OpenAI Whisper:技术、实战、生态
概述
在语音转文本ASR工具合集汇总介绍过几款语音识别模型和项目,其中就包括OpenAI开源的Whisper。
论文,OpenAI开源的支持多语言的通用ASR。在68万小时的标注数据上进行训练,有很强的泛化能力;作为一个多任务模型,可执行多语言语音识别、语音翻译和口语识别。通过使用分块算法,也可用于转录任意长度的音频样本。分块是通过在实例化管道时设置chunk_length_s=30启用。
Whisper共提供5种不同参数大小的模型,其中4种有专一的英文模型,在速度与准确性做平衡。
| Size | Parameters | English-only model | Multilingual model | Required VRAM | Relative speed |
|---|---|---|---|---|---|
| tiny | 72M | tiny.en | tiny | ~1GB | ~32x |
| base | 138M | base.en | base | ~1GB | ~16x |
| small | -M | small.en | small | ~2GB | ~6x |
| medium | -M | medium.en | medium | ~5GB | ~2x |
| large | -M | N/A | large | ~10GB | 1x |
注:large有v1,v2,v3三个版本,v3还有个openai/whisper-large-v3-turbo版本。
对于本地部署的模型,WAV和TS(Transport Stream,一种流媒体容器格式,用于在数字电视广播中传输音频和视频数据)文件都可直接使用,但TS文件在OpenAI付费接口上不行,需要提前通过FFMPEG将TS文件转为mp3文件。
技术
核心工作流
五步完成语音转文本的蜕变,Whisper的成功关键,在于精准的预处理与高效Transformer二者之间的协同作用。许多人仅仅关注Transformer架构本身,却忽略其前置处理环节中那些精巧的设计——正是80通道的梅尔频谱图,经过两次卷积操作,并结合GELU激活函数,才为Transformer的高效运行,打下坚实的基础。整个处理流程,可划分为五个核心步骤:
- 音频标准化:将任意采样率的原始音频统一重采样至16kHz(模型标准输入);
- 梅尔频谱转换:将标准化音频,转为80通道对数幅度梅尔频谱图(v3版本升级为128通道),把波形信号,变成符合人耳特性的特征图像;
- 特征精炼:通过两层卷积提取局部语音特征,GELU(Gaussian Error Linear Unit)注入非线性,完成降维提效;
- 编码阶段:加入旋转位置编码(RoPE),经Transformer编码器捕捉全局依赖;
- 解码与后处理:结合CTC(Connectionist Temporal Classification)与自回归解码生成文本,自动完成语言识别、标点与时间戳标注。
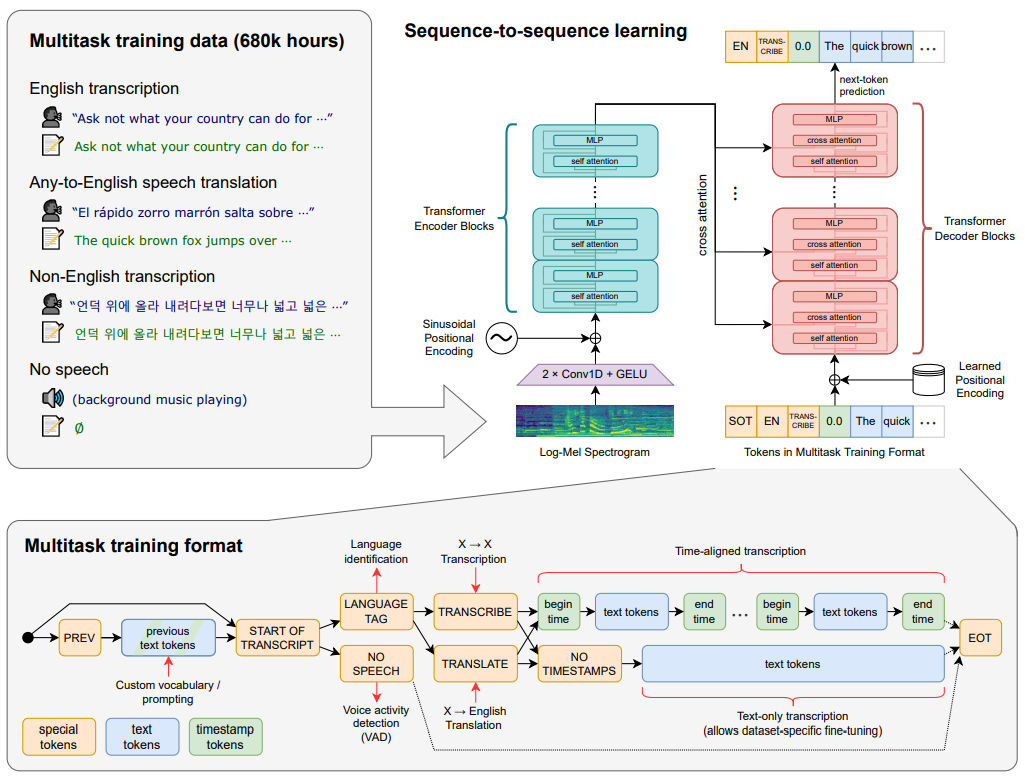
架构基石
Transformer虽擅长于捕捉长序列的全局关系,但却无法直接对原始音频进行处理——它既不善于提取局部特征,也难以应付海量冗余的数据。Whisper的80通道梅尔频谱图、经过两次的卷积以及GELU,恰恰是为了解决这一矛盾而诞生的三重前置处理模块,构成模型架构的底层重要基础。
第一重魔法:80通道梅尔频谱图
原始音频,它是连续的波形(在16kHz的采样率下,10秒之中包含16万个振幅的数据点),倘若直接进行输入,这样就会致使数据爆炸和特征冗余。梅尔频谱图的核心作用在于模拟人耳的听觉特性,以此来达成信号提纯的目的。
- 设计逻辑:人耳对于低频(100-400Hz,此为说话基音)较为敏感,而对高频(>8000Hz,乃是环境噪声)不太敏感。80个通道恰好能够覆盖人类语音的核心频率范围,这样既不会丢失关键信息,与此同时又能够压缩数据量(10秒音频数据量从16万降低至8万)。
- 技术细节:经短时傅里叶变换(STFT转频谱→梅尔滤波器组提能量→取对数放大弱信号,最终得到时间-频率二维特征图
- 架构意义:将波形信号转化为模型易理解的频率特征,为后续处理奠定基础
核心代码:梅尔频谱图生成(关键参数标注)
import librosa
import numpy as npdef generate_whisper_mel(audio_path: str):# 1. 加载音频并统一采样率为16kHzwaveform, _ = librosa.load(audio_path, sr=16000)# 2. 按Whisper标准参数生成80通道梅尔谱mel_spec = librosa.feature.melspectrogram(y=waveform, sr=16000, n_fft=400, hop_length=160, n_mels=80, fmax=8000)# 3. 对数转换+归一化(Whisper必填步骤)log_mel = np.log(np.clip(mel_spec, a_min=1e-10, a_max=None))return (log_mel - log_mel.mean()) / (log_mel.std() + 1e-6)mel_feature = generate_whisper_mel("sample_audio.wav")
print(f"梅尔谱形状: {mel_feature.shape}") # 输出(80, 时间步长)
第二重魔法:两次卷积
梅尔频谱图,仍含有局部冗余,两次卷积所构成的特征提取词干,核心作用在于提取局部语音特征,与此同时降低时间维度,以便为Transformer输送精炼素材。
- 层级分工
- 第一次卷积:16个3×3核,提取声带振动浊音、摩擦音清音等基础特征,80通道→16通道;
- 第二次卷积:32个3×3核步长2,将其整合为音素级特征;在此期间,把时间维度压缩至12,减少Transformer计算量;
- 架构意义:帮Transformer提前完成局部特征提取,避免其在原始频谱中大海捞针
第三重魔法:GELU激活函数——给模型注入非线性理解能力
卷积输出,需经激活函数,这样能产生非线性变换,从而才能够理解复杂语音规律,(例如升调、轻音)。Whisper选择GELU而非ReLU,其核心之处在于精准地把捉语音里的细微细节。
- 关键区别
- ReLU是硬开关:输入若小于等于0,则便直接将其置为0,如此这般容易丢失像那轻声音节这般较弱的特征;
- GELU是渐变开关,基于高斯误差函数来动态地保留特征,能够以一种温和的方式保留那些较弱的信号。
- 架构意义:让模型不遗漏细节、不夸大噪声,是复杂场景识别准确率领先的关键
核心代码:预处理模块整合(含卷积+GELU)
import torch
import torch.nn as nnclass WhisperPreprocessStem(nn.Module):"""Whisper Transformer前的核心预处理模块"""def __init__(self, out_dim: int = 512):super().__init__()# 两次卷积+GELU特征提取self.conv_block = nn.Sequential(nn.Conv2d(1, 16, 3, padding=1), # 1→16通道(输入为单通道梅尔谱)nn.GELU(),nn.Conv2d(16, 32, 3, padding=1, stride=(2,1)), # 16→32通道,时间降维1/2nn.GELU())# 映射到Transformer输入维度self.fc = nn.Linear(32 * 80 * 500, out_dim) # 假设输入时间步1000,降维后500def forward(self, mel_spec: torch.Tensor):# 梅尔谱形状:(batch, 时间步, 80) → (batch, 1, 时间步, 80)(适配卷积)mel_spec = mel_spec.unsqueeze(1)conv_out = self.conv_block(mel_spec).flatten(1) # 展平卷积结果return self.fc(conv_out).permute(1, 0, 2) # 转成Transformer需要的(seq_len, batch, d_model)fake_mel = torch.randn(1, 1000, 80) # 1个batch、1000时间步、80通道
preprocessor = WhisperPreprocessStem()
print(f"预处理后输出形状: {preprocessor(fake_mel).shape}")
架构精髓
多任务联合训练的底层逻辑,完成“三重预处理”后精炼的特征,会输入Transformer编码器-解码器架构。Whisper以单一模型来承载语音识别、翻译以及语言检测这三大任务,其核心在于多任务的联合训练以及统一的文本生成接口。
核心代码:Transformer位置编码(时序建模关键)
import torch
import mathclass PositionalEncoding(nn.Module):def __init__(self, d_model: int, max_len: int = 5000):super().__init__()# 预计算位置编码(不参与梯度更新)pe = torch.zeros(max_len, d_model)position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)div_term = torch.exp(torch.arange(0, d_model, 2) * (-math.log(10000.0) / d_model))pe[:, 0::2] = torch.sin(position * div_term)pe[:, 1::2] = torch.cos(position * div_term)self.register_buffer('pe', pe)def forward(self, x: torch.Tensor):return x + self.pe[:x.size(0)] # 按输入序列长度截取编码
未来演进
Whisper未来可能的演进方向:
- 低资源语言突破:从英语优先到全球覆盖
- 接入Mozilla Common Voice等多语言数据集,丰富方言样本
- 用高资源语言预训练知识,通过语言嵌入适配低资源语言
- 多模态融合:不止听声辨字,更能理解语境
- 结合视频唇动信号优化嘈杂环境识别,
- 联动GPT-4o实现语音理解生成闭环,支持复杂指令
- 边缘部署深化:从云端依赖到设备原生
- 微型模型(如
ggml-base-tdrz内存<100MB,支持手机、嵌入式设备 - 实时流处理优化,端到端延迟降至200ms以内
- 微型模型(如
实战
有多种安装方式,最简单的就是:pip install -U openai-whisper
源码安装:
git clone https://github.com/openai/whisper.git
python -m venv whisper-env
source whisper-env/bin/activate
可选:
pip install torch torchaudio librosa
简单使用:
import whisper# 加载模型,以Windows为例,下载路径C:\Users\johnny\.cache\whisper
model = whisper.load_model("base")
# load audio and pad/trim it to fit 30 seconds
audio = whisper.load_audio("ok.wav")
audio = whisper.pad_or_trim(audio)
# make log-Mel spectrogram and move to the same device as the model
mel = whisper.log_mel_spectrogram(audio).to(model.device)
# detect the spoken language
_, probs = model.detect_language(mel)
print(f"Detected language: {max(probs, key=probs.get)}")
本地模型:

运行效果:

使用CPU:
model = whisper.load_model("tiny")
result = model.transcribe("ok.wav")
print(result["text"])

使用GPU加速:
import torch
torch.cuda.is_available()
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
model = whisper.load_model("tiny", device=DEVICE)
result = model.transcribe("ok.wav")
print(result["text"])
转录实例:
import whisper
import time# 转录
def basic_transcribe(audio_path: str, model_size: str = "base"):model = whisper.load_model(model_size)start = time.time()# 核心转录(内部自动执行梅尔谱+卷积+GELU预处理)result = model.transcribe(audio_path, language="zh", task="transcribe", word_timestamps=True)return {"text": result["text"],"word_level": [{"word": w["word"], "time": (w["start"], w["end"])} for w in result["segments"][0]["words"]],"耗时": f"{time.time()-start:.2f}秒"}print(basic_transcribe("meeting.wav", "large-v3-turbo"))
结合PyAnnote实现会议转录:
from pyannote.audio import Pipeline
import whisperdef meeting_transcribe(audio_path: str, hf_token: str):# 1. 说话人分离diarize = Pipeline.from_pretrained("pyannote/speaker-diarization-3.1", use_auth_token=hf_token)speaker_segments = diarize(audio_path)# 2. Whisper转录全量音频model = whisper.load_model("medium")result = model.transcribe(audio_path, word_timestamps=True)# 3. 文本与说话人对齐meeting_notes = []for text_seg in result["segments"]:# 匹配该时间段的说话人speaker = next((spk for turn, _, spk in speaker_segments.itertracks() if turn.start <= text_seg["start"] <= turn.end), "未知")meeting_notes.append({"speaker": speaker, "text": text_seg["text"]})return meeting_notesprint(meeting_transcribe("team_meeting.wav", "xxx"))
量化模型低延迟推理
import torch
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessordef industrial_whisper_infer(audio_tensor: torch.Tensor):# 加载8-bit量化模型,显存占用降低45%processor = AutoProcessor.from_pretrained("openai/whisper-large-v3-turbo")model = AutoModelForSpeechSeq2Seq.from_pretrained("openai/whisper-large-v3-turbo", load_in_8bit=True, device_map="auto", torch_dtype=torch.float16)# 低延迟推理参数inputs = processor(audio_tensor, sampling_rate=16000, return_tensors="pt").to("cuda")with torch.no_grad():gen_ids = model.generate(**inputs, max_new_tokens=256, do_sample=False, temperature=0.0)return processor.batch_decode(gen_ids, skip_special_tokens=True)[0]
实践建议
- 选型策略:边缘场景选
tiny或small量化,桌面端选medium,工业级选largev3-turbo+GPU - 性能优化:优先8-bit量化+混合精度计算,复杂场景可裁剪高频噪声进一步降维
- 场景拓展:基础转录用官方API,会议场景加PyAnnote,工业场景固化预处理流程
集成HuggingFace:
import torch
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor, pipeline
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model_id = "openai/whisper-large-v2"
model = AutoModelForSpeechSeq2Seq.from_pretrained(model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True
)
model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
pipe = pipeline("automatic-speech-recognition",model=model,tokenizer=processor.tokenizer,feature_extractor=processor.feature_extractor,torch_dtype=torch_dtype,device=device,
)
generate_kwargs = {"max_new_tokens": 448
}
命令行使用:
# 使用medium模型识别音频,生成json、srt、tsv、txt、vtt文本文件
whisper --model medium dataset/9s.wav
解读:
- srt:用于存储音视频文件的字幕信息
- tsv:存储表格数据,类似于CSV
- vtt:用于存储视频文件的字幕信息
使用付费API:
import openai
CHATGPT_KEY = "OpenAI API Key"
openai.api_key = CHATGPT_KEY
audio_file = open("9s.wav", "rb")
transcription = openai.audio.transcriptions.create(model="whisper-1", file=audio_file, response_format="text"
)
print(transcription)