es开源小工具 -- 分析器功能
es开源小工具 -- 分析器功能
- 一. 前言
- 二. 分词器知识点
- 2.1 基本概念
- 2.2 分析器
- 三. 项目的功能介绍及es使用
- 四. 代码逻辑
- 4.1 后端代码
- 4.2 前端代码
前言
这是我在这个网站整理的笔记,有错误的地方请指出,关注我,接下来还会持续更新。作者:神的孩子都在歌唱
一. 前言
今天我的es工具又添加了一个功能,最近做项目一直在研究分词器,为了方便日常开发调用,就添加了一个分词器功能。效果如下
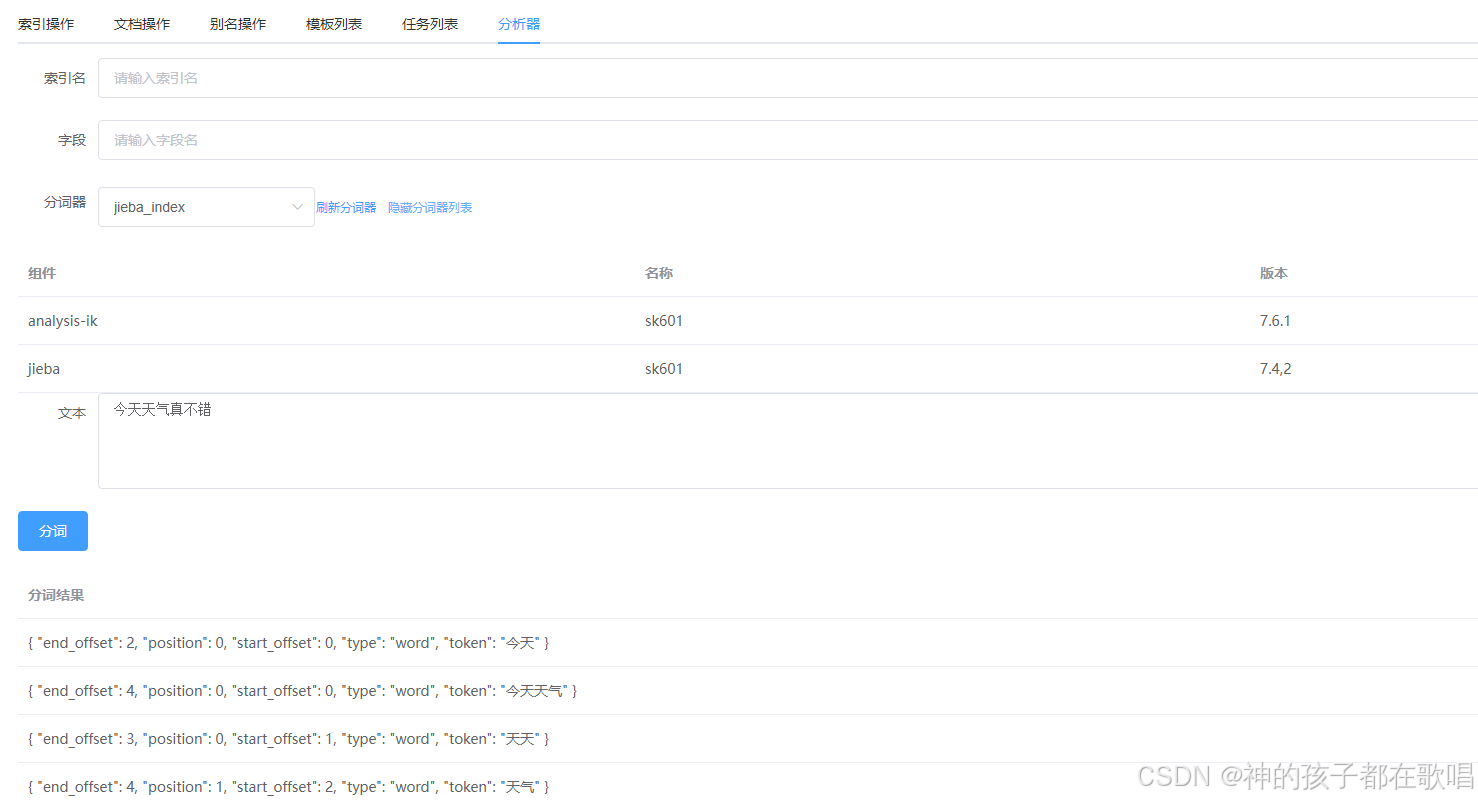
好了,接下来说说怎么实现的吧。
已开源:完整代码连接 github 对你有帮助记得点赞收藏
二. 分词器知识点
2.1 基本概念
- 分词器(Analyzer):Elasticsearch 用于将文本分解成词项(tokens)的组件,是全文搜索的核心。
- 分词器是 索引和查询分析链 的一部分,包括:
- 字符过滤器(char_filter):在分词前对原始文本做替换或去除特定字符。
- 分词器(tokenizer):将文本切分成一个个 token。
- 词项过滤器(token_filter):对 token 进行处理,如小写化、去停用词、同义词处理。
- Elasticsearch 中 Analyzer = CharFilter + Tokenizer + TokenFilter。
2.2 分析器
分析器有以下两类
- 索引时分析器(Index Analyzer):用于文档建立索引时分析文本。
- 查询时分析器(Search Analyzer):用于查询时对用户输入文本分析。
这两个可以不同,方便实现“索引精确,查询灵活”的策略。
内置标准分词器
standard:默认分词器,适合英文,按空格和标点切词。simple:按非字母字符切分文本,小写化处理。whitespace:仅按空格分词,不做小写化。keyword:不做任何分词,将整个文本作为一个 token(适合精确匹配)。
其他分词器
- IK 分词器(开源中文分词):
ik_smart:智能模式,分词较粗ik_max_word:最大化模式,尽可能切出所有词 - jieba 分词器(中文分词)
jieba_index:用于索引jieba_search:用于搜索,粒度更细 - 其他语言插件:如
mecab_ja(日文)、kuromoji(日文)、nori(韩文)等
三. 项目的功能介绍及es使用
- 查看已有的分词器列表
{{url}}/_cat/plugins?v

- 使用分词器分词
{{url}}/_analyze
{"analyzer": "jieba_index","text": "程序智"
}
下面是我使用结巴分词器查询出来的结果

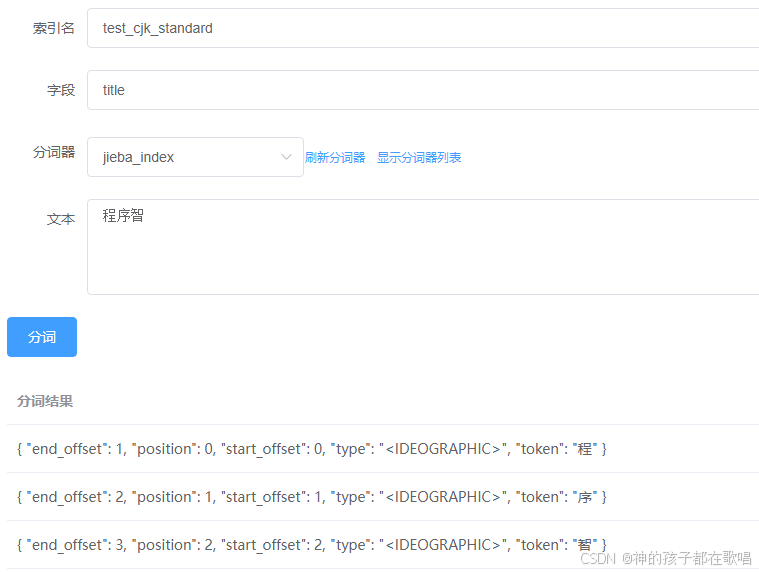
- 指定索引字段分词
指定字段和索引后,它不会在用你选择的分词器分词,而是使用title字段的分词器,在es中默认使用standard分词器
{{url}}/test_cjk_standard/_analyze
{"field": "title","text": "程序智"
}
四. 代码逻辑
完整代码连接 github 对你有帮助记得点赞收藏
4.1 后端代码
我是用的是8.11的依赖
<dependency><groupId>co.elastic.clients</groupId><artifactId>elasticsearch-java</artifactId><version>8.11.4</version></dependency>
主要代码
/*** 查看安装插件*/public Object pluginsInfo(ElasticsearchClient client) throws IOException {return FastJsonUtils.convertToHashMapList(client.cat().plugins().valueBody());}/*** 分词器分词*/public Object analyze(ElasticsearchClient client, String index, String analyzer, String text, String field) throws IOException {if (StringUtils.isBlank(index)) {return FastJsonUtils.convertToHashMapList(client.indices().analyze(a -> a.analyzer(analyzer).text(text)).tokens());}if (StringUtils.isNotBlank(field) && StringUtils.isNotBlank(index)) {return FastJsonUtils.convertToHashMapList(client.indices().analyze(a -> a.index(index).field(field).text(text)).tokens());}return FastJsonUtils.convertToHashMapList(client.indices().analyze(a -> a.index(index).analyzer(analyzer).text(text)).tokens());}
4.2 前端代码
<template><div><!-- 输入文本框和选择分词器 --><el-form :model="formData" label-width="80px"><div><el-form-item label="索引名"><el-input v-model="formData.indexName" placeholder="请输入索引名"></el-input></el-form-item><el-form-item label="字段"><el-input v-model="formData.filed" placeholder="请输入字段名"></el-input></el-form-item></div><el-form-item label="分词器"><el-select v-model="formData.analyzer" placeholder="请选择分词器"><el-option v-for="(item, index) in analyzersMap" :key="index" :label="item" :value="item"></el-option></el-select><el-button type="text" size="small" @click="fetchAnalyzerOperations" style="margin-top: 10px;">刷新分词器</el-button><el-button type="text" size="small" @click="toggleAnalyzerList" style="margin-top: 10px; margin-left: 10px;">{{ isAnalyzerListVisible ? '隐藏分词器列表' : '显示分词器列表' }}</el-button></el-form-item><!-- 分词器列表展示 --><el-table v-if="isAnalyzerListVisible && analyzers.length > 0" :data="analyzers" style="width: 100%; margin-top: 20px;"><el-table-column label="组件" prop="component"></el-table-column><el-table-column label="名称" prop="name"></el-table-column><el-table-column label="版本" prop="version"></el-table-column></el-table><el-form-item label="文本"><el-input type="textarea" v-model="formData.document" placeholder="请输入文本" rows="4"></el-input></el-form-item><el-button type="primary" @click="analyzeText">分词</el-button></el-form><!-- 分词结果展示 --><el-table :data="analysisResult" style="width: 100%" v-if="analysisResult.length > 0"><el-table-column label="分词结果"><template slot-scope="scope">{{ scope.row }}</template></el-table-column></el-table><!-- 错误信息展示 --><el-alert v-if="errorMessage" type="error" :title="errorMessage"></el-alert></div>
</template>
作者:神的孩子都在歌唱
本人博客:https://blog.csdn.net/weixin_46654114
转载说明:务必注明来源,附带本人博客连接。