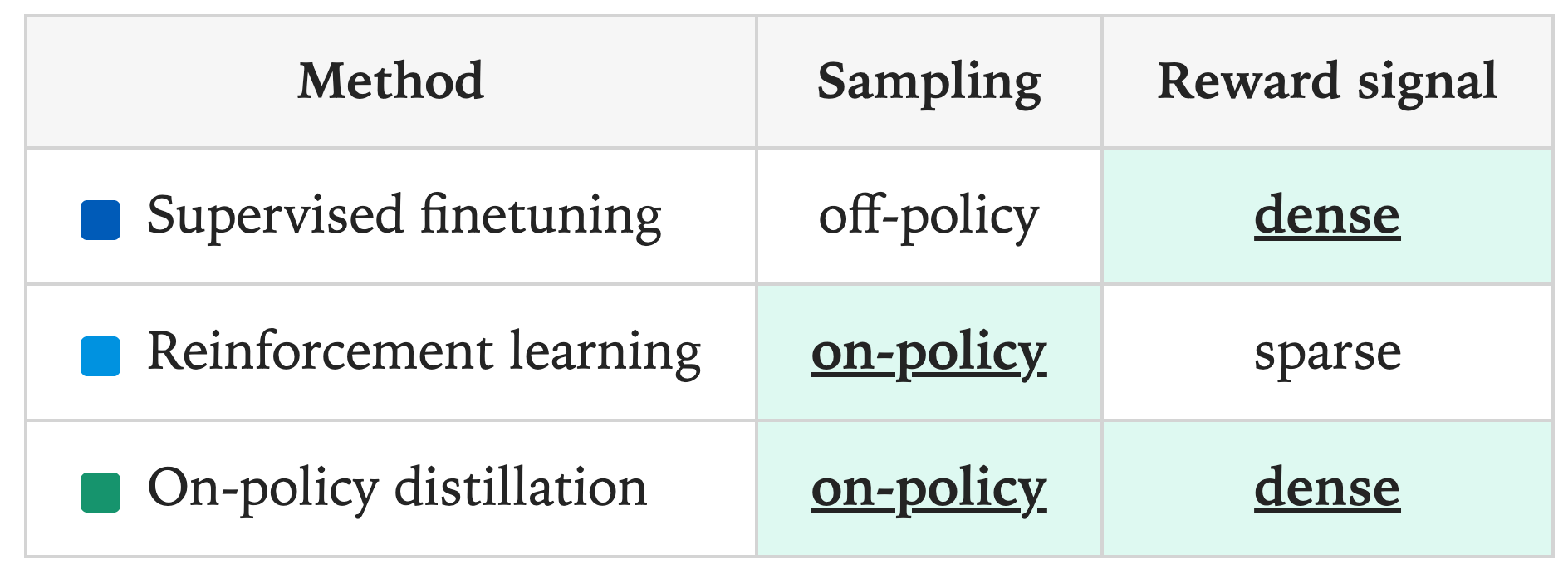
大模型的后训练方法主要分为两类:
- On-policy(在线策略):从学生模型自身生成的推理过程中采样,并为这些结果分配奖励。
- 优点:On-policy的优势在于模型通过学习自己生成(rollout)的样本,可以更直接地避免错误。
- 缺点:然而,RL有一个主要缺点——反馈/奖励极其稀疏,无论推理过程有多长,每次训练只提供少量的反馈信息(比如accuracy/format reward)。
- Off-policy(离线策略):依赖外部(比如一个更强大的教师模型)提供的目标输出,学生模型通过模仿这些目标进行学习。Off-policy通常通过SFT完成,使用精心整理的、任务相关的标注样例进行训练(标注数据通常来自在该任务上表现优异的教师模型)。这里本质上就是 蒸馏(distillation) 机制,让学生模型去匹配教师模型的输出分布,具体做法是以教师模型的推理轨迹进行训练,包括其生成的完整序列以及中间的思考步骤。训练时可以使用教师在每一步的完整下一词分布(称为logits蒸馏),也可以只用采样的序列。
- 优点:奖励信号密集,是在token粒度上进行蒸馏学习。
- 缺点:学生模型是在教师常见的上下文中学习,而非它自己实际会经常遇到的上下文中学习,这会导致误差累积。如果学生在早期犯了教师从不犯的错误,它就会越来越偏离训练中见过的状态,对于长序列表现尤为严重。为避免这种发散,学生必须学会从自身错误中恢复。另一个问题是,学生可能在学习模仿教师的风格和自信度,但并非学习事实准确性。
举个原文中下棋的例子:如果你在学习下棋,on-policy强化学习是自己独立下棋,没有任何指导,赢输的反馈直接与自己的棋局相关,但反馈仅在每局结束时提供一次,并且无法告诉你哪些棋步对结果贡献最大;而off-policy蒸馏则观看一位棋艺高超的大师下棋,你能观察到非常强的棋步,但这些棋步往往发生在新手很少遇到的棋盘状态下,所以无法有效模仿。那么,on-policy与off-policy相结合,就等同于在学棋的场景中,有一个老师给你每一步棋打分(等级从愚蠢到杰出),让你可以在自己亲自下棋的同时,深刻理解每一步棋的好坏。
所以,更好的后训练方法应该兼顾两者优势:1)获得on-policy训练中RL的自适应学习;2)利用off-policy蒸馏的密集奖励信号。于是引出了本文的核心——On-Policy Distillation。
On-Policy Distillation方法
On-policy distillation的核心思想:从学生模型中采样推理轨迹,并使用高性能的教师模型对每个轨迹的每个token进行评分。

On-policy distillation会对学生模型生成的解题步骤中的每一步进行评分,惩罚导致最终答案错误的步骤,同时强化那些执行正确的步骤。
损失函数:反向KL散度
选择用逐token的反向KL散度(Reverse KL Divergence),该损失函数衡量在给定相同上文的情况下,学生模型和教师模型在下一个token 上的分布差异。
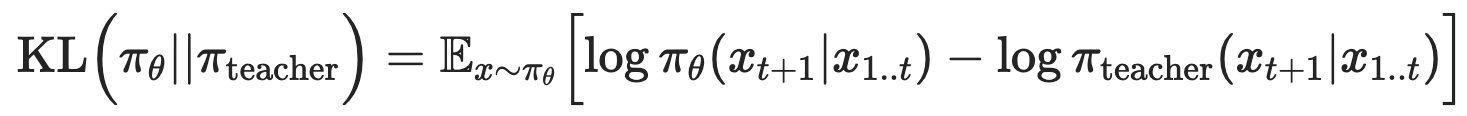
奖励函数的目标是最小化反向KL散度,这促使学生在每个状态下尽可能地模仿教师的行为。当学生的行为与教师完全相同时,反向KL散度为0。
该方法可以显著节省计算,因为不需要等待一个完整的序列生成结束才计算一个奖励,而是可以用更短或部分的序列进行训练。同时,计算教师模型的对数概率(log prob)只需要一次前向传播,而轨迹完全是由更小的学生模型生成的。此外,这种方法也不需要一个单独的奖励模型或标注模型。
伪代码
- 初始化教师:为教师模型创建一个采样客户端
- 采样轨迹:与标准RL一样,从学生模型中采样序列(rollouts),在采样过程中,已经计算好了学生模型的对数概率 ,用于后续的重要性采样损失计算
- 计算奖励:使用compute_logprobs函数计算教师客户端,获取在 学生模型采样的轨迹上,教师模型的对数概率。然后利用这两个对数概率计算反向KL散度
- 使用RL进行训练:将每个token的优势(advantage)设置为负的反向KL散度,然后调用RL的重要性采样损失函数来更新学生模型的参数
# 初始化教师模型
teacher_client = service_client.create_sampling_client(base_model=teacher_config.base_model,model_path=teacher_config.load_checkpoint_path,
)# 用学生模型采样轨迹
trajectories = do_group_rollout(student_client, env_group_builder)
sampled_logprobs = trajectories.loss_fn_inputs["logprobs"]# 计算奖励(师生模型的反向KL散度)
teacher_logprobs = teacher_client.compute_logprobs(trajectories)
reverse_kl = sampled_logprobs - teacher_logprobs
trajectories["advantages"] = -reverse_kl# 训练RL
training_client.forward_backward(trajectories, loss_fn="importance_sampling")本质上,offline-policy蒸馏就是我们以前常规理解的知识蒸馏,利用教师模型的轨迹,来让学生模型进行模仿学习。而on-policy蒸馏是让学生模型正常做rollout以及RL训练,但是同时让教师模型在学生模型所生成的轨迹上,计算下一个token的概率分布,然后优化目标就是让学生模型在token粒度上学习教师模型的预测分布。