基于 CNN-BiLSTM-Attention 的电力变压器油温多元时间序列预测(含详细源码)
基于 CNN-BiLSTM-Attention 的电力变压器油温多元时间序列预测
项目总体预览
./cnn_bilstm_attention_xm/
├── dataset
│ └── ETTh1.csv
├── logs
│ └── log_train.txt
├── predict.py
├── prediction_result.csv
├── readme.md
├── requirements.txt
├── res_imgs
│ ├── all_months_prediction.png
│ ├── attention_weights_2017-07.png
│ └── first_month_prediction.png
├── saved_models
│ ├── attention_model_2018-06.h5
│ ├── cnn_bilstm_attention_2018-06.h5
│ ├── prediction_metrics.csv
│ └── scalers.json
├── tools
│ └── msyh.ttc
└── train.py一、问题说明
本项目旨在解决多变量时间序列预测任务,基于电力变压器数据集 (ETTh1.csv) 实现变压器油温(OT)及相关变量的预测。该数据集记录了 2016 年 7 月至 2018 年 7 月期间的小时级负载指标和油温数据。
核心目标:利用历史监测数据构建预测模型,实现变压器未来状态的精准预测,为设备运维提供数据支持。
具体要求:
- 1. 数据处理:采用 Z-score 标准化对数据进行预处理,标准化参数基于
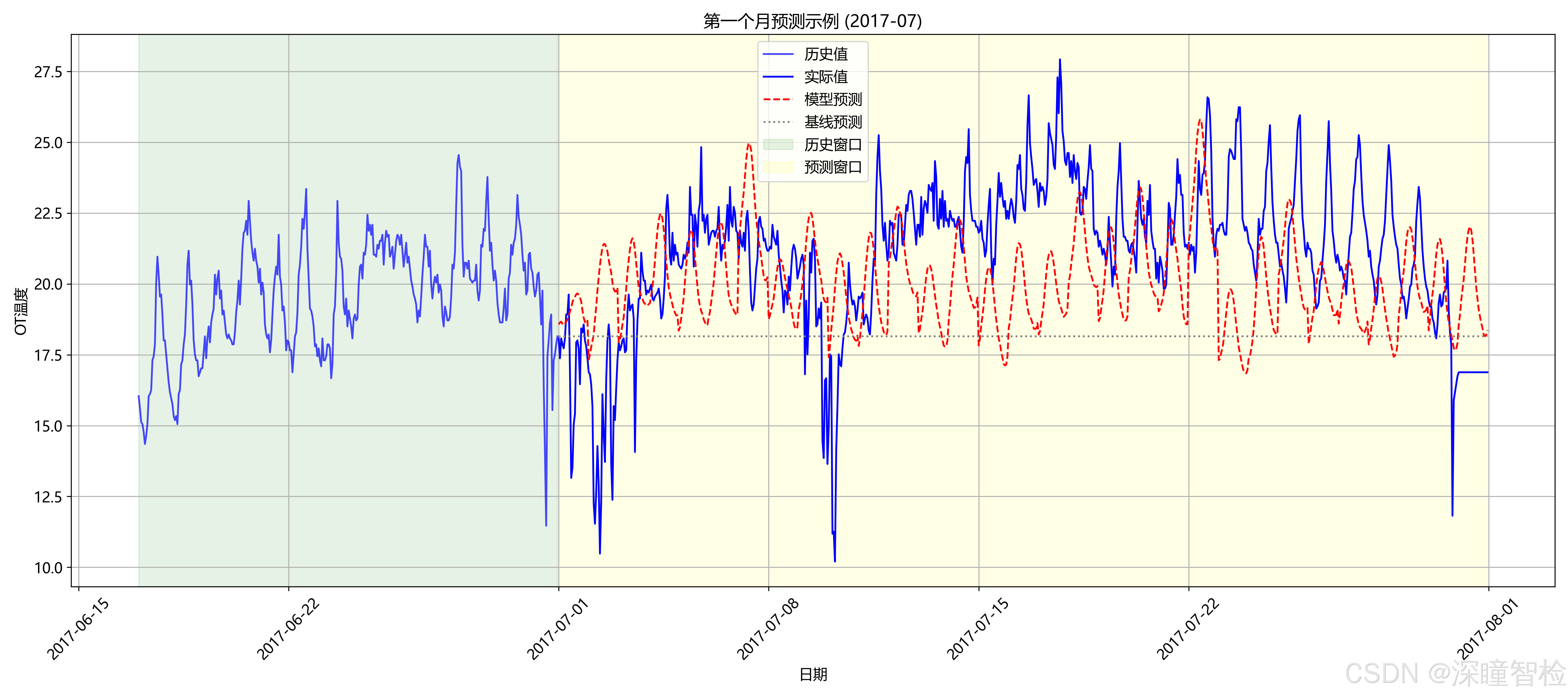
2016.7-2017.6的历史数据计算 - 2. 预测粒度:使用过去336 小时(14 天) 的数据,预测未来24 小时(1 天) 的数据
- 3. 训练策略:实施月度滚动预测机制,从
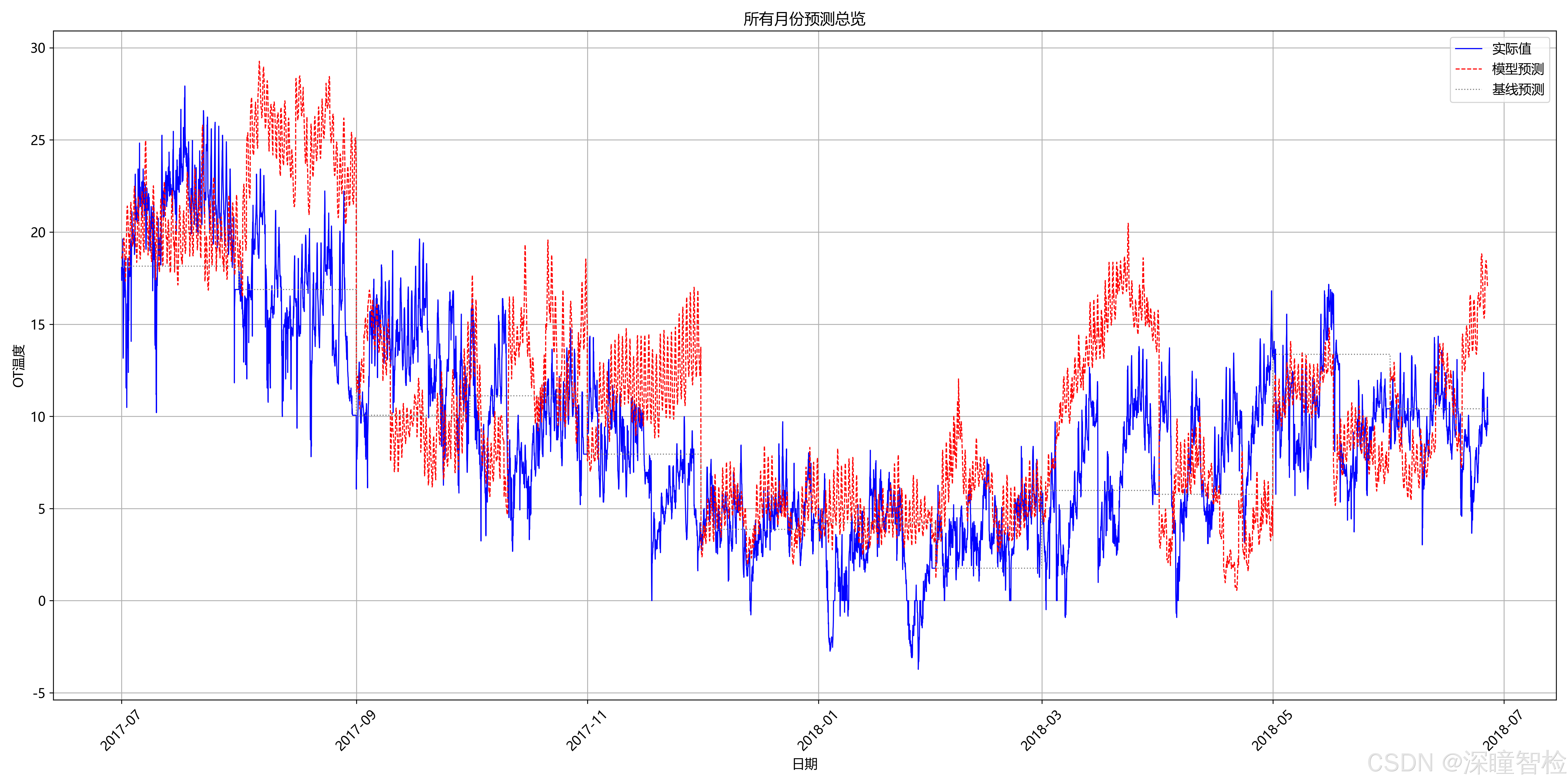
2017.7开始,每月利用截止到上月底的全部历史数据重新训练模型并预测当月数据 - 4. 效果评估:采用均方误差(MSE)和平均绝对误差(MAE)作为评估指标,并与 "上一个值" 基线模型进行对比
二、技术实现
1. 数据处理流程
- • 数据加载与清洗:使用
pandas加载 ETTh1.csv 数据,转换时间格式并设置为索引,确保数据频率为小时级 - • 缺失值处理:采用前向填充(ffill)和后向填充(bfill)相结合的方式处理缺失值
- • 标准化处理:基于
2016.7-2017.6的训练数据计算每个特征的均值和标准差,对全量数据进行 Z-score 标准化,并保存标准化参数用于后续预测
2. 模型架构
项目采用CNN-BiLSTM-Attention混合模型架构,融合了卷积神经网络和循环神经网络的优势:
- • CNN 特征提取层:通过两层卷积(Conv1D)和池化(MaxPooling1D)操作,提取局部特征模式,将 336 小时序列降维至 84 小时
- • BiLSTM 层:使用双向 LSTM 网络捕捉时间序列的双向依赖关系,配备 Dropout 层防止过拟合
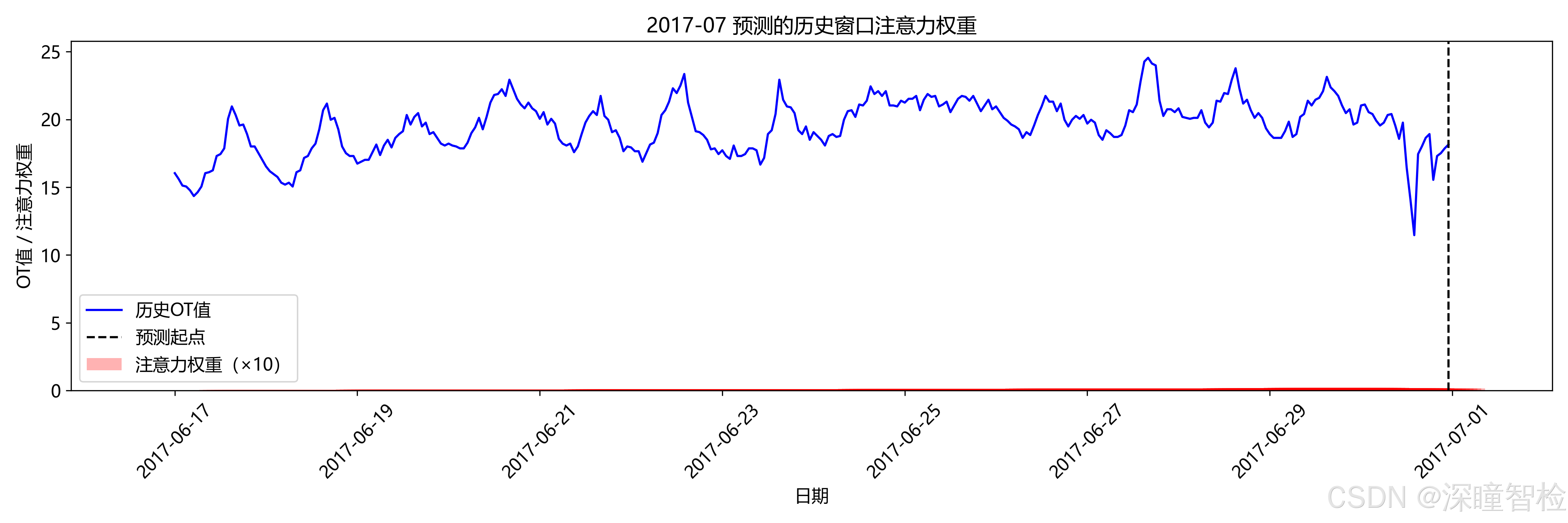
- • Attention 机制:通过自定义 Attention 层聚焦历史序列中的关键时间步,提升模型对重要信息的关注度
- • 输出层:将特征映射到未来 24 小时的多变量预测结果
3. 训练机制
- • 月度滚动训练:从 2017 年 7 月开始,每月使用截止到上月底的全部历史数据重新训练模型
- • 数据划分:采用 9:1 的比例划分训练集和验证集,使用早停机制(EarlyStopping)防止过拟合
- • 模型保存:支持两种保存策略(仅保存最新模型或保留所有月度模型),同时保存注意力权重模型用于可视化分析
- • 训练参数:批量大小 128,学习率 0.0005,最大迭代 200 轮,采用 Adam 优化器和 MSE 损失函数
4. 预测策略
- • 滚动预测机制:由于模型单次预测 24 小时,采用自回归(Autoregressive)策略,将前 24 小时的预测结果作为输入一部分,持续预测直至覆盖目标周期
- • 多步预测实现:通过
predict_rolling函数实现任意时长的连续预测,自动处理预测窗口的滑动更新 - • 结果还原:使用训练阶段保存的标准化参数,将预测结果从标准化尺度转换为原始物理尺度
5. 评估与可视化
- • 评估指标:计算每个月预测结果的 MSE 和 MAE,并与 "上一个值" 基线模型对比
- • 可视化内容
- • 月度注意力权重分布(展示历史序列中各时间步的重要性)
- • 首个月份预测详情(包含历史窗口、预测窗口、真实值与预测值对比)
- • 全周期预测总览(展示所有预测月份的模型表现)
- • 预测结果与历史数据对比图
三、代码结构
train.py
- • 数据加载、清洗与标准化处理
- • 自定义 Attention 层实现
- • CNN-BiLSTM-Attention 模型构建
- • 月度滚动训练与预测逻辑
- • 模型保存与评估指标计算
- • 注意力权重与预测结果可视化
predict.py
- • 模型与标准化参数加载
- • 预测数据预处理
- • 滚动预测函数实现
- • 预测结果逆标准化转换
- • 预测结果可视化与保存
四、依赖环境
pandas==1.5.3
numpy==1.23.5
scikit-learn==1.2.2
tensorflow==2.12.0
matplotlib==3.7.1
tqdm五、如何运行
- 1. 环境准备:
### 构建虚拟环境 conda create -n tf212 python=3.10 ### 进入虚拟环境 conda activate tf212 ### 安装指定依赖包 pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple - 2. 模型训练:
python train.py训练过程将自动执行月度滚动训练,生成模型文件、评估指标和可视化图像
- 3. 预测执行:
python predict.py加载最新模型(或指定月份模型),基于历史数据预测未来指定小时数的油温,并生成预测结果文件和可视化图像
六、输出说明
- • 模型文件:保存于
saved_models目录,包括月度模型、注意力模型和标准化参数 - • 评估指标:月度 MSE/MAE 对比表格,保存为
prediction_metrics.csv - • 可视化结果:保存于
res_imgs目录,包括注意力权重图、月度预测示例和全周期预测总览 - • 预测结果:生成
prediction_result.csv,包含预测时间和对应 OT 温度预测值
该项目通过融合多种深度学习技术和严谨的评估机制,实现了变压器油温的精准预测,为电力设备的智能运维提供了有效支持。
⭐源码项目获取说明
下方关注-VX回复关键词【油温多元时间序列预测项目】可查询获取整个项目源码(制作不易,拒绝白嫖),感谢您,祝前程似锦!