数据库知识整理——SQL数据查询(2)
SQL语言对数据库的操作十分灵活、方便,原因在于 SELECT 语句中成分丰富多样的元组,有许多可选形式,尤其是目标列和条件表达式。

SELECT基本结构
语句格式:

注意点:SOL 查询中的子句顺序为 SELECT、FROM、WHERE、GROUP BY、HAVING 和 ORDERBY。其中,SELECT、FROM 是必需的,HAVING 条件子句只能与 GROUP BY 搭配起来使用。
- SELECT子句:列出查询的属性、或者对应属性的聚合函数(如AVG、COUNT、MAX、MIN、SUM)。
- FROM子句:指定查询操作的数据表或视图,当存在多个表时,会首先执行笛卡尔积操作。
- WHERE子句:过滤行数据的条件,常用运算符:=, <>, >, <, >=, <=, BETWEEN, LIKE, IN, IS NULL等,后面不能跟聚合函数
- GROUP BY 子句:对结果集进行分组
- HAVING 子句:对分组后的结果进行过滤,通常与聚合函数一起使用
- ORDER BY 子句:对结果集进行排序
一个简单示例

对应的关系代数表达式:
![]()
上一章节中我们回顾了简单查询、内连接查询、外连接查询等查询方法,这一章节将继续补充其他的几种查询方式。
子查询
子查询也称嵌套查询。嵌套查询是指一个SELECT-FROM-WHERE 查询块可以嵌入另一个查询块之中。在 SOL 中允许多重嵌套。
例如:检索选修了课程名“MS”的学生的学号和姓名,可用连接查询和嵌套查询实现
SELECT Sno,Sname
FROM S
WHERE Sno IN (SELECT Sno
FROM SC
WHERE Cno IN (SELECT Cno
FROM C
WHERECname-' MS'))子查询还存在其他的变体:
相关子查询
相关子查询(Correlated Subquery)是一种嵌套查询,其特点在于子查询的执行依赖于外部查询的每一行数据。与普通子查询不同,相关子查询会为外部查询的每一行单独执行一次,通过引用外部查询的列来建立关联关系。
例子:查找工资高于部门平均工资的员工
SELECT e1.employee_id, e1.salary, e1.department_id
FROM employees e1
WHERE e1.salary > (SELECT AVG(e2.salary)FROM employees e2WHERE e2.department_id = e1.department_id
);EXISTS子查询
EXISTS子查询是一种SQL条件运算符,用于检查子查询是否返回至少一行结果。若子查询结果非空,EXISTS返回TRUE,否则返回FALSE。通常用于替代IN子查询,尤其在处理大数据集时性能更优。
例子:查询存在订单的客户
SELECT customer_id, name
FROM customers c
WHERE EXISTS (SELECT 1 FROM orders o WHERE o.customer_id = c.customer_id
);聚集函数
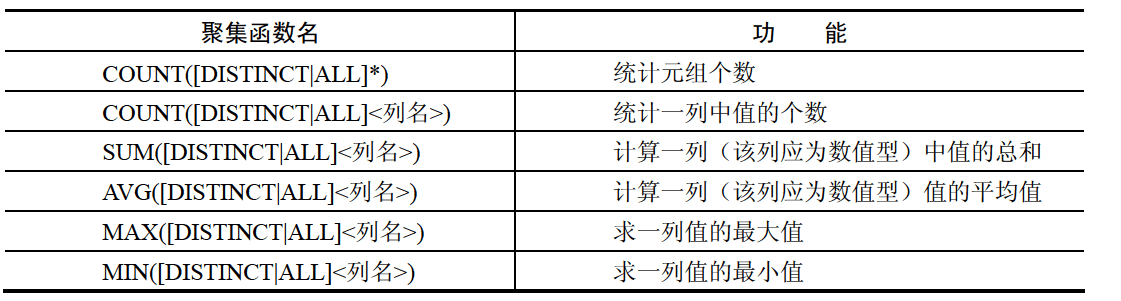
聚集函数是以一个值的集合为输入,返回单个值的函数。SQL 提供了5个预定义聚集函数:平均值 AVG、最小值 MIN、最大值 MAX、求和 SUM 以及计数 COUNT。
注意点:
- 不可直接在
WHERE子句中使用,需通过HAVING过滤聚合结果。 - 聚集函数忽略
NULL值(COUNT(*)除外)。 - 使用
DISTINCT排除重复值。
使用 ANY 和 AIL, 谓词必须同时使用比较运算符,其含义及等价的转换关系如下图所示。
用聚集函数实现子査询通常比直接用 AIL 或 ANY 查询效率要高。

例子:
- 查询课程 C1的最高分和最低分以及高低分之间的差距
SELECT MAX(G),MIN(G),MAX(G)-MIN(G)
FROM Sc
WHERE Cno='C1'- 查询其他系比计算机系CS所有学生年龄都要小的学生的姓名及年龄。
SELECTSname, Age
FROM S
WHERE Age<ALL(SELECT Age
FROM S
WHERE SD='CS’)
AND SD<>'CS'分组查询
GROUP BY子句
在 WHERE 子句后面加上 GROUP BY 子句可以对元组进行分组,保留字 GROUP BY 后面跟着一个分组属性列表。最简单的情况是 FROM 子句后面只有一个关系,根据分组属性对它的元组进行分组。SELECT 子句中使用的聚集操作符仅用在每个分组上。
注意点:
ORDER BY可对聚合结果排序,但需注意字段是否在SELECT列表中
例子:学生数据库中的 SC 关系,查询每个学生的平均成绩。
SELECT Sno,AVG(Grade)
FROM SC
GROUP BY SnoHAVING 子句
假如元组在分组前按照某种方式加上限制,使得不需要的分组为空,在 GROUP BY 子句后面跟一个 HAVING 子句即可。
注意项:
- 空值在任何聚集操作中被忽视。它对求和、求平均值和计数都没有影响。它也不能是某列的最大值或最小值。例如,COUNT(*)是某个关系中所有元组数目之和,但 COUNT(A)却是A属性非空的元组个数之和。
- NULL 值又可以在分组属性中看作是一个一般的值。例如,在 SELECT A,AVG(B) FORMR 中,当A的属性值为空时,就会统计 A-NULL,的所有元组中 B的均值。
例子:
供应商数据库中的 S、P、J、SPJ 关系,查询某工程至少用了三家供应商(包含三家)供应的零件的平均数量,并按工程号的降序排列。
SELECT Jno, AVG(Qty)
FROM SPJ
GROUP BY Jno
HAVING COUNT(DISTINCT(Sno))>2
ORDER BY Jno DESC;执行结果:

视图查询
针对视图进行的查询操作,与基本表的操作大致相同。
注意点:
- 系统执行该语句时,通常先将其转换成等价的对基本表的查询,然后执行查询语句。
例子:建立“计算机系”(CS 表示计算机系)学生的视图,并要求进行修改、插入操作时保证该视图只有计算机系的学生。
CREATE VIEW CS-STUDENT
AS SELECT Sno, Sname, Sage, Sex
FROM Student
WHERE SD='CS'
WITH CHECK OPTION:此时查询计算机系年龄小于 20 岁的学生的学号及年龄的 SQL 语句如下:
SELECT Sno, Age FORM CS-STUDENT WHERE SD-'CS' AND Age<20;字符串操作查询
对于字符串进行的最常用的操作是使用操作符LIKE的模式匹配。使用两个特殊的字符来描述模式:
- %:匹配任意字符串
- _:匹配任意一个字符
注意点:
- 该操作是大小写敏感的
- “_”匹配只含两个字符的字符串;“_%”匹配至少包含两个字符的字符串。
- Marry%匹配任何以 Marry 开头的字符串;%idge%匹配任何包含 idge 的字符串,例如Marryidge、Rock Ridge、Mianus Bridge 和 Ridgeway。
例子:
学生关系模式为(Sno,Sname,Sex,SD,Age,Add),其中,Sno 为学号,Sname 为姓名,Sex 为性别,SD为所在系,Age为年龄,Add为家庭住址。
(1)家庭住址包含“科技路”的学生的姓名。
SELECT Sname
FROM S
WHERE Add LIKE'%科技路%'(2)名字为“晓军”的学生的姓名、年龄和所在系。
SELECT Sname,Age,SD
FROM S
WHERE Sname LIKE'_晓军'为了使模式中包含特殊模式字符(即%和_),在 SOL 中允许使用 ESCAPE 关键词来定义转义符。转义符紧靠着特殊字符,并放在它的前面,表示该特殊字符被当成普通字符。例如,在 LIKE 比较中使用 ESCAPE 关键词来定义转义符,例如使用反斜杠“\”作为转义符:
- LIKE 'ab\%cd%'ESCAPE '\',匹配所有以 ab%cd 开头的字符串
- LIKE 'ab\\cd%'ESCAPE '\',匹配所有以 ab\cd 开头的字符串。