Elasticsearch-4--倒排索引的原理?
1、什么是倒排索引?
1、与“正排索引”对比
(1)、正排索引 (Forward Index)
定义:以文档为单位组织数据。记录每个文档中包含了哪些词语。
映射方向:文档(Document) → 词语列表(Term List)。(如数据库的行式存储)。
示例:Doc1 → [“lucene”, “search”, “engine”]
特点:
- 结构直观,类似于文档的原始内容表示。
- 在搜索引擎中,通常作为构建倒排索引的中间步骤。
- 查询效率低:当需要查找包含某个特定词(如 “search”)的所有文档时,必须遍历所有文档的词语列表,时间复杂度高。
(2)、倒排索引 (Inverted Index)
定义:以词语为单位组织数据。记录每个词语出现在哪些文档中。
映射方向:词语(Term) → 包含该词的文档列表(Posting List)。(如搜索引擎的列式存储)。
示例:“search” → [Doc1, Doc3, Doc5]
特点:
- 是现代搜索引擎(如 Elasticsearch, Lucene)的核心数据结构。
- 查询效率极高:对于关键词搜索,可以直接通过词语定位到所有相关文档列表,无需扫描全部文档。
- 通常还会在文档列表中存储额外信息,如词频(TF)、位置(Position)、偏移量(Offset)等,用于相关性评分和高亮显示。
(3)、对比

总结:
正排索引是基础,倒排索引才是实现高效全文检索的基石。
2、倒排索引的核心组成
一个完整的倒排索引由两部分构成。
1、词典(Term Dictionary)
存储所有唯一的词项(Term),并按字典序排列。
- 存储所有唯一的词项(Terms)
- 通常用有序数组、Trie、FST(Finite State Transducer)实现
- 支持快速查找:"lucene"是否存在?位置在哪?
2、倒排表(Posting List)
每个词项对应的文档列表,记录包含该词项的文档ID、词频(Term Frequency)、位置(Position)等信息。
每个词项对应一个倒排表,记录:
- 文档ID(DocID)
- 词频(TF, Term Frequency)
- 位置(Position) → 用于短语查询"big data"
- 偏移(Offset) → 用于高亮显示
- Payload → 自定义数据(如权重、标签)
3、构建倒排索引步骤示例
假设有3个文档。

(1)、分词与处理(Analyzer)
Doc1: [lucene, search, engine]
Doc2: [elasticsearch, uses, lucene]
Doc3: [search, engine, lucene]
一般分词器会去掉停用词如:“is”, “a”, “with”
(2)、构建词典和倒排表
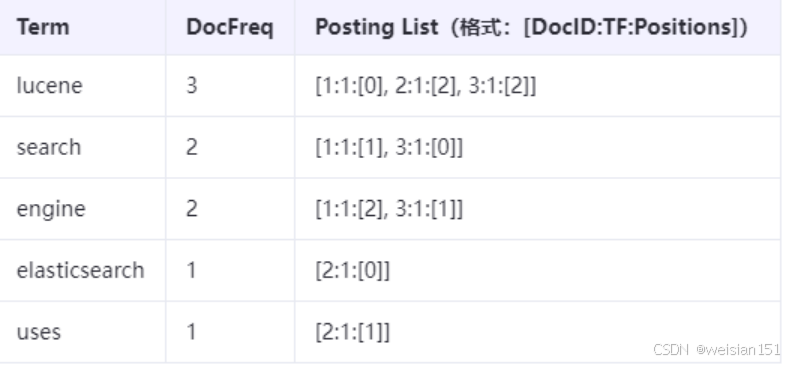
说明:
- Term: 词项(词语)。
- DocFreq: 文档频率(Document Frequency),表示包含该词项的文档数量。
- Posting List: 倒排列表,包含每个包含该词项的文档信息。
- 格式 [DocID:TF:Positions] 中:
- DocID: 文档ID。
- TF (Term Frequency): 该词项在对应文档中的出现次数(词频)。
- Positions: 该词项在对应文档中的位置(通常指在分词后的词语序列中的索引,从0开始)。
- 示例:[1:1:[0]]表示文档1,出现1次,位置0
- 格式 [DocID:TF:Positions] 中:
3、倒排索引的构建流程
1、文档解析与分析
(1)、分词(Tokenization)
- 分词(Tokenization):
- 使用分词器(Tokenizer)将文本拆分为词项。例如:
- 英文:“The quick brown fox” → [“the”, “quick”, “brown”, “fox”]。
- 中文:依赖分词器(如IK Analyzer、Jieba)将连续文本切分为有意义的词汇。
- 使用分词器(Tokenizer)将文本拆分为词项。例如:
(2)、过滤
- 过滤(Filtering):
- 去除停用词(如"the", “is”)。
- 词干提取(Stemming):将变形词还原为词根(如"running" → “run”)。
- 同义词扩展:将"car"和"automobile"视为同一Term。
2、内存缓冲(In-Memory Buffer)
文档分词后,Term和文档ID临时存储在内存中。同时记录Term的频率和位置信息。Lucene使用FST(Finite State Transducer)在内存中临时存储。
- Term → TermID映射
- Document → Term列表
有限状态转换器FST(Finite State Transducer)是一种紧凑的有限状态机,支持高效前缀匹配和模糊查询。
- Lucene使用FST存储Term字典,支持前缀压缩和快速查找。
- 例如,Term “apple"和"app"共享前缀"app”,节省内存。
3、生成 Segment(段)
当内存缓冲区满或达到刷新间隔(如Elasticsearch的1秒),将数据写入磁盘生成Segment。
Segment内部文件结构:
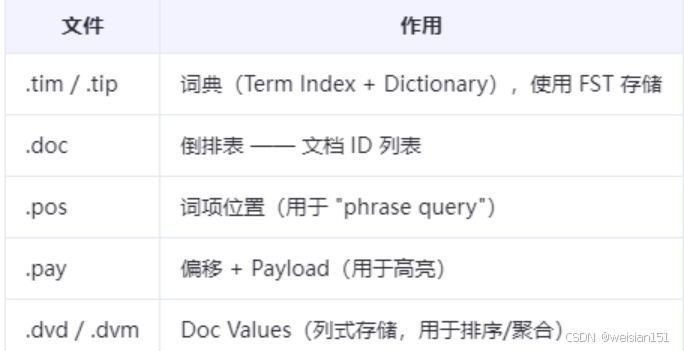
说明:
- 所有文件都是只读的。
- Segment是Lucene的最小可搜索单元。
4、合并 Segment(Merge)
- 多个小Segment会影响查询性能(需查多个文件)。
- Lucene定期执行Merge,将多个小Segment合并为大Segment。
- 合并过程中会:
- 清除已删除文档
- 压缩Posting List
- 重建词典
注意:Merge是I/O密集型操作,但对性能至关重要。
5、分布式实现(如Elasticsearch)
- 文档路由到分片:
- 根据文档ID的哈希值%分片数确定目标分片。
- 主分片(Primary Shard)负责写入,副本分片(Replica Shard)同步数据。
- 事务日志(Translog):
- 写入内存缓冲区时记录日志,防止数据丢失。
- 定期(如每5分钟)持久化到磁盘并清空缓冲区(Flush操作)。
4、倒排索引的查询流程
以查询"lucene AND search"为例。
1、解析查询语句
java示例:
Query query = new BooleanQuery.Builder().add(new TermQuery(new Term("content", "lucene")), BooleanClause.Occur.MUST).add(new TermQuery(new Term("content", "search")), BooleanClause.Occur.MUST).build();
2、查找词项
- 在.tim/.tip文件(单词表文件)中查找"lucene"和"search"。
- 获取它们的TermID和倒排表指针。
注意:为了加快读取速度,lucene进行的优化。
- 查询缓存(Query Cache):
- 缓存频繁查询的Posting List结果(如过滤条件)。
- 热词预热:
- 提前加载高频Term的Posting List到内存。
3、读取倒排表
- 并行读取两个倒排表。
- lucene → [1,2,3]
- search → [1,3]
4、求交集(Intersection)
- 使用双指针算法或Skip List快速求交。
[1,2,3]↑[1,3]↑→ 公共DocID: [1,3]
5、计算相关性得分(Scoring)
使用BM25算法计算每个文档的相关性。
示例:
score(D, Q) = Σ BM25(t in Q)
其中:
- t是查询词项
- BM25考虑:词频(TF)、逆文档频率(IDF)、字段长度归一化
注意:Lucene默认使用BM25(比TF-IDF更先进)
6、排序并返回Top-K
- 按得分排序
- 返回前N个文档(支持分页)
5、倒排表的压缩技术(关键优化)
Posting List可能非常大,Lucene使用多种压缩技术。
1、Delta Encoding(差值编码)
- DocID通常是递增的,存储差值而非原始值
- 例如:[100, 102, 105] → [100, 2, 3]
2、Variable-Byte Encoding(VBCode)
- 小整数用1字节存储,大整数用多字节
- 节省空间,适合Posting List
3、PForDelta/Simple16
- 高效压缩整数数组
- 支持快速随机访问
4、Roaring Bitmap
- 对于高频词(如"the"),使用位图代替列表
- 极致压缩 + 快速集合运算(AND/OR)
6、Lucene中的高级结构:FST(Finite State Transducer)
1、什么是FST?
FST(有限状态转换器)是一种有向图数据结构,它扩展了FSA (Finite State Automaton, 有限状态自动机)。FST不仅可以判断一个字符串是否存在于集合中,还能将输入的字符串映射到一个输出值(例如,一个整数、另一个字符串或一个复杂对象)。
在Lucene的语境下,FST主要用于词典(Term Dictionary)的实现。
它的核心功能是:
输入:一个词项(Term),例如 “search”。
输出:该词项对应的元数据信息,例如在.tim文件中的偏移量指针、文档频率(DocFreq)等,这些信息用于快速定位和读取倒排列表。
2、FST是怎么实现的?(核心机制)
Lucene的FST实现(主要在org.apache.lucene.util.fst包中)基于以下几个关键设计。
(1)、状态(State)与弧(Arc):
状态(State):图中的节点。每个状态代表处理输入字符串过程中的一个中间点。
弧(Arc):连接状态的有向边。每条弧上标记着:
- 输入标签(Input Label):通常是一个字符(或字节)。
- 输出值(Output):一个可以累积的数值(在Lucene中通常是long类型)。这个输出值是FST强大功能的核心。
从起始状态开始,沿着弧根据输入字符进行转移,最终到达一个终态。
(2)、路径输出的累积:
当从起始状态遍历到终态时,路径上所有弧的输出值会进行累积(通常是求和)。
这个累积的总输出值就是该输入字符串(词项)所映射的最终结果。
示例:查找"sea"。
- s -> 弧输出100 -> 状态A
- e -> 弧输出20 -> 状态B
- a -> 弧输出5 -> 终态
- 最终输出 = 100 + 20 + 5 = 125。这个125可能就是词项"sea"在索引文件中的偏移量。
(3)、高度压缩与共享:
-
前缀共享(Prefix Sharing):这是FST空间效率高的根本原因。所有具有相同前缀的词项(如 “search”, “seek”, “sea”)会共享从起始状态到分叉点之前的路径。
-
后缀共享 (Suffix Sharing):更进一步,FST构建算法(通常是基于排序的)会尝试让具有相同后缀的路径也进行共享。例如"cat", “bat”, "hat"的后缀"at"可以共享。
-
最小化 (Minimization):构建过程会生成一个最小化的FST,即在保证功能相同的前提下,拥有最少的状态和弧。这极大地减少了存储空间。
(4)、与磁盘文件的结合:
FST本身存储的是词项到元数据指针的映射。
这个元数据指针(即FST查询的输出值)通常指向.tim文件中的某个位置,那里存储着更详细的词典信息(如词频、指向 .doc/.pos文件的指针等)。
.tip (Term Index)文件可以看作是一个“超级FST的索引”,它存储了.tim文件中大块FST数据块的入口指针,用于加速对.tim文件的随机访问。
3、FST优势
Lucene选择FST作为词典实现,是为了解决大规模索引中词典存储和查询的效率问题,其优势如下。
(1)、空间效率极高(High Space Efficiency)
核心优势。通过前缀和后缀的深度共享,FST能够以极小的空间存储海量的词项。这对于搜索引擎动辄数百万、上亿词项的场景至关重要。相比于简单的哈希表或Trie,FST的空间占用要小得多。
(2)、支持高效的前缀查询(Prefix Query)
由于前缀共享,查找所有以"searc"开头的词项非常高效。算法可以快速定位到代表"searc"的状态,然后遍历从该状态出发的所有路径,即可得到所有匹配的词项及其输出值。
(3)、支持模糊查询(Fuzzy Query)
FST可以相对高效地支持基于编辑距离(Levenshtein Distance)的模糊查询。算法可以在状态图上进行“容错”遍历,允许一定次数的插入、删除、替换操作,找到与查询词项编辑距离在阈值内的所有词项。
(4)、查询性能优秀(Good Query Performance)
查找一个词项的时间复杂度接近O(词项长度)。虽然比哈希表的O(1)稍慢,但考虑到其巨大的空间优势,这个查询速度对于搜索引擎来说是完全可以接受的,并且远快于线性扫描。
(5)、支持复杂映射(Supports Complex Mapping):
FST的“转换”特性允许它将字符串映射到任意(可累积的)数值。Lucene利用这一点,将词项映射到其在磁盘文件中的物理位置(偏移量),实现了词典逻辑与物理存储的解耦。
(6)、支持正则匹配 (Regular Expression Matching):
FST本质上是正则语言的接受器,因此可以支持正则表达式查询。

总结来说,**Lucene采用FST是一个在空间和时间复杂度之间取得卓越平衡的设计。它牺牲了哈希表极致的查询速度(O(1)),换来了数量级上的空间压缩,并同时获得了对前缀、模糊、正则等复杂查询的天然支持。**这种设计使得Lucene能够在有限的硬件资源下,构建和维护极其庞大的倒排索引,是其高性能的关键基石之一。
7、实现示例
1、Lucene的倒排索引实现
- Segment结构:
- 每个Segment包含:
- Term Dictionary:FST存储。
- Posting List:按文档ID排序并压缩。
- 字段存储(Stored Fields):原始文档字段值。
- 每个Segment包含:
- 实时搜索优化:
- 默认1秒刷新(Refresh)生成新Segment,实现近实时(NRT)搜索。
2、Elasticsearch的分布式索引
写入流程:
1、客户端发送请求到协调节点(Coordinating Node)。
2、协调节点路由文档到主分片(Primary Shard)。
3、主分片写入内存缓冲区和Translog,同步到副本分片(Replica Shard)。
4、定期刷新生成Segment,合并优化。
8、倒排索引vs正排索引vs列存(Doc Values)
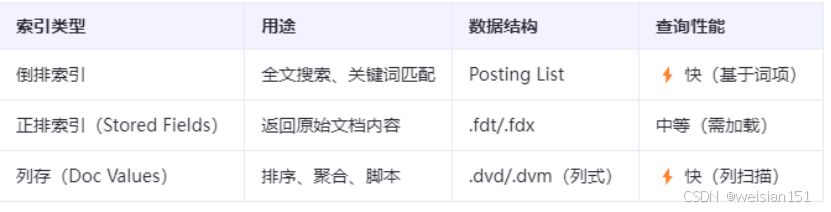
注意:
- 倒排索引适合“找包含某词的文档”
- Doc Values适合“按price排序”或“按category聚合”
9、Lucene中如何查看倒排索引?
可以使用Lucene自带的IndexReader查看索引内容。
java示例:
Directory directory = FSDirectory.open(Paths.get("/path/to/index"));
IndexReader reader = DirectoryReader.open(directory);// 获取某个字段的Terms
Terms terms = reader.terms("content");
TermsEnum termsEnum = terms.iterator();while (termsEnum.next() != null) {BytesRef term = termsEnum.term();System.out.println("Term: " + term.utf8ToString());// 获取倒排表PostingsEnum postings = termsEnum.postings(null);while (postings.nextDoc() != PostingsEnum.NO_MORE_DOCS) {int docId = postings.docID();int freq = postings.freq(); // 词频System.out.println("DocID: " + docId + ", Freq: " + freq);}
}
10、总结:倒排索引的核心要点
倒排索引通过词项到文档的映射,解决了大规模文本数据的快速检索问题。其构建流程包括分词、排序、Segment生成和合并优化,结合压缩、缓存、分布式等技术进一步提升性能。无论是Lucene的单机实现,还是Elasticsearch的分布式架构,倒排索引都是高效搜索的核心基础。实际应用中需结合分词、压缩和分布式策略,平衡存储成本与查询效率。
重点:
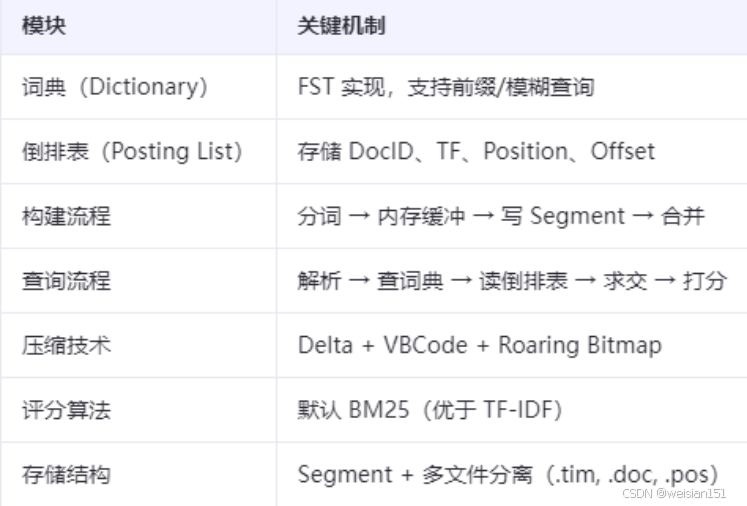
为什么倒排索引如此高效?
- 空间换时间:预构建索引,牺牲存储换取查询速度。
- 只读设计:Segment不可变,便于缓存和并发读。
- 分治思想:大索引拆分为多个Segment,支持并行处理。
- 压缩优化:减少磁盘I/O,提升缓存命中率。
向阳前行,Dare To Be!!!