Databend SQL nom Parser 性能优化
nom 简介
nom 是 Rust 生态中非常受欢迎的解析框架:性能优秀、组合灵活,并且能很好地利用 Rust 的类型系统。Databend 在 SQL 表达式和语句解析上大量使用 nom,开发体验不错,可读性也高。
不过,组合式 parser 容易在不经意间埋下性能隐患——尤其是当多个分支结构相似、再加上递归嵌套时,回溯成本会指数级膨胀。
/// 一个简单的 parser:匹配 "foo" 或 "bar"
fn foo_or_bar(input: &str) -> IResult<&str, &str> {alt((tag("foo"),tag("bar"),))(input)
}问题案例:function 嵌套拖慢解析
一次用户反馈里,我们收到了一条解析 20 分钟都跑不完的 SQL。火焰图清楚地显示:函数解析反复尝试、层层回溯。
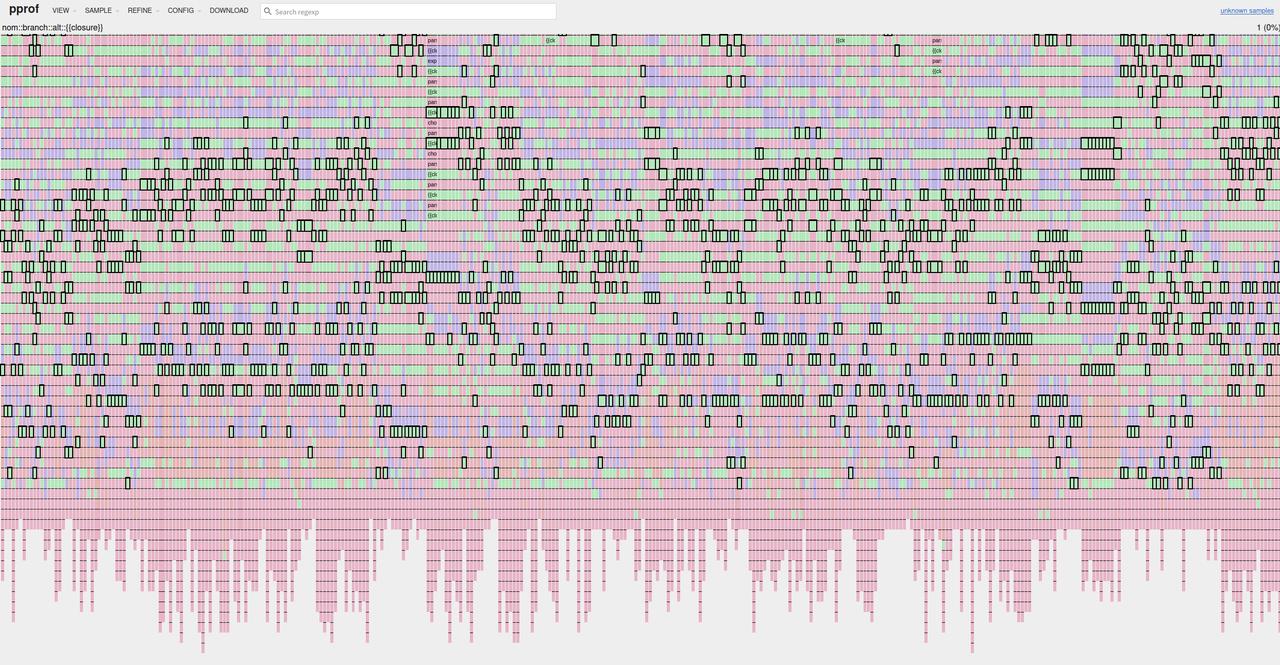
select json_object_insert(json_object_insert(json_object_insert(json_object_insert(json_object_insert('{}'::variant,'email_address', 'gokul', true,'home_phone', 12345, true,'mobile_phone', 345678, true,'race_code', 'M', true),'race_desc', 'm', true,'marital_status_code', 'y', true,'marital_status_desc', 'yu', true,'prefix', 'hj', true),'first_name', 'g', true,'last_name', 'p', true,'deceased_date', '2085-05-07', true,'birth_date', '6789', true),'middle_name', '89', true,'middle_initial', '0789', true,'gender_code', '56789', true,'gender_desc', 'm', true),'home_phone_line_type', 'uyt', true,'mobile_phone_line_type', 4, true);当时的函数解析写法大致如下:
let function_call = map(rule! {#function_name~ "(" ~ DISTINCT? ~ #comma_separated_list0(subexpr(0))? ~ ")"},|(name, _, opt_distinct, opt_args, _)| ExprElement::FunctionCall { .. },
);
let function_call_with_lambda = map(rule! {#function_name~ "(" ~ #subexpr(0) ~ "," ~ #lambda_params ~ "->" ~ #subexpr(0) ~ ")"},|(name, _, arg, _, params, _, expr, _)| ExprElement::FunctionCall { .. },
);
let function_call_with_window = map(rule! {#function_name~ "(" ~ DISTINCT? ~ #comma_separated_list0(subexpr(0))? ~ ")"~ #window_function},|(name, _, opt_distinct, opt_args, _, window)| ExprElement::FunctionCall { .. },
);
let function_call_with_within_group_window = map(rule! {#function_name~ "(" ~ DISTINCT? ~ #comma_separated_list0(subexpr(0))? ~ ")"~ #within_group~ #window_function?},|(name, _, opt_distinct, opt_args, _, order_by, window)| ExprElement::FunctionCall { .. },
);
let function_call_with_params_window = map(rule! {#function_name~ "(" ~ #comma_separated_list1(subexpr(0)) ~ ")"~ "(" ~ DISTINCT? ~ #comma_separated_list0(subexpr(0))? ~ ")"~ #window_function?},|(name, _, params, _, _, opt_distinct, opt_args, _, window)| ExprElement::FunctionCall { .. },
);rule! {#function_call_with_lambda : "`function(..., x -> ...)`"| #function_call_with_window : "`function(...) OVER ([ PARTITION BY <expr>, ... ] [ ORDER BY <expr>, ... ] [ <window frame> ])`"| #function_call_with_within_group_window: "`function(...) [ WITHIN GROUP ( ORDER BY <expr>, ... ) ] OVER ([ PARTITION BY <expr>, ... ] [ ORDER BY <expr>, ... ] [ <window frame> ])`"| #function_call_with_params_window : "`function(...)(...) OVER ([ PARTITION BY <expr>, ... ] [ ORDER BY <expr>, ... ] [ <window frame> ])`"| #function_call : "`function(...)`"
}这段代码对阅读者非常友好,但也有两个特征:
- 所有分支都以
function(...)起手; - 深度优先的
alt每次匹配失败都会回溯到下一个分支。
在上面这种五层嵌套、每层模式数量为 5 的场景里,最常见的 “纯函数调用” 分支放在最后,实际要尝试 5^5 = 3125 次才能命中。复杂度飙升到 O(m^n),性能立刻崩掉。
优化方案一:折叠相似分支,避免指数级回溯
问题根源是“结构高度相似 + 递归 + 深度优先回溯”。我们把多个分支折叠成一次解析,再根据匹配到的后缀来决定具体的函数类型,相当于把流程变成了“先整体匹配,再分类处理”的广度优先思路:
let function_call_body = map_res(rule! {"(" ~ DISTINCT? ~ #subexpr(0)? ~ ","? ~ (#lambda_params ~ "->" ~ #subexpr(0))? ~ #comma_separated_list1(subexpr(0))? ~ ")"~ ("(" ~ DISTINCT? ~ #comma_separated_list0(subexpr(0))? ~ ")")?~ #within_group?~ #window_function?},|(_,opt_distinct_0,first_param,_,opt_lambda,params_0,_,params_1,order_by,window,)| {match (first_param,opt_lambda,opt_distinct_0,params_0,params_1,order_by,window,) {(Some(first_param),Some((lambda_params, _, arg_1)),None,None,None,None,None,) => Ok(FunctionCallSuffix::Lambda { .. }),(Some(first_param),None,None,params_0,Some((_, opt_distinct_1, params_1, _)),None,window,) => Ok(FunctionCallSuffix::ParamsWindow { .. }),(first_param, None, opt_distinct, params, None, Some(order_by), window) => {Ok(FunctionCallSuffix::WithInGroupWindow { .. })}(first_param, None, opt_distinct, params, None, None, Some(window)) => {Ok(FunctionCallSuffix::Window { .. })}(first_param, None, opt_distinct, params, None, None, None) => {Ok(FunctionCallSuffix::Simple { .. })}_ => Err(nom::Err::Error(ErrorKind::Other("Unsupported function format",))),}},
);一次解析完成所有结构匹配,再根据分支类型装配结果,直接消除了指数级回溯。该优化落地后,原先需要几十分钟的 SQL 如今只要几十毫秒。
优化方案二:高频 Token 解析直接 hard code
function 回溯问题解决后,我们又在表达式解析上抓到了第二个热点:Binary/Unary/Json Operator 等简单 token 被频繁命中,而原先的实现是 alt + value + rule! 的组合。这个组合每次调用都要:
- 构造闭包;
- 包装错误信息;
- 构建返回值;
- 再进入下一层 parser。
对于几乎只包含单个 token 的场景,直接手写匹配会快得多。Databend 的 expr 有 49 个分支,热度非常高,把这些分支 hard code 掉收益极可观。以下是 json_op 替换前后的实现:
// 原实现:alt + rule!
pub fn json_op(i: Input) -> IResult<JsonOperator> {alt((value(JsonOperator::Arrow, rule! { "->" }),value(JsonOperator::LongArrow, rule! { "->>" }),value(JsonOperator::HashArrow, rule! { "#>" }),value(JsonOperator::HashLongArrow, rule! { "#>>" }),value(JsonOperator::Question, rule! { "?" }),value(JsonOperator::QuestionOr, rule! { "?|" }),value(JsonOperator::QuestionAnd, rule! { "?&" }),value(JsonOperator::AtArrow, rule! { "@>" }),value(JsonOperator::ArrowAt, rule! { "<@" }),value(JsonOperator::AtQuestion, rule! { "@?" }),value(JsonOperator::AtAt, rule! { "@@" }),value(JsonOperator::HashMinus, rule! { "#-" }),))(i)
}// 新实现:hard code
macro_rules! op_branch {($i:ident, $token_0:ident, $($kind:ident => $op:expr),+ $(,)?) => {match $token_0.kind {$(TokenKind::$kind => return return_op($i, 1, $op),)+_ => (),}};
}pub(crate) fn json_op_simple(i: Input) -> IResult<JsonOperator> {if let Some(token_0) = i.tokens.first() {op_branch!(i, token_0,RArrow => JsonOperator::Arrow,LongRArrow => JsonOperator::LongArrow,HashRArrow => JsonOperator::HashArrow,HashLongRArrow => JsonOperator::HashLongArrow,Placeholder => JsonOperator::Question,QuestionOr => JsonOperator::QuestionOr,QuestionAnd => JsonOperator::QuestionAnd,AtArrow => JsonOperator::AtArrow,ArrowAt => JsonOperator::ArrowAt,AtQuestion => JsonOperator::AtQuestion,AtAt => JsonOperator::AtAt,HashMinus => JsonOperator::HashMinus,);}Err(nom::Err::Error(Error::from_error_kind(i,ErrorKind::Other("expecting `->`, '->>', '#>', '#>>', '?', '?|', '?&', '@>', '<@', '@?', '@@', '#-', or more ..."),)))
}#[inline]
fn return_op<T>(i: Input, start: usize, op: T) -> IResult<T> {Ok((i.slice(start..), op))
}Benchmark
bench fastest │ slowest │ median │ mean │ samples │ iters
╰─ dummy │ │ │ │ │├─ test_json_op_parse 413.8 ns │ 2.817 µs │ 441.3 ns │ 482.6 ns │ 100 │ 100╰─ test_json_op_parse_simple 35.41 ns │ 54.89 ns │ 37.1 ns │ 37.61 ns │ 100 │ 6400hard code 版本能带来约 10 倍的收益。
ASM 分析:硬件视角的差异
借助 cargo asm -p databend-common-ast --lib databend_common_ast::parser::expr::json_op,我们对比了两种实现的汇编:
| 对比点 | alt + value + rule! | hard code |
|---|---|---|
| 栈内存使用量 | sub rsp, 288,每次调用都要分配 288 字节 | 几乎无显式栈分配 |
| 初始化逻辑 | 运行时逐项构造数组(字符串指针、长度、标志位) | 直接跳转静态表或编译期常量 |
| 寄存器操作 | 大量 mov、lea,说明在构建临时数据 | 少量跳表与分支,路径短 |
| 函数调用 | 调 <Alt>::choice,参数来自刚构造的数组 | 调同一函数,但参数是静态常量 |
| 代码长度 | 很长、展开明显 | 精简,便于 CPU 预测/缓存 |
| 性能结论 | 每次解析都重复构造数据,吞吐量低 | 纯分支判断,常量折叠,性能稳定 |
经验总结
- 合并结构相似的 parser,避免深度优先 + 回溯导致的指数级爆炸。
- 高频、简单 token 的解析直接 hard code,省掉闭包、错误包装等额外成本。
- 及时查看火焰图,能发现异常深的解析栈。
- 必要时对热点路径做汇编级分析,更容易验证优化方向。
这两项优化落地后,Databend 的函数调用解析从分钟级降到毫秒级,表达式解析也获得了量级上的性能提升。
关于 Databend
Databend 是一款开源、弹性、低成本,基于对象存储也可以做实时分析的新式湖仓。期待您的关注,一起探索云原生数仓解决方案,打造新一代开源 Data Cloud。
👨💻 Databend Cloud:databend.cn
📖 Databend 文档:docs.databend.cn
💻 Wechat:Databend
✨ GitHub:github.com/databendlab…