从 Chat Completions 到 Responses:不仅仅是更改了接口这么简单

OpenAI 这次推出的 Responses API,相较于原来的chat completions接口来说,是一次“重构级”的升级,不是简单改个参数名,它改变了我们构建智能应用的方式,但是它的威力现在还远远没有显露出来。今天我想再次详细的介绍下,旧 API 和新 API 到底区别在哪?为什么任何人都应该尽早迁移?Responses API 到底强在哪里?
本文大量参考了openai 官方文档: https://platform.openai.com/docs/guides/migrate-to-responses![]() https://platform.openai.com/docs/guides/migrate-to-responses
https://platform.openai.com/docs/guides/migrate-to-responses
一、旧 API:Chat Completions / Assistants API 的局限到底是什么?
无论你之前用的是:Chat Completions API(最常见)还是 Assistants API(支持工具、文件、线程的那一套)
你一定踩过下面这些坑:
1. Chat Completions 最大的问题——全部上下文必须每次重发
你要维持对话,就得维护一个类似这样的结构:
[{"role": "system", "content": "XXXX"},{"role": "user", "content": "问题1"},{"role": "assistant", "content": "回答1"},{"role": "user", "content": "问题2"}
]
下一轮你还得重新发一次全量消息。
这几个问题你应该很熟:历史越多,请求越大,成本越高,你要自己维护“上下文管理” ,模型并不知道什么叫“会话 ID”,你不发它不知道
如果你做的应用对话很多(比如智能客服、AI 教师、AI 编程助手),你一定深受其害。
2. Assistants API 的问题——太重、太非标准、太封闭
Assistants API 是个有野心的尝试,但事实证明:太多专用术语(thread、run、step),太多专用抽象(file search、code interpreter),工具调用流程复杂,文档写得像产品思路演示,而不是工程 API,很多事件格式、生命周期不透明,对工程师来说,它就是:好用但重、强大但不灵活。
OpenAI 也意识到这点,所以 Responses API 直接把 Assistants API 包装掉了。
二、Responses API:到底“新”在哪里?
如果只用一句话来描述,就是:
Responses API = 统一的、事件驱动的、有状态的下一代模型调用接口。
下面我把核心差异直接列出来。
1. 统一接口:所有输入都叫 input,所有输出都叫 response
旧 API:
1). completions 用 prompt 2). chat completions 用 messages 3). assistants 用 input_text、input_image、input_audio…… 4). 工具用 functions / tools / file_ids,又不统一
Responses API:
"input": [{"type": "message", "role": "user", "content": "..."},{"type": "image", "image_url": "..."},{"type": "audio", "audio_url": "..."},{"type": "response_output", "id": "..."} // 甚至可以喂回上一次模型输出
]
一次性解决所有输入类型统一的问题。
2. 有状态对话:你终于不用每次发全部历史了
Responses API 原生带: conversation_id 以及 previous_response_id
这意味着:
你只发这一轮用户内容:
{"type": "message", "role": "user", "content": "继续刚才"}
模型也能理解之前你们聊过什么。
这完全改变了长会话应用的成本结构。
3. 工具调用流程变得符合“事件驱动”思维
旧 API(function_call)的问题:
工具调用参数可能是字符串也可能是 JSON(非常坑)响应格式不一致,流式模式下工具调用难处理
Responses API 把工具调用拆成明确的事件序列,像这样:
response.output_item.added (可能是assistant文字)
response.function_call_arguments.delta (工具调用参数逐块发送)
response.function_call_arguments.done (参数结束)
---你此时执行工具---
response.function_call_output.added (你把工具结果回灌给模型)
response.completed (整轮完成)
如果你写过 WebRTC,就知道事件驱动绝对比“靠状态猜测”更清晰。
4. 更干净的流式响应(Stream)
旧 API 的流式响应是“token 流”:
{ "choices": [ { "delta": { "content": "a" }}]}
Responses API 是“事件流”:
response.output_text.delta
response.output_text.delta
response.output_text.delta
...
response.completed
你可以清晰地区分:
文本是否结束,工具调用是否进入,工具参数是否已发送完毕,模型是否已经完成本轮
做复杂 agent 系统的时候尤其关键。
5. 更适合多模态
旧 API 的图像、音频输入非常混乱:
-
有的用 base64
-
有的用 URL
-
有的要额外上传 file_id
Responses API 统一到 input item:
{"type": "input_audio","audio": {...}
}
你做多模态流水线(例如:自动转字幕 → 翻译 → 内容生成),流程清爽很多。
三、核心对比表(来源于官方文档)
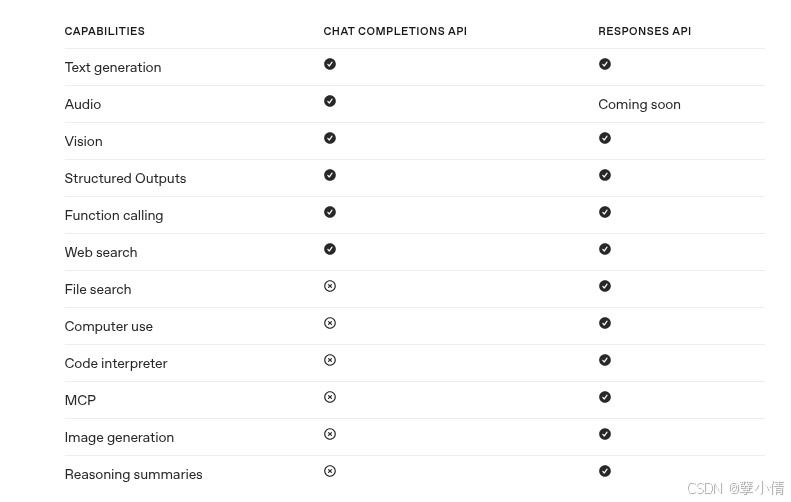
| 项目 | Chat Completions / Assistants | Responses API |
|---|---|---|
| 上下文 | 必须每次手动拼接全部历史 | 支持 conversation_id,回传上一条 response |
| 输入结构 | messages / prompt / input_text | input: [ {type: ...} ] 统一格式 |
| 工具调用 | function_call,参数可能是字符串或 JSON,不稳定 | 事件化:arguments.delta → done → output |
| 流式响应 | delta token,在复杂场景难处理 | 事件驱动,语义清晰 |
| 多模态 | 各 API 不一致 | input items 完全统一 |
| 状态管理 | 完全靠开发者维护 | 可以部分交给 OpenAI |
| 未来兼容 | 会被弃用(Assistants API 明确 2026 停用) | OpenAI 明确主推 |
这张表基本就是迁移的理由。
四、Responses API 的优势(我自己的角度)
我这几年做 AV 编解码、WebRTC、流式转写、转码 pipeline,这种系统都有一个共性:流、事件、状态。
用 Responses API 的感觉就是:
“终于不是拿着一个聊天补全器硬凹成一个 agent 框架了。”
如果把复杂的 AI 系统当成“实时图处理 pipeline”,Responses API 更像是:
-
有状态的节点
-
协议统一的输入格式
-
事件驱动的输出格式
-
可插拔的工具(像 filter 或 plugin)
这是工程意义上的统一,不是产品意义上的统一。
五、适用场景(从我的多年经验来看非常关键)
1. 智能客服 / AI 助手(长对话)
省去维护历史消息的麻烦,成本也降低。
2. 多工具、多步骤 agent
工具调用变得可控、可追踪、不再乱。
3. 多模态流水线(音频 → 文本 → 翻译 → 图文生成)
结构清晰、事件可控,适合稳定构建 pipeline。
4. 需要细粒度流式控制的应用(IDE 插件、代码助手)
可以按事件分阶段渲染,而不是收到 token 才猜测阶段。
5. 模型链式调用(RAG、推理树、规划类应用)
Responses API 正好支持“把上一次模型输出作为输入项再喂回去”。
最后想说,Responses API 是未来,不是选项,而是方向。如果你只是做简单问答,旧 API 还能撑一阵;但如果你要:做一个复杂的 agent,想接多模态能力,需要长上下文,想做类似 GPTs / DeepSeek R1 / Cursor 那种交互体验,想构建自己的“AI 工作流系统”,那你迟早要迁移到 Responses API。它不是“新接口”而已,说的夸张一点就是:
OpenAI 为未来十年智能应用设计的统一协议。