预训练语言模型(Pre-trained Language Model, PLM)介绍
预训练语言模型(Pre-trained Language Model, PLM)
一、预训练语言模型核心定义与价值
预训练语言模型是自然语言处理(NLP)领域的里程碑技术,其核心思想是先在大规模无标注文本上进行通用语言知识学习(预训练阶段),再针对具体下游任务进行微调(微调阶段),实现“一次预训练,多任务复用”的高效开发模式。
核心价值
- 突破数据依赖:传统NLP方法需为每个任务标注大量数据,而预训练模型通过无标注文本学习通用语言规律,大幅降低下游任务的标注成本。
- 提升任务效果:预训练阶段积累的语法、语义、常识等知识,能为下游任务提供强大基础,使模型在文本分类、命名实体识别等任务中轻松达到State-of-the-Art(SOTA)水平。
- 统一技术框架:无论是文本生成、问答还是翻译任务,均可基于同一预训练模型进行微调,避免为每个任务单独设计模型结构,简化NLP技术栈。
二、预训练方法与传统方法对比
预训练模型的“Pre-train + Fine-tune”模式,彻底改变了传统NLP的开发流程,两者在数据利用、训练效率和泛化能力上存在显著差异:
| 对比维度 | 预训练方法(Pre-train + Fine-tune) | 传统方法(Task-specific Training) |
|---|---|---|
| 数据使用 | 1. 先利用海量无标注文本完成预训练; 2. 再用少量标注数据微调下游任务 | 直接使用任务专属标注数据训练,无标注数据利用率极低 |
| 训练流程 | 两阶段:通用预训练 → 任务微调,可复用预训练模型 | 单阶段:为每个任务单独设计模型、训练参数,无复用性 |
| 泛化能力 | 预训练学习通用语言规律,微调后可快速适配新任务 | 模型仅适配特定任务,换任务需重新训练,泛化能力弱 |
| 标注成本 | 下游任务仅需少量标注数据,大幅降低成本 | 每个任务需大量标注数据,成本高、周期长 |
| 代表模型 | BERT、GPT、RoBERTa等 | 传统CNN/RNN模型、SVM等机器学习模型 |
关键差异解析
传统方法如同“为每个任务单独造一辆车”,需从头设计结构、组装零件;而预训练方法则是“先造好通用底盘(预训练模型),再根据需求加装座椅、方向盘(微调)”,效率和复用性大幅提升。
三、核心预训练技术:以BERT为例
BERT(Bidirectional Encoder Representations from Transformers)是预训练语言模型的标杆,其预训练过程通过两个核心任务实现通用语言知识的学习,同时基于Transformer架构保障建模能力。
1. BERT预训练的两大核心任务
(1)掩码语言模型(Masked Language Model, MLM)
- 定义:模拟“完形填空”任务,随机掩盖文本中的部分词汇,让模型预测被掩盖的原词,强制模型学习上下文双向语义关联。
- 具体流程:
- 从输入文本中随机选择15%的词汇作为掩码对象;
- 对选中的词汇,80%概率替换为特殊符号 [MASK][MASK][MASK],10%概率替换为随机词汇,10%概率保留原词(避免模型仅依赖 [MASK][MASK][MASK] 符号,提升泛化性);
- 模型通过上下文信息预测被掩盖位置的原词,计算预测误差并反向更新参数。
- 示例:
- 输入序列(掩码后):The man went to [MASK] store with [MASK] dog
- 目标序列(需预测): the、his
- 核心作用:让模型学习双向上下文语义,解决传统自回归模型(如GPT)仅能单向建模的局限,更适合语义理解类任务。
(2)下一句预测(Next Sentence Prediction, NSP)
- 定义:判断两个句子是否为连续的上下文(即第二句是否是第一句的下一句),让模型学习句子级别的语义关联和逻辑关系。
- 具体流程:
- 从语料中抽取句子对(A, B),50%概率B是A的真实下一句(标签为TrueTrueTrue),50%概率B是随机抽取的无关句子(标签为FalseFalseFalse);
- 在句子对前添加特殊符号[CLS][CLS][CLS](用于分类任务的聚合特征),在A和B之间添加[SEP][SEP][SEP](句子分隔符);
- 模型通过[CLS][CLS][CLS]位置的输出特征预测句子对的标签(TrueTrueTrue/FalseFalseFalse),学习句子间的逻辑关系。
- 示例:
- 正例(标签TrueTrueTrue):[CLS]师徒四人历经艰险[SEP]取得真经[SEP][CLS] 师徒四人历经艰险 [SEP] 取得真经 [SEP][CLS]师徒四人历经艰险[SEP]取得真经[SEP]
- 反例(标签FalseFalseFalse):[CLS]师徒四人历经艰险[SEP]火烧赤壁[SEP][CLS] 师徒四人历经艰险 [SEP] 火烧赤壁 [SEP][CLS]师徒四人历经艰险[SEP]火烧赤壁[SEP]
- 核心作用:帮助模型理解句子间的连贯性,为文本匹配、问答等依赖句子关系的任务打下基础。
2. BERT的核心优势:动态文本表征
BERT的本质是动态文本表征模型,能根据上下文生成词汇的动态向量,这与传统静态词向量(如Word2Vec)有本质区别:
| 特征 | BERT动态表征 | Word2Vec静态表征 |
|---|---|---|
| 向量生成逻辑 | 词汇向量随上下文变化(“苹果”在“吃苹果”和“苹果手机”中向量不同) | 每个词汇对应唯一固定向量(“苹果”在任何语境下向量相同) |
| 语义捕捉能力 | 能准确区分多义词、歧义句,贴合真实语言逻辑 | 无法处理多义词,歧义句语义表征易混淆 |
| 下游任务适配性 | 无需额外调整词向量,可直接用于各类NLP任务 | 需针对任务额外优化词向量,适配性弱 |
| 示例 | “我喜欢吃苹果”→“苹果”向量偏向“水果”;“苹果和华为哪个好”→“苹果”向量偏向“品牌” | 无论“吃苹果”还是“苹果手机”,“苹果”向量完全相同 |
四、BERT的技术基石:Transformer架构
BERT的模型主体基于Transformer的Encoder层(编码器)构建,Transformer通过自注意力机制(Self-Attention)和多层神经网络,实现对文本语义的深度建模。
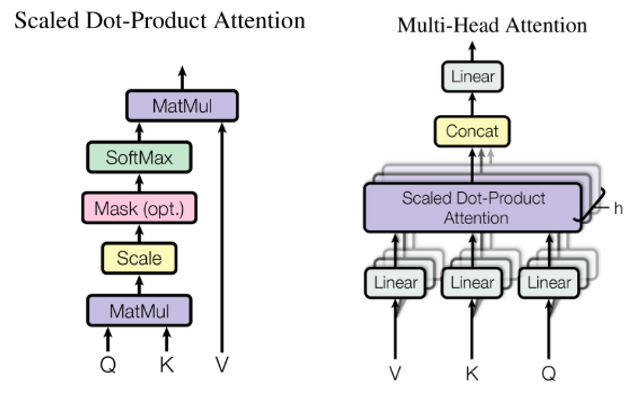
1. Transformer Encoder的核心结构
Transformer Encoder采用“多层堆叠”设计,每层包含两个关键子层:多头自注意力层(Multi-Head Self-Attention) 和前馈神经网络层(Feed-Forward Neural Network, FFN),且每个子层后均添加“残差连接(Residual Connection)”和“层归一化(Layer Normalization)”。
(1)输入嵌入层(Embedding Layer)
BERT的输入嵌入是三种嵌入的加和,确保模型同时捕捉词汇、句子边界和语序信息:
-
Token Embedding:词汇本身的嵌入向量,将每个词汇映射到低维稠密空间(如768维);
-
Segment Embedding:句子来源嵌入,用于区分句子对中的两个句子(如句子A用EAE_AEA,句子B用EBE_BEB);
-
Position Embedding:位置嵌入,为每个词汇添加位置信息(Transformer本身无语序感知能力,需通过位置嵌入补充)。
-
示例(输入:[CLS]mydogiscute[SEP]helikesplaying[SEP][CLS] my dog is cute [SEP] he likes playing [SEP][CLS]mydogiscute[SEP]helikesplaying[SEP]):
嵌入类型 对应向量 作用 Token Embedding E[CLS]E_[CLS]E[CLS], EmyE_myEmy, EdogE_dogEdog… 捕捉词汇本身语义 Segment Embedding EAE_AEA, EAE_AEA, EAE_AEA… EBE_BEB, EBE_BEB… 区分句子A和句子B Position Embedding E0E_0E0, E1E_1E1, E2E_2E2… E10E_10E10 标记词汇在序列中的位置 三种嵌入加和后,需经过Layer Normalization处理,得到最终的输入特征矩阵。
(2)多头自注意力层(Multi-Head Self-Attention)
自注意力机制是Transformer的核心,其作用是让模型在处理每个词汇时,自动关注序列中其他相关词汇的信息,捕捉词汇间的语义关联;“多头”则是通过多个并行的注意力头,从不同角度捕捉关联信息。
-
单头自注意力计算流程:
- 将输入特征矩阵 XXX 分别与三个可学习参数矩阵 WQW_QWQ(Query,查询)、WKW_KWK(Key,键)、WVW_VWV(Value,值)相乘,得到QQQ、KKK、VVV矩阵;
- 计算注意力分数:Score=Q×KT/dkScore = Q × K^T / \sqrt{d_k}Score=Q×KT/dk(dkd_kdk是QQQ/KKK的维度,除以dk{\sqrt{d_k}}dk是为了避免分数过大导致Softmax梯度消失,这个场景出现在 “自己与自己进行计算时,相似性会很大,因此计算数值也会很大” );
- 对注意力分数进行Softmax归一化,得到注意力权重(权重越高,说明该位置词汇与当前词汇关联越强);
- 用注意力权重对VVV矩阵加权求和,得到单头自注意力输出:Attention(Q,K,V)=Softmax(Score)×VAttention(Q,K,V) = Softmax(Score) × VAttention(Q,K,V)=Softmax(Score)×V。
-
多头自注意力计算流程:
- 将QQQ、KKK、VVV分别拆分为hhh个并行的子矩阵(如h=12h=12h=12,即12个注意力头);
- 每个子矩阵独立计算单头自注意力,得到hhh个输出子矩阵;
- 将hhh个输出子矩阵拼接,再与参数矩阵WOW_OWO相乘,得到多头自注意力的最终输出。
-
示例(句子“今天天气不错”的注意力分数矩阵):
当前词 今 天 天 气 不 错 今 0.12 0.123 -1.324 0.571 -0.669 0.982 天 … … … … … … (注:分数越高,代表当前词与对应词的关联越强)
(3)前馈神经网络层(FFN)
多头自注意力层输出的特征矩阵,需经过前馈神经网络进一步处理,增强模型的非线性拟合能力。其结构为:
- 第一层:线性变换 + ReLU激活函数,公式:FFN1(x)=ReLU(x×W1+b1)FFN1(x) = ReLU(x × W_1 + b_1)FFN1(x)=ReLU(x×W1+b1);
- 第二层:线性变换,公式:FFN2(x)=x×W2+b2FFN2(x) = x × W_2 + b_2FFN2(x)=x×W2+b2;
- (注:每个位置的词汇特征独立处理,无序列依赖)。
(4)残差连接与层归一化
为解决深层网络训练中的梯度消失问题,Transformer在每个子层(自注意力层、FFN层)后添加:
- 残差连接:将子层输入与子层输出直接相加(Output=Input+SubLayer(Input)Output = Input + SubLayer(Input)Output=Input+SubLayer(Input)),确保梯度能直接反向传播;
- 层归一化:对残差连接后的特征进行归一化(LayerNorm(Output)LayerNorm(Output)LayerNorm(Output)),使特征分布更稳定,加速训练。
2. Transformer Encoder的整体流程
输入序列 → 嵌入层(Token+Segment+Position)→ Layer Normalization → 多头自注意力层 → 残差连接+Layer Normalization → FFN层 → 残差连接+Layer Normalization → 输出特征矩阵(用于下游任务)。
五、BERT在下游任务中的应用
BERT通过微调(Fine-tune)可适配几乎所有NLP任务,根据任务类型的不同,微调方式主要分为三类:
1. 文本分类任务(如情感分析、MNLI)
- 任务目标:判断文本属于哪个类别(如“正面”/“负面”、“支持”/“反对”);
- 微调方式:
- 将文本输入BERT,得到[CLS][CLS][CLS]位置的输出特征(该特征聚合了整个文本的语义信息);
- 在[CLS][CLS][CLS]特征后添加一个分类器(如线性层+Softmax);
- 使用标注的分类数据训练分类器,同时微调BERT部分参数;
- 示例:判断“这部电影太精彩了”的情感类别为“正面”。
2. 序列标注任务(如命名实体识别NER、词性标注)
- 任务目标:为文本中的每个词汇标注类别(如“人名”、“地名”、“动词”);
- 微调方式:
- 将文本输入BERT,得到每个词汇(Token)的输出特征;
- 为每个Token的特征添加一个分类器;
- 使用标注的序列数据训练分类器,学习每个Token的类别映射;
- 示例:对“北京是中国的首都”标注:“北京(地名)”、“中国(地名)”。
3. 文本匹配任务(如问答SQuAD、文本相似度)
- 任务目标:判断两个文本的关系(如“问答匹配”、“文本是否相似”);
- 微调方式(以SQuAD问答为例):
- 将问题(Question)和段落(Paragraph)拼接为[CLS]问题[SEP]段落[SEP][CLS] 问题 [SEP] 段落 [SEP][CLS]问题[SEP]段落[SEP],输入BERT;
- 在BERT输出层后添加两个线性层,分别预测答案在段落中的“起始位置”和“结束位置”;
- 使用标注的问答数据(问题+段落+答案位置)训练位置预测器;
- 示例:问题“中国的首都是哪里?”,段落“北京是中国的首都…”,预测答案起始位置为“北”,结束位置为“京”。
六、BERT的优势与局限性
1. 核心优势
- 双向语义建模:MLM任务让模型同时利用上下文信息,语义理解更准确;
- 海量数据利用:预训练阶段可使用TB级无标注文本,学习更全面的语言知识;
- 任务适配性强:微调方式简单,无需大幅修改模型结构即可适配多任务;
- 效果显著:在11个NLP任务中刷新SOTA,成为后续预训练模型的设计基准。
2. 主要局限性
- 训练成本高:预训练需消耗大量计算资源(如BERT-Base需在TPU上训练数天),普通开发者难以复现;
- 生成式任务弱:BERT是Encoder-only结构,无生成能力,无法直接用于文本生成、机器翻译等任务;
- 参数量大:BERT-Base参数量约110M,BERT-Large约340M,部署时对硬件要求较高;
- 依赖微调数据:若下游任务无标注数据,BERT的效果会大幅下降(需结合零样本/少样本学习优化)。
七、预训练技术的发展趋势
BERT之后,预训练技术不断迭代,主要发展方向包括:
1. 模型结构优化
- Decoder-only结构:如GPT系列,专注于文本生成任务,通过自回归预训练实现流畅的长文本生成;
- Encoder-Decoder结构:如T5、BART,结合Encoder的语义理解能力和Decoder的生成能力,适配翻译、摘要等生成式任务。
2. 预训练任务改进
- 取消NSP任务:如RoBERTa,研究发现NSP任务对模型效果提升有限,取消后通过增加预训练数据量和批次大小,进一步提升性能;
- 更精细的掩码策略:如SpanBERT,对连续的词汇片段进行掩码,而非单个词汇,增强模型对短语语义的理解。
3. 效率优化
- 模型压缩:通过蒸馏(Distillation,如DistilBERT)、量化(Quantization)等技术,在保证效果的前提下减少参数量,降低部署成本;
- 快速预训练:如ALBERT,通过参数共享、因式分解嵌入矩阵等方式,大幅减少参数量,加速预训练过程。
4. 多模态融合
- 预训练模型从纯文本扩展到“文本+图像”(如CLIP、ViBERT)、“文本+语音”等多模态领域,实现跨模态的语义理解和生成。
八、总结
预训练语言模型(以BERT为代表)通过“Pre-train + Fine-tune”模式,彻底革新了NLP领域的技术范式。其核心价值在于利用海量无标注数据学习通用语言知识,为下游任务提供强大基础;而Transformer架构的自注意力机制,則保障了模型对语义关联的深度捕捉能力。
尽管BERT存在训练成本高、生成能力弱等局限,但它奠定了现代预训练技术的基础,后续的GPT、T5、CLIP等模型均在其思想上不断优化。未来,预训练技术将朝着“更高效、多模态、通用化”的方向发展,持续推动NLP乃至人工智能领域的进步。