HOVER:用于人形机器人的多功能全身神经控制器
25年3月来自Nvidia、CMU、伯克利分校、德州奥斯丁分校和 UCSD 的论文“HOVER: Versatile Neural Whole-Body Controller for Humanoid Robots”。
人形机器人的全身控制需要适应导航、移动操作和桌面操作等多种任务,每种任务都需要不同的控制模式。例如,导航依赖于根速度或位置跟踪,而桌面操作则优先考虑上半身关节角度跟踪。现有方法通常针对特定指令空间训练单独的策略,这限制它们在不同模式间的迁移性。其提出一个关键见解:全身运动学运动模仿可以作为所有这些任务的通用抽象,并为学习多种全身控制模式提供通用的运动技能。基于此,提出 HOVER(人形机器人通用控制器),这是一个多模式策略蒸馏框架,它将不同的控制模式整合到一个统一的策略中。HOVER 能够在控制模式之间实现无缝切换,同时保留每种模式的独特优势,为跨多种模式的人形机器人控制提供一个稳健且可扩展的解决方案。通过消除针对每种控制模式重训练策略的需求,该方法提高未来人形机器人应用的效率和灵活性。
HOVER 是一款用于人形机器人全身控制的统一神经控制器,如图所示,它支持多种控制模式,包括超过 15 种适用于实际应用的模式,可用于 19 自由度人形机器人。这种多功能的指令空间涵盖先前工作 [9, 10, 12, 13] 中使用的大多数模式。为了确保运动技能的稳健基础,使其能够很好地泛化到各种任务中,其训练一个预言式运动模仿器,以模仿来自 MoCap [17] 的大规模人体运动数据,涵盖各种运动和控制目标。这种设计选择利用人体运动固有的适应性和自然效率,为策略提供丰富的运动先验信息,这些信息可以在多种控制模式下重用。通过将训练过程建立在类人运动的基础上,该策略能够更深入地理解平衡、协调和运动控制,这些对于有效的全身人形机器人行为至关重要。通过策略蒸馏过程,将这些运动技能从预言式策略迁移到一个能够处理多种控制模式的单一“通用策略”中。
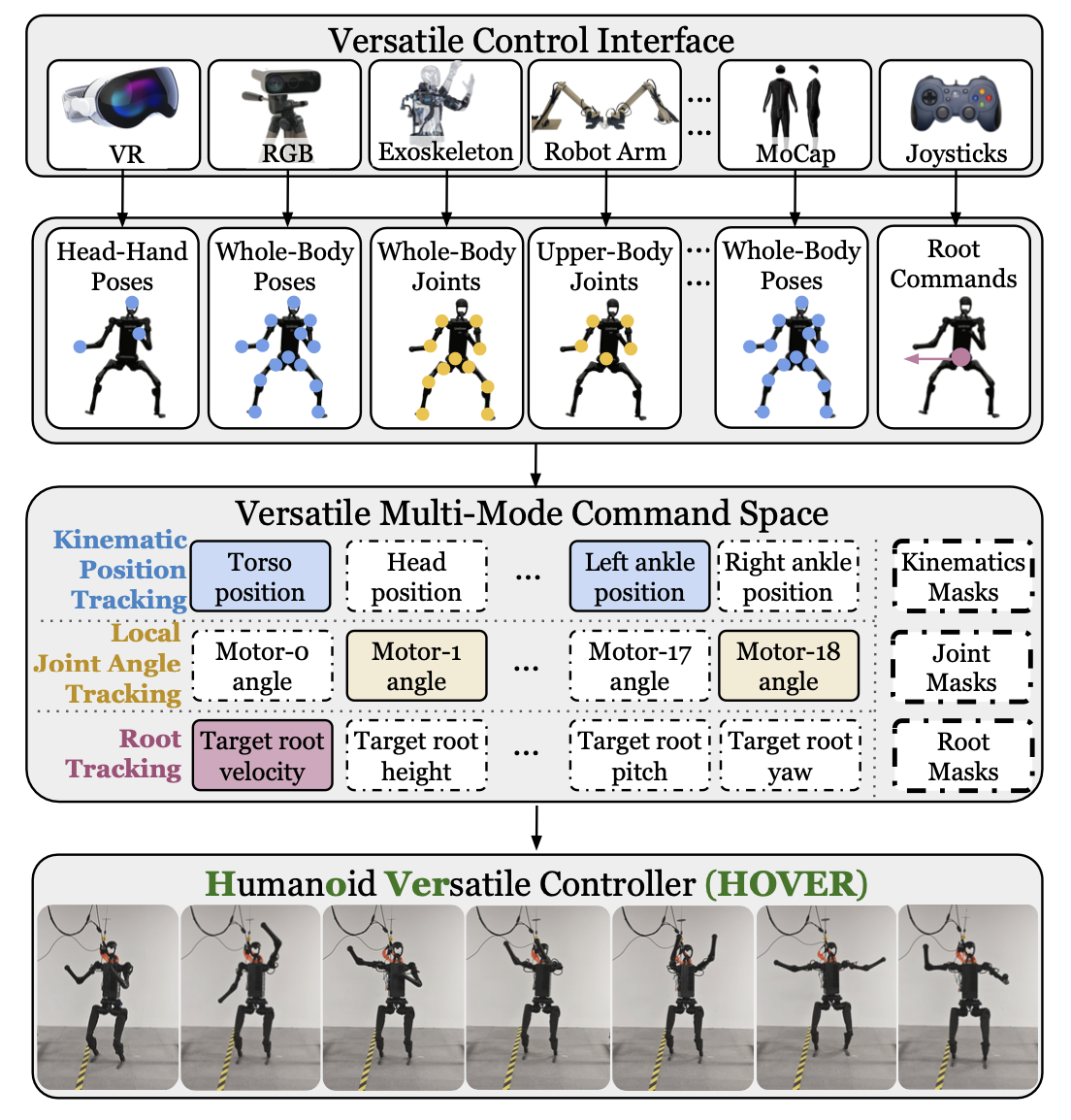
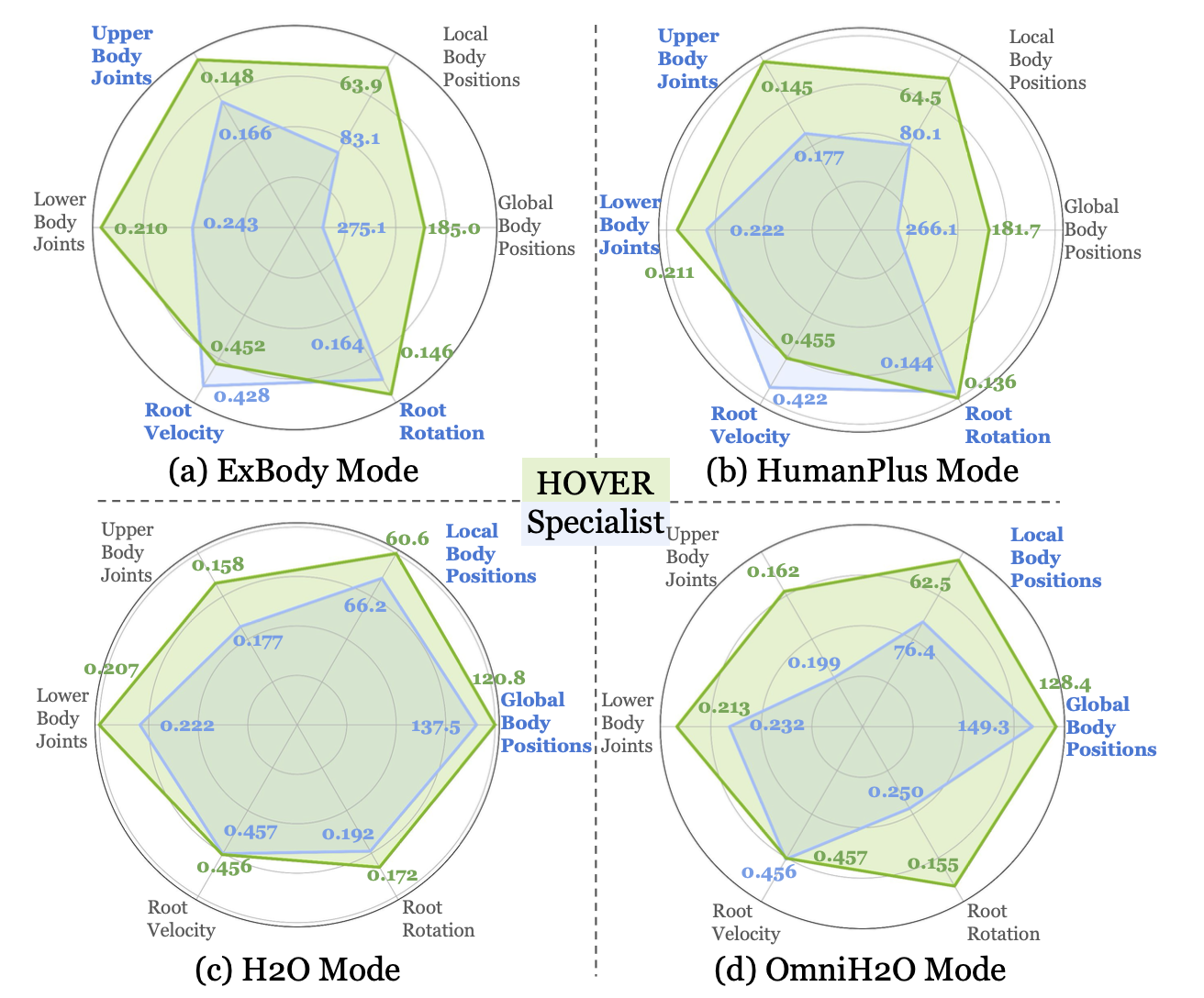
如图所示,由此产生的多模式策略不仅支持多种控制模式,而且性能优于针对每种模式单独训练的策略,主要因为该策略利用跨模式共享的物理知识,例如保持平衡、类人运动和精确的肢体控制。这些共享技能增强泛化能力,从而在所有模式下都取得更好的性能。相比之下,单模式策略通常过拟合特定的奖励结构和训练环境,限制其适应性。多模式通用策略还能够实现模式间的无缝转换,使其兼具鲁棒性和通用性。
面向目标的强化学习用于人形机器人控制
将问题建模为一个目标条件强化学习(RL)任务,其中策略π被训练来跟踪实时的人体运动。状态s_t包含智体的本体感觉sp_t和目标状态sg_t。目标状态sg_t提供目标运动的统一表示。利用智体的本体感觉sp_t和目标状态sg_t,定义用于策略优化的奖励r_t = R(sp_t, sg_t)。动作a_t表示目标关节位置,这些位置被输入到PD控制器以驱动机器人的自由度。
采用近端策略优化(PPO)算法[18]来最大化累积折扣奖励E[sum(γt-1r_t)_t=1, T]。该设置被构建为一个指令跟踪任务,其中人形机器人学习在每个时间步跟踪目标指令。
人形机器人控制的指令空间设计
在腿式运动中,根速度[19]或位置跟踪[20]是常用的指令空间。然而,仅仅关注根跟踪会限制人形机器人的全部能力,尤其是在全身运动操作任务中。虽然先前的工作[9, 10, 12, 13]引入具有不同优缺点的控制模式,但每种模式通常都针对特定的任务子集,因此缺乏通用人形机器人控制所需的灵活性。相比之下,目标是设计一个能够适应各种场景并可应用于不同人形机器人任务的综合控制框架。为了实现这一目标,指令空间必须满足以下关键标准:
通用性:指令空间应涵盖大多数现有配置,允许通用控制器在不牺牲性能或通用性的前提下替代特定任务控制器。此外,该空间应具有足够的表达能力,以便与现实世界的控制设备进行交互,包括操纵杆、键盘、动作捕捉系统、外骨骼和虚拟现实 (VR) 头戴设备。
原子性:指令空间应由独立的维度构成,从而支持控制选项的任意组合,进而支持各种控制模式。
基于这些标准,定义一个用于人形机器人全身控制的统一指令空间。该空间由两个主要控制区域——上半身控制和下半身控制——组成,并包含三种不同的控制模式:
• 运动学位置跟踪:机器人上关键刚体点的三维目标位置。
• 局部关节角度跟踪:每个机器人电机的关节角度目标。
• 根跟踪:目标根的速度、高度和方向,由横滚角、俯仰角和偏航角指定。
在框架中,引入一个one-hot掩码向量来指定哪些指令空间分量被激活用于跟踪。如表所示,最近基于学习的人形机器人全身控制工作 [9, 10, 12, 13] 可以看作是统一指令空间的子集,每个子集代表特定的配置。

运动重定向
最近的研究表明,从大型运动数据集中学习人形机器人的鲁棒全身控制具有优势 [9, 10, 12, 13]。从人体运动数据集 [17] 到人形机器人运动数据集的重定向过程分为三个步骤:
步骤 1:首先使用正向运动学计算人形机器人的关键点位置,将其关节配置映射到工作空间坐标。
步骤 2:接下来,通过优化 SMPL 参数,使模型与正向运动学计算出的关键点对齐,从而拟合 SMPL 模型以匹配人形机器人的运动学。
步骤 3:最后,使用梯度下降法,将拟合的 SMPL 模型与人形机器人之间的对应关键点进行匹配,从而重新定位 AMASS 数据集。
遵循与 [10] 相同的运动重定向和“模拟-到-数据”流程,将大规模人体运动数据集 [17] 转换为仅包含人形机器人可行运动的数据集 Qˆ。
基于大规模人体运动的 Oracle 策略训练
状态空间设计。训练一个 oracle 运动模仿器 πoracle(a_t |sp-oracle_t, sg-oracle_t)。本体感觉定义为: sp-oracle_t ≜ [p_t, θ_t, p ̇_t, ω_t, a_t-1],其中包含人形刚体位置 p_t、方向 θ_t、线速度 p ̇_t、角速度 ω_t 以及前一个动作 a_t−1。目标状态定义为 sg-oracle_t ≜ [θˆ_t+1 ⊖ θ_t, pˆ_t+1 − p_t, vˆ_t+1 −v_t, ωˆ_t+1− ω_t, θˆ_t, pˆ_t],其中包含人形机器人所有刚体的参考姿态 (θˆ_t, pˆ_t) 以及参考状态与当前状态之间的一帧差值。用与文献 [9] 相同的策略网络结构,即一个三层 MLP,其层维度为 [512, 256, 128]。
奖励设计和域随机化。将奖励 r_t 表示为三个部分之和:1) 惩罚项,2) 正则化项,以及 3) 任务奖励,详见下表。遵循 [9] 中的相同域随机化方法,对模拟环境和人形机器人的物理参数进行随机化,以实现从模拟-到-现实的成功迁移。
基于蒸馏的多模式通用控制器
本体感觉。对于从预言教师 πoracle 中蒸馏的学生策略 πstudent(sp-student_t, sg-student_t),本体感觉定义为 sp-student_t ≜ [q, q̇, ωbase, g]_t−25:t ∪ [a_t−25:t−1],其中 q 为关节位置,q̇ 为关节速度,ωbase 为基座角速度,g 为重力矢量,a 为动作历史。参考 [9],将最后 25 步的这些项堆叠起来,以表示学生的本体感觉输入。
命令掩码。如图所示,学生策略的任务命令输入使用基于模式和基于稀疏性的掩码定义。具体来说,学生的任务指令输入 sg-student_t 表示为 sg-student_t ≜ M_sparsity ⊙ [M_mode ⊙ sg-upper_t, M_mode ⊙ sg-lower_t]。模式掩码 M_mode 分别独立地为上半身和下半身选择特定的任务指令模式。例如,上半身可以跟踪运动学位置,而下半身则专注于关节角度和根部跟踪,如图所示。在模式特定的掩码之后,应用稀疏性掩码 M_sparsity。例如,在某些情况下,上半身可能只跟踪手部的运动学位置,而下半身只跟踪躯干的关节角度。模式和稀疏性二进制掩码的每一位都服从伯努利分布 B(0.5)。模式和稀疏性掩码在回合开始时随机化,并在回合结束前保持不变。
策略蒸馏。用 DAgger 框架 [22] 进行策略蒸馏。对于每个回合,在模拟中展开学生策略 πstudent(a_t | sp-student_t, sg-student_t) 以获得 (sp-student_t, sg-student_t) 的轨迹。在每个时间步,还计算相应的预言机状态 (sp-oracle_t, sg-oracle_t)。利用这些预言机状态,查询预言机教师策略 πoracle(aˆ_t | sp-oracle_t, sg-oracle_t) 以获得参考动作 aˆ_t。然后通过最小化损失函数来更新学生策略 πstudent:L = ||aˆ_t − a_t||2_2,其中 aˆ_t 是来自预言机的参考动作,a_t 是学生策略采取的动作。
实验设置。分别在仿真环境和真实环境中评估HOVER的运动跟踪性能。在仿真环境中,用重新定向的AMASS数据集Qˆ进行评估。在真实环境中,测试20个站立运动序列,重点关注定量跟踪和运动任务,以进行定性的多模式控制。真实机器人采用19自由度的Unitree H1平台[24],总质量约为51.5kg,高度约为1.8m。
基线。将HOVER与几个专业机器人进行比较。ExBody [12] 侧重于跟踪上半身关节角度和根速度,HumanPlus [13] 跟踪全身关节和根速度,H2O [10] 跟踪八个关键点(肩部、肘部、手部、踝部)的运动学位置,而 OmniH2O [9] 跟踪头部和双手的运动学位置。还比较其他一些有用的跟踪模式(例如,左手模式、右手模式、双手模式、头部模式)。对于每种控制模式,仅向控制器提供相关的观测输入,并使用强化学习 (RL) 训练相应的基线模型。例如,在仅左手模式下,仅提供左手的参考运动。与另一种多模式强化学习策略进行比较。该策略对目标指令采用相同的掩码处理,但从头开始使用强化学习目标训练基线模型。在多模式强化学习基线训练中,模式和稀疏度在每个回合开始时随机化,并保持固定直到回合结束,这与蒸馏过程中的随机掩码过程相同。
指标。生存率,即如果人形机器人落地(非脚着地),则回合结束。根据运动学姿态、关节角度以及根扭转和旋转来计算跟踪误差。这些指标的平均值是在数据集 Qˆ 的所有运动序列上计算的。通过比较全局身体位置的跟踪误差 E_g−mpjpe (mm)、根相对平均关节位置 (MPJPE) E_mpjpe (mm)、关节跟踪误差 E_j (rad)、根速度 E_root-vel (m/s) 和根方向跟踪误差 E_root-rpy (rad) 来评估策略模仿参考运动的能力。为了展示物理真实性,报告平均关节加速度误差 E_acc (mm/frame2) 和速度误差 Evel (mm/frame)。