python爬虫入门案例day05:Pexels
python爬虫入门案例day05:Pexels
目标网站
Pexels
目标网址
https://www.pexels.com/zh-cn/search/%E6%97%A5%E8%90%BD/
开发环境
1、window11
2、python3.7
3、PyCharm Community Edition 2021.2.1
4、双核浏览器
5、浏览器自带开发者工具
网站分析
在下拉网页的过程中发现,会不断加载出新的图片,说明该网页为动态网页,那我们可以初步猜想图片的链接存放在通过Ajax请求的网络数据包中,抓包过程如图:

数据包url规律分析
1、https://www.pexels.com/zh-cn/api/v3/search/photos?page=10&per_page=24&query=%E6%97%A5%E8%90%BD&orientation=all&size=all&color=all
2、https://www.pexels.com/zh-cn/api/v3/search/photos?page=11&per_page=24&query=%E6%97%A5%E8%90%BD&orientation=all&size=all&color=all
3、https://www.pexels.com/zh-cn/api/v3/search/photos?page=12&per_page=24&query=%E6%97%A5%E8%90%BD&orientation=all&size=all&color=all
4、https://www.pexels.com/zh-cn/api/v3/search/photos?page=13&per_page=24&query=%E6%97%A5%E8%90%BD&orientation=all&size=all&color=all
5、https://www.pexels.com/zh-cn/api/v3/search/photos?page=14&per_page=24&query=%E6%97%A5%E8%90%BD&orientation=all&size=all&color=all
经过对比发现,只有参数page在变化,且从1开始隔间为1开始递增,可以删除的参数color、size、orientation
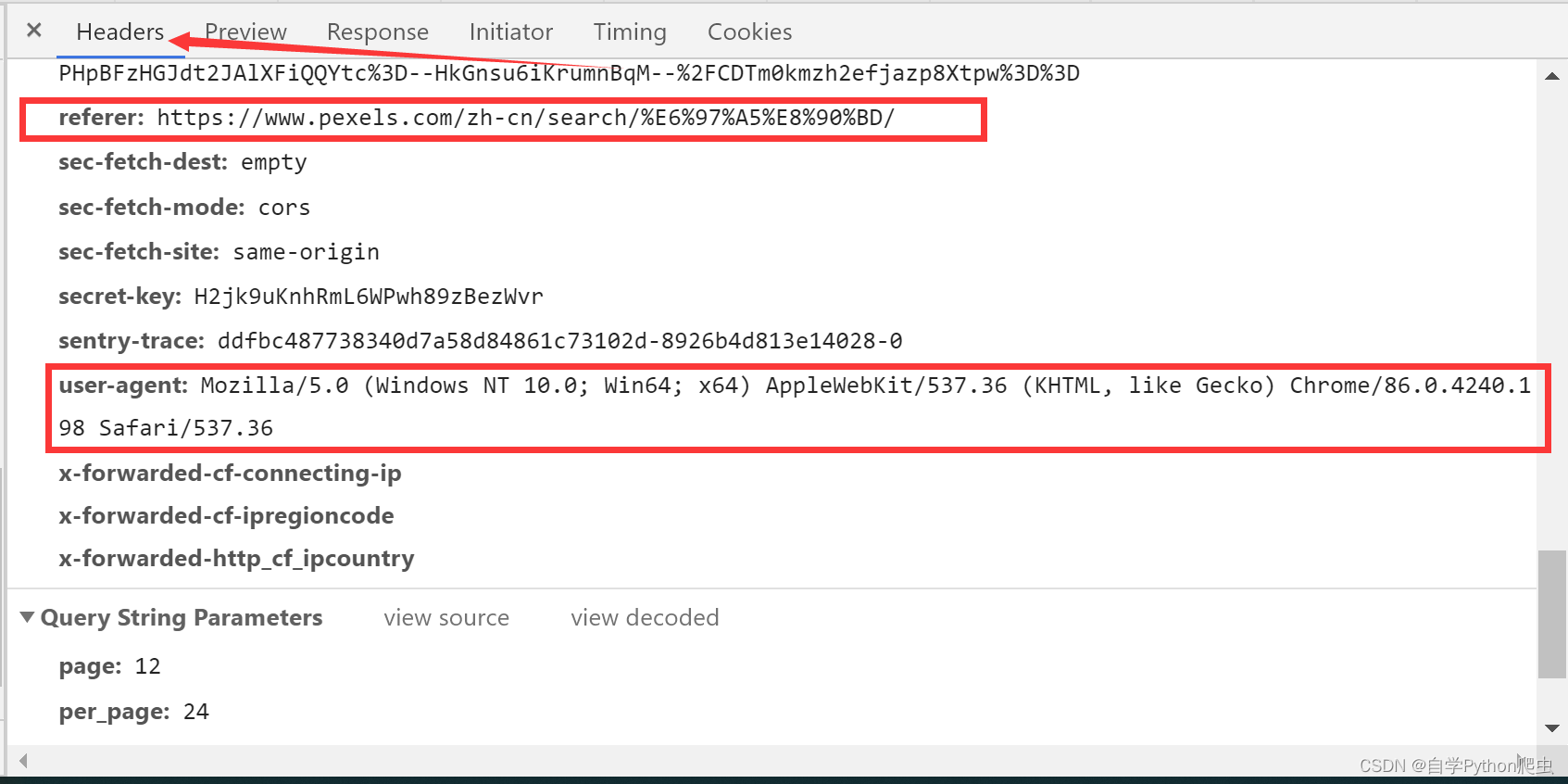
请求头分析
先将请求头内容照如图所写,发现返回报错:{‘error_messages’: [‘Bad API credentials.’]}
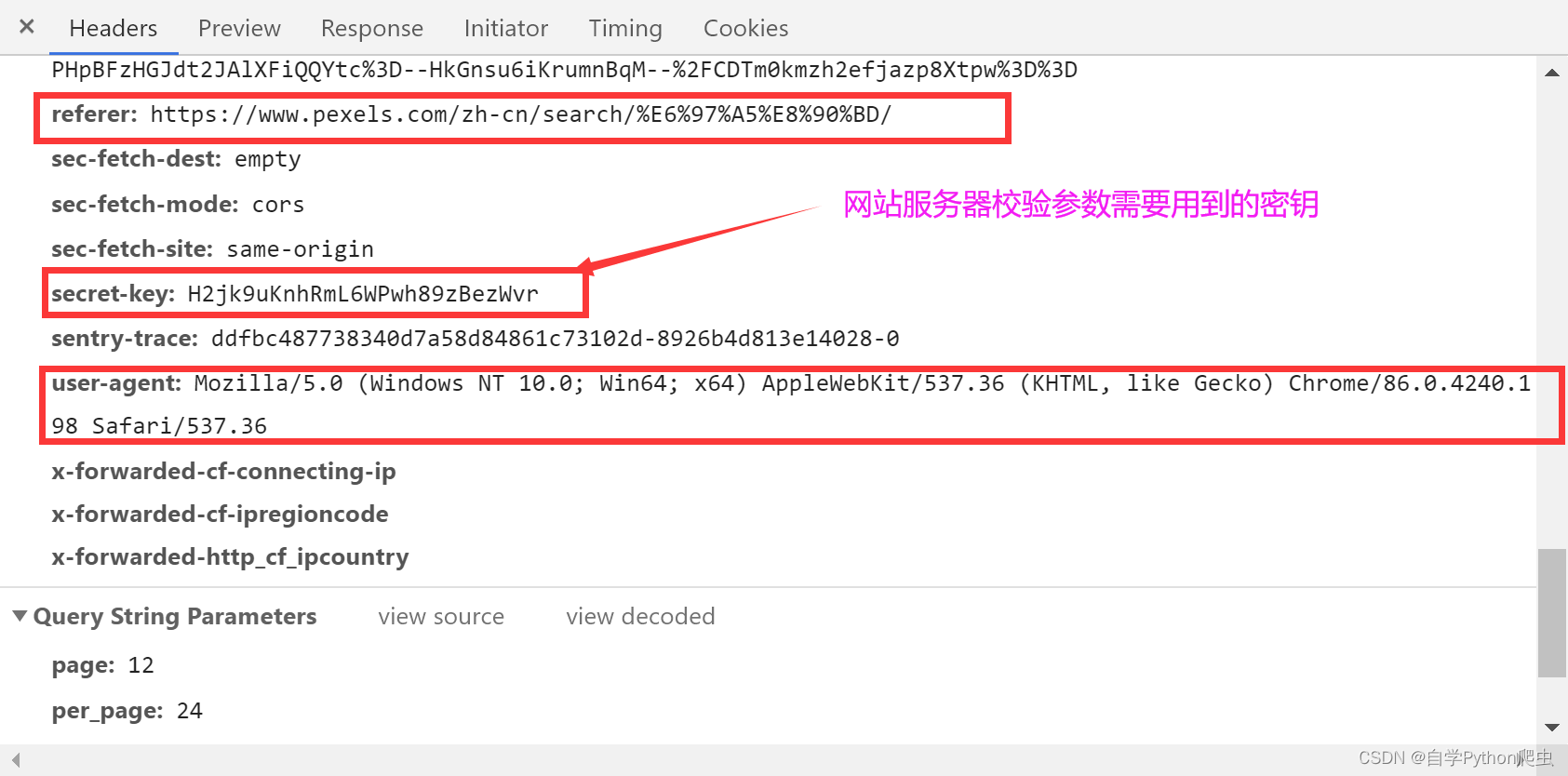
原因是因为网站服务器对gei请求的参数进行了校验,但是请求头中没有找到密钥,于是修改请求头如下图:
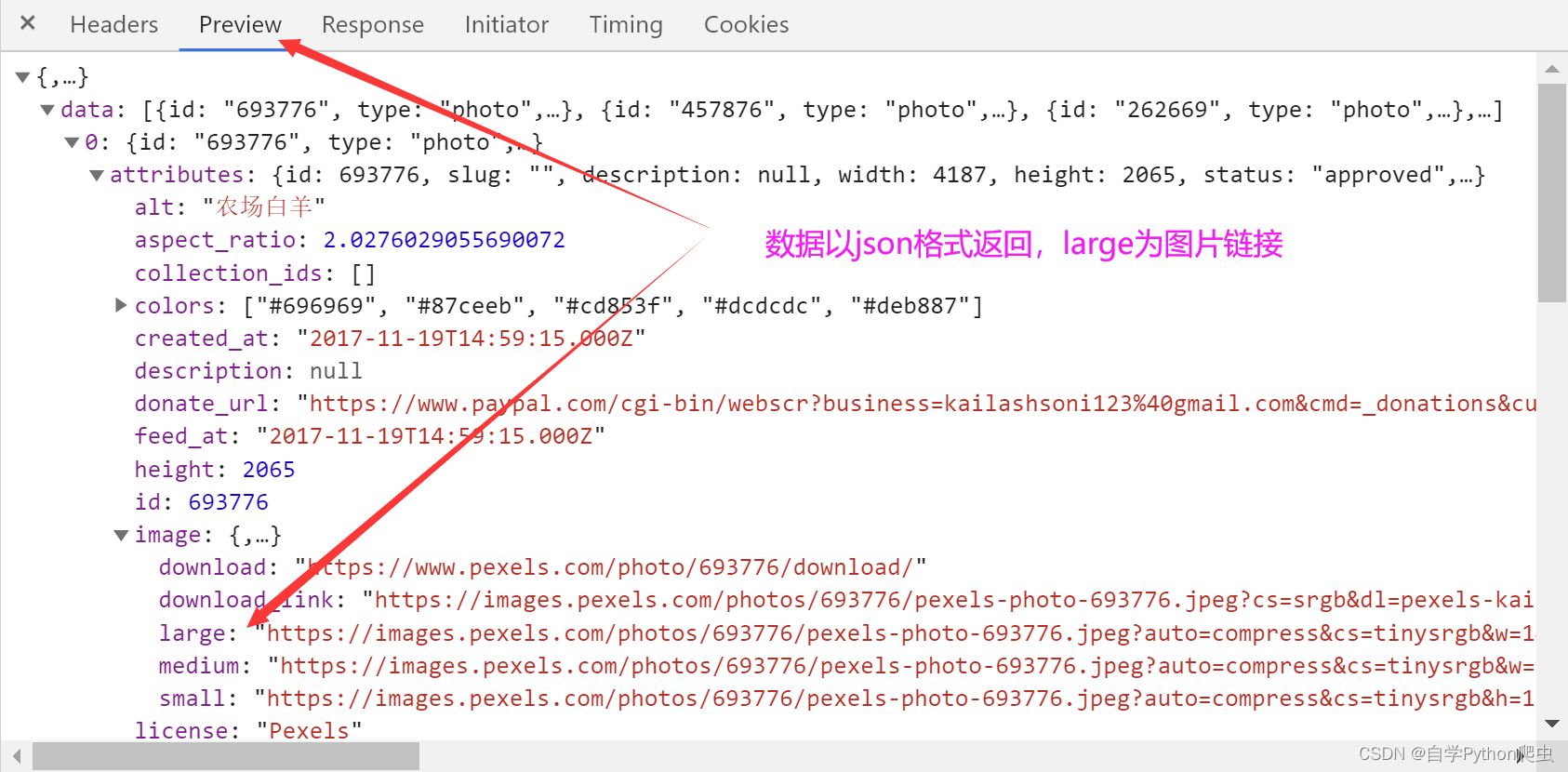
响应数据结构分析
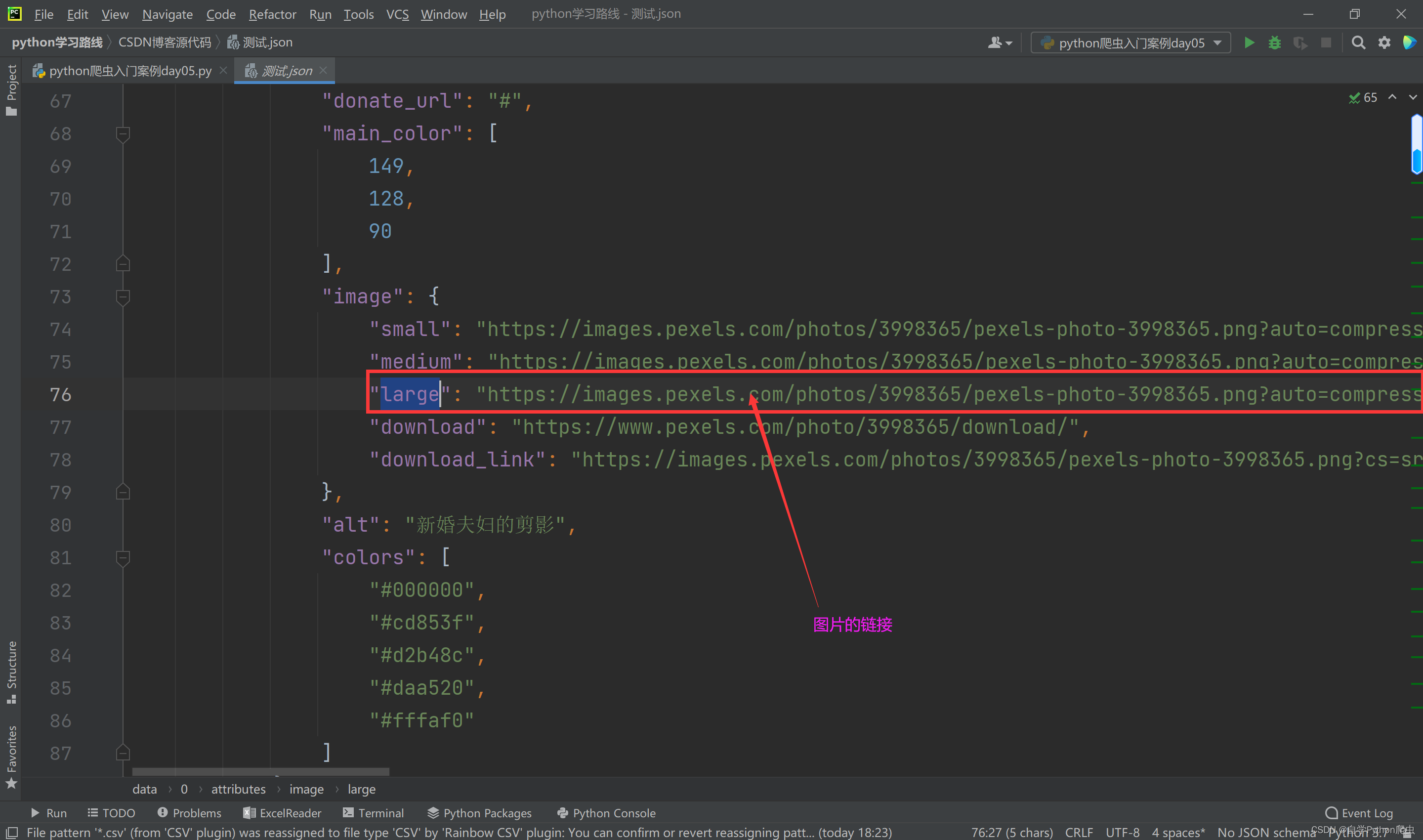
如上图一眼可以看出,响应数据格式为json数据格式,可以使用jsonpath对json数据进行解析,方便简单且快速
源代码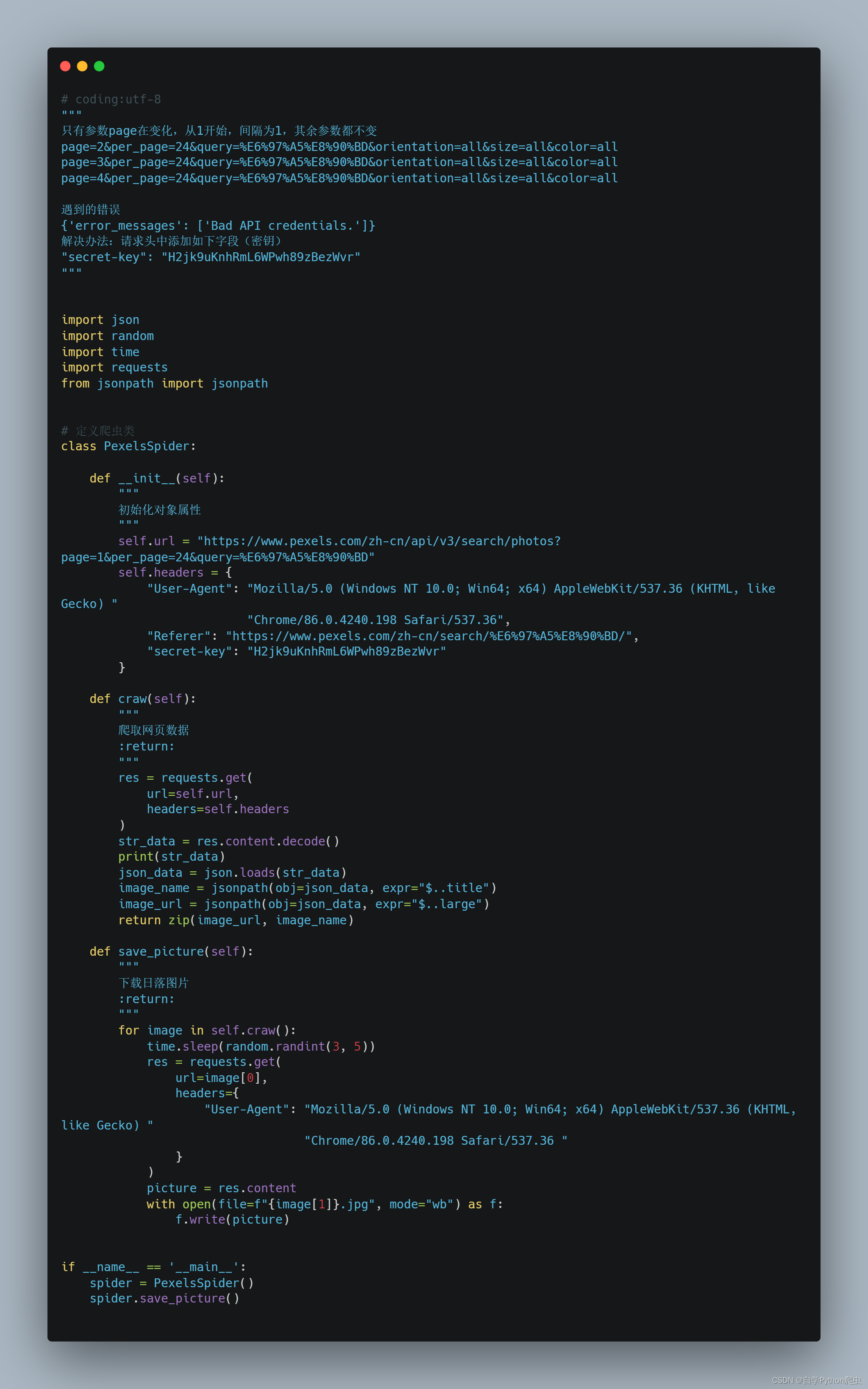
下载的图片
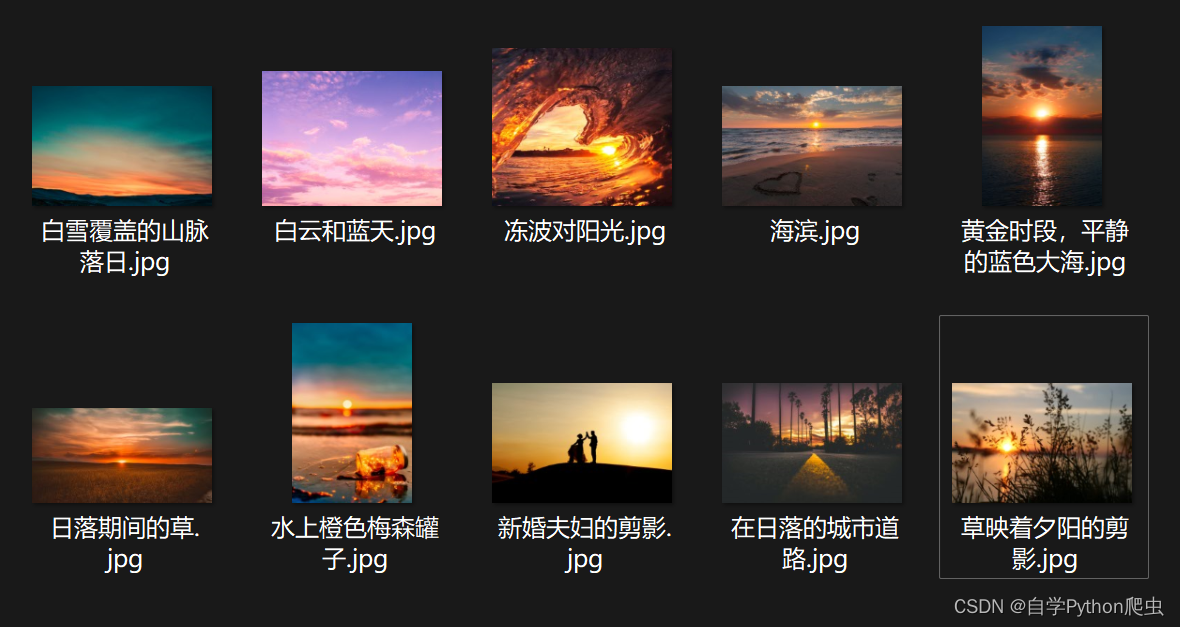
知识点总结
1、requests模块的get方法就是模拟浏览器发起get网络请求,得到服务器返回响应数据,headers中添加了user-agent用来将程序伪装成浏览器,user-agent是浏览器标识,一般服务器都会检查请求头中的user-agent字段的内容;
2、响应数据是字符串格式,但是看起来和json数据一样,使用json.loads()将str格式数据转换为json格式数据;
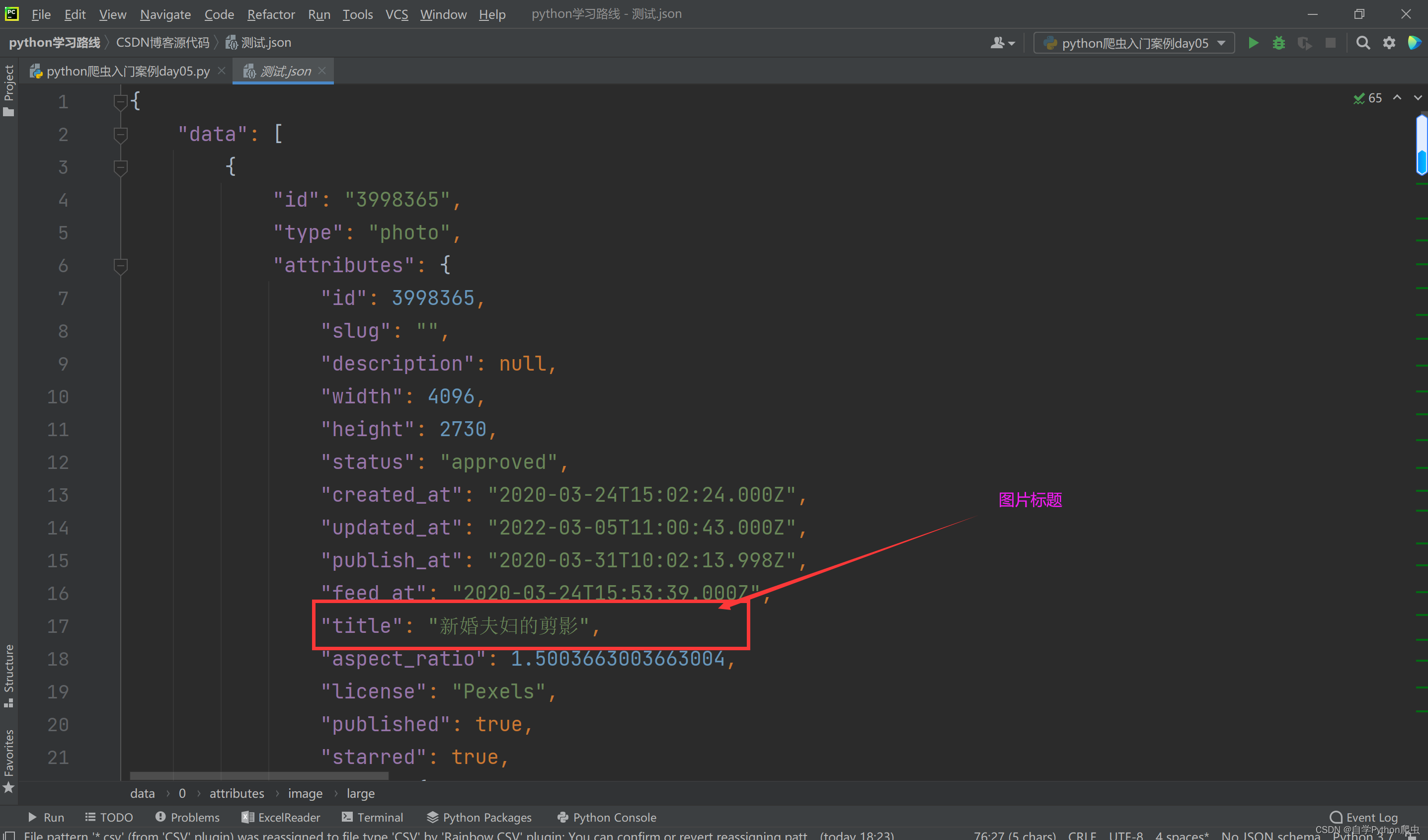
3、使用jsonpath.jsonpath()方法来对json格式数据进行解析提取出图片名称和图片链接;
4、为了降低爬虫程序对目标服务器造成的压力,要在程序中设置强制随机休眠time.sleep(random.randint(3, 5));