CVPR 2025|电子科大提出渐进聚焦Transformer:显著降低超分辨率计算开销
点击原文链接,查看更多图像超分辨率论文精读
一、导读
单张图像超分辨率(Single Image Super-Resolution, SR)旨在从低分辨率图像中恢复出高分辨率细节。
近年来,基于Transformer的模型因其能捕捉图像中的长距离依赖关系而表现优异,但其自注意力机制计算量大,且会引入大量与当前查询无关的特征,影响重建效果和效率。如何精准筛选出对当前查询真正重要的特征,避免无效计算,成为当前研究的难点。
为解决这一问题,本文提出了一种渐进聚焦Transformer(Progressive Focused Transformer, PFT),通过渐进聚焦注意力(Progressive Focused Attention, PFA) 机制,将网络中原本孤立的注意力图连接起来,逐步聚焦于最重要的图像块(token),从而在提升重建质量的同时显著降低计算开销。
实验表明,该方法在多个超分辨率基准测试中取得了领先性能。
二、论文基本信息

-
论文标题:Progressive Focused Transformer for Single Image Super-Resolution
-
作者与单位:Wei Long, Xingyu Zhou, Leheng Zhang, Shuhang Gu(电子科技大学)
-
发表日期与来源:CVPR 2025
-
代码地址:https://github.com/LabShuHangGU/PPT-SR
三、主要贡献与创新
-
提出渐进聚焦注意力(PFA),通过逐层继承注意力图,增强重要token的权重并抑制无关token。
-
引入稀疏矩阵乘法(SMM) 机制,在计算前过滤不相关特征,显著降低计算复杂度。
-
构建了PFT和PFT-light两种模型,分别适用于标准与轻量级超分辨率任务,在多个基准测试中取得最优性能。
-
设计了注意力聚焦比例(focus ratio) 控制机制,实现注意力逐步聚焦,提升模型效率与精度。
四、研究方法与原理
PFT的核心思路是:通过逐层传递注意力图,逐步聚焦于对当前查询最重要的图像块,避免无效计算,提升重建质量。
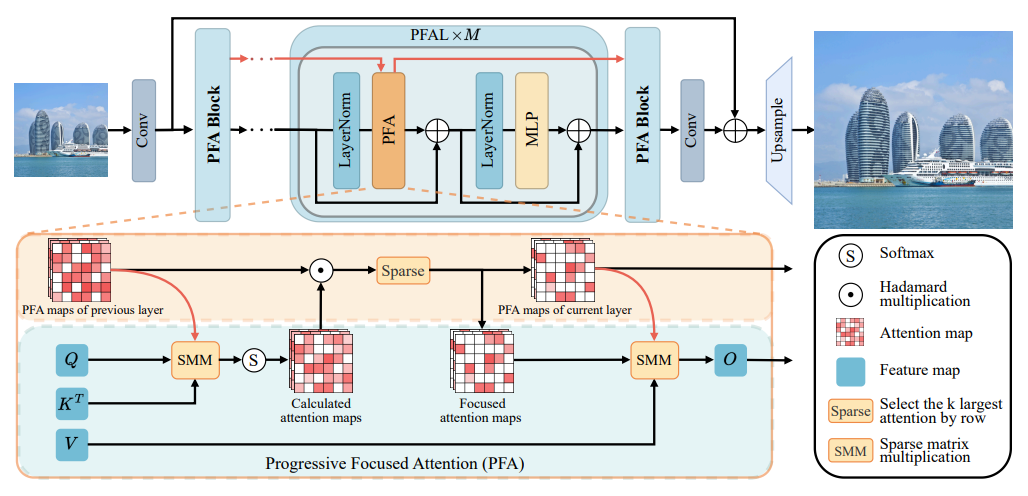
PFT主要由多个渐进聚焦注意力块(PFA Block) 构成,每个块包含若干渐进聚焦注意力层(PFAL)。其关键机制如下:
-
渐进注意力跨层传递
当前层的注意力图 由上一层的注意力图 与本层计算得到的注意力图 逐元素相乘并归一化得到:其中 表示行归一化操作。这样,持续重要的token会被增强,不重要的则被抑制。
-
渐进聚焦注意力(PFA)
为了进一步减少计算,PFA在计算前使用稀疏索引矩阵 过滤不相关位置:其中 是稀疏矩阵乘法(SMM)操作,仅对 的位置计算注意力。最终注意力图通过:
其中 是保留每行前 个最大值的稀疏化操作。
-
聚焦比例控制
每层保留的注意力值数量 按 递减, 为聚焦比例(通常设为0.5),实现注意力逐步聚焦。
五、实验设计与结果分析
实验设置
-
训练集:DF2K(DIV2K + Flickr2K)
-
测试集:Set5, Set14, BSD100, Urban100, Manga109
-
评估指标:PSNR, SSIM
-
训练配置:AdamW优化器,初始学习率 ,批量大小32,输入块尺寸
对比实验
【表1】展示了PFT在多个数据集上 、、 超分辨率任务中的PSNR/SSIM结果。PFT在多数情况下优于HAT、ATD等方法,且计算量(FLOPs)更低。
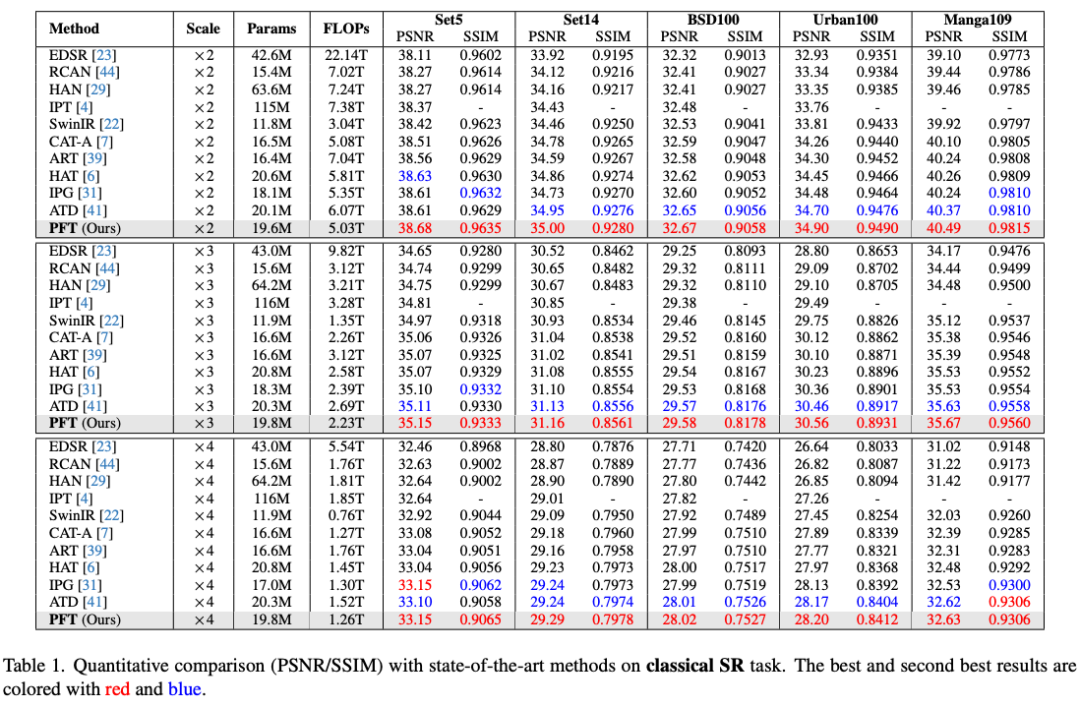
例如在 任务中,PFLOPs为1.26T,低于ATD的1.52T,而PSNR在Urban100上达到28.20dB,优于ATD的28.17dB。
-
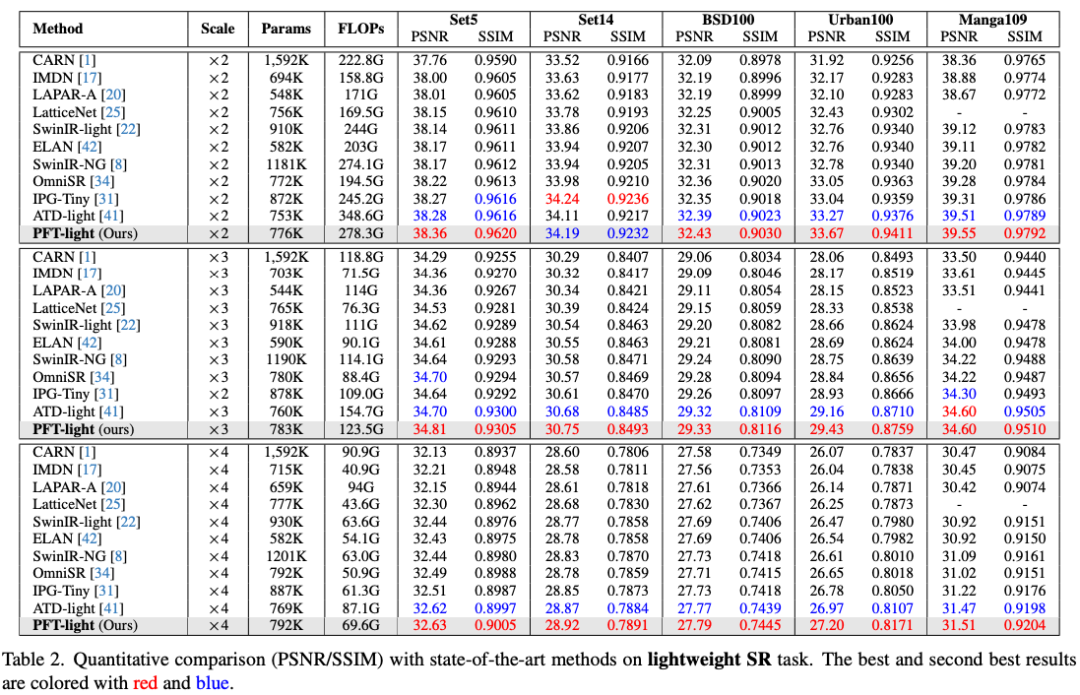
轻量级模型对比
PFT-light在参数量仅792K的情况下,在Urban100上 任务中PSNR达到27.20dB,优于ATD-light的26.97dB,且计算量降低20.1%。
-
可视化对比
【图3】展示了PFA注意力分布更加集中,有效过滤无关区域;

【图4、6、7、8】显示PFT在恢复边缘和纹理细节方面优于其他方法。
(篇幅有限,如需查看完整论文请点击原文)
消融实验
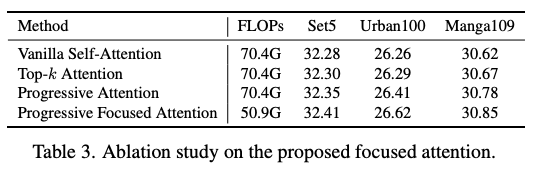
【表3】验证了PFA相比传统自注意力和Top-注意力的优势,PSNR在Urban100上提升0.36dB,计算量降低27.69%。
【表4】显示聚焦比例 时效果最佳。

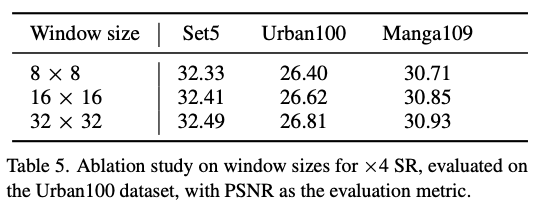
【表5】表明窗口尺寸从 增大到 可进一步提升性能。
六、论文结论与评价
总结
本文提出的PFT模型通过渐进聚焦注意力机制,有效提升了超分辨率任务中特征选择的准确性和计算效率。实验证明,PFT在多个基准测试中取得了最优性能,同时显著降低了计算开销。
评价
PFT在理论和实验上均表现出色,尤其在实际应用中具有较高的部署价值。其优点在于注意力聚焦机制和稀疏计算策略的结合,使得模型在保持高性能的同时具备良好的效率。
然而,PFA机制对初始注意力图的依赖较强,若浅层注意力选择偏差较大,可能影响深层特征聚合。未来可进一步探索注意力初始化的鲁棒性,或将其拓展至视频超分辨率等时序任务中。
点击原文链接,查看更多图像超分辨率论文精读