从一到无穷大 #57:Snowflake的剪枝方案
 本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
文章目录
- 引言
- Top-k
- Limit
- Filter
- 总结
引言
正如[4]中提到的:
The fastest way of processing data is to not process it at all.
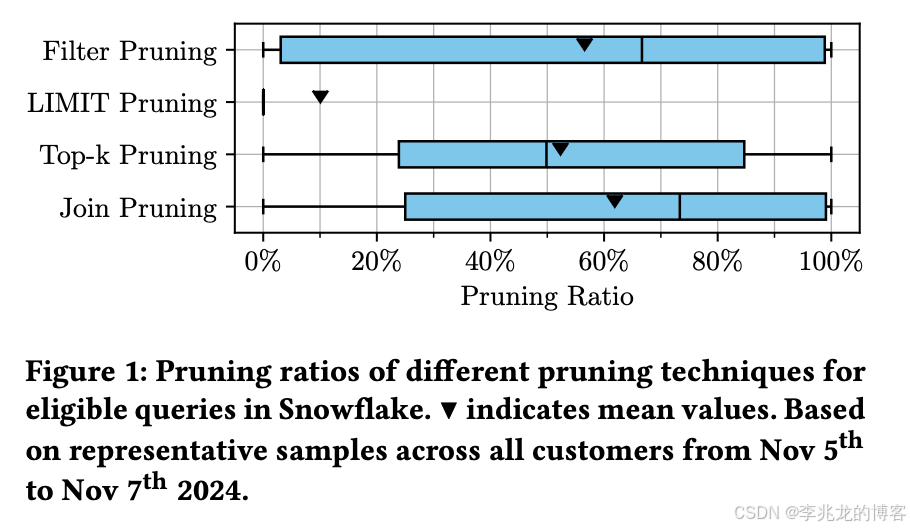
在Snowflake中提到的剪枝算法中,我关心Filter,Limit,Top-k三种形式的剪枝。
当然无论采用何种剪枝技术,可跳过的数据分区数量主要取决于数据的分布方式(例如通过排序或聚类)以及具体的工作负载,基于工作负载特征进行数据布局优化和自适应分区策略以实现更好的剪枝。
在本篇文章中,Snowflake的剪枝主要在分区级别执行,当然对于Parquet格式的表,剪枝则发生在文件、RowGroup和Page级别。Snowflake基于为每个分区维护的轻量级元数据执行最小/最大剪枝,这与zone-maps类似。通过将此元数据与查询的谓词进行比较,数据库引擎能够高效识别不包含相关数据的分区,从而完全跳过这些分区。
Top-k
这里没有图,我用简单易懂的语言来组织一下;
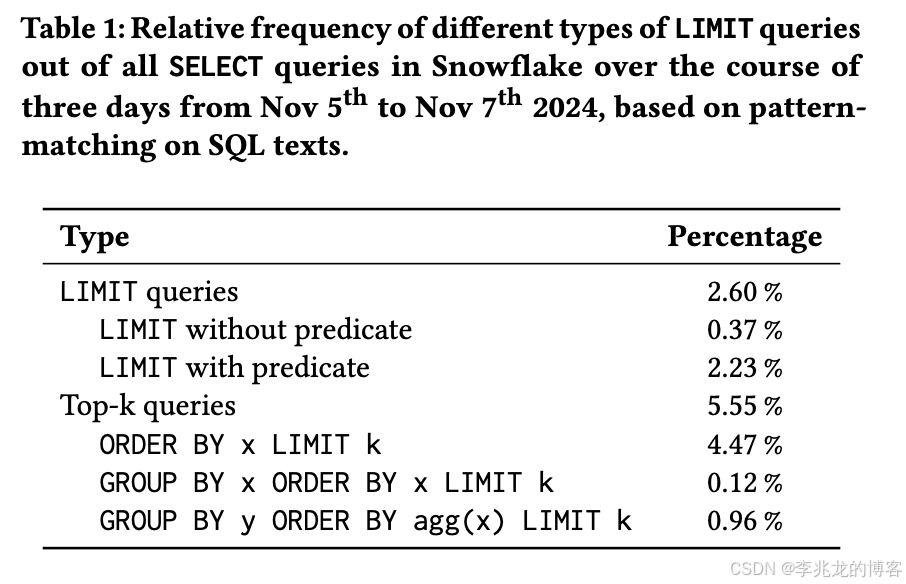
Top-k在Snowflake的场景中占到了现网查询的5.55%;在我们运营的某个大客户场景中,甚至达到了50%以上,优化的收益率是很高的。
首先为什么现有的计算引擎算Top-k很慢?
想想看,首先数据排布是有序的,一共10个shard,每个shard100个文件,每个文件里面有1000条符合查询条件的行,但是limit 1000。用户的查询自然是Top算子底下是一个TableScan,每个文件作为一个split。静态剪枝最大的问题是不能假设底层数据的分布。那此时如果Top和TableScan的设计是独立的,不考虑runtime优化,就需要将全部的Split载入,然后取前1k条,非常非常慢。
文中给的解决思路其实是一种很好的解决思路,
即类似于The Threshold Algorithm 和The WAND Algorithm,总结一下就是提前终止。
使用排序最靠前,即最有可能产生Top-k的文件先addSplit,动态维护堆的边界,然后基于堆的下界对后续的Split执行去重,在最优情况下,只需要读取第一个文件即可完成整个查询。
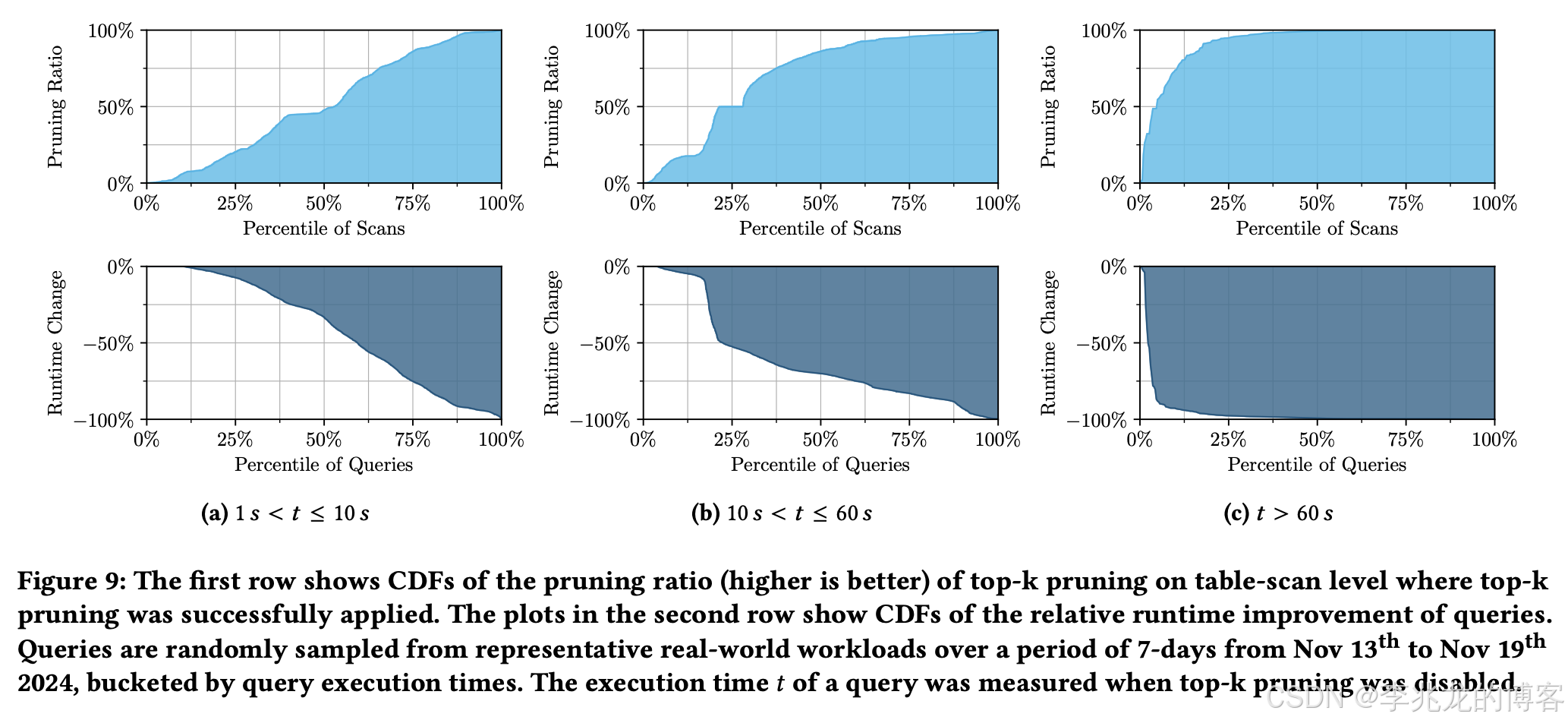
这个数据是可信的,我们之前对于Top-k的优化就是静态的,做不到这种效果,但是也可以降低一个数量级,很明显这种思路在没有历史数据写入的情况下剪枝率非常高。
文章还提到了边界值的预先初始化。如果元数据包含每个分区的行数以及某列是否包含空值等细节,我们就可以在查询编译期间预先计算出初始边界值,从而从第一个分区开始就能进行剪枝。小Trick,和前面的优化比起来很小。
Limit
其创新点在于引入 “完全匹配分区(Fully-Matching Partitions)” 概念 —— 指所有行均满足查询谓词的微分区,通过 “二次剪枝” 识别:
- 首次剪枝:用原始谓词(如species LIKE ‘Alpine%’ AND s >= 50)排除无匹配数据的分区,剩余为 “部分匹配分区”;
- 二次剪枝:用反向谓词(如species NOT LIKE ‘Alpine%’ OR s < 50)扫描部分匹配分区(如果 S 是完全匹配分区(所有行都满足 P),那么根据矛盾律,S 中所有行都不满足 ¬P。因此,S 中不存在任何一行满足 ¬P),若某分区无任何行满足反向谓词,则标记为 “完全匹配分区”;
若所有完全匹配分区的总行数≥LIMIT 值(如 LIMIT 3),则仅扫描这些分区即可满足结果需求,无需访问部分匹配分区;若总行数 < LIMIT 值,则优先扫描完全匹配分区,再补充扫描部分匹配分区;
比较小的Trick。
Filter
基于过滤器的 Pruning 主要介绍了两种方式:
- 复杂表达式处理:对含函数或多列运算的谓词(如IF(unit=‘feet’, altit * 0.3048, altit) > 1500),通过 “范围推导” 生成表达式的 min/max 范围 —— 例如altit列的原始范围为 934-7674,转换为米后范围为 284.68-2339.04,再结合unit列的取值范围扩展为 284.68-7674,最终判断与 “>1500” 的重叠性;
- 模糊匹配改写:对 LIKE 等模糊查询(如name LIKE ‘Marked-%-Ridge’),采用 “不精确过滤改写” 策略 —— 将谓词放宽为STARTSWITH(‘Marked-’),通过字符串列的 min/max 范围(如name列的范围为 “Basecamp-…” 至 “Unmarked-…”)判断是否可能匹配,实现剪枝;
除此之外论文还讨论了Balancing Compile-Time and Runtime Filter Pruning; 本质是认为编译时剪枝会给编译过程带来额外开销,对于具有复杂且深度嵌套谓词的超大型表上的查询而言,这种开销可能会高到令人难以承受(比如1000文件,5000查询条件)
为了保持较快的查询执行时间,Snowflake采用了两项关键策略:
- 在分区剪枝期间ReOrder Filter的顺序,以优先处理快速且有效的过滤器;
- 对于在编译时被证明无效或缓慢的过滤器,停止对其进行剪枝,并可以选择将其执行推迟到高度并行化的虚拟仓库,从而将其评估推到查询执行阶段。
我对这里的优化有没有用持怀疑态度,下面是Snowflake的BI数据场景中where条件的深度,我不认为这种数量级下作全量剪枝有什么问题。
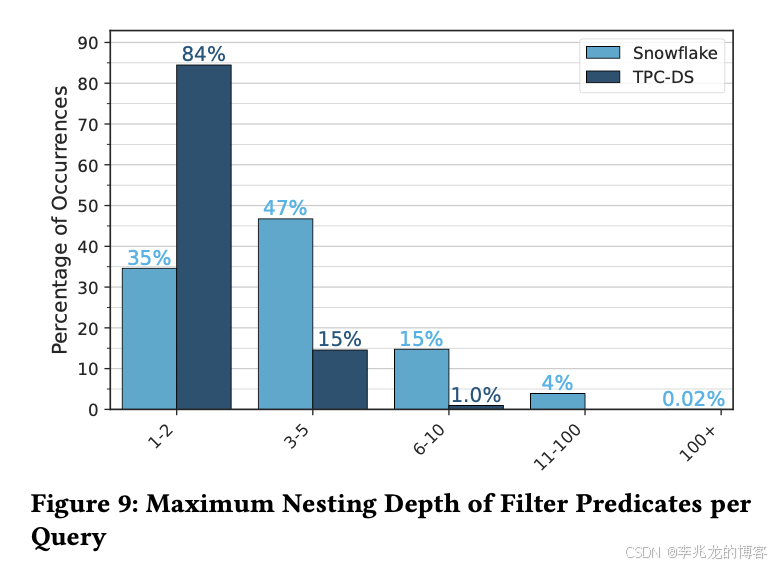
之前我们在一种业务场景下遇到了常态1500+的查询条件,在对SQL执行优化的时候就是全条件作分区过滤,还附带查询改写以减少到每个分区的查询条件,其实没有多慢。这里Balancing Compile-Time and Runtime Filter Pruning我猜测大概率是针对于非常少的查询做的Trick优化。
总结

Snowflake的这篇文章很有工程实践价值。上面这张图阐述了不同剪枝方案的收益查询百分比,这个就比较依赖于负载了。优化其实当时是要从瓶颈开始,但是随着运营的时间越久,其实最后很多时间都投入到bad case的解决,这其实也是所谓的经验:即业务特征与bad case。也能让人在设计中考虑到更多方面。
[2]中描述的BI工作负载也很有意思,揭示了测试集和现网环境的巨大差异,这一点在时序数据库远比论文中提到的严峻的多。
正在火锅店门口排队,原本打算再润色一下文章的,但是还有两桌就到我了,这篇文章就到这吧。
参考:
- The Snowflake Elastic Data Warehouse sigmod 2016
- Workload Insights From The Snowflake Data Cloud: What Do Production Analytic Queries Really Look Like? sigmod 2025
- Pruning in Snowflake: Working Smarter, Not Harder sigmod 2025
- 从一到无穷大 #55 提升Lakehouse查询性能:数据层面