大模型架构和原理二
大模型架构和原理二
- 1、请解释掩码(mask)在注意力机制中的作用,并说明masked_fill函数的具体实现原理
- 2、请详细解释Transformer架构中交叉注意力机制的工作原理和数学表达
- 3、请基于HuggingFace模型配置文件,现场计算一个大型语言模型的总参数量
- 4、请解释神经网络中梯度消失和梯度爆炸现象产生的原因,针对梯度消失和梯度爆炸问题,有哪些常用的解决方案和技术?
- 5、请详细解释ResNet和Transformer中残差连接的作用机制,包括其解决的问题、具体实现方式以及对模型训练效果的影响。
- 6、请详细介绍旋转位置编码(ROPE)的原理、数学表达和在Transformner中的应用优势。
- 7、除了Attention机制,Transformer模型架构中还包含哪些关键组件?请简述它们的作用。
- 8、请详细描述Transformer架构的核心组件实现细节,包括自注意力机制、位置编码、前馈网络等,并讨论在实际实现中需要注意的技术要点和常见陷阱
- 9、请详细阐述BERT模型的核心设计思想、架构特点,以及其在自然语言理解任务中的优势
- 10、请详细介绍Transformer架构的核心原理,并比较分析BERT与其他预训练模型的技术特点和适用场景
- 11、请详细介绍sigmoid、softmax和ReLU激活函数的数学表达式、特性、优缺点以及各自的适用场景
- 12、残差连接(Residual Connection)是深度神经网络中的一种重要设计。请详细阐述它在ResNet或Transformer架构中的作用、工作原理以及带来的好处
- 13、在Transformer架构中,为什么要使用多头注意力机制而不是单头注意力?请解释多头注意力的优势和作用。
- 14、请阐述在多头自注意力机制中mask的作用原理,并详细说明mask是如何应用到attentionscores上的具体实现方式。
- 15、请解释为什么在现代大语言模型中普遍采用decoder-only架构,而不是encoder-decoder或encoder-only架构?这种架构选择有哪些优势和局限性?
- 16、LSTM主要解决了传统RNN中的哪些核心问题?请详细说明其解决梯度消失和长期依赖问题的机制。
- 17、请解释多头注意力机制中,如何从注意力权重矩阵(attn_weights)和值矩阵(V)计算得到最终的输出(out)。并说明在计算完成后,通常需要进进行的transpose和view/reshape操作的具体目的和作用
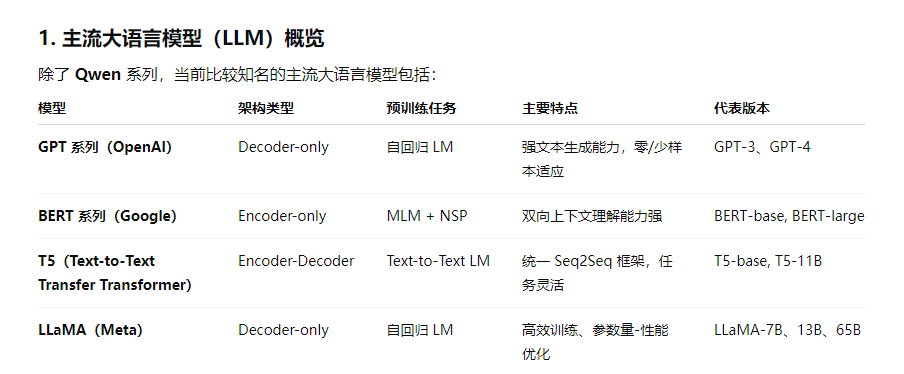
- 18、除了Qwen之外,您还了解哪些主流大语言模型?请详细阐述LLaMA模型的架构设计特点,以及它在模型结构和训练方法上的主要贡献和创新点
- 19、在Transformer模型的forward方法中,输入张量x和注意力掩码mask的维度要求分别是多少?请说明其数学含义和设计原理
- 20、请阐述文本嵌入(Text Embedding)的基本原理和方法,以及这些向量表示在大语言模型中的具体应用和重要性。
1、请解释掩码(mask)在注意力机制中的作用,并说明masked_fill函数的具体实现原理




2、请详细解释Transformer架构中交叉注意力机制的工作原理和数学表达



3、请基于HuggingFace模型配置文件,现场计算一个大型语言模型的总参数量
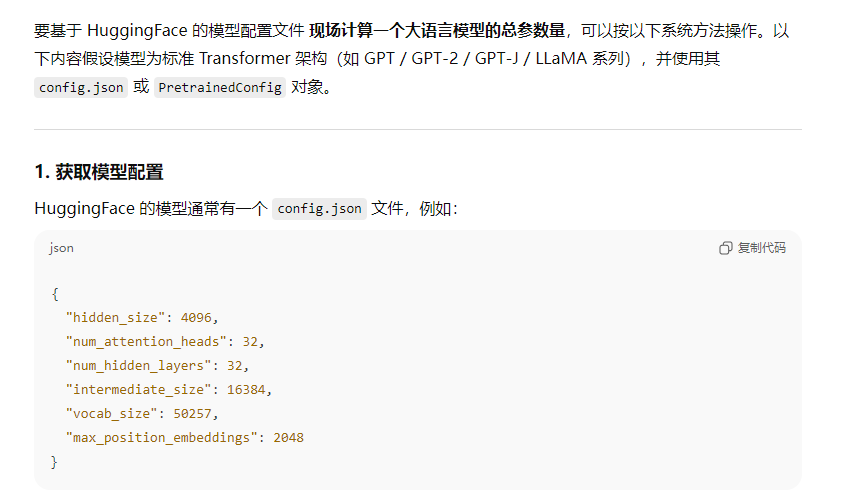
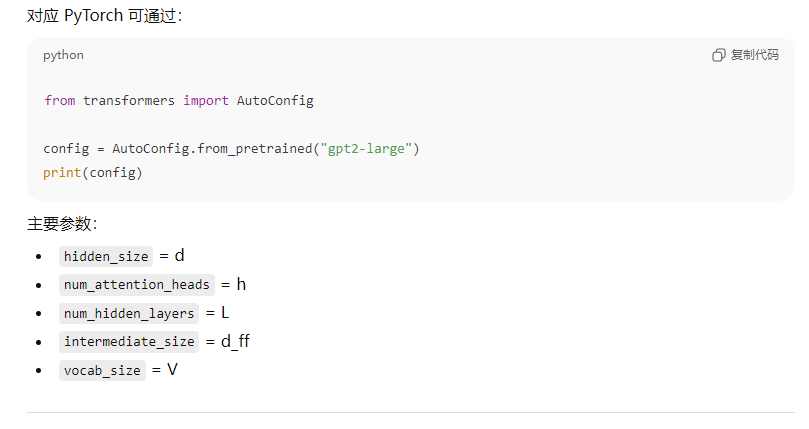




4、请解释神经网络中梯度消失和梯度爆炸现象产生的原因,针对梯度消失和梯度爆炸问题,有哪些常用的解决方案和技术?




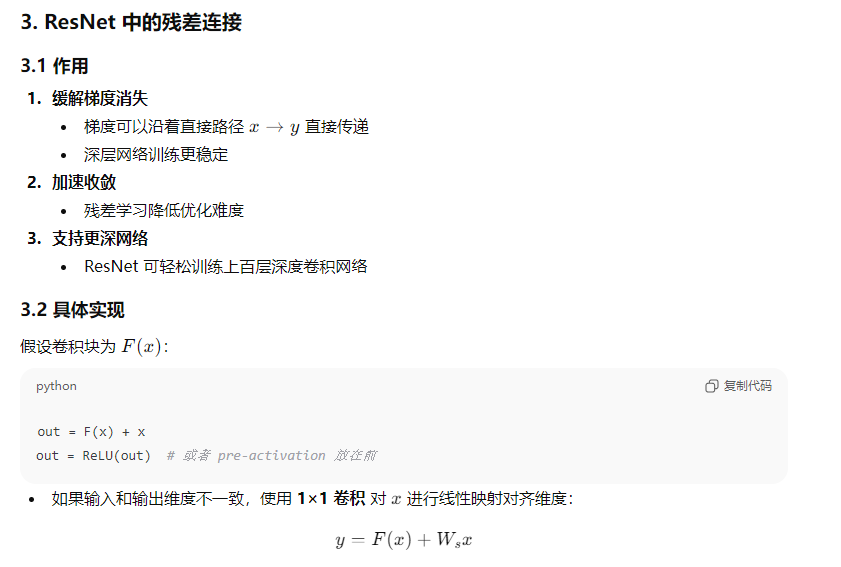
5、请详细解释ResNet和Transformer中残差连接的作用机制,包括其解决的问题、具体实现方式以及对模型训练效果的影响。



6、请详细介绍旋转位置编码(ROPE)的原理、数学表达和在Transformner中的应用优势。



7、除了Attention机制,Transformer模型架构中还包含哪些关键组件?请简述它们的作用。



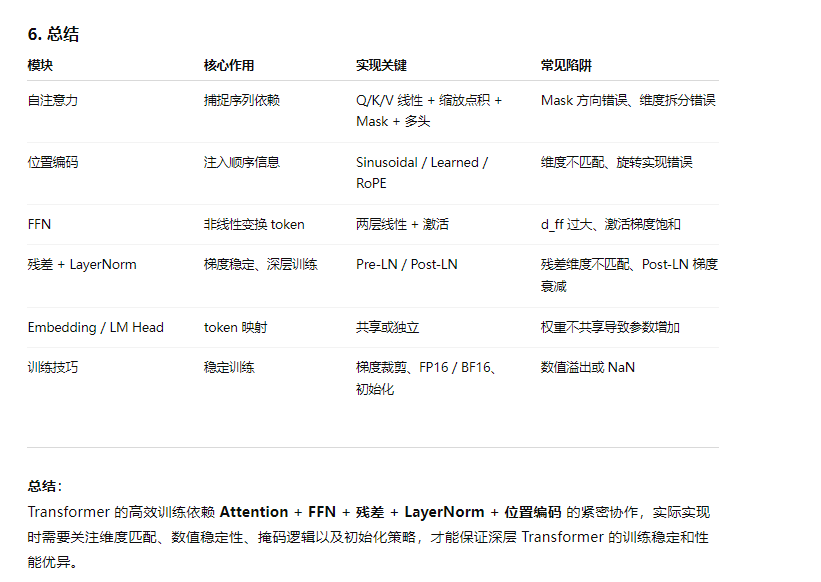
8、请详细描述Transformer架构的核心组件实现细节,包括自注意力机制、位置编码、前馈网络等,并讨论在实际实现中需要注意的技术要点和常见陷阱




9、请详细阐述BERT模型的核心设计思想、架构特点,以及其在自然语言理解任务中的优势



10、请详细介绍Transformer架构的核心原理,并比较分析BERT与其他预训练模型的技术特点和适用场景




11、请详细介绍sigmoid、softmax和ReLU激活函数的数学表达式、特性、优缺点以及各自的适用场景




12、残差连接(Residual Connection)是深度神经网络中的一种重要设计。请详细阐述它在ResNet或Transformer架构中的作用、工作原理以及带来的好处



13、在Transformer架构中,为什么要使用多头注意力机制而不是单头注意力?请解释多头注意力的优势和作用。


14、请阐述在多头自注意力机制中mask的作用原理,并详细说明mask是如何应用到attentionscores上的具体实现方式。


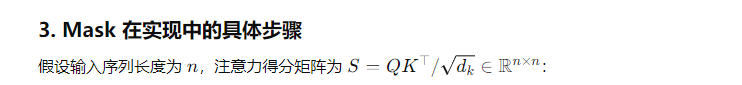
Padding mask
# seq_mask: [batch_size, seq_len], 1表示有效token, 0表示padding
mask = (seq_mask[:, None, :] == 0) # shape: [batch_size, 1, seq_len]
mask = mask.float() * (-1e9) # 将padding位置设为 -∞Padding mask
causal_mask = torch.triu(torch.ones(seq_len, seq_len), diagonal=1) * (-1e9)
# 上三角设为 -∞,保证当前位置只能看到前面tokenPadding mask
attn_scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(d_k)
attn_scores = attn_scores + mask # mask 作用在 logits 上
attn_weights = torch.softmax(attn_scores, dim=-1)
output = torch.matmul(attn_weights, V)
15、请解释为什么在现代大语言模型中普遍采用decoder-only架构,而不是encoder-decoder或encoder-only架构?这种架构选择有哪些优势和局限性?




16、LSTM主要解决了传统RNN中的哪些核心问题?请详细说明其解决梯度消失和长期依赖问题的机制。




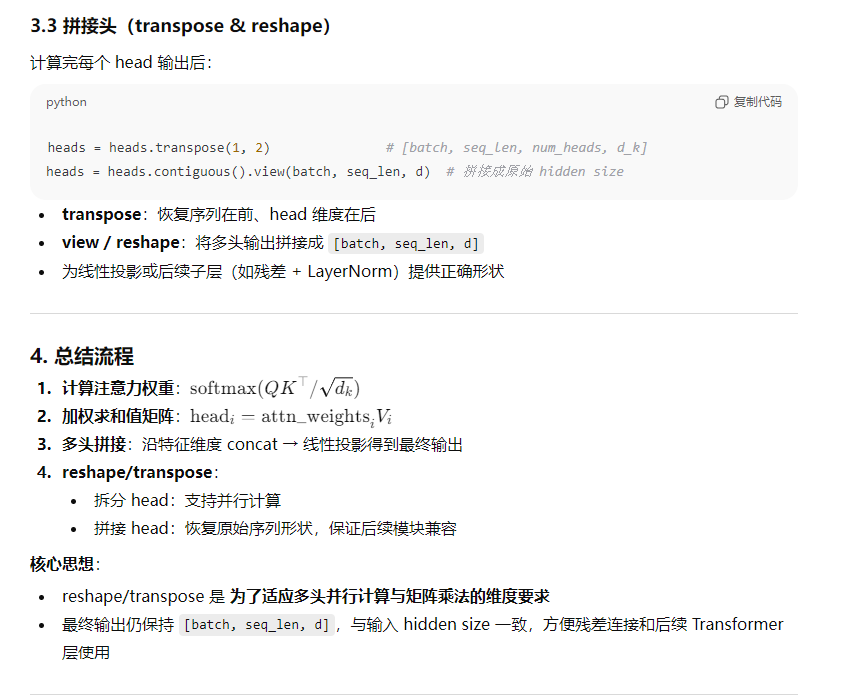
17、请解释多头注意力机制中,如何从注意力权重矩阵(attn_weights)和值矩阵(V)计算得到最终的输出(out)。并说明在计算完成后,通常需要进进行的transpose和view/reshape操作的具体目的和作用



18、除了Qwen之外,您还了解哪些主流大语言模型?请详细阐述LLaMA模型的架构设计特点,以及它在模型结构和训练方法上的主要贡献和创新点



19、在Transformer模型的forward方法中,输入张量x和注意力掩码mask的维度要求分别是多少?请说明其数学含义和设计原理



20、请阐述文本嵌入(Text Embedding)的基本原理和方法,以及这些向量表示在大语言模型中的具体应用和重要性。



