【学习笔记】多智能体系统
1 多智能体系统的概念
多智能体系统是由多个自主(或半自主)的智能体 (Multi-Agent Systems, MAS)通过交互 构成的计算机系统。这些智能体在一个共享的环境 中,通过协调、协作或竞争,来解决单个智能体无法解决的复杂问题。许多现实世界的问题本质上是分布式的、并发的和社会性的。MAS的核心思想就是将复杂问题分解,由多个简单的、并行的实体(智能体)通过互动来解决,这通常比构建一个庞大而复杂的单一系统更高效、更灵活、更鲁棒。多智能体系统是社会计算层面的概念。
多智能体与群体智能的区别
群体智能(Swarm Intelligence)是通过多个个体(或智能体)的协作来实现集体行为的技术。这些个体虽然简单,但通过局部的交互可以产生出复杂的全局行为。以下是群体智能技术的一些关键特征和应用:
-
自组织:群体智能系统能够在没有中央控制的情况下,通过简单规则和局部交互实现自组织。这在模拟自然界中的昆虫群体(如蚁群、蜂群)时尤其明显。
-
适应性:群体智能系统可以适应动态变化的环境,这种特性使得它们在复杂和不确定性环境中表现出色。
-
去中心化控制:每个个体都遵循简单的规则,没有单一的控制中心,这增加了系统的鲁棒性和可扩展性。
-
鲁棒性和容错性:系统可以容忍个体故障而不会影响整体功能,这是因为行为是集体产生的,而不是依赖于某个特定的个体。
-
应用领域:
- 优化问题:例如,蚁群算法被用于解决旅行商问题和其他组合优化问题。
- 机器人群体:用于协调多个机器人执行任务,如灾难救援中的自主搜索。
- 网络路由:基于群体智能的算法可以优化数据包在网络中的传输路径。
表1 比较多智能体系统和群体智能
| 维度 | 多智能体系统 | 群体智能 |
|---|---|---|
| 设计哲学 | 自上而下,强调规划和理性 | 自下而上,强调涌现和自组织 |
| 智能体性质 | 可以是异质的(功能、目标不同) | 通常是同质的(个体简单、规则一致) |
| 系统结构 | 可以是集中式、分层式或分布式 | 完全分布式、去中心化 |
| 控制方式 | 明确的协商、通信、协调机制 | 局部感知和交互,无直接通信或通信简单 |
| 核心目标 | 解决复杂的分布式问题,体现个体理性与社会理性 | 通过简单规则实现复杂的全局模式,解决优化、自组织问题 |
| 代表性算法/应用 | 合同网协议、多智能体规划、多智能体强化学习 | 蚁群优化、粒子群优化、Boids鸟群模型 |
| 与“理性”的关系 | 紧密相连,智能体被设计为理性的决策者 | 关系松散,个体通常不具复杂性,智能在群体层面涌现 |
2 多智能体系统案例
有个斯坦福小镇Standford Smallville的案例,可参考
论文
Generative Agents: Interactive Simulacra of Human Behavior
https://arxiv.org/abs/2304.03442
代码
https://github.com/joonspk-research/generative_agents
Demo
https://reverie.herokuapp.com/arXiv_Demo/#
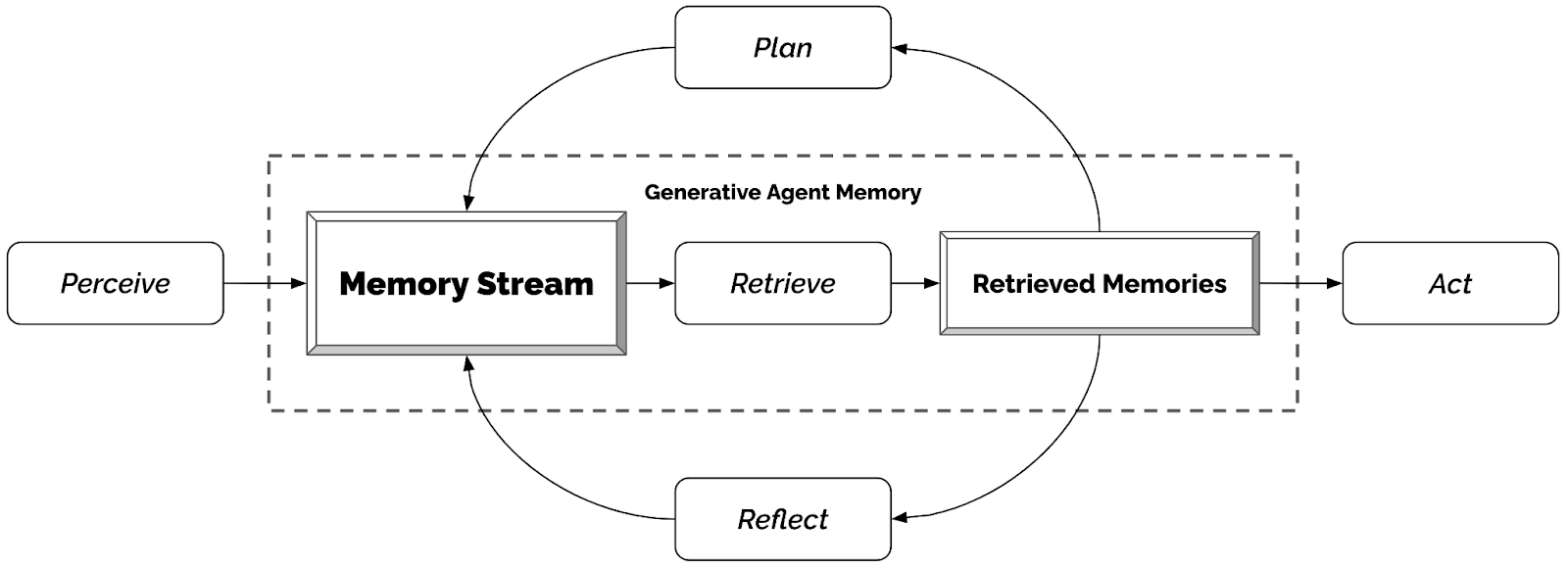
图片来源:https://hai.stanford.edu/news/computational-agents-exhibit-believable-humanlike-behavior
它深入思考了独立于人类交互的个体智能体如何生成可信的类人行为,并将其转化为简洁实用的计算架构。
该代理架构图被朴博士称为团队的核心技术贡献,其设计精妙而简洁:角色的感知输入至记忆流,反馈回路实现记忆检索,进而使代理在行动前完成反思与规划。“我们经历多次迭代,将极其复杂的理念提炼成简洁而富有表现力的架构图,”朴博士解释道。
来源:https://hai.stanford.edu/news/computational-agents-exhibit-believable-humanlike-behavior
3 多智能体系统的相关技术
多智能体协作或竞争以完成复杂任务,多智能体之间的交互会用到以下的技术。
3.1 核心决策与规划技术
博弈论:多智能体系统中的智能体可能具有竞争或合作的关系,博弈论提供了分析这些关系的方法和工具。
决策理论:用于指导智能体在交互过程中做出最佳决策,特别是在不确定性环境中。
3.2 通信与协作技术
智能体之间如何有效“沟通”是实现复杂协作的关键。
信号处理:在物理世界中的智能体可能需要对传感器数据进行处理,以识别环境中的重要信息。
通信协议:在多智能体系统中,智能体之间需要通过某种协议进行通信。常见的协议包括消息传递机制、发布/订阅模型等。
分布式系统技术:由于多智能体系统通常是分布式的,因此需要使用分布式计算技术,如分布式数据库、分布式中间件等,来保证智能体之间的协调和数据一致性。
网络技术:为了实现智能体之间的联网和远程通信,需要依赖于网络技术,如TCP/IP协议、无线传感器网络(WSN)、物联网(IoT)等。
安全与隐私技术:为了保护智能体间通信的安全,使用加密技术、身份认证等手段。
机器人技术:在物理环境中,尤其是涉及机器人时,使用传感器融合、路径规划等技术。
3.3 学习与适应技术
通过强化学习、集成学习等方法,智能体可以在交互过程中不断优化其策略和行为。
迁移学习:将一个任务中学到的知识迁移到另一个相关任务中。
元学习:学习如何学习。可参考此篇文章 【学习笔记】元学习如何解决计算机视觉少样本学习的问题?
模糊逻辑:帮助智能体处理不确定性和模糊的信息,从而在复杂环境中更有效地进行交互。
多智能体强化学习技术,细节查看4 多智能体强化学习。
3.4 知识表示与组织技术
本体论:形式化地规范领域知识。
分布式问题求解:将一个大问题分解为子问题,分配给不同的智能体去解决,最后整合结果。
组织与社会结构:为多智能体系统设计组织结构(如层次结构、团队结构、市场结构),并定义角色、权限和社会规范。
3.5 测试环境和平台
多智能体强化学习设计的环境
- 一个轻量级、功能强大的多智能体工作流框架
https://github.com/openai/openai-agents-python
- OpenAI Gym Multi-Agent / PettingZoo
PettingZoo is a multi-agent version of Gymnasium with a number of implemented environments, i.e. multi-agent Atari environments. https://arxiv.org/abs/2009.14471
- StarCraft II Learning Environment:复杂的即时战略游戏,是测试MAS的标杆。PySC2 - StarCraft II Learning Environment - GitHub
- CARLA:自动驾驶仿真平台,包含多个交通参与者(车辆、行人)。https://carla.org/ https://github.com/carla-simulator/carla
3.6 分形理论和多智能体系统之间的关系
分形理论为多智能体系统提供了有价值的视角和工具,用于分析、理解和优化复杂的智能体行为和系统结构。它不仅帮助更好地理解系统的内在动态,还能启发新的算法设计和应用。
分形理论和多智能体系统之间的关系主要体现在以下几个方面:
-
模式识别与生成:分形理论可以用于描述自然界中复杂的自相似模式。在多智能体系统中,分形结构可以用于生成和识别复杂的模式,这对于环境建模和路径规划等任务有重要意义。例如,多智能体系统中的智能体可以使用分形生成的方法创建复杂的地图或场景,从而提高任务执行的有效性。
-
复杂系统建模:多智能体系统通常表现为复杂系统,具有非线性和不可预测的特性。分形理论提供了一种工具来分析和理解这种复杂性,通过分形维数等指标可以量化和描述系统的复杂程度。
-
自组织现象:多智能体系统中常常出现自组织行为,而分形是自组织现象的一种形式。通过分形理论,可以更好地理解多智能体系统中涌现的自组织结构和模式。
-
算法设计:在多智能体算法的设计中,分形结构可以被用来设计更加高效的算法。例如,在优化和搜索问题中,分形算法能够利用其自相似性质,提高计算的效率。
-
仿真与可视化:分形理论提供了一种视觉化工具,可以帮助研究人员和开发者以可视的方式分析和调试多智能体系统的行为和交互。
4 多智能体强化学习
根据智能体之间的合作与竞争关系,学习各智能体的策略,就是多智能体强化学习。多智能体问题的目标是整体收益最大化。多智能体强化学习的理论框架建立在博弈论的基础上,以纳什均衡为优化目标,其求解方法由单智能体强化学习算法发展而来。
可参考 【学习资源】一起来学习知识图谱和强化学习吧
表2 比较多智能体强化学习算法
| 算法名称 | 核心思想 | 优点 | 缺点 | 适用场景 |
| IA2C 独立A2C | 去中心化:每个智能体将自己视作单智能体,独立运行A2C算法,无视其他智能体。 | 实现简单,无需智能体间通信。 | 环境非平稳性,难以收敛;智能体之间是“零和”竞争思维。 | 智能体间互动简单或竞争性强的环境。 |
| MA-A2C 多智能体A2C | 中心化:使用一个中心化的Critic,在训练时获取所有智能体的信息来评估动作。 | 解决了环境非平稳问题,收敛性更好;智能体学会协作。 | 执行时需要中心化控制器,不适用于分布式部署。 | 需要紧密协作,且执行时可以接受中心控制的场景。 |
| IPPO 独立PPO | 去中心化:IA2C的PPO版本,每个智能体独立运行PPO。 | 实现简单,PPO算法更稳定。 | 同IA2C,存在环境非平稳性问题。 | 同IA2C,但希望训练更稳定时。 |
| MA-PPO 多智能体PPO | 中心化:MA-A2C的PPO版本,使用中心化的Critic。 | 同MA-A2C,且PPO的训练稳定性更好。 | 同MA-A2C,执行时需要中心化网络。 | 同MA-A2C,但希望训练更稳定时。 |
| DQN (Double Q) | 去中心化(基线):通常指每个智能体独立运行DQN算法。 | 实现极其简单。 | 环境非平稳性问题最严重,通常作为基线对比。 | 仅用于简单基线比较,实际应用较少。 |
| VDN | CTDE:假设团队总Q值是单个智能体Q值的线性求和。 | 实现CTDE,执行完全去中心化;结构简单。 | 价值函数表征能力弱,无法建模复杂的非线性协作关系。 | 智能体贡献相对独立、可加的协作任务。 |
| QMIX | CTDE:使用神经网络来混合单个Q值,以单调性约束保证策略一致性。 | 价值函数表征能力强,能学习复杂协作策略;执行效率高。 | 单调性约束可能限制价值函数的表达能力。 | 目前最流行的协作MARL算法之一,适用于大多数需要紧密协作的场景。 |
代码参考
https://github.com/marl-book/codebase
可参考https://github.com/marl-book/slides
5 参考书籍和代码
https://www.ibm.com/think/topics/multiagent-system
多智能体强化学习:基础与现代方法
(德)斯特凡诺·V· 阿尔布莱希特,(希)菲利波斯·克里斯蒂安诺斯,(德)卢卡斯·舍费尔
https://github.com/marl-book/codebase
PettingZoo: Gym for Multi-Agent Reinforcement Learning https://arxiv.org/abs/2009.14471 https://github.com/Farama-Foundation/PettingZoo
https://github.com/openai/gym
先总结一些内容,下次再续。