MotionTrans: 从人类VR数据学习机器人操作的运动级迁移
论文概述
这是一篇来自清华大学、北京大学等机构的机器人操作学习研究工作。论文提出了MotionTrans框架,通过VR采集的人类演示数据,使端到端机器人策略能够直接学习和执行新的操作动作。研究团队在15个人类任务和15个机器人任务上进行联合训练,实现了13个人类任务的运动级迁移,其中9个任务在零样本设置下达到了良好的成功率。
论文地址: https://arxiv.org/abs/2509.17759
项目主页: https://motiontrans.github.io/

一、研究动机与核心问题
1.1 机器人数据稀缺问题
机器人操作学习面临的最大瓶颈是真实机器人数据的采集成本高昂且耗时。虽然互联网数据可以为视觉理解和语言理解提供丰富的预训练资源,但运动知识(motion knowledge)的获取仍然是一个挑战。
1.2 人类数据的潜力
人类演示数据具有以下优势:
- 数据丰富:容易大规模采集
- 动作多样:包含丰富的操作行为
- 采集便捷:使用VR设备即可随时随地采集
但关键问题是:人类数据能否让机器人策略直接学习新的运动模式来完成任务?
虽然之前的工作已经证明人类数据可以提升视觉理解、鲁棒性和训练效率,但运动级别的迁移(motion-level transfer)——即让机器人直接从人类数据中学会完成新任务的动作——仍未被系统性地验证。
二、MotionTrans框架详解
MotionTrans框架包含三个核心模块:
2.1 人类-机器人数据采集系统


人类数据采集
- 硬件:Meta Quest 3 VR头显 + ZED2相机
- 采集内容:
- 手部关键点位置 KtK_tKt
- 手腕姿态 WtW_tWt
- 自身视角RGB图像 ItI_tIt
- 数据质量保障:
- VR视野实时反馈RGB相机捕捉范围
- 手部位置对齐提示
- 支持手势交互放弃低质量数据
机器人数据采集
- 硬件平台:Franka Emika机械臂 + Inspired 6自由度灵巧手
- 遥操作系统:基于Open-Television开发,通过VR实时捕捉人类动作并驱动机器人复现
2.2 人类数据到机器人格式的转换
这是框架的核心创新之一。目标是将人类数据转换为"伪机器人数据",使其可以直接用于训练端到端策略。
观察-动作空间定义
策略的输入输出空间 S=(It,Pt,At)S = (I_t, P_t, A_t)S=(It,Pt,At):
- 图像观察 It∈RH×W×3I_t \in \mathbb{R}^{H \times W \times 3}It∈RH×W×3:自身视角RGB图像
- 本体感知状态 Pt∈RTP×DP_t \in \mathbb{R}^{T_P \times D}Pt∈RTP×D:机器人手腕姿态+手部关节状态的历史
- 动作 At∈RTA×DA_t \in \mathbb{R}^{T_A \times D}At∈RTA×D:动作块预测(action chunk)
关键转换步骤
-
图像观察:人类和机器人都使用自身视角,保证空间关系一致
-
手腕姿态:统一到自身相机坐标系,通过标定将VR坐标系转换到RGB相机坐标系
-
手部关节:使用dex-retargeting库(基于优化的逆运动学求解器)将人类手部关键点映射到机器人手部关节
-
关键优化:
- 速度调整:人类动作速度比机器人快2.25倍,通过插值降速
- 相对姿态表示:使用基于动作块的相对姿态而非绝对姿态,减少人机分布差异
- 视角多样化:鼓励采集者改变相机视角,增强机器人工作空间泛化能力
2.3 加权多任务联合训练
策略架构选择
研究探索了两种主流端到端策略:
-
Diffusion Policy (DP):
- 扩展为多任务版本,每个任务有可学习的嵌入作为条件
- 视觉编码器使用DINOv2增强视觉感知
-
π₀-VLA(Vision-Language-Action模型):
- 集成大规模预训练的视觉-语言模型
- 支持语言指令进行任务分配
- 从π₀-droid预训练权重开始训练
统一动作归一化
与之前工作不同,MotionTrans对人类和机器人数据采用统一的Z-score归一化。原因是在运动级评估中,独立归一化会导致训练(人类归一化)和推理(机器人归一化)之间的不匹配。
加权联合训练策略
训练目标:
LD=αLDrobot+(1−α)LDhuman\mathcal{L}_D = \alpha \mathcal{L}_{D_{\text{robot}}} + (1-\alpha) \mathcal{L}_{D_{\text{human}}}LD=αLDrobot+(1−α)LDhuman
权重设置:
α=∣Dhuman∣∣Dhuman∣+∣Drobot∣\alpha = \frac{|D_{\text{human}}|}{|D_{\text{human}}| + |D_{\text{robot}}|}α=∣Dhuman∣+∣Drobot∣∣Dhuman∣
这确保了人类和机器人数据权重总和相等,实现数据源平衡。
三、MotionTrans数据集

3.1 数据集规模
- 总计:3,213条演示
- 人类任务:15个任务,1,705条演示
- 机器人任务:15个任务,1,508条演示
- 场景数量:超过10个场景
3.2 任务覆盖
数据集覆盖了丰富的运动技能:
人类任务示例:
- 拔充电器(Unplug Charger)
- 合上笔记本电脑(Close Laptop)
- 物品放置(Banana-Plate, Orange-Bucket)
- 倾倒瓶子(Pour Bottle)
- 擦毛巾(Wipe Towel)
- 压订书机(Press Stapler)
机器人任务示例:
- 推方块(Push Cube)
- 物品放置(Bread-Pad, Panda-Box)
- 打开盒子(Open Box)
- 倒可乐(Pour Cola)
- 按鼠标(Press Mouse)
关键特点:
- 人类和机器人任务集不重叠
- 某些运动模式(如拔插、合上、抬起)仅出现在人类数据中
- 相似任务(如不同的抓取-放置)在人机数据间有运动模式的相似性但仍有差异
3.3 数据集对比
| 数据集 | 人类演示 | 人类任务 | 野外场景 | 机器人演示 | 机器人任务 | 野外场景 |
|---|---|---|---|---|---|---|
| EgoMimic | 2,150 | 3 | 0% | 1,000 | 3 | 0% |
| PH²D | 26,842 | 4 | 100% | 1,552 | 4 | 0% |
| MotionTrans | 1,705 | 15 | 100% | 1,508 | 15 | 50% |
MotionTrans在任务/运动覆盖度和场景多样性方面都有显著提升。
四、实验结果与核心发现
4.1 零样本实验(Zero-shot)
实验设置:在MotionTrans数据集上训练策略后,直接部署到真实机器人上执行人类任务,不为这些人类任务收集任何机器人数据。
主要结果
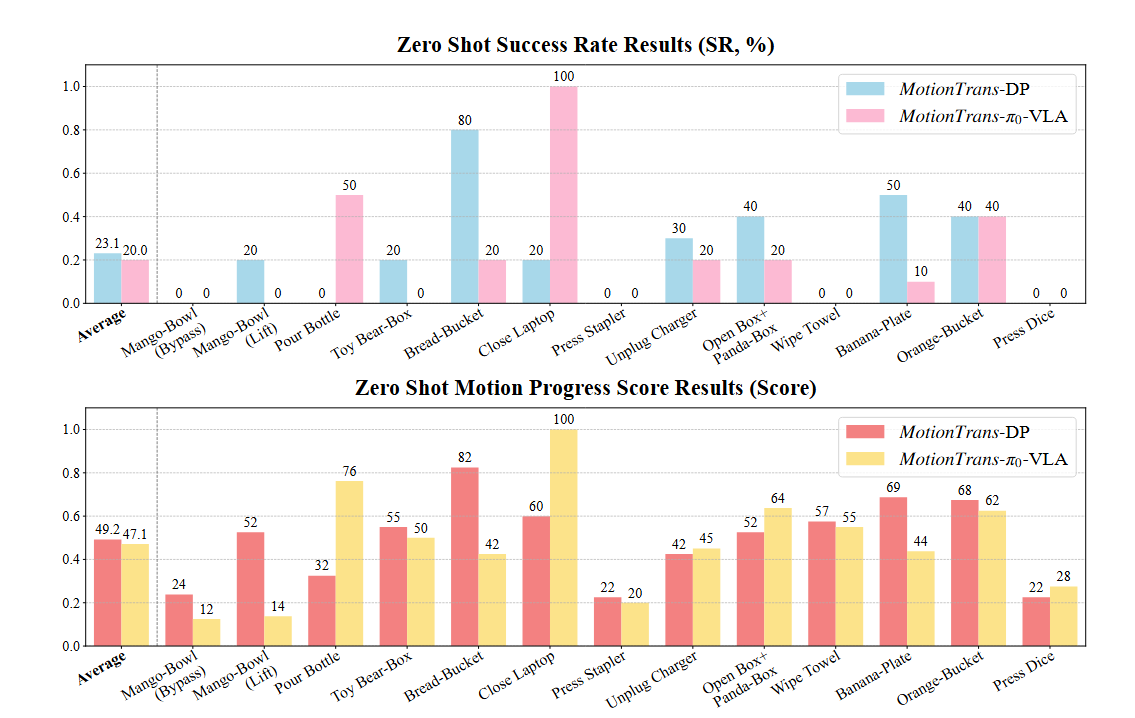
| 模型 | 平均成功率 | 平均运动进度得分 |
|---|---|---|
| MotionTrans-DP | 23.1% | 0.492 |
| MotionTrans-π₀-VLA | 20.0% | 0.471 |
关键发现:
-
9个任务达到非零成功率,平均成功率约20%
- 抓取-放置任务占多数(如Orange——>Bucket: 70%, Banana——>Plate: 50%)
- 其他成功的运动包括:倾倒、拔插、抬起、开启和合上
-
所有任务都展现出有意义的运动
- 平均运动进度得分约0.5(归一化到[0,1])
- 即使未完成任务,策略也能学会接近目标物体
- 例如"Wipe Towel"任务中学会了"向前推毛巾"的动作
-
与机器人数据联合训练是关键
- 仅用人类数据训练的策略成功率为0%
- 机器人数据帮助弥合人机差异,使人类动作适应机器人实体
-
DP vs π₀-VLA的差异:
- DP:在精确操作(如抓取)上表现更好,平均抓取成功率65%
- π₀-VLA:在指令遵循和任务语义理解上更强(如倾倒动作的完整执行),但抓取成功率仅20%
- 两者平均性能相近,各有所长
真机部分可视化结果:

4.2 少样本微调实验(Few-shot)
实验设置:为所有人类任务额外收集20条机器人演示,使用5-shot和20-shot设置进行微调。这里指作者比较了不同预训练方式在5-shot(5个示例)和20-shot(20个示例)微调设置下的表现。
对比基线
- MotionTrans: 人类+机器人数据预训练
- from-scratch:不使用预训练,直接训练
- robot-only:仅在机器人数据上预训练
- human-only:仅在人类数据上预训练
主要结果
平均成功率提升:
- 5-shot:MotionTrans比from-scratch提升约40%
- 20-shot:MotionTrans仍保持显著优势
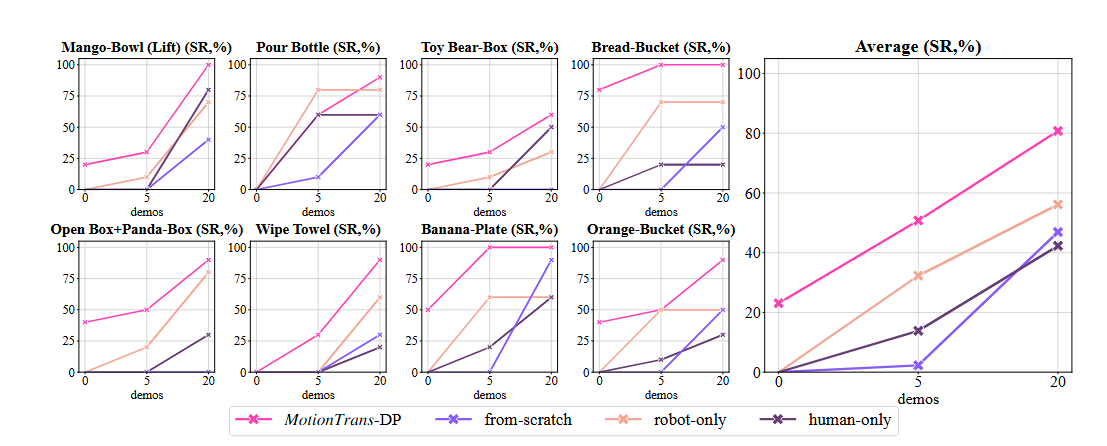
关键发现:
-
人机数据联合预训练效果最佳
- MotionTrans > robot-only > human-only > from-scratch
-
实体匹配比任务匹配更重要
- robot-only(相同实体,不同任务)比human-only(不同实体,相似任务)效果更好
- 说明机器人数据的分布更接近下游微调分布
-
低数据区域效果更显著
- 在5-shot设置下,预训练的优势最大
- 20-shot时,robot-only优势减小,human-only优势消失
总结就是,当微调数据很少时,人类-机器人联合预训练的优势最明显;随着微调数据增多,预训练的优势会逐渐减弱。
这是一个经典的数据效率问题:
数据少时:预训练知识能填补数据不足的空白,帮助模型快速适应新任务数据多时:充足的任务特定数据本身就能让模型学好,预训练的边际收益递减
4.3 设计消融实验
| 变体 | 运动进度得分 | 成功率 |
|---|---|---|
| w/ Abs Pose (使用绝对位姿) | 0.370 | 10.0% |
| w/ ED-Norm (具身依赖的归一化) | 0.341 | 8.4% |
| w/ Visual Rendering (视觉渲染) | 0.475 | 23.1% |
| MotionTrans-DP | 0.492 | 23.1% |
这里解释下消融实验的变体:
- w/ Abs Pose(使用绝对位姿)
- 改动:用绝对自我中心位姿替代原本的"基于动作块的相对位姿"
- 结果:Score降至0.370,成功率降至10.0%
- 原因:绝对位姿会增大人类和机器人动作标签之间的分布差异,阻碍运动迁移
- 举例:人类手在世界坐标系中的位置和机器人手的舒适工作空间分布不同,用绝对位姿会导致不匹配
- w/ ED-Norm(具身依赖的归一化)
- 改动:对人类数据和机器人数据分别进行独立的动作和本体感觉归一化
- 结果:Score降至0.341,成功率降至8.4%
- 原因:训练时用人类数据的归一化,推理时用机器人的归一化,造成了不匹配
- 关键洞察:这种方法在之前的工作中用于提高视觉鲁棒性是有效的,但在运动级别的迁移场景下反而有害
- w/ Visual Rendering(视觉渲染)
- 改动:将机器人在仿真中重放,然后把渲染的机器人裁剪粘贴到原始RGB图像上(见Figure 9)
- 结果:Score 0.475,成功率23.1%(与原版几乎相同)
- 发现:渲染并没有带来显著改进
- 可能原因:尽管对人类看起来很真实,但神经网络仍能识别出具身域的线索,和原始人类视频区别不大
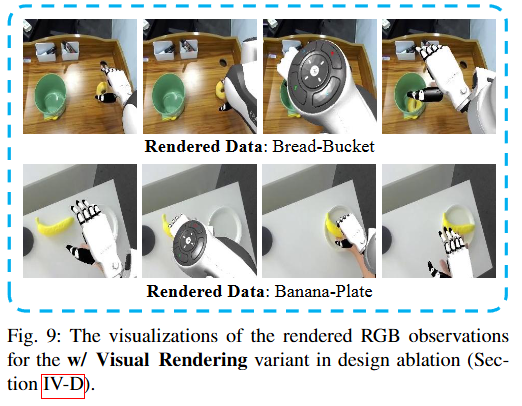
这里再详细补充下什么是视觉渲染:
视觉渲染的具体步骤
- 步骤1:重放机器人轨迹
- 在仿真环境中,按照记录的机器人动作轨迹重新执行一遍
- 这样就能从相同视角渲染出机器人的3D模型
- 步骤2:裁剪机器人
- 从仿真渲染的图像中,把机器人手臂部分单独抠出来
- 类似于抠图,只保留机器人手臂,背景透明- 步骤3:粘贴到原图
- 把抠出来的机器人手臂,粘贴回原始真实拍摄的RGB图像上
- 替换掉原本画面中机器人手臂的位置
这样做的主要目的是弥补仿真和真实数据的视觉差异,但是实验结果表明视觉渲染并没有起到任何作用。
对比:MotionTrans原版设计
- Score: 0.492
- 成功率: 23.1%
- 采用:
- 相对位姿表示(降低分布差异)
- 统一的动作归一化(训练-推理一致)
- 不使用视觉渲染(性价比低)
作者通过这个消融实验得出了一个重要观点:
当目标是运动级别的迁移和评估时,某些设计的有效性可能与用人类数据提高视觉鲁棒性或训练效率时的有效性不同。
也就是说:
- ED-Norm 在提高视觉鲁棒性时有用 → 但在运动迁移时有害
- 视觉渲染 看起来应该有帮助 → 实际上没什么用
- 相对位姿 是运动迁移的关键 → 绝对位姿会破坏迁移效果
这强调了针对不同目标(视觉鲁棒性 vs 运动迁移)需要采用不同的设计策略。
核心发现总结:
-
相对姿态 vs 绝对姿态:
- 使用绝对姿态显著降低性能
- 相对姿态减少了人机动作标签的分布差异
-
统一归一化 vs 实体依赖归一化:
- 实体依赖归一化在运动级迁移中造成训练-推理不匹配
- 与之前提升视觉鲁棒性的研究结论不同
-
视觉渲染效果有限:
- 将机器人渲染到人类视频中并未带来显著提升
- 可能是因为渲染结果仍包含实体域线索
五、运动迁移机制分析
5.1 动作如何迁移?
案例研究:Bread——>Bucket任务(将面包放入桶中)
研究团队训练了不同任务子集的策略,重点关注放置高度这一具体维度:
| 训练集 | 放置高度 | 成功率 |
|---|---|---|
| H-bucket(仅人类) | 15.3cm | 0% |
| H-bucket + R-pad | 0.3cm | 0% |
| H-bucket + R-platform | 20.7cm | 30% |
| H-bucket + R-pad + R-platform | 0.3-20.7cm | 40% |
| + PP-set(更多抓放任务) | - | 70% |
| 全部数据 | - | 80% |
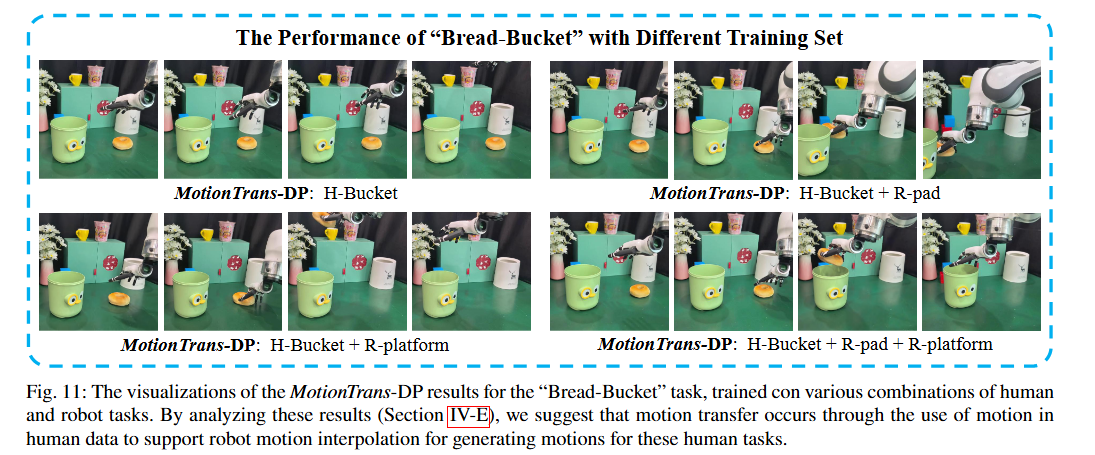
核心假设:
人类任务完成的动作是通过插值机器人数据中的动作生成的(如从R-Pad的0.3cm和R-Platform的20.7cm插值到H-Bucket的15.3cm)。这种插值能力是通过学习人类数据中的任务感知运动获得的。
机制总结:
- 策略从人类数据中学习任务感知的运动模式
- 推理时遇到机器人实体,在机器人数据定义的安全操作范围内生成动作
- 任务特定元素(如任务标识符或图像中的相关物体)触发插值过程
5.2 视觉感知如何迁移?
通过DINOv2编码器和Grad-CAM可视化注意力图:

发现:
- 视觉编码器能够关注人类数据任务中的目标操作物体
- 即使实体从人类切换到机器人,这种注意力模式依然保持
- 形成了实体不变的任务感知表示
总结就是:这解释了为什么模型能够在零样本情况下,在机器人上执行只在人类数据中见过的任务——因为它学会了关注"任务本身的关键要素"(目标物体),而不是"谁在执行任务"(人还是机器人)。
5.3 是否存在规模化趋势?
实验:逐步增加任务多样性和运动覆盖度
结果:
- 任务覆盖度增加带来性能稳步提升
- Bread-Bucket任务成功率:0% → 30% → 40% → 70% → 80%
初步结论:
运动迁移可能受益于更广泛的任务相关运动覆盖。虽然基于有限子集,但提供了规模化趋势的初步证据。
六、研究意义与影响
6.1 理论贡献
-
首次系统性验证运动级迁移
- 证明端到端策略可以直接从人类数据学习新运动
- 明确了实现条件:机器人数据联合训练 + 充足的任务相关运动覆盖
-
运动迁移机制揭示
- 提出基于插值的动作生成假设
- 发现实体不变的任务感知视觉表示
-
设计原则的澄清
- 在运动级迁移场景中,某些设计(如统一归一化)比之前视觉鲁棒性研究中的结论更有效
6.2 实践价值
-
降低机器人数据需求
- 零样本:9个任务无需机器人数据即可执行
- 少样本:预训练提升40%成功率
-
加速技能学习
- 人类数据作为丰富的运动先验
- 支持快速适应新任务
-
数据集与框架开源
- 3,213条演示的MotionTrans数据集
- 完整代码和模型权重
- 促进社区进一步研究
七、局限性与未来方向
7.1 当前局限
-
高度感知能力有限
- 单目自身视角感知存在局限
- 有时无法到达正确高度
-
数据规模
- 仍限于自采集的人类数据集
- 未扩展到互联网规模数据
7.2 未来方向
-
改进感知系统
- 为人类和机器人平台添加手腕相机
- 增强深度感知能力
-
扩大数据规模
- 探索互联网规模人类演示数据的运动级学习
- 类似于视觉-语言预训练的规模化路径
-
更复杂的运动
- 双臂协作任务
- 更精细的操作技能
-
自适应速度采样
- 当前采用固定2.25倍降速
- 探索自适应策略以更好匹配人机速度差异
八、与相关研究的对比
根据我查询的最新研究趋势,MotionTrans在以下方面具有独特性:
8.1 与现有人机数据联合训练工作的区别
| 研究 | 数据规模 | 任务数 | 评估方式 | 主要贡献 |
|---|---|---|---|---|
| EgoMimic | 2,150人类+1,000机器人 | 3(重叠) | 视觉鲁棒性 | 提升视觉泛化 |
| PH²D | 26,842人类+1,552机器人 | 4(重叠) | 训练效率 | 大规模数据收集 |
| MotionTrans | 1,705人类+1,508机器人 | 30(不重叠) | 运动级迁移 | 显式运动学习 |
核心差异:
- 之前工作:人机任务重叠,主要验证辅助性能(视觉、效率)
- MotionTrans:人机任务不重叠,直接验证运动知识迁移
8.2 与表示学习方法的区别
传统方法(如affordances、keypoint flows)使用中间表示,限制了与主流端到端策略的集成。MotionTrans直接在机器人观察-动作空间中训练,完全兼容Diffusion Policy和VLA等架构。
8.3 在AI智能体趋势中的位置
最新趋势(如上文trending papers所示)强调:
- 多模态基础模型:Qwen3-Omni、InternVL3.5等
- 强化学习推理:DeepSeek-R1、reasoning with sampling
- 智能体学习:Agent Learning via Early Experience、UI-TARS-2
MotionTrans的贡献是为具身智能体提供运动级学习能力,弥补了纯语言/视觉预训练无法获取运动知识的空白。
九、技术实现要点
9.1 数据采集最佳实践
- 最小化头部移动:模拟静态相机设置
- 实时质量反馈:VR视野显示相机捕捉范围和手部对齐
- 手势交互:支持实时放弃低质量数据
- 视角多样化:轨迹间改变视角增强泛化
9.2 坐标系标定方法
链式标定:
- 相机-棋盘标定:使用ArUco棋盘和OpenCV
- VR-棋盘标定:利用VR深度感知拟合桌面高度
- 变换链:Tcam−1TvrT^{-1}_{\text{cam}} T_{\text{vr}}Tcam−1Tvr
9.3 训练超参数
Diffusion Policy:
- 训练轮次:300 epochs
- 学习率:5×10⁻⁴
- 批次大小:1024
- 训练时间:约1.5天
π₀-VLA:
- 训练步数:160,000 steps
- 学习率:2.5×10⁻⁵
- 批次大小:192
- 训练时间:约2.5天
十、总结
MotionTrans代表了从人类数据学习机器人操作的一个重要里程碑。通过系统的框架设计和大规模实验验证,这项工作:
✅ 证明了运动级迁移的可行性:首次实现端到端策略从人类数据直接学习新运动
✅ 揭示了关键成功因素:机器人数据联合训练 + 充足运动覆盖
✅ 提供了完整工具链:从数据采集到策略部署的全流程开源
✅ 指明了规模化方向:任务多样性提升带来性能改善
这项研究为具身智能的一个核心挑战——如何从人类的丰富演示中学习可部署的机器人技能——提供了清晰的解决方案和实践指导。
相关论文推荐
- Diffusion Policy - 端到端扩散策略架构基础
- π₀-VLA - 视觉-语言-动作模型
- EgoMimic - 人机数据联合训练先驱工作
- ARCap - VR数据采集系统基础
- Open-Television - 机器人遥操作系统