DAPO(Dynamic sAmpling Policy Optimization)
DAPO是一种直接基于“优势函数 Advantage”来优化策略的对齐方法,不需要奖励模型,也不需要 KL 惩罚,是 RLHF 的轻量级替代方案。
首先看两者公式:
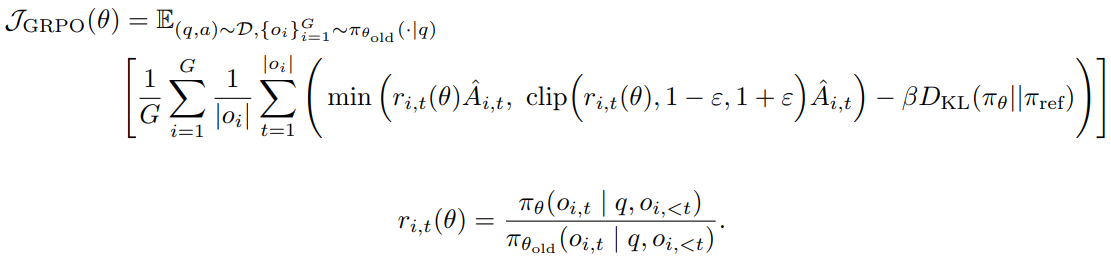

1、移除KL散度
KL惩罚项用于调节在线策略和冻结参考策略之间的散度。在RLHF场景中,RL的目标是对齐模型行为而不偏离初始模型太远。然而,在训练长链思考推理模型期间,模型分布可能与初始模型有显著差异,因此这一限制不是必需的。因此,我们将从提出的算法中排除KL项。
2、使用 Clip-Higher
在使用常规 PPO 或 GRPO 的实验中,作者观察到 策略熵快速下降(entropy collapse),即模型输出趋于高度确定性,探索受限,这会阻碍训练和扩展。
原因在于 PPO-Clip 的上界裁剪(upper clip)
-
PPO-Clip 限制了重要性采样比的变化幅度,以保持训练稳定。
-
但是对低概率“探索”动作(exploration tokens)而言,上界裁剪过紧,导致它们的概率很难增加;而高概率“利用”动作(exploitation tokens)则容易进一步被放大。
-
举例:ε=0.2 时,高概率动作从 0.9 增加到 1.08 很容易,但低概率动作从 0.01 只能增加到 0.012,提升有限。
-
实验发现,上裁剪后的低概率动作平均概率仍然很低(<0.2),说明探索受限。
为解决这个问题,作者提出 Clip-Higher 策略:
-
将上下裁剪范围解耦为 ε_low 和 ε_high。
-
增加 ε_high,为低概率“探索”动作提供更大的增长空间,从而提升策略熵和样本多样性。
-
保持 ε_low 不变,避免抑制低概率动作导致采样空间坍塌。
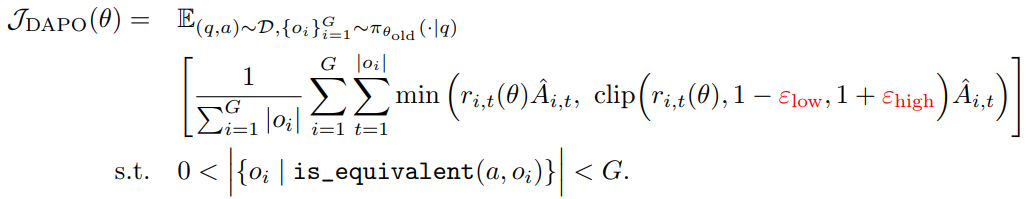
3、Dynamic Sampling
现有的强化学习算法(如 GRPO)在处理某些提示(prompt)时,如果所有输出都完全正确(accuracy = 1),会导致优势函数(advantage)为零,从而产生零策略梯度。零梯度会使梯度幅度减小、对噪声更敏感,降低样本效率。随着训练进行,完全正确或完全错误的样本数量增加,导致每个批次中有效提示数量减少,使梯度方差增大、训练信号减弱。为了解决这个问题,作者提出 对完全正确(accuracy=1)或完全错误(accuracy=0)的提示进行过采样和过滤,确保每个批次中只包含能够产生有效梯度的样本,从而保持批次大小和梯度信号的稳定。采样成本动态调整,训练前会持续采样,直到批次被有效样本填满。
4、Token-Level Loss
原始 GRPO 使用 样本级损失(sample-level loss):先在每个样本内按 token 平均,再跨样本汇总,最终每个样本权重相同。
问题在 长链式推理(long-CoT)场景下:
-
长样本 token 权重偏低:高质量长样本的推理模式难以充分学习。
-
长样本低质量模式难以惩罚:如乱码、重复词,导致策略熵过高、响应长度不受控。
为解决这个问题,作者提出 Token-level Policy Gradient Loss:
-
更长的序列在梯度更新中能有更大影响力。
-
每个 token 的生成模式都能被平等地奖励或抑制,无论其所在样本长度如何。

5、Overlong Punishment
在 RL 训练中,生成通常有最大长度限制,超长样本会被截断。对截断样本的不当奖励设计会引入奖励噪声,干扰训练。
-
默认做法是对截断样本给予惩罚,但这样可能会误伤合理的长推理,使模型对推理有效性产生困惑。
-
作者提出 Overlong Filtering 策略:对截断样本的损失进行屏蔽(mask),不纳入梯度计算。
-
实验表明,这种方法能 显著稳定训练并提升性能。
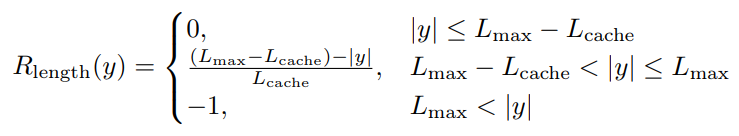
Soft Overlong Punishment 通过长度感知奖励惩罚,鼓励模型生成不过长的合理回答。
参考资料:
(19 封私信 / 80 条消息) DAPO详解 - 知乎