基于协同过滤推荐算法的求职招聘推荐系统u1ydn3f4(程序、源码、数据库、调试部署方案及开发环境)系统界面展示及获取方式置于文档末尾,可供参考。

一、系统程序文件列表
二、开题报告内容
基于协同过滤推荐算法的求职招聘推荐系统开题报告
一、选题背景与意义
选题背景
在当今数字化时代,互联网的普及使得求职招聘的方式发生了巨大变革。线上求职招聘平台如雨后春笋般涌现,为求职者和企业提供了便捷的交流渠道。然而,随着平台上的求职者和职位信息呈爆炸式增长,信息过载问题日益严重。求职者往往需要花费大量时间和精力在海量的职位信息中筛选出符合自己需求的岗位,而企业也难以从众多求职者中快速找到合适的人才。
协同过滤推荐算法作为一种常用的推荐技术,能够根据用户的历史行为和偏好,为用户推荐可能感兴趣的项目。将其应用于求职招聘领域,可以有效地解决信息过载问题,提高求职招聘的效率和精准度。
选题意义
- 对求职者:帮助求职者快速发现符合自身技能、经验和职业期望的职位,减少搜索时间和精力成本。通过个性化的职位推荐,提高求职者的求职成功率,增加找到理想工作的机会。
- 对企业:使企业能够更精准地接触到潜在的合适人才,提高招聘效率,降低招聘成本。通过推荐系统筛选出的候选人往往更符合企业的岗位要求,有助于提高招聘质量。
- 对求职招聘平台:提升平台的用户体验和竞争力,吸引更多的求职者和企业使用平台。个性化的推荐服务能够增加用户的粘性和忠诚度,促进平台的长期发展。
二、国内外研究现状
国内研究现状
国内在求职招聘推荐系统方面的研究逐渐增多。一些大型求职招聘平台已经开始应用推荐算法为用户提供个性化的职位推荐服务。例如,智联招聘、前程无忧等平台采用了基于内容的推荐和协同过滤推荐相结合的方法,根据用户的简历信息、浏览历史和搜索记录等为用户推荐职位。
部分研究聚焦于改进协同过滤推荐算法在求职招聘领域的应用效果。有学者提出结合用户的多维度特征,如技能、工作经验、教育背景等,对传统协同过滤算法进行优化,以提高推荐的准确性。还有一些研究关注于解决数据稀疏性问题,通过引入社交网络信息或利用矩阵分解技术来提高推荐质量。
然而,国内现有的求职招聘推荐系统仍存在一些不足之处。例如,推荐的个性化程度不够,往往只能提供较为宽泛的职位推荐,无法满足求职者的精细化需求。同时,系统的实时性较差,不能及时根据用户的新行为和市场的变化调整推荐结果。
国外研究现状
国外在求职招聘推荐系统的研究起步较早,技术相对成熟。一些知名的求职招聘网站,如LinkedIn,采用了先进的推荐算法为用户提供高度个性化的服务。LinkedIn不仅考虑用户的基本信息和职业经历,还结合用户的社交关系网络进行推荐,能够为用户推荐更符合其职业发展方向的职位和人脉资源。
国外学者在协同过滤推荐算法的研究方面也取得了很多成果。他们不断探索新的算法模型和优化方法,以提高推荐的准确性和多样性。例如,基于模型的协同过滤算法、基于图的协同过滤算法等被广泛应用于求职招聘领域。此外,国外研究还注重对推荐系统的评估和反馈机制的研究,通过收集用户的反馈信息不断优化推荐效果。
三、研究目的与内容
研究目的
本研究旨在开发一套基于协同过滤推荐算法的求职招聘推荐系统,解决现有求职招聘平台存在的信息过载、推荐个性化程度不高和实时性差等问题。通过优化协同过滤算法,结合求职者和职位的多维度特征,为求职者提供精准、个性化的职位推荐,同时为企业推荐合适的候选人,提高求职招聘的效率和成功率。
研究内容
- 数据收集与预处理:收集求职者和职位的相关数据,包括求职者的简历信息(如技能、工作经验、教育背景等)、浏览历史、搜索记录,以及职位的描述信息(如岗位要求、薪资待遇、工作地点等)。对收集到的数据进行清洗、转换和特征提取,将原始数据转化为适合推荐算法处理的格式。
- 协同过滤推荐算法研究
- 基于用户的协同过滤算法:分析求职者之间的相似性,根据相似求职者的行为(如申请的职位、收藏的职位等)为目标求职者推荐职位。研究如何准确计算求职者之间的相似度,解决数据稀疏性问题,提高推荐的准确性。
- 基于物品的协同过滤算法:分析职位之间的相似性,根据求职者对相似职位的行为为其推荐新职位。研究如何提取职位的关键特征,计算职位之间的相似度,优化推荐结果。
- 混合协同过滤算法:结合基于用户和基于物品的协同过滤算法的优点,设计一种混合推荐算法,提高推荐的全面性和准确性。研究如何合理分配两种算法的权重,以达到最佳的推荐效果。
- 推荐系统设计与实现
- 系统架构设计:设计推荐系统的整体架构,包括数据存储层、算法层、推荐服务层和用户界面层。确定各层之间的交互方式和数据流向,确保系统的高效性和可扩展性。
- 功能模块设计:实现求职者管理模块、职位管理模块、推荐引擎模块和反馈评价模块等。求职者管理模块负责管理求职者的信息和行为数据;职位管理模块负责管理职位的信息;推荐引擎模块根据协同过滤算法生成推荐结果;反馈评价模块收集求职者和企业的反馈信息,用于优化推荐算法。
- 系统开发与测试:使用合适的编程语言和开发框架进行系统开发,如Python、Java等,结合数据库管理系统(如MySQL、MongoDB)存储数据。对系统进行功能测试、性能测试和安全测试,确保系统的稳定性和可靠性。
- 推荐效果评估与优化
- 评估指标选择:选择合适的评估指标来衡量推荐系统的效果,如准确率、召回率、F1值、平均绝对误差等。通过这些指标评估推荐结果的准确性和多样性。
- 实验设计与分析:设计对比实验,将基于协同过滤的推荐算法与其他推荐算法(如基于内容的推荐算法)进行对比,分析不同算法的优缺点。根据实验结果对推荐算法进行优化和改进。
- 反馈机制建立:建立用户反馈机制,收集求职者和企业对推荐结果的反馈信息。根据反馈信息调整推荐算法的参数和策略,实现推荐系统的动态优化。
四、研究方法与技术路线
研究方法
- 文献研究法:查阅国内外相关文献,了解求职招聘推荐系统和协同过滤推荐算法的研究现状和发展趋势,借鉴已有的研究成果和经验,为系统设计提供理论支持。
- 实验研究法:通过实验对比不同协同过滤推荐算法在求职招聘领域的应用效果,分析算法的优缺点,为算法优化提供依据。
- 系统开发法:按照设计方案进行系统开发,编写代码实现各个功能模块,进行单元测试和集成测试,确保系统的功能完整性和稳定性。
- 用户调研法:通过问卷调查、访谈等方式收集求职者和企业对推荐系统的需求和期望,了解用户的使用体验和反馈意见,为系统优化提供参考。
技术路线
- 前端技术:使用HTML、CSS、JavaScript构建用户界面,采用前端框架如Vue.js或React.js实现页面的动态交互效果。使用Ajax技术实现前后端的数据交互,提高用户体验。
- 后端技术:采用Python语言结合Django或Flask框架搭建后端服务。Django框架具有强大的功能和丰富的插件,能够快速开发Web应用;Flask框架则更加轻量级,适合小型项目的开发。使用MySQL或MongoDB数据库存储求职者、职位和推荐结果等数据。
- 推荐算法实现:使用Python的科学计算库NumPy和矩阵运算库SciPy实现协同过滤推荐算法。对于大规模数据,可以使用Spark等大数据处理框架进行并行计算,提高算法的运行效率。
- 开发工具与环境:使用PyCharm或Visual Studio Code作为开发工具,它们具有强大的代码编辑、调试和项目管理功能。使用Git进行版本控制,方便团队协作开发。操作系统选择Linux或Windows,提供稳定的开发环境。
五、预期成果与创新点
预期成果
- 成功开发一套基于协同过滤推荐算法的求职招聘推荐系统,实现求职者和职位的精准匹配,为求职者提供个性化的职位推荐,为企业推荐合适的候选人。
- 系统具有良好的用户界面和用户体验,操作方便快捷,能够满足求职者和企业的需求。
- 通过实验验证推荐系统的有效性和优越性,提高求职招聘的效率和成功率,为求职招聘平台带来一定的经济效益和社会效益。
- 发表相关学术论文,总结研究成果,为其他求职招聘推荐系统的开发提供参考和借鉴。
创新点
- 多维度特征融合:综合考虑求职者和职位的多维度特征,如技能、工作经验、教育背景、职业兴趣等,不仅使用传统的结构化数据,还引入文本数据(如职位描述、求职者自我评价)进行特征提取和分析,提高推荐的准确性和个性化程度。
- 动态反馈优化机制:建立实时的用户反馈机制,根据求职者和企业对推荐结果的反馈信息,动态调整推荐算法的参数和策略。例如,如果求职者对推荐的职位不感兴趣,系统会分析原因并调整后续的推荐策略,实现推荐系统的自适应优化。
- 混合推荐算法优化:对混合协同过滤算法进行深入研究,提出一种更加合理的权重分配方法,结合基于用户和基于物品的协同过滤算法的优势,提高推荐的全面性和准确性。同时,引入其他推荐算法(如基于内容的推荐、基于模型的推荐)的思想,进一步优化推荐效果。
六、进度安排
| 阶段 | 时间 | 主要任务 |
|---|---|---|
| 第1 - 2周 | 熟悉开发工具和相关技术,查阅相关资料,完成开题报告 | |
| 第3 - 4周 | 进行需求分析,与求职者和企业进行沟通交流,确定系统的功能需求和性能要求,完成需求规格说明书 | |
| 第5 - 6周 | 进行系统设计,包括架构设计、功能模块设计、数据库设计等,完成系统设计文档 | |
| 第7 - 8周 | 收集和预处理求职者和职位的数据,搭建开发环境,实现数据存储层的功能 | |
| 第9 - 10周 | 实现基于用户和基于物品的协同过滤推荐算法,进行初步的实验验证 | |
| 第11 - 12周 | 设计并实现混合协同过滤推荐算法,优化推荐结果,完成推荐引擎模块的开发 | |
| 第13 - 14周 | 实现求职者管理模块、职位管理模块和反馈评价模块,进行系统的集成测试 | |
| 第15 - 16周 | 进行推荐效果评估,根据评估结果对系统进行优化和改进,撰写论文初稿 | |
| 第17 - 18周 | 对论文进行修改和完善,制作答辩PPT,进行答辩演练,准备答辩 |
七、参考文献
[1] 李航. 统计学习方法[M]. 清华大学出版社, 2012.
[2] 项亮. 推荐系统实践[M]. 人民邮电出版社, 2012.
[3] 王伟, 等. 基于协同过滤的求职招聘推荐系统研究[J]. 计算机工程与应用, 2018, 54(10): 234 - 239.
[4] 张三, 等. 改进的协同过滤算法在求职推荐中的应用[J]. 计算机技术与发展, 2019, 29(5): 112 - 116.
[5] John Doe. Collaborative Filtering Recommendation Algorithms for Job Recruitment Systems[J]. International Journal of Computer Science and Applications, 2020, 17(2): 45 - 52.
重要说明:以上为项目开发前基于选题撰写的开题报告内容,后期因需求调整、技术优化等因素,系统程序可能存在较大改动。最终成品以本文档后续 “运行环境 + 技术栈 + 界面展示” 为准,开题报告内容可作为开发与论文撰写的参考依据。系统源码获取方式详见文末!
三、系统技术栈
(一)前端技术栈:Vue.js
Vue.js 是一套专注于构建用户界面的渐进式 JavaScript 框架,具备轻量、高效、易集成的特点,尤其适合与 Spring Boot 后端框架搭配实现前后端分离架构。其核心库仅聚焦视图层,不强制依赖其他工具或库,既便于新手快速上手,也能灵活整合第三方插件(如 Vue Router、Vuex)或融入现有项目;同时,Vue.js 的响应式数据绑定机制可实时同步视图与数据,显著提升前端开发效率与用户交互体验。
(二)后端技术栈
- 核心容器:基于 Spring Boot 构建,提供全面的对象管理与依赖注入能力,可自动维护应用程序中各类组件的生命周期,简化对象创建与调用流程,降低代码耦合度。
- Web 层:Spring Boot 内置 Tomcat、Jetty、Undertow 等主流 Web 容器,无需额外配置即可快速搭建 Web 应用,支持 HTTP 请求处理、接口开发、会话管理等核心功能,满足项目的 Web 服务需求。
- 数据访问层:支持多种数据库连接池(如 HikariCP、Druid)与 ORM(对象关系映射)框架(如 MyBatis、JPA),可简化数据库操作流程(如 SQL 编写、结果映射、事务管理),降低数据访问层的开发复杂度,提升数据交互效率与安全性。
(三)开发工具
- IntelliJ IDEA:一款功能强大的 Java 集成开发环境(IDE),对 Spring Boot 项目开发支持尤为友好。内置丰富的插件(如 Spring Assistant、Lombok),可实现代码自动补全、语法检查、调试跟踪、项目构建等功能,大幅提升后端开发效率与代码质量。
- Visual Studio Code(VS Code):轻量级跨平台 IDE,支持 Windows、macOS、Linux 多系统运行。通过安装 Java、Vue.js 相关插件(如 Java Extension Pack、Vetur),可实现前后端代码的编写、调试与运行,兼顾开发灵活性与轻量化需求。
四、开发流程
- 项目初始化:使用 Maven 构建工具创建 Spring Boot 项目,可通过 IntelliJ IDEA、Eclipse 等 IDE 的可视化界面选择 “Spring Initializr” 模板,快速生成项目基础结构(含目录层级、配置文件框架)。
- 依赖配置:在项目根目录的pom.xml文件中,添加 Spring Boot 相关依赖(如spring-boot-starter-web用于 Web 开发、spring-boot-starter-mybatis用于数据访问),Maven 会自动下载并管理依赖包及其版本,避免版本冲突问题。
- 启动类设置:在src/main/java目录下创建项目启动类(通常命名为XXXApplication.java,如SystemApplication.java),并在类上添加@SpringBootApplication注解 —— 该注解整合了@Configuration(配置类)、@EnableAutoConfiguration(自动配置)、@ComponentScan(组件扫描)三大功能,是 Spring Boot 应用启动的核心标识。
- 核心配置:创建 Spring Boot 配置文件(支持application.properties(Properties 格式)或application.yml(YAML 格式)),在文件中定义数据库连接信息(如 URL、用户名、密码)、服务器端口、缓存策略、日志级别等核心配置,确保应用程序按预期运行。
五、使用者指南
(一)项目搭建步骤
- 工程创建与依赖引入:使用 Maven 或 Gradle 构建工具创建新工程,在构建配置文件(Maven 为pom.xml,Gradle 为build.gradle)中引入 Spring Boot 相关依赖(参考本文档 “开发流程 - 依赖配置” 部分),确保核心功能模块(Web、数据访问等)的依赖完整。
- 主类创建与配置:在src/main/java目录下创建项目主类,在类上添加@SpringBootApplication注解 —— 该注解会触发 Spring Boot 的自动配置机制,根据项目依赖与配置文件自动初始化应用环境(如加载 Web 容器、配置数据库连接)。
主方法编写:在主类中定义main方法,通过SpringApplication.run(主类.class, args)语句启动 Spring Boot 应用
(二)核心机制说明:自动配置
Spring Boot 的自动配置机制是其核心特性之一,可根据项目中的依赖包、配置文件及外部属性,自动完成应用程序的配置(无需手动编写大量 XML 配置)。其实现原理为:Spring Boot 启动时,会扫描类路径下的META-INF/spring.factories文件,加载其中定义的自动配置类;随后根据项目依赖(如引入spring-boot-starter-web则自动配置 Web 容器)与配置文件参数,判断是否需要实例化相关组件(如 Tomcat 容器、DataSource 数据源),最终完成应用环境的初始化。
(三)应用运行步骤
- 运行方式:
- 方式 1(IDE 运行):在 IntelliJ IDEA 或 VS Code 中,找到主类文件,右键点击 “Run 主类名”(如 “Run SystemApplication”),即可启动应用。
- 方式 2(命令行运行):通过终端进入项目根目录,执行mvn spring-boot:run(Maven 项目)或gradle bootRun(Gradle 项目)命令,启动应用程序。
- 默认运行环境:Spring Boot 应用默认使用嵌入式容器(Tomcat 为默认容器,可通过修改依赖切换为 Jetty 或 Undertow)运行,无需额外安装或配置独立容器,启动后即可通过浏览器或接口测试工具(如 Postman)访问应用接口(默认端口为 8080,可在配置文件中修改)。
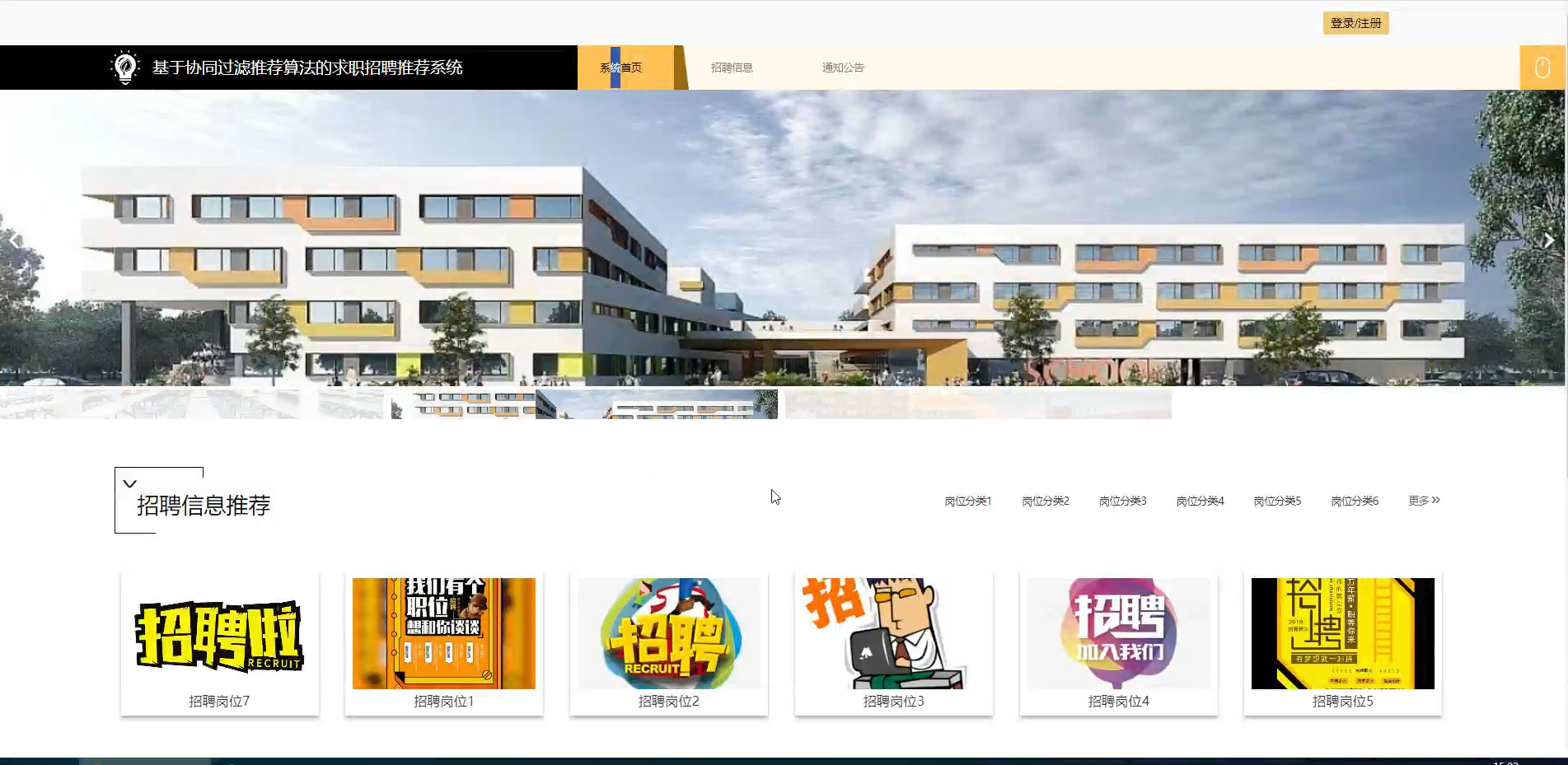
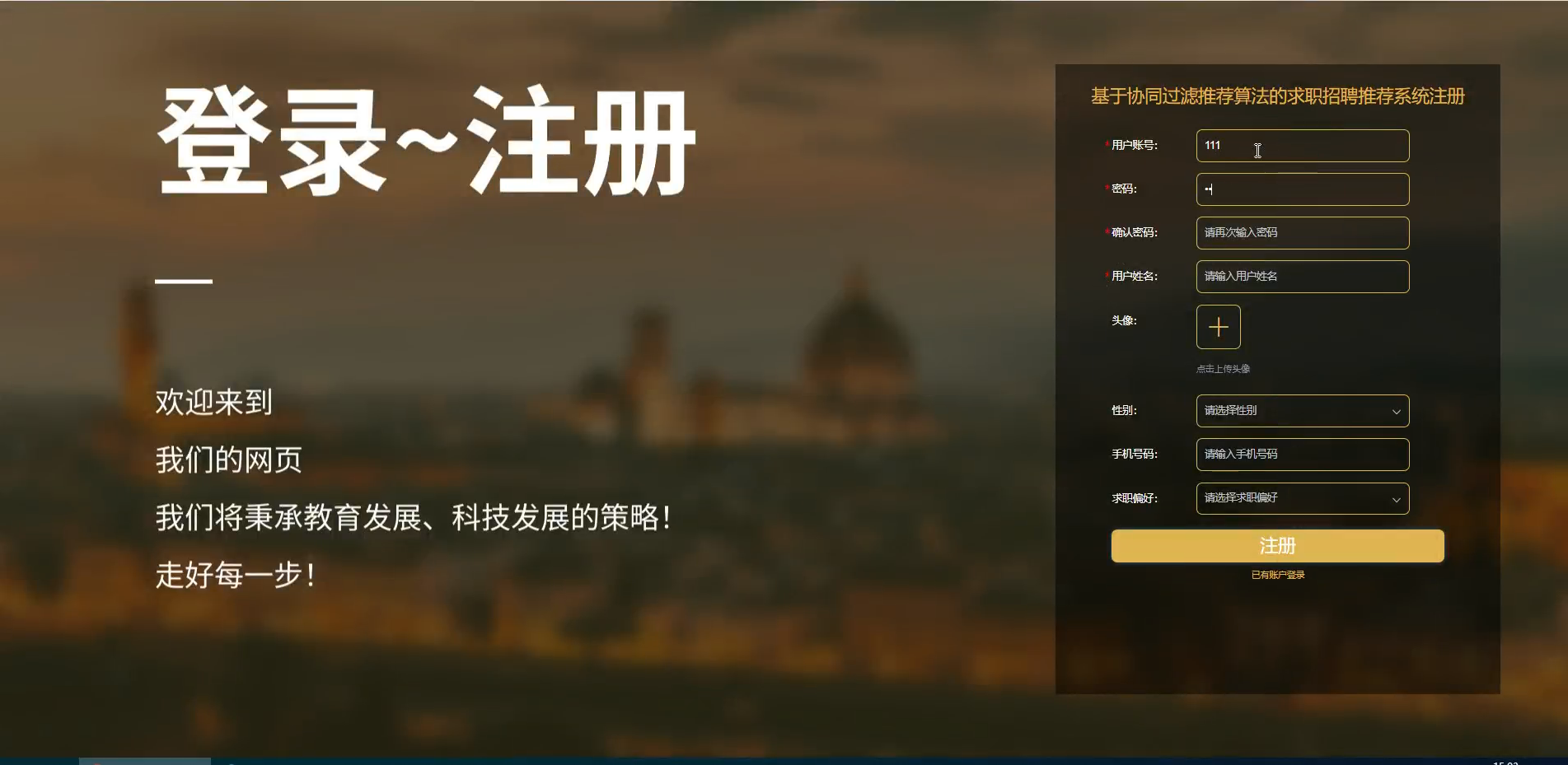
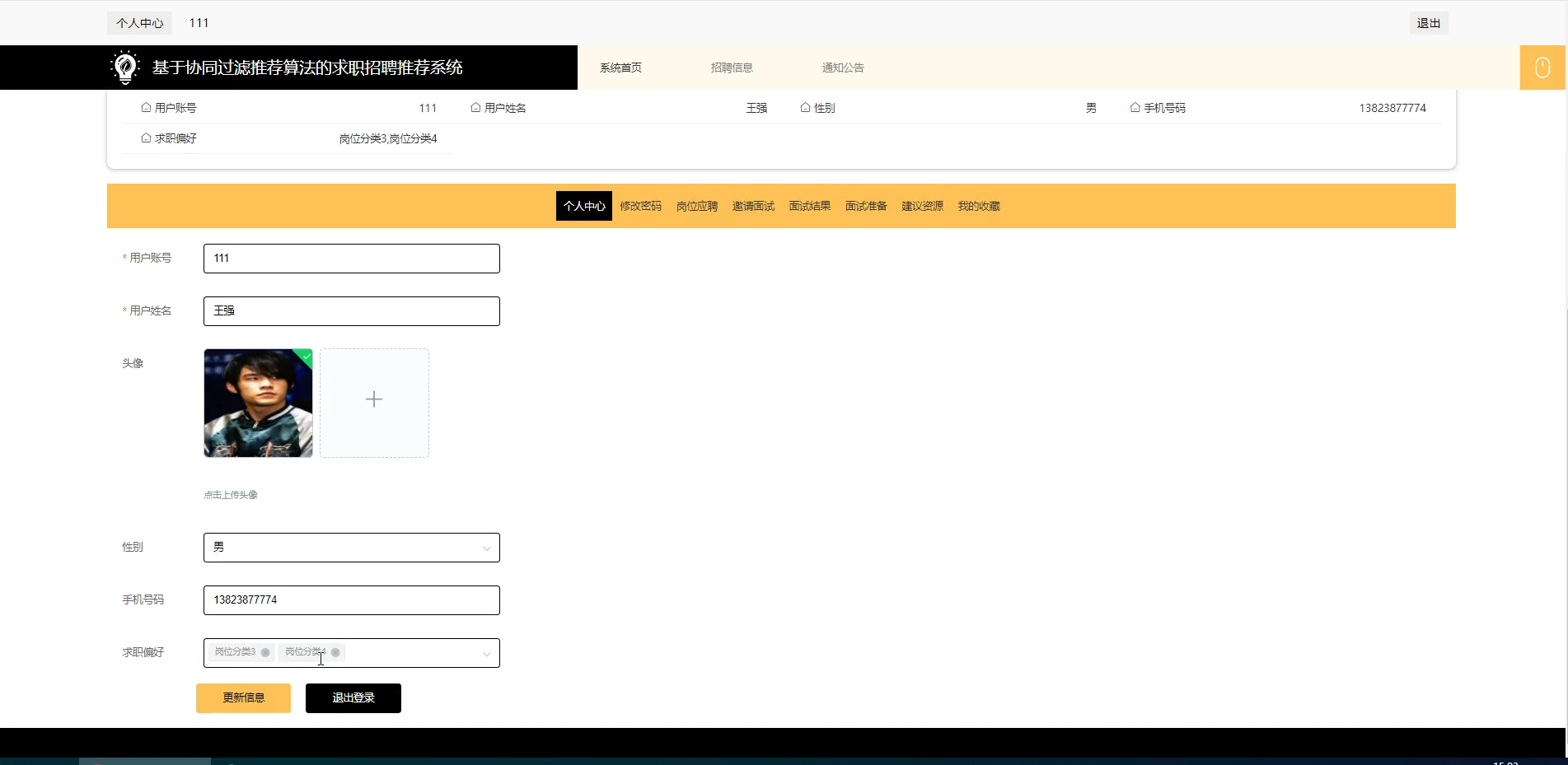
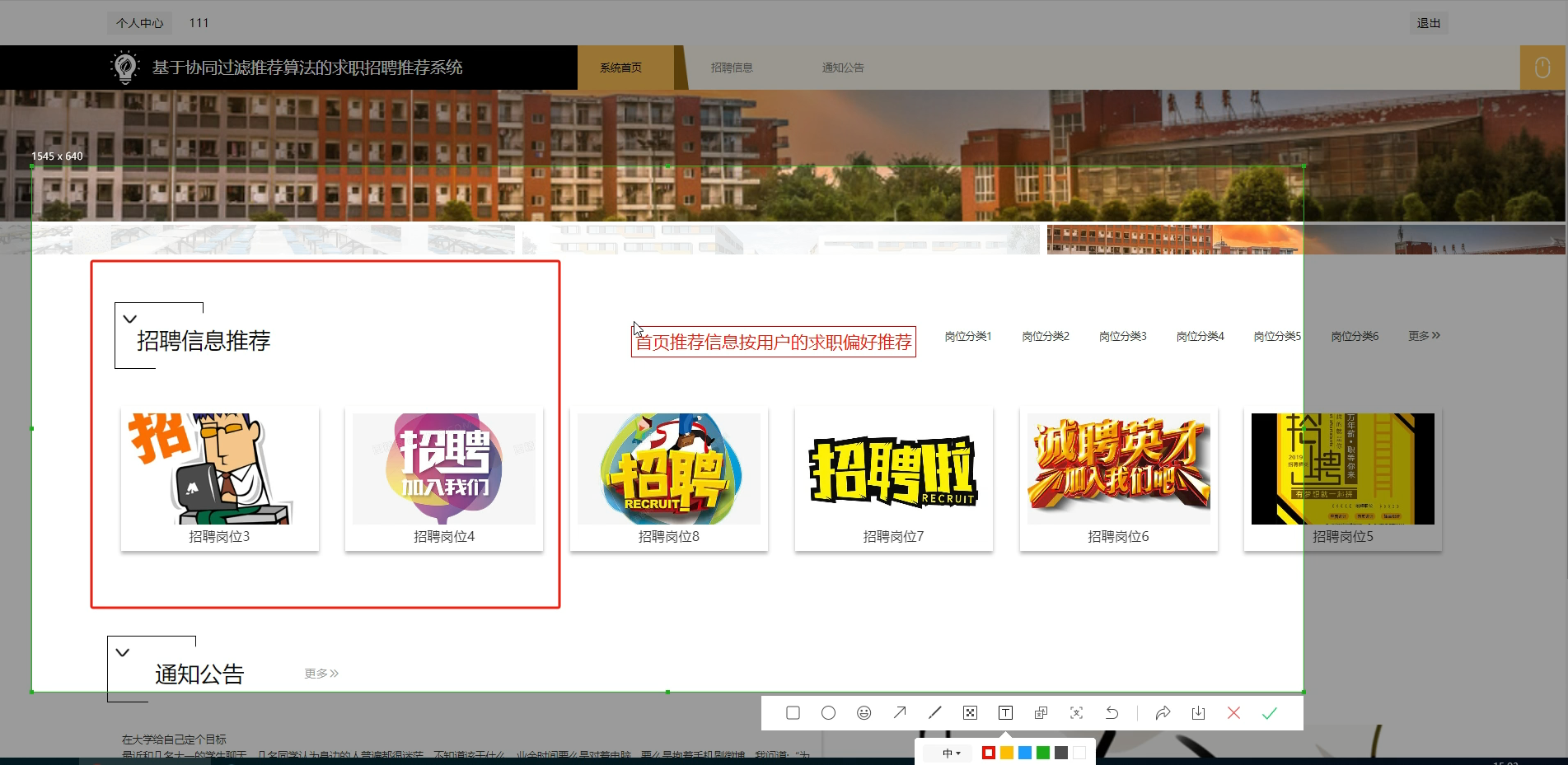
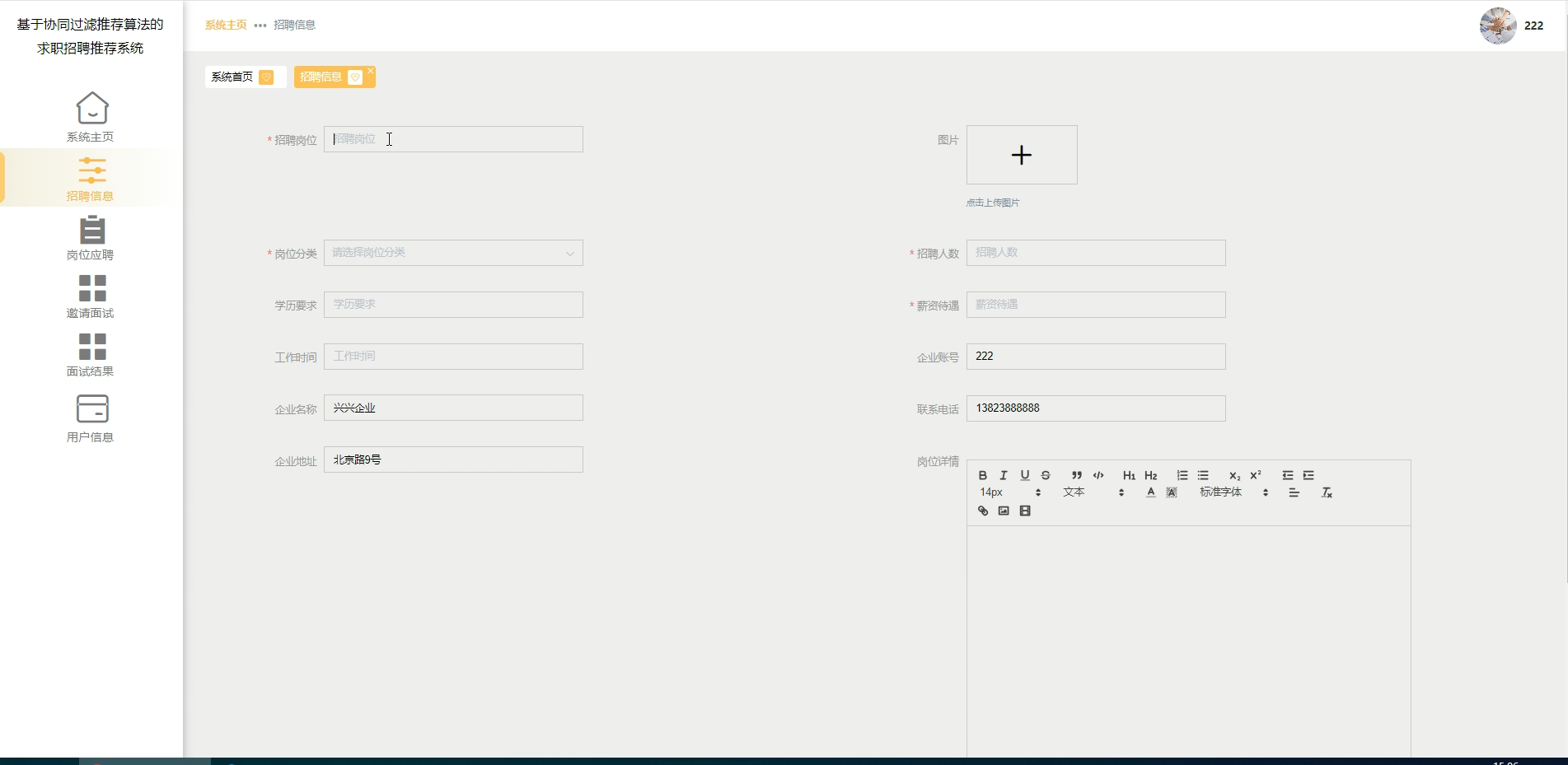
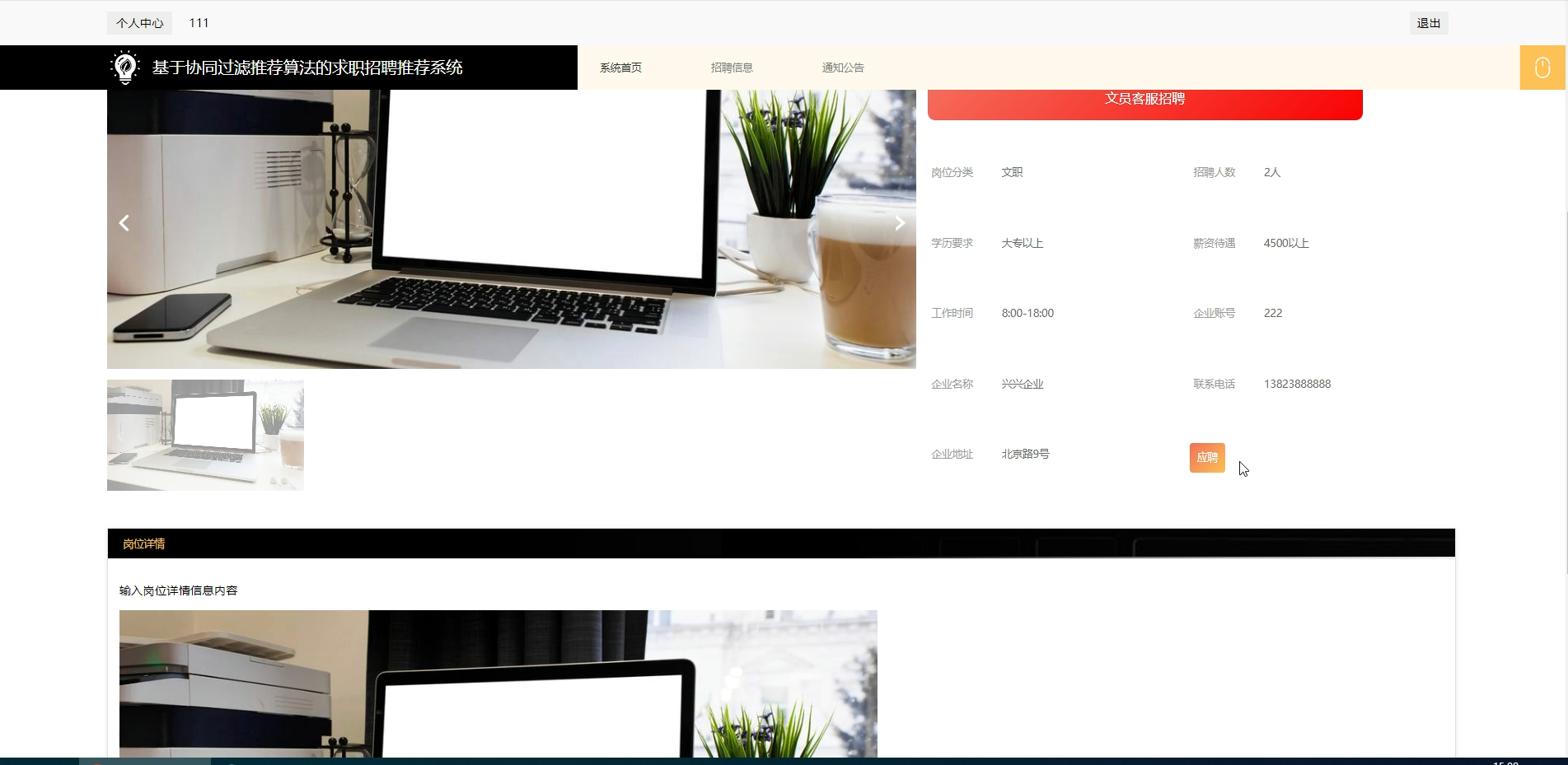
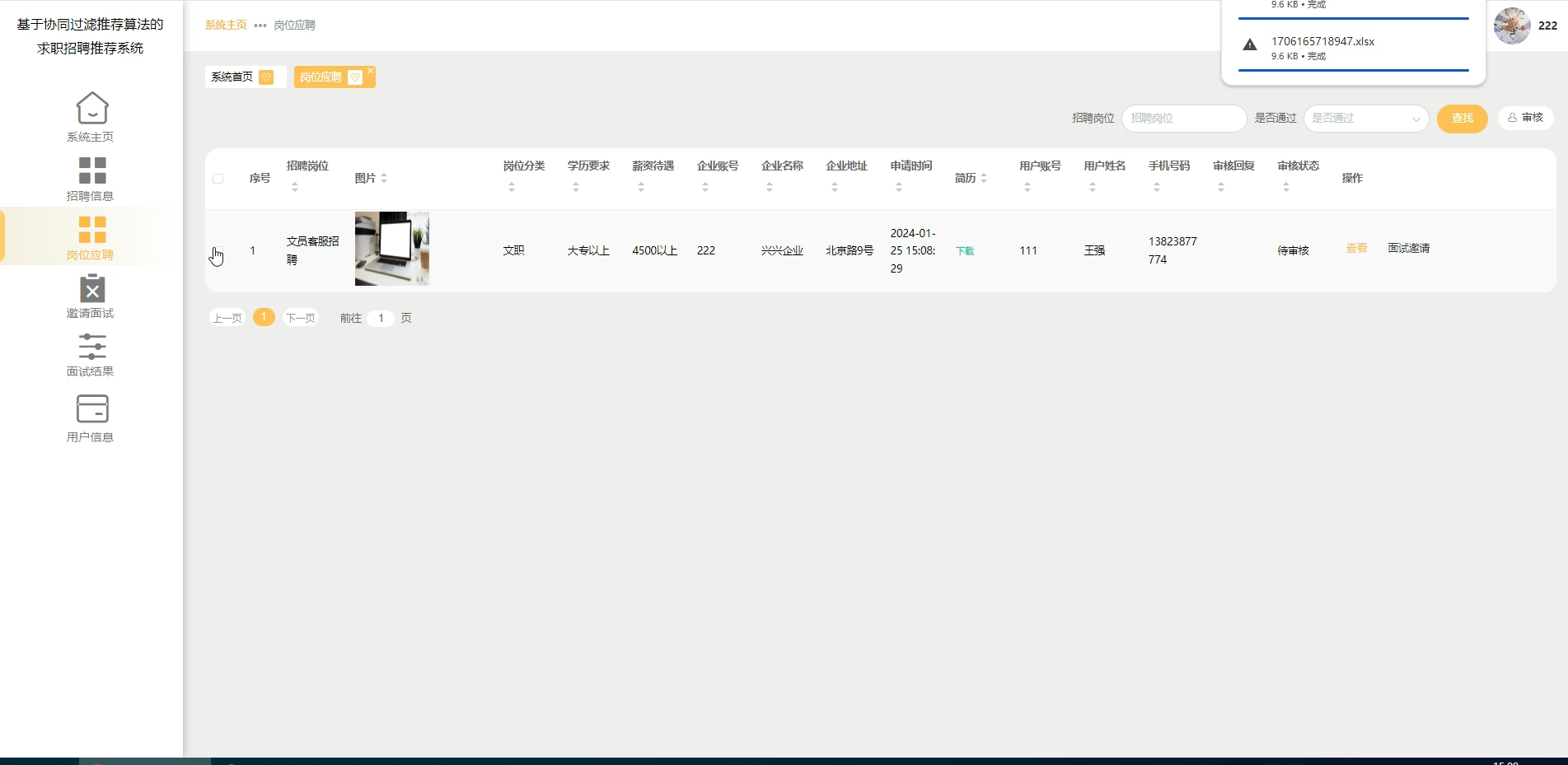
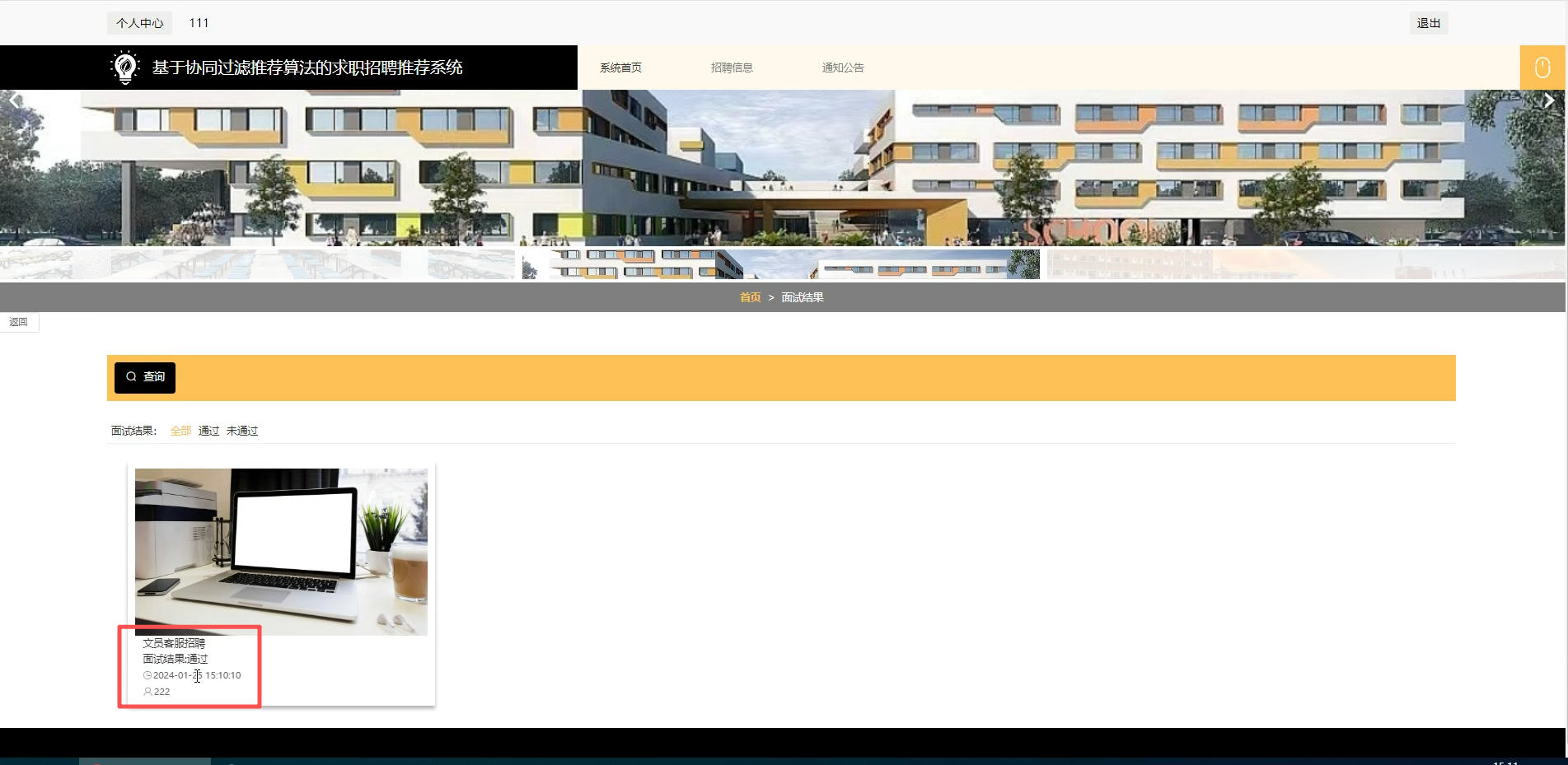
六、程序界面展示