【论文阅读16】-LLM-TSFD:一种基于大型语言模型的工业时间序列人机回路故障诊断方法
😊文章背景
题目:LLM-TSFD: An industrial time series human-in-the-loop fault diagnosis method based on a large language model
期刊:Expert Systems With Applications
检索情况:IF 7.5 SCIUpTop 计算机科学TOP SCI升级版 计算机科学1区SCI Q1 EI检索
作者:Qi Zhang a, Chao Xu a, Jie Li a, Yicheng Sun a, Jinsong Bao a,*, Dan Zhang
单位:东华大学机械工程学院
发表年份:2024.11
DOI:10.1016/j.eswa.2024.125861
网址:https://www.sciencedirect.com/science/article/pii/S0957417424027283
❓ 研究问题
-
工业故障诊断流程复杂,高度依赖领域专家进行数据标注、模型选择和知识融合。
-
传统数据驱动方法(FD 1.0)可解释性差,且严重依赖数据质量。
-
知识驱动方法(FD 1.5)知识规则不完整,难以解决新问题。
📌 研究目标
提出一种任务驱动、人机协同的新范式(FD 2.0),以降低对人工标注数据的依赖,提升诊断过程的自动化和结果的可解释性。
🧠 所用方法
整体框架
核心思想: 任务驱动 + 人在回路
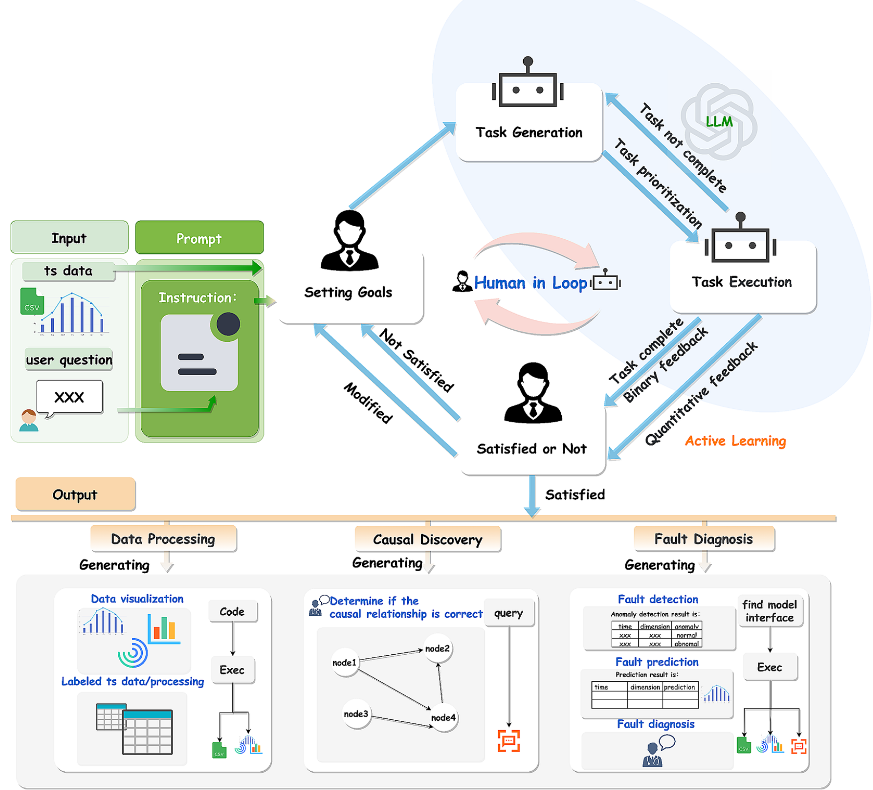
-
输入: 用户任务 + 工业时序数据(结合提示组成用户需求目标)。
-
核心处理: LLM分解任务,通过“人在回路”机制与用户交互(二元/量化反馈)。
-
输出: 数据处理结果、修正后的因果关系、故障检测/预测结果、诊断决策。
一、LLM的四大角色
LLM在故障诊断2.0中的价值:
- 在数据处理方面,LLM扮演着“管道管理器”的角色;
- 在因果发现方面,LLM则充当“监督者”;
- 在故障诊断中,LLM兼具“控制器”和“决策者”的职能,以有效诊断故障。
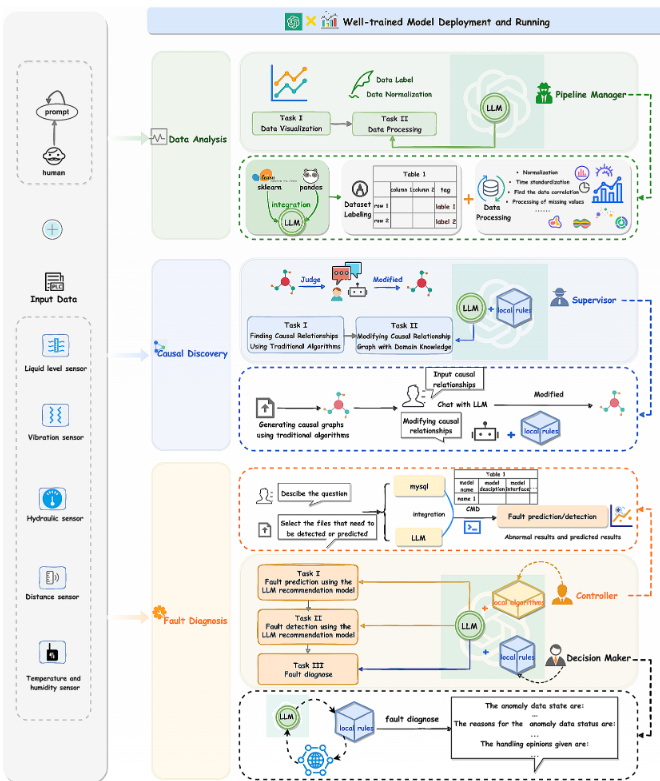
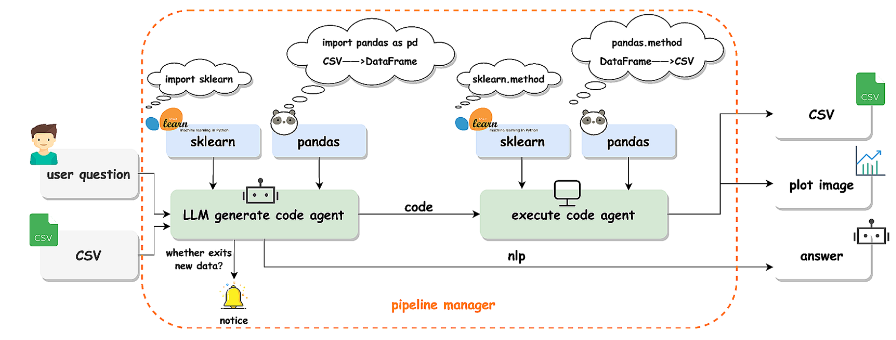
角色一: 管道管理者
将LLM作为数据处理的管道管理器:LLM与一些用于数据处理的Python库结合,生成完整的代码内容。在本地环境中执行该代码,然后生成所需的答案、CSV文件、图像等。
-
功能: 自动化数据预处理、清洗、可视化。
-
价值: 替代手动数据标注和代码编写。

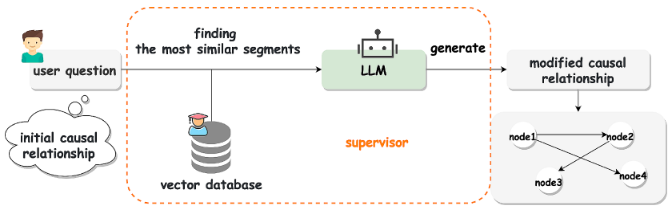
角色二: 监督者
用户输入初始因果关系,LLM结合专家知识库修正因果关系,最后输出修正后的结果。
-
功能: 结合领域知识库,修正因果发现算法的结果。
-
价值: 提升因果关系的准确性。
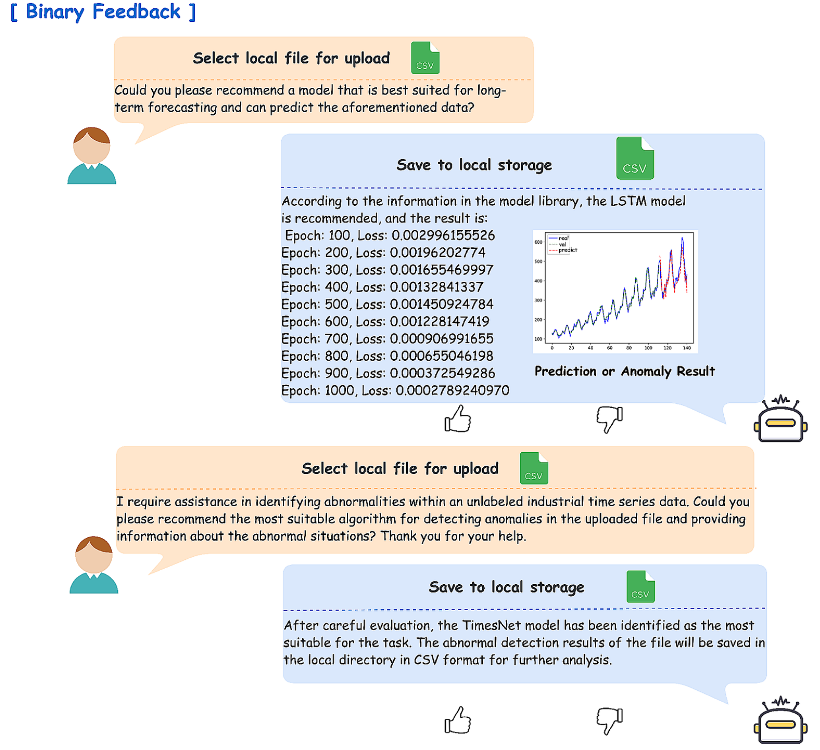
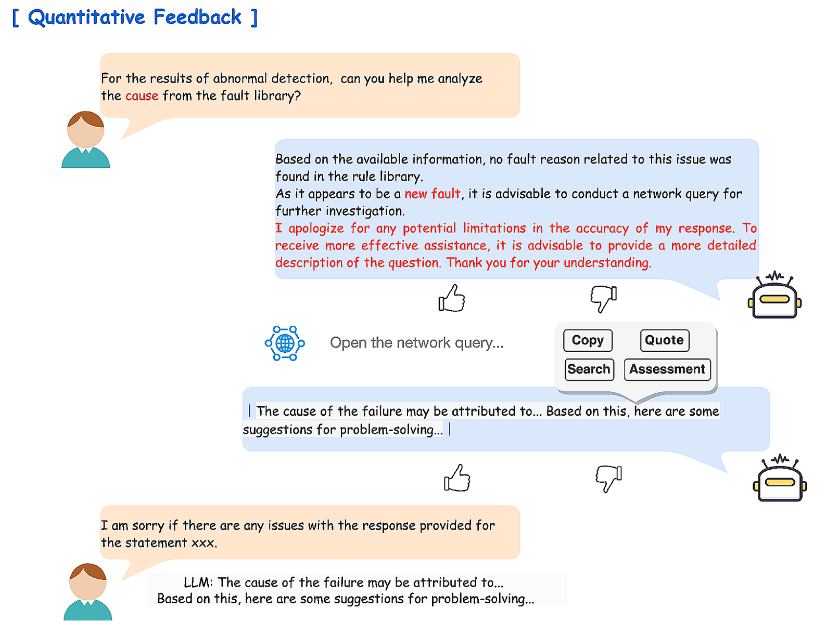
使用大型语言模型进行因果关系校正操作的过程:
大型语言模型通过使用二元和定量反馈机制来纠正其输入的因果关系:
- 前者提供有关答案是否正确的信息;
- 而后者告知大型语言模型其提供的响应不足,需要用户提供额外的输入。

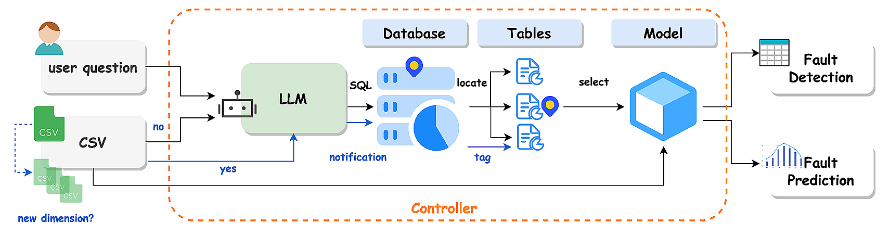
角色三: 控制器
用户向系统提供需要处理的需求和数据。然后,LLM算法将此输入与SQL数据库进行匹配,以推荐匹配度最高的模型。随后,推荐的模型会输出故障检测/预测结果。
-
功能: 根据用户需求和数据变化,推荐并调用本地算法库中的模型。
-
价值: 自动化模型调度与维护提醒。
角色四: 决策者
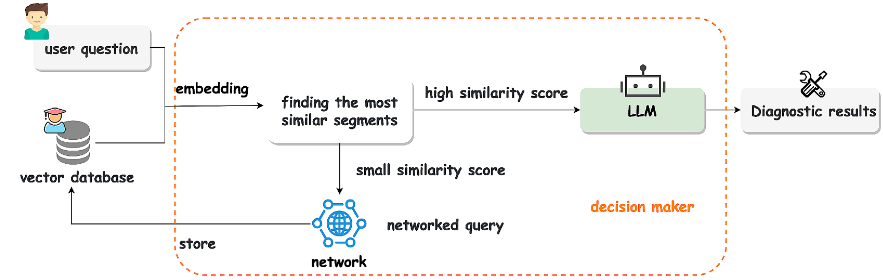
用户询问故障原因,LLM会将其问题与本地故障知识库进行匹配。若匹配到高相似度内容,则直接生成诊断结果;若匹配度低,则进行联网搜索,并将搜索到的新知识补充到本地知识库中,再生成答案,从而具备解决新问题的能力。
-
功能: 诊断故障原因,提供可解释方案,支持联网搜索新知识。
-
价值: 提升结果可读性,解决新问题。
二、关键技术:提示词工程
- 挑战: LLM作为通用模型,如何使其精准执行工业诊断任务?
-
解决方案: 设计结构化提示词框架。
-
提示词构成 (7大组件):
-
T (时间), R (角色), I (输入), O (输出)
-
TD (任务分解), Rea (推理方式), DK (领域知识)
-
-
作用: 通过角色设定和领域知识注入,将LLM“框定”在专业领域内,确保其输出专业、可靠的结果。
-

🧪 实验设计与结果
一、实验设计
-
实验场景: 中国宝山某钢铁企业的连续铸造设备故障诊断。
-
数据来源: 导辊电流、结晶器液位/流量等传感器数据。
-
实验一:
-
对比基线:不使用LLM的钢铁冶金故障诊断方法
-
-
实验二:FD 1.0、FD 1.5 和 FD2.0 的比较
-
对比基线:
-
FD 1.0 模型: LSTM, TCN, Transformer等。
-
FD 1.5 模型: K-means &规则, 知识蒸馏等。
-
FD 2.0 模型: Time-GPT, Prompter-GPT等。
-
-
评估指标: Precision (精确率), Recall (召回率), F1-Score (F1分数)。
-
-
实验三:消融实验:验证框架中各个角色模块的有效性。
-
管道管理者
-
监督者
-
控制器
-
-
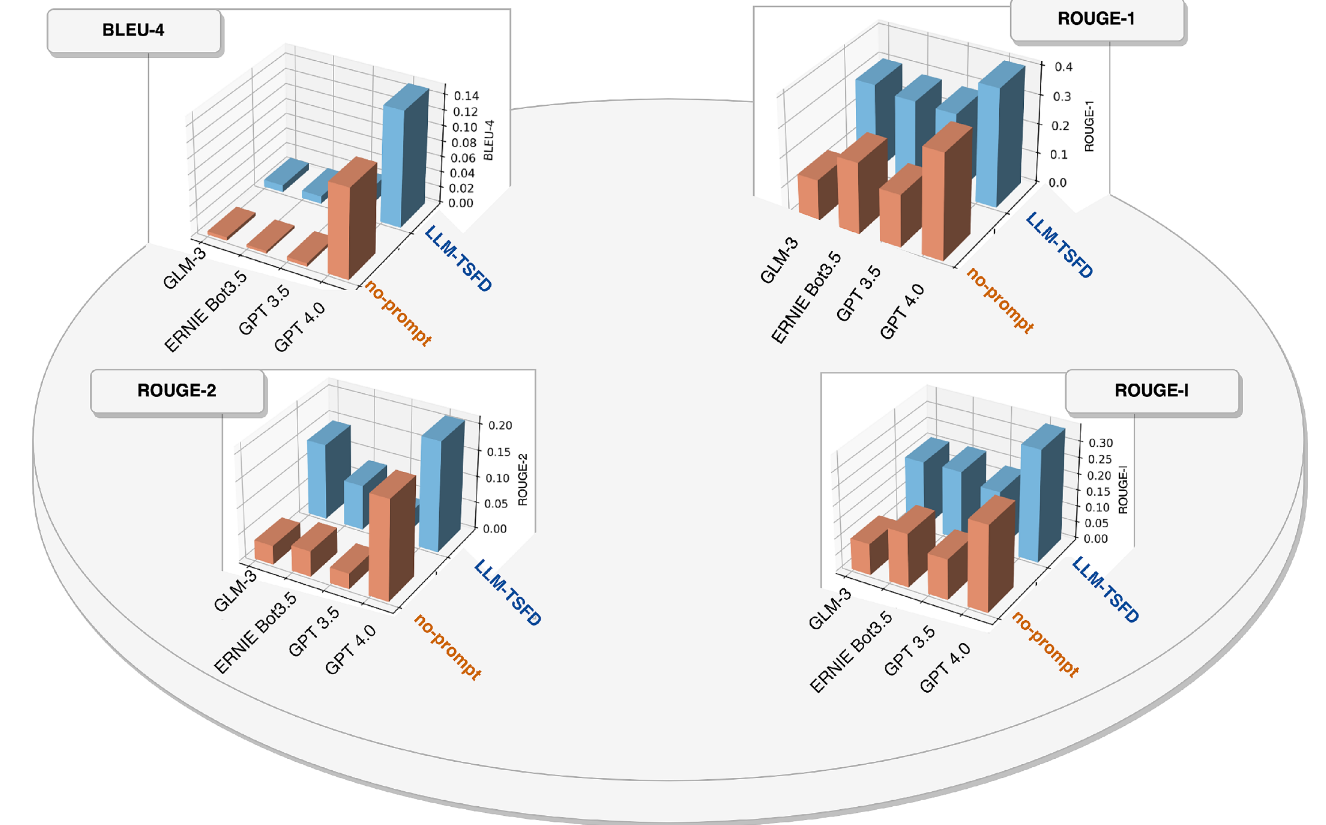
实验四:将LLM-TSFD 与不使用提示的 LLM 方法比较
-
对比基线:GLM-3, ERNIE Bot3.5, GPT3.5, and GPT4.0
-
评价指标:
- bleu-4评分用于评估四元数情况下预测答案与标准答案之间的相似度。
- rouge-1指标衡量预测结果与参考答案之间的单词重叠程度,评估预测结果与参考文本的单个词语或短语的匹配紧密程度。
- rouge-2 指标量化了预测结果与参考文本中连续两个词语或短语之间的一致性水平。
- rouge-l 指标量化了预测结果与参考文本中最长公共子序列之间的重叠程度。
-
二、实验结果
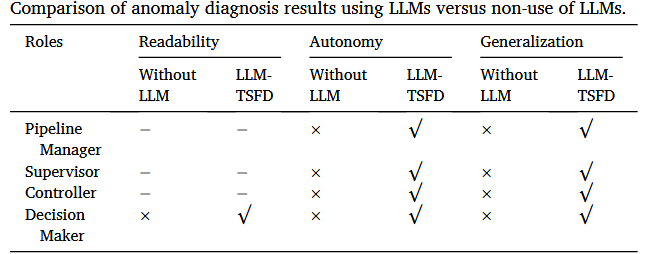
实验一:通过对比基于深度学习的传统平台,突出了LLM-TSFD在可读性(决策者角色提供易懂解释)、自主性(任务驱动自动化)和泛化性(处理多种角色任务)方面的显著优势。
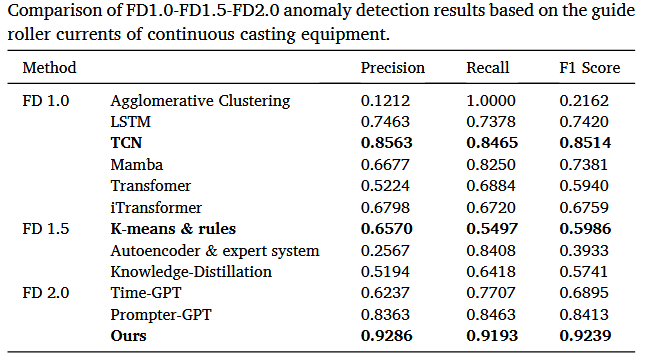
实验二:
基于连铸设备导向辊电流的FD1.0-FD1.5-FD2.0异常检测结果比较
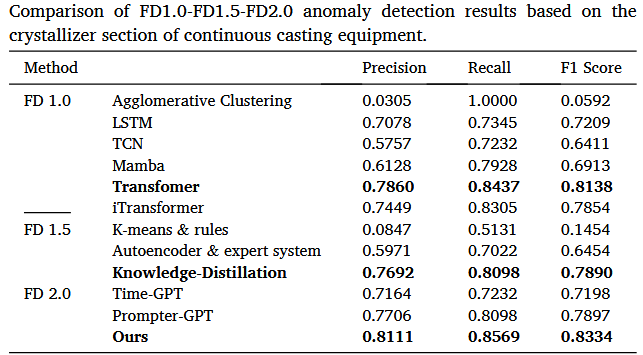
基于连铸设备结晶器段的FD1.0-FD1.5-FD2.0异常检测结果比较
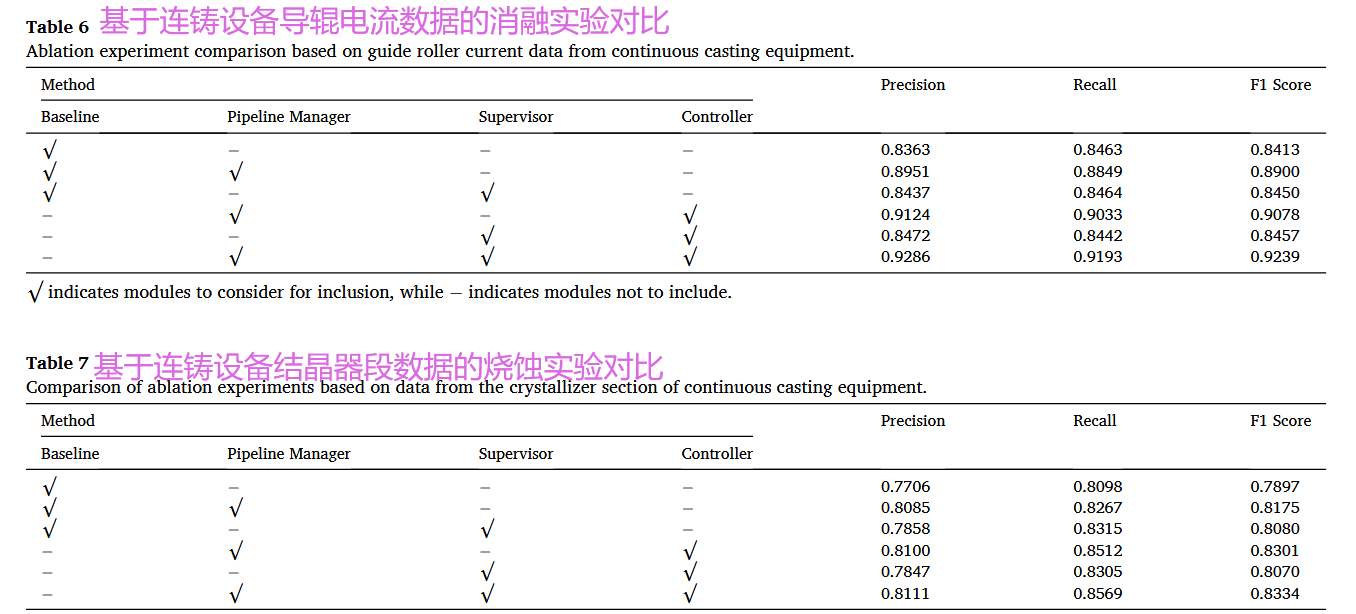
实验三:通过逐一添加管道管理者、监督者和控制器模块到基线模型(Prompter-GPT)中,证明了每个角色模块对提升模型性能的有效性。
实验四:通过对比使用本文提示词(LLM-TSFD)和不使用提示词(no-prompt)在多个LLM上的表现,使用BLEU-4、ROUGE-1等指标评估,证实了本文设计的提示词结构能显著提升LLM生成答案的质量。

✅ 研究结论
-
范式转变: 成功提出并验证了由LLM驱动的任务驱动型故障诊断新范式 (FD 2.0)。
-
角色创新: 明确了LLM在工业诊断流程中的四大角色,实现了全流程自动化。
-
有效验证: 在真实工业场景中验证了方法的优越性能、可解释性和实用性。
📈 研究意义
-
为LLM在垂直工业领域的应用提供了系统性的框架和方法论。
-
推动了故障诊断从“工具辅助”到“智能体自主”的演进。
🔮 未来研究方向
-
多模态数据: 处理图像、音频等多模态工业数据。
-
领域大模型: 构建钢铁冶金等特定领域的专用LLM。
-
模型优化: 利用LLM的推理能力进行超参数自动优化。
-
安全与隐私: 研究在保证数据安全的前提下应用LLM。
📕专业名词
-
LLM (Large Language Model) - 大语言模型
外行定义:一种非常强大的人工智能程序,它通过阅读海量文本资料来学习,能够理解和生成人类语言。你可以像与知识渊博的专家对话一样向它提问,它可以完成写作、总结、翻译、写代码等多种任务。文中的GPT、ChatGLM都属于LLM。 -
LLM-TSFD
外行定义:本文提出的核心方法名称,全称为“基于大语言模型的工业时序人机协同故障诊断方法”。其核心思想是利用上述的大语言模型(LLM)来自动化整个故障诊断流程。 -
FD 1.0, FD 1.5, FD 2.0 - 故障诊断1.0/1.5/2.0时代
外行定义:用来描述工业故障诊断技术发展的三个阶段。
- FD 2.0:本文所处的阶段,由大语言模型(LLM)驱动。用户只需用自然语言下达任务,LLM就能自动安排整个诊断流程,并用人能看懂的方式解释故障原因,自动化程度和易用性大大提高。
- FD 1.5:过渡阶段,在分析数据的基础上加入了一些专家总结的规则知识,让结果更容易解释,但依然依赖专家经验。
- FD 1.0:早期阶段,主要依靠计算机分析数据来发现异常,但过程需要大量人工干预(如手动标记数据),且诊断结果像“黑箱”,难以理解。
-
Human-in-the-loop - 人在回路
外行定义:一种人机协作模式。在整个故障诊断过程中,人类(如工程师)不是被完全替代,而是作为监督者和指导者参与其中。例如,AI给出诊断结果后,人类可以反馈“满意”或“不满意”,AI根据反馈进行改进,形成一个不断优化的闭环。
技术方法相关
-
Time Series Data - 时序数据
外行定义:按时间顺序记录的一系列数据点。在工业中,就像传感器每分钟记录一次设备的温度、压力、电流值,这些连续记录的数据就构成了时序数据,可用于分析设备的运行状态和变化趋势。 -
Prompt / Prompt Engineering - 提示/提示工程
外行定义:为了让大语言模型(LLM)更好地完成任务,用户需要给它输入的“指令”或“问题”。设计好的提示词就像给AI一个清晰的工作说明书,能显著影响其回答的质量和方向。本文专门为故障诊断任务设计了一套提示词结构。 -
Task-driven - 任务驱动
外行定义:指整个流程由用户下达的顶层任务(如“诊断这台设备有什么故障”)来驱动。LLM会像项目经理一样,自动将这个复杂任务拆解成一系列小步骤(如先处理数据、再分析因果、最后诊断),然后逐一完成。 -
Transformer
外行定义:一种支撑现代大语言模型(如GPT)的核心技术架构。它的关键组成部分是“自注意力机制”,可以让模型在处理一句话或一段文本时,更好地理解不同词语之间的关系和上下文含义。
评估指标相关
-
Precision - 精确率
外行定义:衡量模型报警的“准确度”。在所有被模型判断为“故障”的情况中,有多少是真正的故障。比例越高,说明误报(假警报)越少。 -
Recall - 召回率
外行定义:衡量模型发现故障的“全面度”。在所有实际发生的故障中,模型成功检测出了多少。比例越高,说明漏报(真故障没被发现)越少。 -
F1 Score - F1分数
外行定义:精确率和召回率的综合得分,是平衡两者表现的一个指标。当需要同时考虑减少误报和漏报时,F1分数是一个很好的整体性能衡量标准。