(论文速读)面向实用的实时神经视频压缩
论文题目:Towards Practical Real-Time Neural Video Compression(面向实用的实时神经视频压缩)
会议:CVPR2025
摘要:我们介绍了一种实用的实时神经视频编解码器(NVC),旨在提供高压缩比,低延迟和广泛的通用性。在实践中,NVC的编码速度取决于1)计算成本和2)非计算操作成本,例如内存I/O和函数调用的数量。虽然最有效的NVC优先考虑降低计算成本,但我们认为操作成本是实现更高编码速度的主要瓶颈。利用这种洞察力,我们引入了一组效率驱动的设计改进,重点是最小化运营成本。具体来说,我们采用隐式时间建模来消除复杂的显式运动模块,并使用单个低分辨率潜在表示而不是渐进式下采样。这些创新在不牺牲压缩质量的情况下显著加快了NVC的速度。此外,我们还实现了模型集成,以实现一致的跨设备编码和基于模块银行的速率控制方案,以提高实际适应性。实验表明,我们提出的dcvc - rt1080p视频的平均编码/解码速度为125.2/112.8 fps(每秒帧数),同时与H.266/VTM相比,平均节省了21%的比特率。
代码可在https://github.com/microsoft/DCVC上获得。
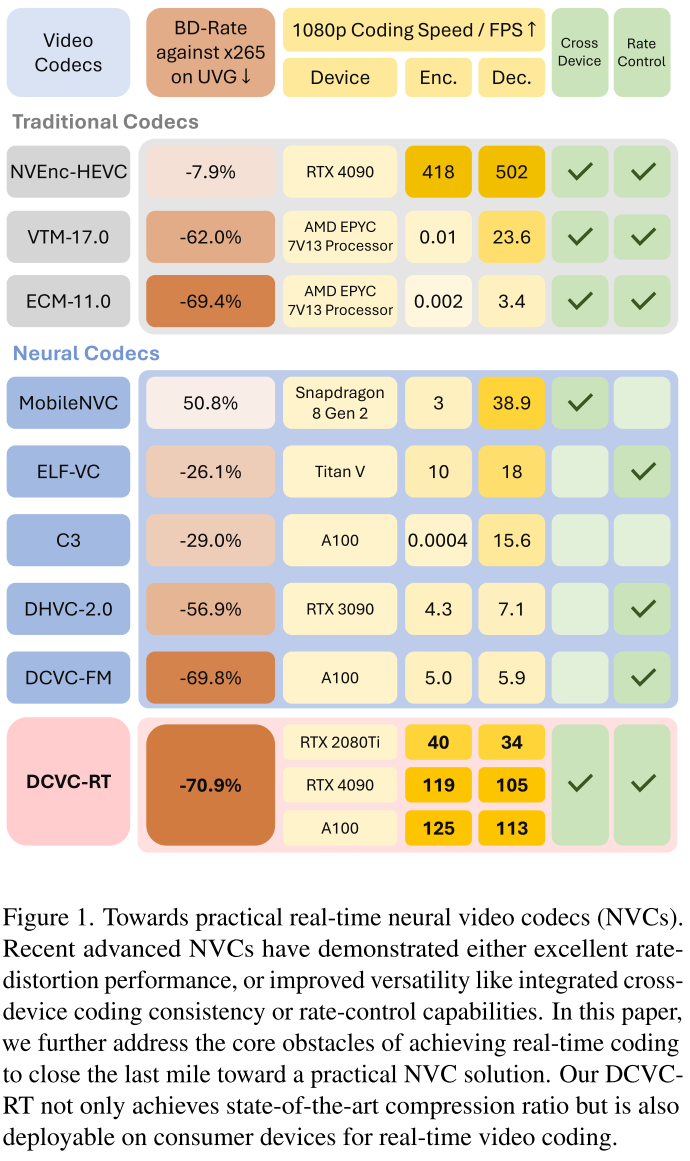
DCVC-RT - 打破神经视频编码实时性能瓶颈的里程碑之作
引言:神经视频编码的"最后一公里"
自DVC开创神经视频编码(NVC)以来,这个领域在压缩率上取得了惊人进展。最新的神经编码器已经超越了H.265、H.266甚至ECM等传统编码器。然而,一个关键问题始终困扰着研究者:如何让NVC真正实用化?
微软亚洲研究院与中国科学技术大学的研究团队在CVPR 2025上发表的论文《Towards Practical Real-Time Neural Video Compression》给出了令人振奋的答案。他们提出的DCVC-RT系统在NVIDIA A100 GPU上实现了125 fps的1080p视频编码速度,同时相比H.266/VTM节省21%的比特率。这是首个在消费级硬件上实现实时高质量编码的神经视频编码器。
一、重新审视复杂度问题:真正的瓶颈在哪里?
传统认知的误区
大多数研究者认为,加速神经网络的关键是减少计算量(MACs)。但论文团队通过精心设计的实验发现了一个颠覆性的结论:操作复杂度(operational complexity)才是真正的速度瓶颈。
他们的实验揭示了几个关键发现:
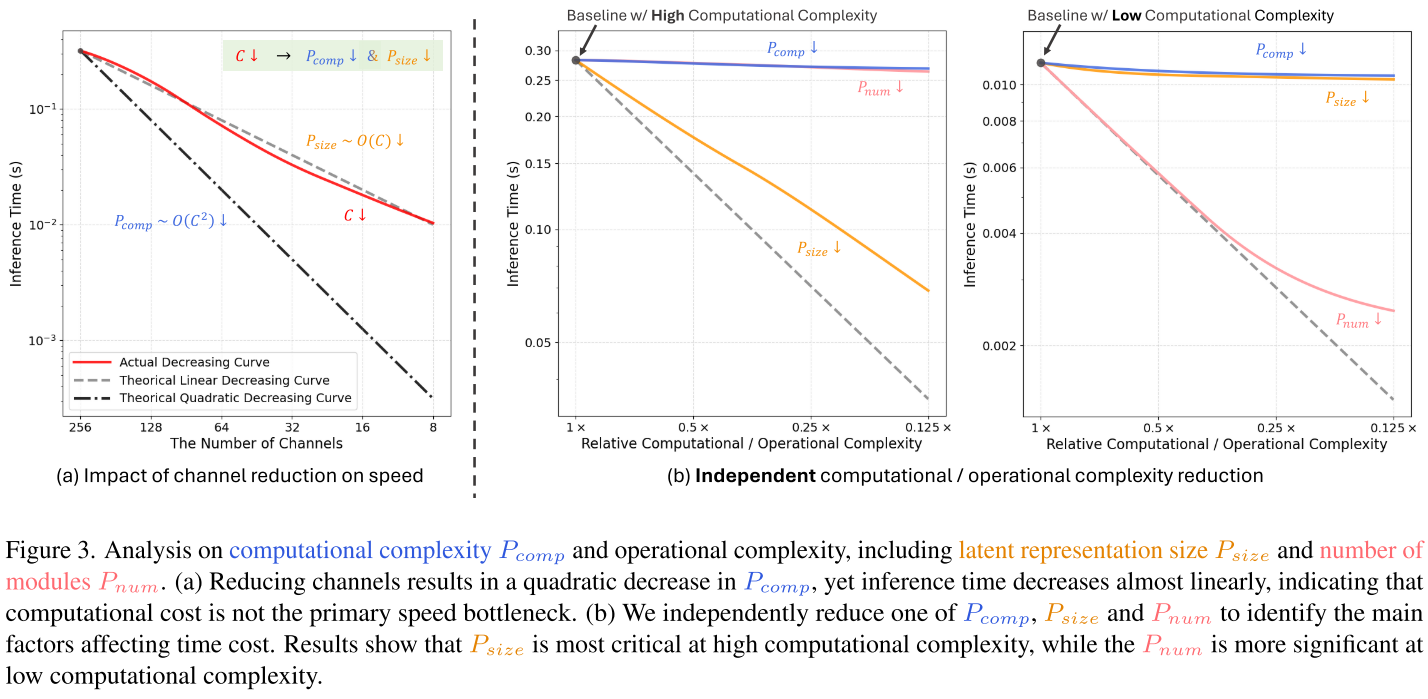
实验1:通道数与速度的关系
- 理论:减少通道C应该带来O(C²)的速度提升
- 实际:速度提升几乎是线性的
- 原因:内存I/O和其他操作开销占主导
实验2:独立控制不同复杂度因素 论文定义了三个关键因素:
- P_comp:计算复杂度(矩阵乘法等)
- P_size:Latent表示大小(影响内存I/O)
- P_num:模块数量(影响函数调用次数)
实验结果(如图3b所示):
- 高计算量场景:P_size是主要瓶颈
- 低计算量场景:P_num成为主要瓶颈
- 单纯降低P_comp:速度提升有限
新的设计理念
基于这一洞察,论文提出了全新的加速策略:
降低操作复杂度,同时保持甚至增加计算能力
这意味着:移除不必要的模块,将计算资源集中到关键模块上。这种"减法设计"反而能带来更好的率失真-复杂度权衡。
二、四大创新技术深度解析
创新1:隐式时间建模 - 告别复杂的运动模块
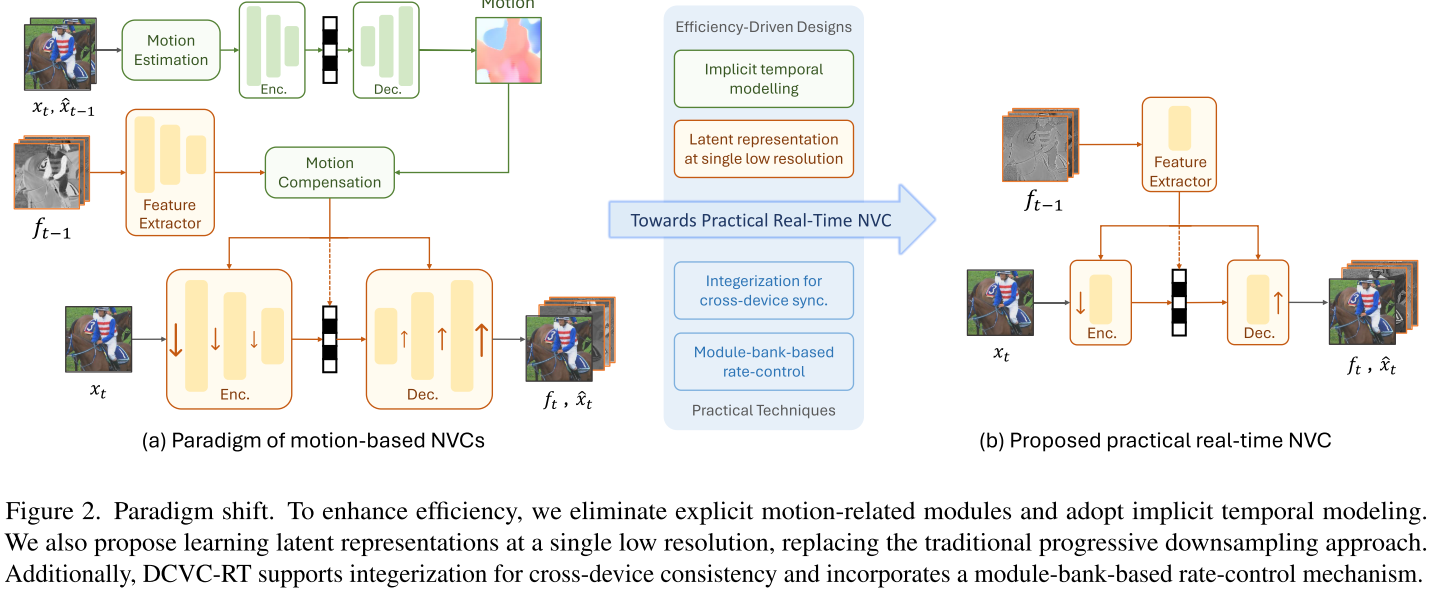
传统做法的问题 几乎所有NVC都采用显式运动估计和运动补偿:
当前帧 → 运动估计 → 运动向量 → 运动补偿 → 预测帧
以DCVC-FM为例:
- 运动编码分支:74 kMACs/pixel,但有123个卷积层
- 条件编码分支:932 kMACs/pixel,但只有225个卷积层
- 运动模块计算量低13倍,但层数是一半
问题在于:频繁的函数调用和模块切换带来巨大的操作开销。
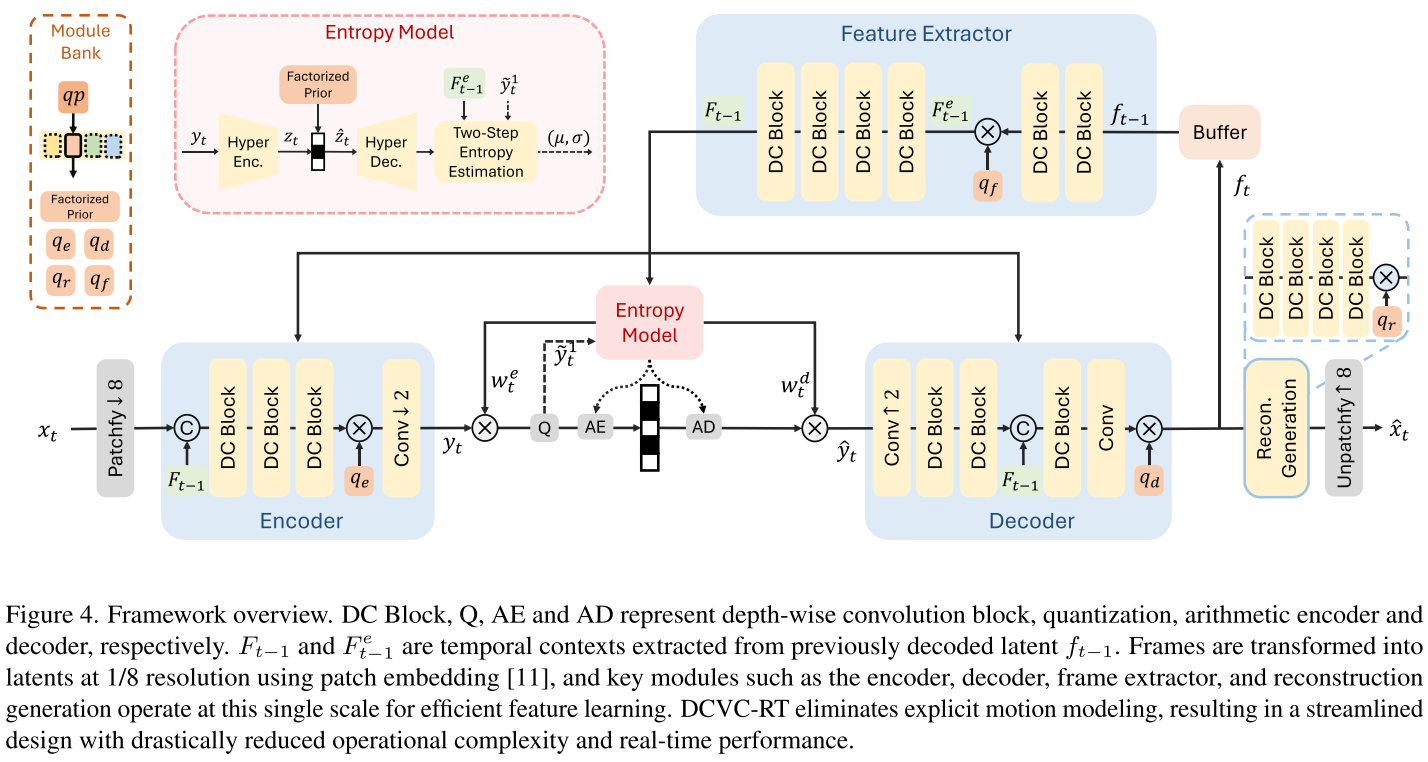
DCVC-RT的解决方案 完全移除运动估计和补偿模块,采用隐式时间建模:
- 使用简单的特征提取器从上一帧提取时间上下文
- 将时间上下文与当前帧latent在通道维度拼接
- 让编码器-解码器联合处理,隐式学习时间相关性
性能对比:

| 方法 | 小运动 | 大运动 | 场景切换 | 编码时间 |
|---|---|---|---|---|
| 显式运动 | 0.0% | 0.0% | 0.0% | 27.2ms |
| 隐式建模 | -0.4% | +3.2% | -4.7% | 8.0ms (3.4×) |
关键发现:
- 小运动场景:性能反而提升0.4%
- 大运动场景:仅损失3.2%
- 场景切换:大幅提升4.7%(运动模型无法处理这种情况)
- 速度:提升3.4倍
创新2:单一低分辨率Latent - 颠覆渐进下采样范式
传统渐进下采样的问题 大多数NVC采用类似U-Net的结构:
原始帧 (3×H×W)↓ 下采样
1/2尺度 (C×H/2×W/2)↓ 下采样
1/4尺度 (2C×H/4×W/4)↓ 下采样
1/8尺度 (4C×H/8×W/8)
虽然每层计算量保持恒定:
- 计算量:O((2C)² × H/2 × W/2) = O(C² × H × W)
- 但Latent大小:2C × H/2 × W/2 = CHW
高分辨率层的巨大Latent size导致严重的内存I/O瓶颈。
DCVC-RT的革新 使用patch embedding直接跳到1/8分辨率:
原始帧 (3×H×W)↓ Patch Embedding (一步到位)
1/8尺度 (256×H/8×W/8)
为什么选择1/8尺度?
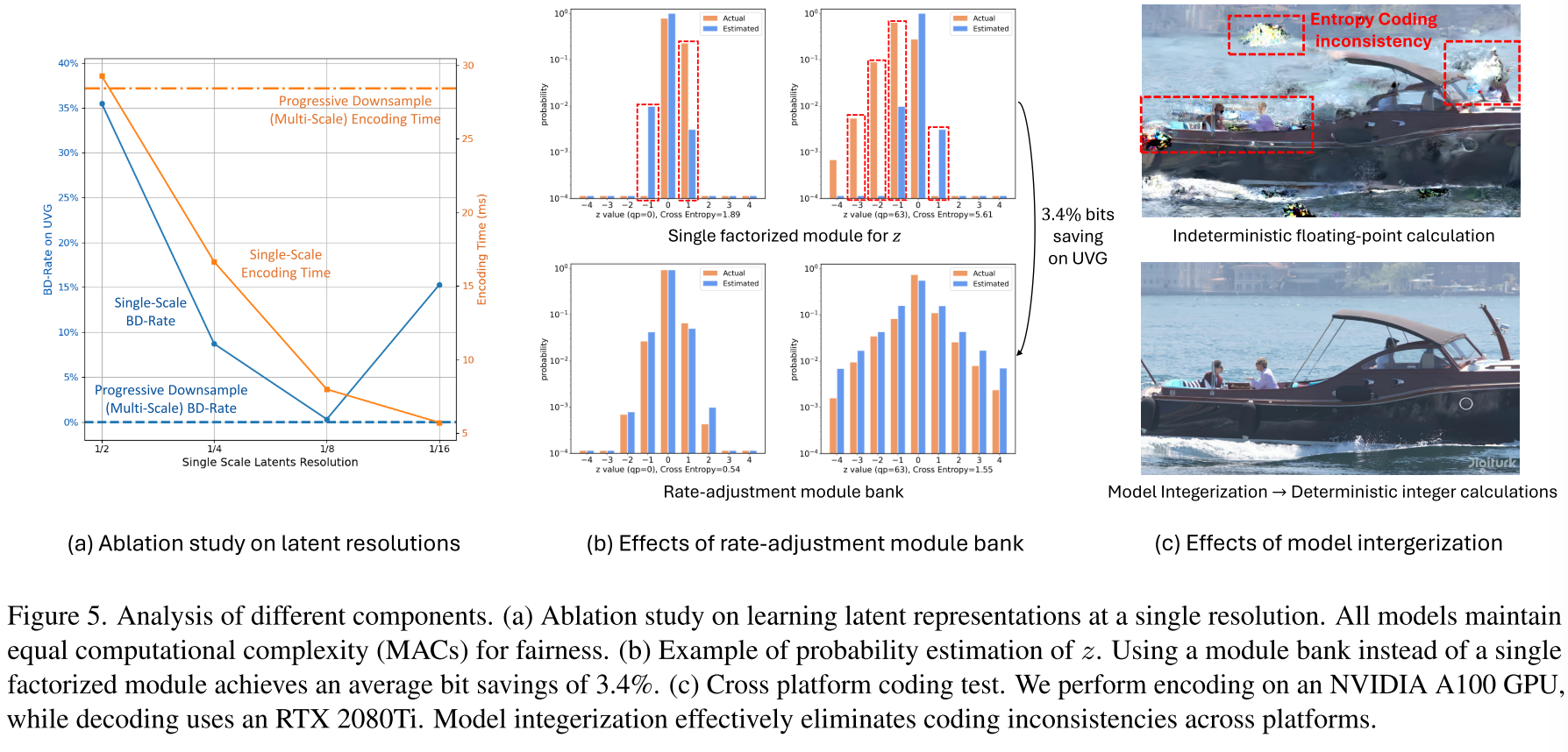
- Latent容量足够:256×H/8×W/8 = 4HW > 原始帧(3HW)
- 感受野更大:单尺度1/8的感受野超过渐进下采样
- 速度提升显著:相比渐进下采样快3.6倍
- 性能损失极小:BD-Rate仅增加0.3%
1/2尺度为何不行?感受野太小,性能严重下降。 1/16尺度为何不行?Latent容量不足(512×H/16×W/16 = 2HW < 3HW)。
创新3:模块库式码率控制 - 精准适配不同比特率
问题背景 在DCVC-RT中,由于移除了运动编码:
- 超先验信息z占总比特数10%以上(传统方法<1%)
- z对空间-时间建模至关重要
现有方法(如DCVC-FM)使用单一分解先验模块估计z的分布,在不同qp下准确度不足。
模块库设计 论文提出为不同量化参数学习专门的模块:
┌─ qp=0模块├─ qp=8模块
超先验模块库 ─┼─ qp=16模块├─ ...└─ qp=63模块
同时为不同功能模块设计独立向量库:
- q_e:编码器向量库
- q_d:解码器向量库
- q_f:特征提取器向量库
- q_r:重建网络向量库
效果验证(图5b):
- 模块库方法的估计分布与实际分布高度吻合
- 平均节省3.4%比特数
- 支持灵活的层次化质量控制(不同帧不同qp)
创新4:模型整数化 - 跨设备一致性保障
浮点计算的不确定性 不同设备上的浮点运算可能产生微小差异,导致:
- 解码端输出与编码端不一致
- 误差在视频序列中累积
- 严重影响视频质量
16位整数化方案 映射关系:v_int16 = round(512 × v_float)
- 有效范围:[-64.0, 63.998]
- 使用int32累加器防止溢出
- Sigmoid等非线性函数:预计算查找表
性能权衡:
- BD-Rate:-21.0% (fp16) → -18.3% (int16),损失仅2.7%
- 完全消除跨设备不一致性(图5c验证)
- 硬件限制:当前GPU对int16优化不足,速度慢于fp16
未来展望: A100上fp16比int16快4倍,主要因为Tensor Cores针对fp16深度优化。随着硬件发展,int16有望超越fp16。
三、实验结果:多维度的突破性表现
压缩性能:与顶级编码器正面交锋
BD-Rate对比(相对VTM-17.0):
| 编码器 | UVG | MCL-JCV | HEVC-B | HEVC-C | HEVC-D | HEVC-E | 平均 |
|---|---|---|---|---|---|---|---|
| HM-16.25 | +40.1% | +48.6% | +47.6% | +41.0% | +34.5% | +42.8% | +42.4% |
| ECM-11.0 | -20.0% | -22.1% | -22.2% | -21.2% | -20.4% | -17.2% | -20.5% |
| DCVC-FM | -17.6% | -8.4% | -15.7% | -30.2% | -37.6% | -23.0% | -22.1% |
| DCVC-RT | -24.0% | -14.8% | -16.6% | -21.0% | -27.3% | -22.4% | -21.0% |
关键发现:
- DCVC-RT平均节省21.0%比特率,超过ECM(下一代传统编码器原型)
- 在UVG数据集上表现最佳(-24.0%)
- 与DCVC-FM压缩率相当,但速度快25倍
率失真曲线分析:
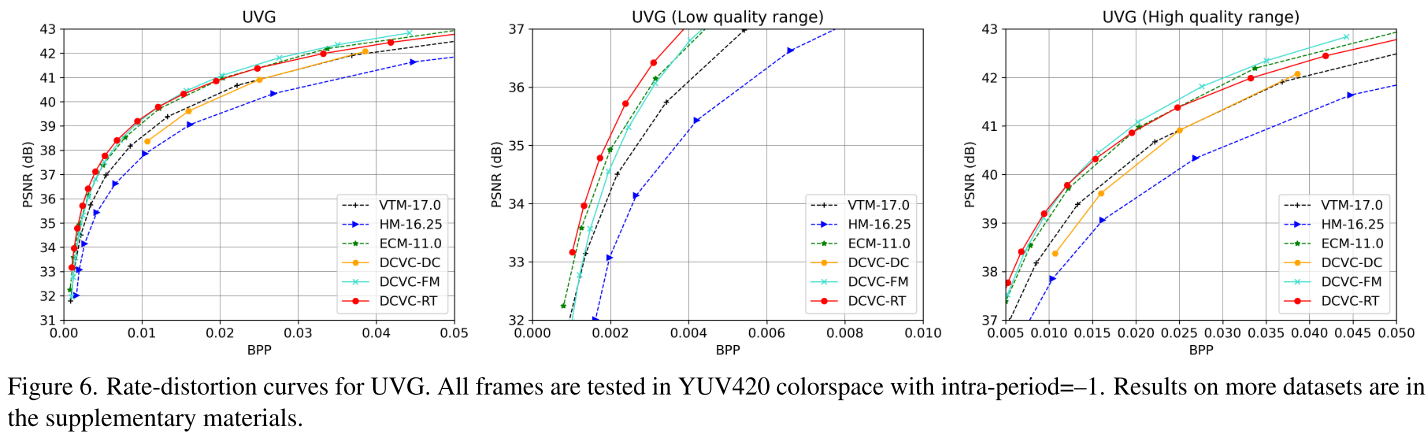
- 低比特率区域(<0.02 bpp):DCVC-RT性能最优
- 中等比特率:全面超越VTM
- 高比特率(>40 dB):轻微下降(人眼难以区分的质量范围)
编码速度:真正的实时性能
1080p视频编码/解码速度(fps):
| 设备 | DCVC-DC | DCVC-FM | DCVC-RT | 加速比 |
|---|---|---|---|---|
| A100 | 3.3 / 4.3 | 5.0 / 5.9 | 125.2 / 112.8 | 25× |
| RTX 4090 | 2.3 / 2.9 | 3.7 / 4.4 | 118.8 / 105.3 | 32× |
| RTX 2080Ti | 0.8 / 1.4 | 1.9 / 2.3 | 39.5 / 34.1 | 21× |
多分辨率性能:
- 720p:A100达到173.9 fps编码,RTX 2080Ti达到73.3 fps
- 4K:A100实现35.5 fps编码(达到30fps实时标准)
里程碑意义:
- RTX 2080Ti(消费级显卡)实现1080p 30fps+ 实时编码
- A100上首次实现4K实时编码
- 相比DCVC-FM速度提升20-32倍
计算复杂度:效率的巨大飞跃
| 模型 | MACs | 参数量 | 平均BD-Rate |
|---|---|---|---|
| DCVC-DC | 2642G | 19.8M | +14.5% |
| DCVC-FM | 2642G | 18.3M | -21.3% |
| DCVC-RT | 385G | 20.7M | -21.0% |
DCVC-RT相比DCVC-FM:
- 计算量减少85%(2642G → 385G)
- 参数量相当(20.7M vs 18.3M)
- 压缩性能持平(-21.0% vs -21.3%)
- 速度提升25倍
这验证了论文的核心观点:降低操作复杂度比降低计算复杂度更有效。
整数化模式:一致性与性能的平衡
跨设备测试(A100编码 → RTX 2080Ti解码):
- fp16模式:存在熵编码不一致性
- int16模式:完全一致,无任何误差累积
性能对比:
| 模式 | 平均BD-Rate | 1080p速度(A100) |
|---|---|---|
| fp16 | -21.0% | 125.2 / 112.8 fps |
| int16 | -18.3% | 28.3 / 20.9 fps |
分析:
- 性能损失:2.7%(可接受范围)
- 速度差距:主要因硬件对int16优化不足
- 实用价值:在需要严格一致性的场景(如直播、视频会议)必不可少
四、深入分析:为什么DCVC-RT能成功?
设计哲学的转变
传统NVC优化路径:
提高压缩率 → 增加模型复杂度 → 速度变慢 → 减少计算量 → 效果有限
DCVC-RT的创新路径:
分析真实瓶颈 → 降低操作复杂度 → 重新分配计算资源 → 同时优化压缩率和速度
关键设计决策的权衡
1. 运动建模:显式 vs 隐式
- 显式:理论上更优,但操作开销大
- 隐式:3.4×速度提升,性能损失可控(平均2.1%)
- 场景切换下反而更优(-4.7%)
2. Latent尺度:渐进 vs 单一
- 1/2尺度:感受野不足,性能差
- 1/4尺度:速度快,但性能下降
- 1/8尺度:最佳平衡点(3.6×速度,0.3%性能损失)
- 1/16尺度:容量不足
3. 数值精度:fp16 vs int16
- fp16:最快,但跨设备不一致
- int16:一致性保证,等待硬件优化
- 提供两种模式满足不同需求
技术融合的协同效应
四大创新技术不是孤立的,而是协同工作:
隐式时间建模 ─┐├─→ 降低操作复杂度 ─→ 实时性能
单一低分辨率 ─┘模块库码率控制 ─┐├─→ 增强实用功能 ─→ 实际部署
模型整数化 ─────┘
五、实际应用场景与展望
适用场景
1. 视频流媒体
- 高压缩率降低带宽成本21%
- 实时编码满足直播需求
- 码率控制适应网络波动
2. 视频会议
- RTX 2080Ti实现1080p实时编码
- int16模式保证跨设备一致性
- 低延迟适合交互应用
3. 视频存储
- 相同质量下节省21%存储空间
- 解码速度112.8 fps支持流畅播放
- 支持4K内容
4. 边缘计算
- 消费级GPU即可运行
- 低计算复杂度适合资源受限环境
当前局限
1. int16模式速度
- 硬件对int16优化不足
- 期待未来硬件发展
2. 高码率性能
40 dB时轻微下降
- 大模型可解决,但会影响速度
3. 编码器生态
- 需要软件播放器支持
- 标准化工作尚在进行
六、技术细节:可复现性分析
训练设置
数据集:
- 训练:Vimeo-90k(7帧序列)+ 处理后的长序列
- 评估:HEVC Class B~E, UVG, MCL-JCV
训练策略:
- qp范围:[0, 63]随机采样
- 层次化质量:GOP 8帧的qp偏移 = [0,8,0,4,0,4,0,4]
- λ值:1到768之间插值
- 损失函数:YUV和RGB联合失真
工程实现:
- 开源代码:https://github.com/microsoft/DCVC
- 可在消费级GPU上训练
- 支持fp16和int16两种模式
测试配置
硬件环境:
- GPU:NVIDIA A100, A6000, RTX 4090, RTX 2080Ti
- CPU:AMD EPYC 7V13 Processor
- 测试分辨率:720p, 1080p, 4K
对比基准:
- 传统编码器:使用实际比特流(含头信息)
- 神经编码器:重新测试以保证公平性
- 设置:低延迟,所有帧编码(intra-period=-1)
结语:神经视频编码的新篇章
DCVC-RT不仅仅是一个更快的神经视频编码器,它代表了该领域设计理念的根本性转变。通过识别操作复杂度这一真正瓶颈,论文团队展示了如何在不牺牲压缩性能的前提下实现实时编码。
核心贡献总结:
- 理论突破:首次系统分析操作复杂度对NVC速度的影响
- 技术创新:四大创新技术的协同设计
- 性能里程碑:首个实用的实时高压缩率NVC
- 开源贡献:提供可复现的完整实现
在NVIDIA A100上125.2 fps的1080p编码速度,同时相比H.266节省21%比特率——这不仅仅是数字上的突破,更意味着神经视频编码从实验室走向实际应用的"最后一公里"已经打通。
随着硬件对int16运算的优化、更大模型的训练、以及产业生态的建立,我们有理由相信,神经视频编码将在不久的将来成为视频压缩的主流技术。DCVC-RT,正是这一变革的重要里程碑。