(ICLR 2019)APPNP传播用 PageRank,不用神经网络!

论文阅读:
https://arxiv.org/pdf/1810.05997
本篇文章核心贡献可以用一句话来总结:把 GNN 的 message passing 解耦,先用 MLP 做预测,再用 Personalized PageRank (PPR) 把预测在图上扩散。
这句核心话是什么意思?
传统 GNN = “学习 + 传播” 绑在一起,而APPNP = “学习(MLP)” 和 “传播(PPR)” 分开做。传统 GNN的邻居传播为: ,特征变换为:
,神经网络学习权重为:
,这就意味着学习和传播是捆绑在一起的,每加一个 GCN 层,就是再做一次:邻居传播、参数学习、非线性激活;这也就导致了如果想扩大邻域,就只能“加层”,但加层会导致oversmoothing、训练难、参数多。
而APPNP 解决了 GCN 的两个大痛点:
- GCN 层数一深就 oversmoothing(节点表示变得一样)。随着层数深 → 相当于不断做邻居平均(Laplacian smoothing),层数太深 → 所有节点 embedding 趋于一样,这称为 oversmoothing。
- GCN 的可用层数通常只有 2–3 层,因此GCN 只能看到很小的邻域(2-hop)。
- GCN 想扩大感受野必须加层、参数变多、训练变难。
如何解决问题?
GCN 的传播本质是 random walk,随机游走走太远就会变成全图 stationary distribution(与起点无关)。为解决这个问题,论文把 random walk 换成Personalized PageRank (PPR):
本质上加了“回跳(teleport)”机制,以 (1−α) 的概率走向邻居,以 α 的概率跳回根节点 i,PPR 即使传播无限次,仍然保持节点的“个性化中心性”,不会失焦,这正好解决 GCN 的 oversmoothing!
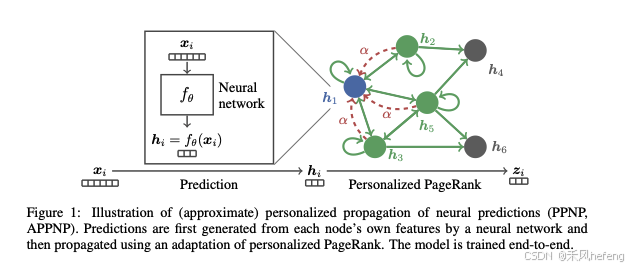
APPNP真正被使用的模型
用 Power Iteration(幂迭代)近似 PPR:
参考:
https://blog.csdn.net/fnoi2014xtx/article/details/107567629
https://blog.csdn.net/gitblog_00008/article/details/139916344