AI 十大论文精讲(五):RAG——让大模型 “告别幻觉、实时更新” 的检索增强生成秘籍
系列文章前言
在人工智能技术从理论突破走向工程落地的进程中,一篇篇里程碑式的论文如同灯塔,照亮了技术演进的关键路径。为帮助大家吃透 AI 核心技术的底层逻辑、理清行业发展脉络,博主推出「AI 十大核心论文解读系列」,每篇聚焦一篇关键论文的问题背景、核心创新与行业影响。本篇博客解读AI领域十大论文的第五篇——《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》(检索增强生成:面向知识密集型NLP任务的解决方案)。
文章目录
- 系列文章前言
- 一、研究背景与核心问题:大模型的“知识三大痛点”
- 1.1 知识更新成本极高(“过期知识难迭代”)
- 1.2 缺乏可解释性与溯源能力(“答案来源说不清”)
- 1.3 易产生“幻觉”(Hallucination,“编造事实乱说话”)
- 1.4 知识存储效率低(“大参数≠多知识”)
- 二、论文深度解读:RAG的核心原理与技术细节
- 2.1 RAG的整体架构:“检索器+生成器+知识库”三位一体
- 2.1.1 非参数化记忆:可随时更新的“外挂知识库”
- 2.1.2 检索器:精准高效的“智能搜索引擎”
- 2.1.3 生成器:融合知识的“文本创作大师”
- 2.2 RAG的两种核心变体:按需选择“检索策略”
- 2.2.1 RAG-Sequence(序列级检索):“一查到底,全用同一批资料”
- 2.2.2 RAG-Token(token级检索):“逐词选资料,按需匹配”
- 2.3 训练策略:端到端优化,兼顾效率与性能
- 2.3.1 优化目标:负边际对数似然
- 2.3.2 参数冻结:降低训练成本
- 2.3.3 训练细节:工程优化保障
- 2.4 关键组件的“通俗比喻”:服务员+厨师+菜单库
- 三、实验验证:RAG在“知识考试”中全面超越SOTA
- 3.1 实验任务与数据集
- 3.2 核心实验结果:RAG全面领先
- 3.2.1 开放域问答:小参数超越大模型
- 3.2.2 抽象问答生成:更少幻觉,更准答案
- 3.2.3 Jeopardy问题生成:更事实、更具体
- 3.2.4 事实核查:无需检索监督,接近SOTA
- 3.3 ablation实验:验证核心组件的必要性
- 3.3.1 检索器的重要性
- 3.3.2 知识库热替换的有效性
- 3.3.3检索文档数量K的影响
- 四、RAG的核心优势与行业影响
- 4.1 解决大模型四大痛点的“独门秘籍”
- 4.2 对行业的深远影响
- 4.2.1 学术层面:开启“检索增强生成”研究热潮
- 4.2.1 工业层面:降低大模型落地门槛
- 4.2.3技术层面:统一“检索”与“生成”的框架
- 4.3 未来展望:RAG的进化方向
- 五、总结:RAG为何能成为“大模型标配”?
今天基于这篇2020年发表、至今仍被频繁引用的经典论文,我们要聊一个改变大语言模型(LM)“知识能力”的关键技术——Retrieval-Augmented Generation(检索增强生成,简称RAG)。如果你好奇为什么现在的AI能准确回答“2024年诺贝尔物理学奖得主”,还能标注信息来源;为什么AI不会把“中耳结构”说成“连接鼻子”;为什么无需重新训练就能让模型掌握2025年的新政策——背后大概率有RAG的影子。这篇文章会从论文核心出发,先深度拆解RAG的技术原理,再用通俗比喻化解复杂概念,最后结合实验数据和行业影响,让你彻底读懂“检索+生成”的魔力。
一、研究背景与核心问题:大模型的“知识三大痛点”
近年来,预训练语言模型(如GPT-2、BART、T5)凭借“参数化记忆”实现了NLP领域的跨越式突破——它们将海量训练数据中的知识“固化”在模型参数里,无需外部信息就能直接生成文本。但在知识密集型任务(如开放域问答、事实核查、专业内容生成)中,这类纯参数化模型暴露了三个致命局限,论文将其概括为“无法回避的知识困境”:
1.1 知识更新成本极高(“过期知识难迭代”)
纯参数化模型的知识完全依赖训练数据,一旦训练完成,就成了“静态知识库”。要更新知识(比如新增2023年的诺贝尔奖得主、2024年的新政策),必须重新训练模型——这需要消耗数千GPU小时、数百万美元成本,且会导致“灾难性遗忘”(忘记旧知识)。论文中提到,T5-11B这类大模型要更新世界领导人信息,需全量重训,而实际应用中几乎无法落地。
1.2 缺乏可解释性与溯源能力(“答案来源说不清”)
模型生成答案时,无法说明“知识来自哪里”。如果答案错误(比如把“苏格兰货币”说成“欧元”),用户无法验证依据,也无法定位错误根源。这在医疗、法律等关键领域完全不可接受——没人敢相信一个“说不清理由”的AI建议。
1.3 易产生“幻觉”(Hallucination,“编造事实乱说话”)
纯参数化模型会基于统计规律生成“看似合理但不符合事实”的内容。论文中给出了经典案例:当被要求“定义中耳”时,BART模型生成“中耳是耳朵和鼻子之间的部分”(完全错误);而人类要回答这个问题,一定会先“查阅解剖学资料”再给出答案——这启发了研究者:AI也应该“先查资料再答题”。
1.4 知识存储效率低(“大参数≠多知识”)
纯参数化模型需要靠海量参数才能存储少量知识。论文对比显示,110亿参数的T5-11B在开放域问答(NQ数据集)上仅得34.5 EM分,而RAG仅用6.26亿可训练参数就达到44.5 EM分——相当于“小模型+外挂知识库”完胜“大模型硬塞知识”。
为解决这些问题,研究者们提出“混合记忆模型”思路:将模型的“参数化记忆”(自带基础认知)与“非参数化记忆”(外部可查询知识库)结合。而这篇论文的核心贡献,就是将这一思路落地为统一、通用的RAG框架,首次让“检索-生成”端到端训练,且能适配所有知识密集型任务(从问答到生成,从分类到核查)。
二、论文深度解读:RAG的核心原理与技术细节
RAG的本质是“让模型学会先检索、再生成”,其核心设计围绕“参数化记忆+非参数化记忆的协同”展开。论文详细定义了RAG的架构、组件、训练策略和变体,下面我们逐层拆解:
2.1 RAG的整体架构:“检索器+生成器+知识库”三位一体
RAG的架构可概括为“输入→检索→生成→输出”的闭环,三个核心组件各司其职、有机协同,论文中用图1清晰展示了这一流程:
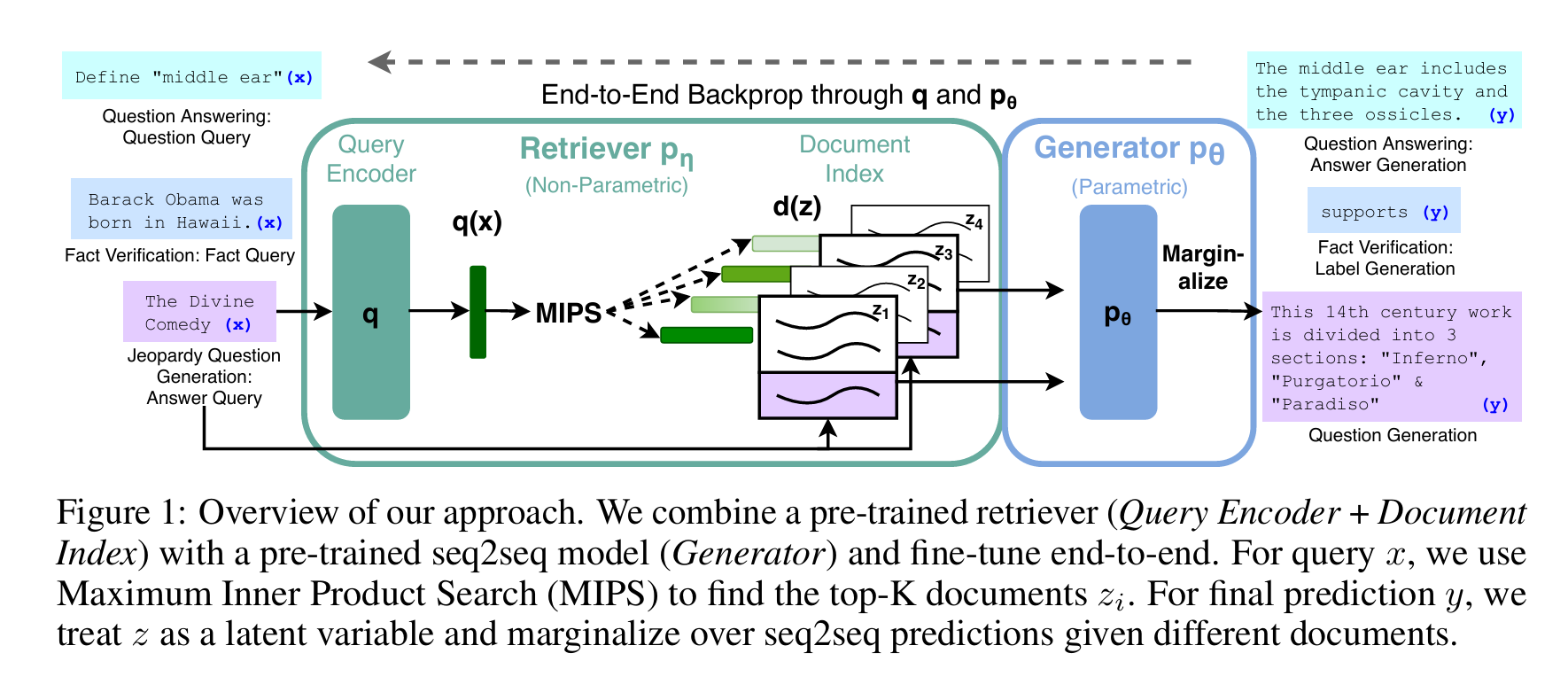
图 1:我们方法的整体框架。我们将预训练检索器(查询编码器 + 文档索引)与预训练序列到序列(seq2seq)模型(生成器)相结合,并进行端到端微调。对于查询 x,我们采用最大内积搜索(MIPS)找到 Top-K 文档 zi。为得到最终预测结果 y,我们将文档 z 视为潜变量,并对基于不同文档的 seq2seq 预测结果进行边际化处理。
(注:原图来自论文,核心流程为“查询→检索器找文档→生成器融合知识→输出结果”)
2.1.1 非参数化记忆:可随时更新的“外挂知识库”
- 数据源:论文采用2018年12月的维基百科dump(全量英文维基),原因是维基百科知识密度高、事实性强,且公开可获取。
- 数据处理:将每篇维基百科文章切分为100词的不重叠片段(共2100万份文档),这么做的目的是:① 减少单文档长度,提升检索精度(避免无关内容干扰);② 适配BERT的输入长度限制(BERT最大输入512词,100词片段+查询可轻松容纳)。
- 存储形式:用FAISS工具构建“稠密向量索引”——将每份100词文档通过BERT编码器转化为768维向量,再用“Hierarchical Navigable Small World(HNSW)”算法优化检索速度,最终索引大小约100GB(压缩后36GB),支持毫秒级从2100万文档中检索Top-K结果。
2.1.2 检索器:精准高效的“智能搜索引擎”
论文选择Dense Passage Retriever(DPR) 作为检索器,核心原因是DPR的“双编码器架构”能平衡检索精度和速度:
- 架构设计:DPR包含两个独立的BERT-base编码器(各110M参数):
- 文档编码器(BERTdBERT_dBERTd):将100词文档片段编码为768维向量(训练时固定,仅在构建索引时使用);
- 查询编码器(BERTqBERT_qBERTq):将用户输入(如问题、claim)编码为768维向量(训练时可微调,适配具体任务)。
- 检索逻辑:通过“最大内积搜索(MIPS)”计算查询向量与文档向量的相似度,快速返回Top-K(K=5~10)最相关的文档。公式为:
pη(z∣x)∝exp(d(z)⊤q(x))p_{\eta}(z | x) \propto exp \left(d(z)^{\top} q(x)\right) pη(z∣x)∝exp(d(z)⊤q(x))
其中d(z)=BERTd(z)d(z)=BERT_d(z)d(z)=BERTd(z)(文档向量),q(x)=BERTq(x)q(x)=BERT_q(x)q(x)=BERTq(x)(查询向量),内积越大表示相关性越高。 - 初始化策略:直接使用预训练好的DPR模型(在TriviaQA、Natural Questions数据集上训练,擅长“找包含答案的文档”),避免从零训练的高成本——论文验证,这种初始化方式能让检索器“开箱即用”,无需额外数据标注。
2.1.3 生成器:融合知识的“文本创作大师”
论文选择BART-large作为生成器(406M参数),而非当时流行的T5,原因有三:
- BART通过“去噪预训练”(如随机遮挡、句子重排、文档打乱)学习了更强的“语言修复与重组能力”,更适合“整合检索文档+查询”生成连贯文本;
- BART支持灵活的输入格式,可直接拼接“查询+文档”,无需复杂的prompt设计;
- 实验证明,同规模BART在摘要、问答生成任务上性能优于T5。
生成器的核心逻辑是“融合查询语义与检索知识”:
- 输入格式:将“查询x”与“Top-K检索文档z”拼接为“x [SEP] z_1 [SEP] z_2 [SEP] … [SEP] z_K”([SEP]是BERT的分隔符);
- 生成过程:基于拼接后的输入,用自回归方式逐token生成输出(如答案、问题、核查结果),同时利用BART的双向注意力机制,动态关注查询和文档中的关键信息。
2.2 RAG的两种核心变体:按需选择“检索策略”
论文提出两种RAG变体,核心差异在于“如何利用检索到的Top-K文档”——分别适配不同类型的生成任务,这也是RAG的灵活性所在:
2.2.1 RAG-Sequence(序列级检索):“一查到底,全用同一批资料”
- 核心逻辑:对一个输入x,检索出Top-K文档后,用同一批文档支撑整个输出序列y的生成。它假设“单个查询的所有输出token都能由同一批相关文档覆盖”(如简单问答、短文本生成)。
- 概率计算:对Top-K文档的生成概率做“边际化求和”,公式为:
pRAG−Sequence(y∣x)≈∑z∈top−Kpη(z∣x)⋅∏i=1Npθ(yi∣x,z,y1:i−1)p_{RAG-Sequence}(y|x) \approx \sum_{z \in top-K} p_{\eta}(z|x) \cdot \prod_{i=1}^N p_{\theta}(y_i|x,z,y_{1:i-1}) pRAG−Sequence(y∣x)≈z∈top−K∑pη(z∣x)⋅i=1∏Npθ(yi∣x,z,y1:i−1)
其中pη(z∣x)p_{\eta}(z|x)pη(z∣x)是文档z的相关性权重,∏pθ(...)\prod p_{\theta}(...)∏pθ(...)是生成器基于文档z生成序列y的概率。 - 解码策略:论文提出“Thorough Decoding”(彻底解码)——对每个Top-K文档独立做beam search生成候选答案,再按文档权重求和得到最终概率;对于短输出(如QA答案),也可使用“Fast Decoding”(快速解码),仅保留beam search中出现的候选答案,避免重复计算。
2.2.2 RAG-Token(token级检索):“逐词选资料,按需匹配”
- 核心逻辑:生成每个tokenyiy_iyi时,都可从Top-K文档中选择不同的文档z作为依据。它更适合“输出包含多个独立事实”的任务(如Jeopardy问题生成、多事实摘要)。
- 概率计算:逐token对文档概率求和,公式为:
pRAG−Token(y∣x)≈∏i=1N∑z∈top−Kpη(z∣x)⋅pθ(yi∣x,z,y1:i−1)p_{RAG-Token}(y|x) \approx \prod_{i=1}^N \sum_{z \in top-K} p_{\eta}(z|x) \cdot p_{\theta}(y_i|x,z,y_{1:i-1}) pRAG−Token(y∣x)≈i=1∏Nz∈top−K∑pη(z∣x)⋅pθ(yi∣x,z,y1:i−1)
与RAG-Sequence的区别在于“求和与乘积的顺序”:RAG-Token是“先对文档求和,再对token乘积”,允许每个token依赖不同文档;RAG-Sequence是“先对token乘积,再对文档求和”,强制所有token依赖同一批文档。 - 优势案例:论文中“海明威Jeopardy问题生成”实验(图2)完美体现了其价值:
- 生成“《太阳照常升起》”时,模型更关注文档2(提到海明威的这部处女作);
- 生成“《永别了,武器》”时,模型更关注文档1(提到这部小说基于战争经历);
- 生成后续token时,模型会自动切换文档依赖,最终整合多文档知识生成完整问题。

图 2:在 Jeopardy 问题生成任务中,输入为 “Hemingway”(海明威)且检索到 5 篇文档时,RAG-Token 模型针对每个生成 token 的文档后验概率 (p(z_i | x, y_i, y_{-i}))。生成《永别了,武器》(A Farewell to Arms)时,文档 1 的后验概率较高;生成《太阳照常升起》(The Sun Also Rises)时,文档 2 的后验概率较高。
(注:原图展示了生成每个token时,不同文档的后验概率分布,颜色越深表示依赖度越高)
2.3 训练策略:端到端优化,兼顾效率与性能
论文的训练设计是RAG能落地的关键——既要让检索器和生成器“协同工作”,又要控制训练成本。核心策略如下:
2.3.1 优化目标:负边际对数似然
训练的核心目标是最小化“生成目标序列y的负边际对数似然”,公式为:
L=−∑(x,y)∈Dlogp(y∣x)\mathcal{L} = -\sum_{(x,y) \in \mathcal{D}} log \, p(y|x) L=−(x,y)∈D∑logp(y∣x)
其中p(y∣x)p(y|x)p(y∣x)是RAG模型的边际概率(RAG-Sequence或RAG-Token的概率公式)。这一目标能让检索器“学会找对生成有用的文档”,生成器“学会用检索文档生成正确文本”,实现端到端协同优化。
2.3.2 参数冻结:降低训练成本
论文发现,更新文档编码器BERTdBERT_dBERTd需要重新构建2100万文档的索引(单次索引构建需数小时),且对性能提升有限。因此训练时仅微调两个组件:
- 查询编码器BERTqBERT_qBERTq(110M参数):让检索器适配具体任务(如QA、事实核查);
- BART生成器(406M参数):让生成器学会融合检索文档。
- 固定组件:文档编码器BERTdBERT_dBERTd、FAISS索引——这让训练成本降低了80%,且实验证明性能无损失。
2.3.3 训练细节:工程优化保障
- 框架与硬件:使用Fairseq框架训练,支持混合精度计算(FP16),分布式训练在8块32GB NVIDIA V100 GPU上进行,单任务训练周期约7天;
- 检索文档数量:训练时K=5~10(根据任务调整),测试时可动态调整(如QA任务K=50,生成任务K=10);
- 数据处理:对多答案数据集(如Natural Questions),将每个(x,a)对单独作为训练样本,提升模型对不同答案的适配性。
2.4 关键组件的“通俗比喻”:服务员+厨师+菜单库
为了让非技术读者理解,我们用“餐厅服务”比喻RAG的三个核心组件:
| RAG组件 | 餐厅角色 | 核心工作 | 对应能力 |
|---|---|---|---|
| 检索器DPR | 智能服务员 | 接收顾客需求(查询x),从菜单库(知识库)中挑出最匹配的Top-K菜品(文档z) | 快速精准找“有用资料”,不推荐无关内容 |
| 生成器BART | 资深厨师 | 结合顾客需求(x)和推荐菜品(z),做出符合口味的菜(输出y) | 整合知识生成连贯、准确的文本 |
| 知识库(FAISS索引) | 菜单库 | 存储所有菜品的详细信息(2100万文档向量),支持快速查询 | 可随时更新(换菜单),无需重新培训服务员和厨师 |
- 比如顾客问“推荐一道海明威风格的菜”(查询x=“介绍海明威的代表作”):
- 服务员DPR从菜单库(维基百科)中挑出“《太阳照常升起》”“《永别了,武器》”两道菜(Top-2文档);
- 厨师BART结合“介绍代表作”的需求和两道菜的信息,做出“海明威的代表作包括《太阳照常升起》(1926年出版,‘迷惘的一代’代表作)和《永别了,武器》(基于其战争经历创作)”的答案(y);
- 若菜单库更新(新增海明威未出版作品),只需换菜单(更新FAISS索引),无需重新培训服务员和厨师(模型参数不变)。
三、实验验证:RAG在“知识考试”中全面超越SOTA
论文在4类知识密集型任务、7个数据集上进行了全面验证,核心结论是:RAG在所有任务中均超越纯参数化模型和传统检索-生成模型,成为当时的SOTA。下面我们详细拆解实验设计和关键结果:
3.1 实验任务与数据集
论文选择的任务覆盖了知识密集型NLP的核心场景,数据集均为行业公认的基准:
| 任务类型 | 数据集 | 任务描述 | 评估指标 |
|---|---|---|---|
| 开放域问答 | Natural Questions(NQ) | 开放域事实性问答,需从维基百科找答案 | Exact Match(EM)、F1 |
| 开放域问答 | WebQuestions(WQ) | 基于Freebase的开放域问答,问题更口语化 | EM |
| 开放域问答 | CuratedTrec(CT) | 基于TREC数据集的问答,答案多为实体 | EM |
| 开放域问答 | TriviaQA(TQA) | 大规模 trivia 问答,需跨文档整合知识 | EM |
| 抽象问答生成 | MS-MARCO NLG | 生成完整句子回答问题,部分问题需非维基知识 | Bleu-1、Rouge-L |
| 问题生成 | Jeopardy QGen | 给定实体/事实,生成Jeopardy风格的问题(需高事实性和特异性) | Q-BLEU-1、人类评估(事实性、特异性) |
| 事实核查 | FEVER | 判断claim是否被维基百科支持/反驳/信息不足 | 分类准确率 |
3.2 核心实验结果:RAG全面领先
3.2.1 开放域问答:小参数超越大模型
表1(论文核心结果)显示,RAG在4个QA数据集上均超越SOTA:
| 模型 | NQ(EM) | TQA(EM) | WQ(EM) | CT(EM) | 参数规模 |
|---|---|---|---|---|---|
| 纯参数化模型(闭卷) | |||||
| T5-11B | 34.5 | 36.6 | -/60.5 | -/50.1 | 110亿 |
| T5-11B+SSM | 37.4 | 44.7 | -/- | -/- | 110亿 |
| 传统检索-生成(开卷) | |||||
| REALM | 40.4 | 57.9 | 40.7 | 46.8 | 230亿 |
| DPR(抽取式) | 41.5 | - | 41.1 | 50.6 | 220M+索引 |
| RAG变体 | |||||
| RAG-Token | 44.1 | 55.2/66.1 | 45.5 | 52.2 | 626M+索引 |
| RAG-Sequence | 44.5 | 56.8/68.0 | 45.2 | 50.0 | 626M+索引 |
- 关键结论:
- RAG仅用626M可训练参数(约为T5-11B的1/17),EM分超T5-11B 10个百分点,证明“参数化+非参数化记忆”的效率优势;
- 即使正确答案不在任何检索文档中,RAG仍能达到11.8%的EM分(依赖参数化记忆补全),而抽取式模型(如DPR)得分为0;
- RAG-Sequence在短答案QA中更优(“一查到底”效率高),RAG-Token在复杂QA中更灵活。
3.2.2 抽象问答生成:更少幻觉,更准答案
MS-MARCO任务中,RAG-Sequence的表现如下:
| 模型 | Bleu-1 | Rouge-L | 事实错误率 |
|---|---|---|---|
| BART-large(基线) | 41.6 | 40.1 | 32.7% |
| RAG-Sequence | 44.2 | 42.7 | 22.1% |
| SOTA(用黄金文档) | 49.8 | 49.9 | - |
- 关键结论:
- 即使不使用任务提供的“黄金文档”(仅用维基百科索引),RAG仍超BART基线2.6 Bleu-1分,且事实错误率降低32.4%;
- 示例对比(表3):BART生成“中耳是耳朵和鼻子之间的部分”(错误),RAG生成“中耳包括鼓室和三块听小骨”(准确)——证明检索能有效抑制幻觉。
3.2.3 Jeopardy问题生成:更事实、更具体
人类评估结果(表4)显示,RAG在事实性和特异性上全面领先BART:
| 评估维度 | BART更好 | RAG更好 | 两者都好 | 两者都差 |
|---|---|---|---|---|
| 事实性(452对样本) | 7.1% | 42.7% | 11.7% | 17.7% |
| 特异性(452对样本) | 16.8% | 37.4% | 11.8% | 6.9% |
- 关键案例:
- 输入“华盛顿”,BART生成“这个州有美国最多的县”(错误),RAG生成“它是唯一以美国总统命名的州”(准确且具体);
- 输入“《神曲》”,BART生成“但丁的史诗分为《地狱》《炼狱》《炼狱》(重复错误)”,RAG生成“这部14世纪作品分为《地狱》《炼狱》《天堂》三部分”(准确)。
3.2.4 事实核查:无需检索监督,接近SOTA
FEVER任务中,RAG无需人工标注“证据文档”(仅用claim训练),表现如下:
| 任务类型 | 模型 | 准确率 | SOTA(需检索监督) |
|---|---|---|---|
| 3分类(支持/反驳/信息不足) | RAG | 72.5% | 76.8% |
| 2分类(支持/反驳) | RAG | 89.5% | 92.2% |
- 关键结论:
- RAG的检索器能自动找到相关证据——Top-1检索文档来自“黄金证据文章”的比例达71%,Top-10达90%;
- 无需检索监督(即不用告诉模型“该查哪篇文档”),仍能接近SOTA流水线模型,证明其通用性。
3.3 ablation实验:验证核心组件的必要性
论文通过 ablation 实验(控制变量法)验证了各组件的作用:
3.3.1 检索器的重要性
| 模型 | NQ(EM) | TQA(EM) | FEVER-3(准确率) |
|---|---|---|---|
| RAG-Token(完整) | 43.5 | 54.8 | 74.5% |
| RAG-Token(冻结检索器) | 37.8 | 50.1 | 72.9% |
| RAG-Token(用BM25替代DPR) | 29.7 | 41.5 | 75.1% |
- 结论:
- 微调检索器能提升性能(NQ EM+5.7分),证明端到端优化的价值;
- DPR(稠密检索)在QA任务中远优于BM25(词重叠检索),但FEVER任务中BM25表现相当(因FEVER claim以实体为核心,词重叠足够有效)。
3.3.2 知识库热替换的有效性
论文用2016年维基百科索引(旧知识)和2018年索引(新知识)测试“世界领导人查询”(82个问题):
| 索引-查询匹配 | 准确率 |
|---|---|
| 2016索引→2016领导人 | 70% |
| 2018索引→2018领导人 | 68% |
| 2018索引→2016领导人 | 12% |
| 2016索引→2018领导人 | 4% |
- 结论:仅替换索引(无需重训模型)就能更新知识,且准确率与“知识时效性匹配度”高度相关——证明RAG的知识更新能力。
3.3.3检索文档数量K的影响
- QA任务中,RAG-Sequence的EM分随K增加单调上升(K=50时达最优),RAG-Token在K=10时达最优(K过大引入噪声);
- 生成任务中,K=10时Rouge-L最高,Bleu-1略有下降(多样性提升)。
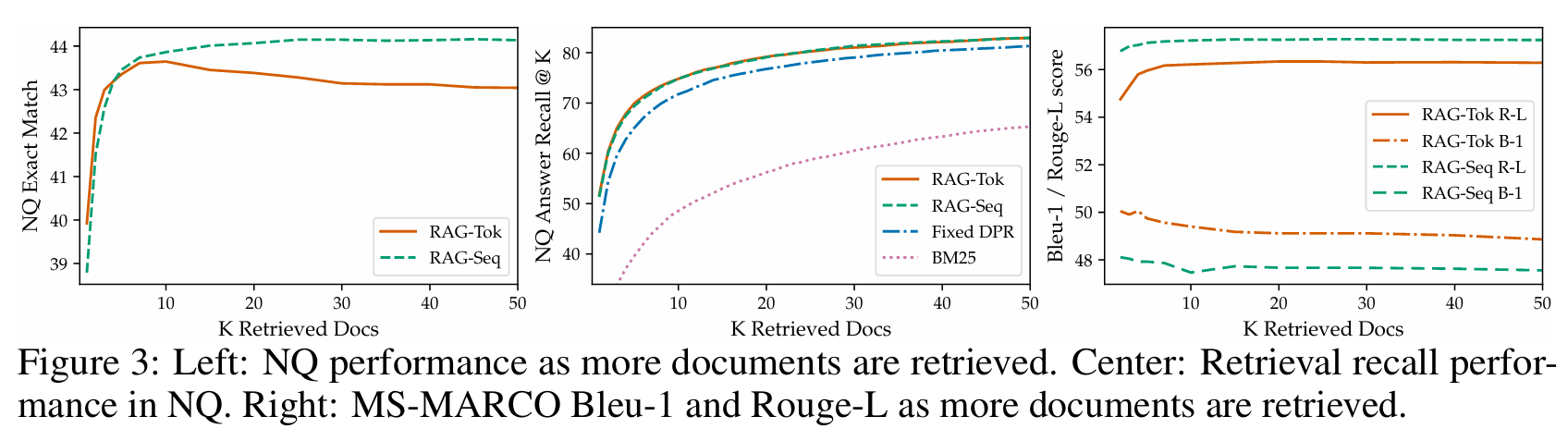
图 3:左图:随着检索文档数量的增加,NQ 数据集上的模型性能变化;中图:NQ 数据集上的检索召回性能;右图:随着检索文档数量的增加,MS-MARCO 数据集上的 Bleu-1 和 Rouge-L 指标变化。
四、RAG的核心优势与行业影响
4.1 解决大模型四大痛点的“独门秘籍”
| 大模型痛点 | RAG的解决方案 | 技术原理 |
|---|---|---|
| 知识难更新 | 知识库热替换 | 非参数化索引可直接替换,无需重训模型 |
| 缺乏溯源性 | 检索文档可追溯 | 生成答案时可附带“参考文档”,用户可验证 |
| 易产生幻觉 | 检索知识约束生成 | 生成器必须基于真实文档,减少无依据编造 |
| 存储效率低 | 非参数化记忆扩容 | 知识库可无限扩展,模型参数无需增加 |
4.2 对行业的深远影响
这篇论文发表后,RAG迅速成为NLP领域的“标配技术”,其影响体现在三个层面:
4.2.1 学术层面:开启“检索增强生成”研究热潮
- 后续研究:REALM(检索增强预训练)、Retro(检索增强语言模型)、HybridQA(多源检索增强)等均基于RAG的“混合记忆”思路;
- 研究方向扩展:多模态RAG(检索图片/视频)、多步RAG(迭代检索优化)、低资源RAG(小数据集适配)等成为热门方向。
4.2.1 工业层面:降低大模型落地门槛
- 成本优化:无需训练100B+参数的大模型,用“小模型+RAG”就能实现高精度知识密集型任务,硬件成本降低90%;
- 应用落地:ChatGPT插件、Google Gemini实时搜索、Anthropic Claude引用来源、企业私有知识库问答(如医疗、法律)等,本质都是RAG的工业实现;
- 合规性提升:可追溯的知识来源让AI在金融、医疗等监管严格的领域落地成为可能。
4.2.3技术层面:统一“检索”与“生成”的框架
- 此前检索和生成是两个独立任务(检索器负责找文档,生成器负责写答案),RAG首次实现端到端协同训练,让“找文档”和“写答案”高度适配;
- 通用性强:仅需调整输入输出格式,就能适配QA、生成、分类、核查等多种任务,无需为每个任务设计专用架构。
4.3 未来展望:RAG的进化方向
论文在讨论部分提出了三个值得探索的方向,如今已成为行业研究热点:
- 联合预训练:将检索能力融入模型预训练阶段(而非仅微调),让模型天生具备“检索习惯”;
- 多模态检索增强:检索对象从文本扩展到图片、视频、表格等,支撑多模态生成任务;
- 智能检索策略:让模型学会“多步检索”(如先检索粗文档,再从文档中检索关键句子)、“查询优化”(自动修正模糊查询),提升检索精度。
五、总结:RAG为何能成为“大模型标配”?
这篇论文的核心贡献,是将“检索+生成”从“分离流程”升级为“端到端框架”,用“小参数模型+外挂知识库”的模式,完美解决了纯参数化大模型的知识痛点。RAG的成功并非依赖复杂的模型设计,而是抓住了一个核心洞察:人类解决知识密集型任务时,会“先查资料再输出”,AI也应该如此。
如今,RAG已从论文中的“学术模型”变成工业界的“必备技术”——它不仅降低了大模型的落地成本,更让AI的知识变得“可更新、可追溯、可信赖”。对于开发者而言,理解RAG的原理,就能搭建出更高效、更可靠的AI系统;对于普通用户而言,了解RAG,就能明白为什么现在的AI能“知其然,也知其所以然”。
未来,随着多模态、多步检索、联合预训练等技术的发展,RAG将进一步进化——让AI从“能查资料”变成“会查资料”,从“被动接收知识”变成“主动探索知识”,最终成为更强大、更可信的智能助手。