【超分辨率专题】HYPIR:扩散模型先验与 GAN 对抗训练相结合的新型图像复原框架
HYPIR:扩散模型先验与 GAN 对抗训练相结合的新型图像复原框架(2025)
- 专题介绍
- 一、研究背景
- 二、方法细节
- 2.1 方案概述
- 2.2 深层解析
- 2.3 实现细节
- 三、实验论证
- 3.1 消融实验
- 3.2 对比实验
- 3.3 条件控制展示
- 四、总结和思考
本文将对《Harnessing diffusion-Yielded Score Prior for Image Restoration》这篇文章进行解读,该文提出了一种新的图像修复框架,其核心思想是“用预训练扩散模型初始化,再用对抗训练微调”。出自超分领域有名的团队,XPixelGroup。参考资料如下:
参考资料如下:
[1]. 论文地址
[2]. 代码地址
专题介绍
现在是数字化时代,图像与视频早已成为信息传递的关键载体。超分辨率(super resolution,SR)技术能够突破数据源的信息瓶颈,挖掘并增强低分辨率图像与视频的潜能,重塑更高品质的视觉内容,是底层视觉的核心研究方向之一。并且SR技术已有几十年的发展历程,方案也从最早的邻域插值迭代至现今的深度学习SR,但无论是经典算法还是AI算法,都在视觉应用领域内发挥着重要作用。
本专题旨在跟进和解读超分辨率技术的发展趋势,为读者分享有价值的超分辨率方法,欢迎一起探讨交流。
系列文章如下:
【1】SR+Codec Benchmark
【2】OSEDiff
【3】PiSA
【4】DLoRAL
【5】DOVE
一、研究背景
在图像复原\超分领域,其本质是从退化图像分布映射回自然图像分布,这需要同时解决 “去退化、生细节、保一致” 三大问题,而这也是长期存在一个 “不可能三角”,鱼与熊掌难以兼得。现有的方法可分为三类:
- MSE 类方法:依赖像素级损失,虽能保证结构一致性(如 PSNR/SSIM 指标优秀),但生成结果过度平滑,缺乏真实纹理细节;
- GAN 类方法:通过对抗训练贴近人类视觉感知,但训练不稳定、易发生模式崩溃,难以覆盖丰富的自然图像分布;
- 扩散类方法:借助大规模预训练模型实现高逼真度生成,但多步迭代采样导致训练慢、推理耗时,即便经过蒸馏压缩,仍难以兼顾效率与效果。
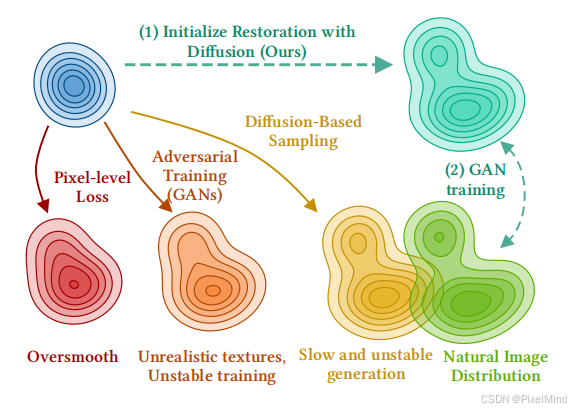
为打破这一僵局,HYPIR 提出了一个看似简单却极具创新性的思路:用预训练扩散模型做初始化,用 GAN 对抗训练做适配,既继承扩散模型的强生成先验,又保证了一步推理的快速性。同时,还支持文本引导修复和可调节的纹理丰富度。

上图中看整体清晰度和纹理表现还是不错的。不过,个人感觉脸部区域的边缘勾勒感较重,类似强锐化的效果。
其实方法很简洁,为何能有效呢?作者提出了两个关键洞察点,也是作者后续花大篇幅去论证的点。
- 图像复原相当于估计退化图像的得分,即退化图像对数密度的梯度,它沿着最快速的路线回到自然图像分布。而预训练好的扩散模型内化的先验已经与理想的复原算法非常匹配。
- 用预训练权重初始化,能够使模型对抗梯度保持较小且数值稳定,避免了训练崩溃,并促使模型更快收敛到高保真结果。
先前工作仍局限于采样过程和蒸馏方案。且普遍认为扩散优于GANs,单纯的对抗训练难有突破。而该论文给出了一个反直觉的结论是:在足够好的初始化下,GAN目标在收敛速度、训练稳定性、输出保真度和推理有效性方面优于扩散目标。
二、方法细节
2.1 方案概述
HYPIR 的 pipeline 简洁高效,核心分为三步(如图 3 所示):

步骤 1:扩散模型初始化,选用预训练的扩散模型(如 SD2、SDXL、Flux)作为基础,直接继承其编码器(Encoder)和解码器(Decoder)结构与参数。扩散模型在训练中已学习到自然图像的 “分数先验”(score prior),本质上是掌握了从含噪图像回归清晰图像的梯度方向。
步骤 2:退化预去除编码器微调,也就是单独微调编码器,使其具备 “退化预去除” 能力 —— 将退化图像映射到 latent 空间时,先初步消除模糊、噪声等退化,相当于减少latent空间的模式干扰,让后续恢复任务更简单。其损失约束如下,
LE=∥VD(VER(ldeg))−VD(VER(lGT))∥22\mathcal{L}_E = \left\| \mathcal{V}_D\left(\mathcal{V}_{ER}(l_{\text{deg}})\right) - \mathcal{V}_D\left(\mathcal{V}_{ER}(l_{\text{GT}})\right) \right\|_2^2LE=∥VD(VER(ldeg))−VD(VER(lGT))∥22
其中VD\mathcal{V}_DVD是固定的解码器,VER\mathcal{V}_{ER}VER是微调的编码器,ldegl_{\text{deg}}ldeg,lGTl_{\text{GT}}lGT是退化图像和GT图像。
步骤 3:对抗训练适配复原任务,用微调后的编码器和预训练解码器初始化恢复网络,仅对核心的 “恢复模块” 进行对抗训练。通过 LoRA 微调方式,结合 MSE 损失(提升保真度)、LPIPS 感知损失(提升感知度)和对抗损失(提升真实性),快速收敛到最优状态。
整个过程不依赖扩散损失、迭代采样或额外控制适配器,训练和推理均为单步流程。
这里原文中还有个小错误,第三章第一段,应该缺个表格?
2.2 深层解析
这部分作者想表达,HYPIR 的创新并非工程层面的简单拼接,而是有坚实的数学理论支撑。围绕了两个点展开探讨。
- 为什么预训练扩散模型天生就适合图像复原
- 为什么预训练扩散模型作为初始化能改善GAN范式训练。
📝问题一:扩散模型的学习目标与图像复原的目标是高度相似的
扩散模型通过 “前向加噪 - 反向去噪” 过程学习自然图像分布,其核心是对分数函数(Score Function) 的估计 —— 即图像分布对数概率的梯度,这恰好与图像恢复的目标高度一致。
-
前向扩散过程:将清晰图像x0∼pdata(x0)x_0 \sim p_{\text{data}}(x_0)x0∼pdata(x0)逐步加入噪声,生成含噪图像 xtx_txt,数学上通过随机微分方程(SDE)描述:dxt=−β(t)2xtdt+β(t)dwdx_t = -\frac{\beta(t)}{2}x_t dt + \sqrt{\beta(t)} dwdxt=−2β(t)xtdt+β(t)dw
其中 t∈[0,T]t \in [0,T]t∈[0,T] 为时间步,β(t)\beta(t)β(t)为noise schedule,www为标准布朗运动。当t=Tt=Tt=T时,xTx_TxT 近似纯噪声,完成 “从清晰到混乱” 的映射。
-
反向去噪过程:学习一个神经网络 sθ(xt,t)≈∇xtlog(pdata∗kσ(t))(xt)s_\theta(x_t, t) \approx \nabla_{x_t}\log(p_{data} * k_{\sigma(t)})(x_t)sθ(xt,t)≈∇xtlog(pdata∗kσ(t))(xt)(即分数函数),通过反向 SDE 将含噪图像恢复为清晰图像:dxt=[−β(t)2xt−β(t)∇xtlogpt(xt)]dt+β(t)dwˉdx_t = \left[-\frac{\beta(t)}{2}x_t - \beta(t)\nabla_{x_t}\log p_t(x_t)\right] dt + \sqrt{\beta(t)} d\bar{w}dxt=[−2β(t)xt−β(t)∇xtlogpt(xt)]dt+β(t)dwˉ
其中dwˉd\bar{w}dwˉ为反向时间的布朗运动,pt(xt)p_t(x_t)pt(xt) 为 xtx_txt 的分布。
对于图像恢复任务,给定退化图像 yyy,目标是采样 x0∼p(x0∣y)x_0 \sim p(x_0|y)x0∼p(x0∣y)(即从退化图像的后验分布中恢复清晰图像)。传统扩散方法需引入后验 SDE 并计算复杂的似然项 ∇xtlogpt(y∣xt)\nabla_{x_t}\log p_t(y|x_t)∇xtlogpt(y∣xt),而 HYPIR 提出简化近似:直接丢弃该似然项,利用预训练扩散模型的分数先验,通过 “中间时间注入观测值 + 无条件反向扩散” 实现一步恢复,
数学表达式为:x0^=1αˉ(t)(xt+(1−αˉ(t))Sθ(xt,t))≜Rθ(xt)\hat{x_0} = \frac{1}{\sqrt{\bar{\alpha}(t)}}\left(x_t + (1-\bar{\alpha}(t))\mathcal{S}_\theta(x_t, t)\right) \triangleq \mathcal{R}_\theta(x_t)x0^=αˉ(t)1(xt+(1−αˉ(t))Sθ(xt,t))≜Rθ(xt)
其中αˉ(t)\bar{\alpha}(t)αˉ(t) 为累积噪声系数,Rθ\mathcal{R}_\thetaRθ 即 HYPIR 的初始恢复模型,与扩散模型的分数函数网络 Sθ\mathcal{S}_\thetaSθ 共享结构。这一简化既保留了扩散模型的强生成能力,又避免了多步迭代的效率问题。
📝问题二:扩散初始化的理论优势:为何能拯救 GAN?
HYPIR 的关键突破在于证明了 “扩散模型初始化能让恢复网络分布极接近自然图像分布”,这一结论通过定理 4.1(Diffusion-to-Restoration Proximity,原文附件有证明过程) 定量验证:
假设预训练扩散模型 uθDiffu_{\theta_{Diff}}uθDiff的分数误差被εSC\varepsilon_{SC}εSC 约束,退化核kdegk_{deg}kdeg 与扩散噪声核 kσk_\sigmakσ 的差异 Δk=∥kdeg−kσ∥1≪1\Delta_k = \|k_{deg}-k_\sigma\|_1 \ll 1Δk=∥kdeg−kσ∥1≪1,则扩散初始化后的恢复模型分布pθDiff=RθDiff♯pyp_{\theta_{Diff}} = \mathcal{R}_{\theta_{Diff}} \sharp p_ypθDiff=RθDiff♯py(pyp_ypy 为退化图像的 latent 分布)与自然图像分布 pdatap_{data}pdata的 Wasserstein-2距离 距离满足:W2(pθDiff,pdata)≤C1εSC+C2Δk=:ϵ0W_2(p_{\theta_{Diff}}, p_{data}) \leq C_1\varepsilon_{SC} + C_2\Delta_k =: \epsilon_0W2(pθDiff,pdata)≤C1εSC+C2Δk=:ϵ0
其中C1、C2C_1、C_2C1、C2 仅依赖于网络的 Lipschitz 常数和图像维度。这一不等式表明,扩散初始化后的模型已处于 “接近自然图像分布” 的区域,为后续对抗训练奠定了优质基础。基于该定理,可推导出三大核心推论,直接解决 GAN 训练的痛点:
- 推论 1:初始梯度小,GAN 的生成器梯度与 W2W_2W2距离成正比,ϵ0\epsilon_0ϵ0 极小意味着初始梯度稳定,避免梯度爆炸、NaN 等问题;下图实验结果也很好地印证了上述推论。
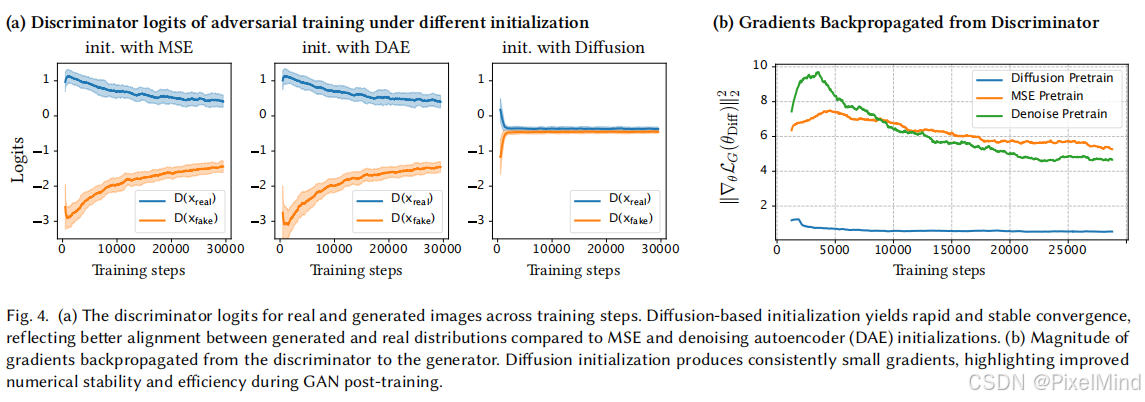
- 推论 2:模式覆盖完整,Proposition 4.3 证明,扩散初始化模型对任意图像区域的概率质量偏差不超过 22ϵ0\frac{\sqrt{2}}{2}\epsilon_022ϵ0,从根源上缓解 GAN 的模式崩溃,能生成多样化纹理;如下图,没有Diffusion初始化的GAN复原模式较为单一,无论动物、植物或景物都相对固定,而有了Diffusion初始化后就产生了更丰富的表征。

- 推论 3:收敛速度快,Proposition 4.4 指出,只需要对数级的梯度步即可收敛到目标精度。实验显示,HYPIR 训练 512×512 图像恢复任务仅需约 10k 步,而传统 GAN 需≥3×10⁵步。

总的来说,扩散初始化通过将模型置于一个“高起点”,带来了稳定性(小梯度)、多样性(模式覆盖)和高效性(快速收敛)三大优势,从而彻底改变了对抗训练在图像修复任务中的困境。
2.3 实现细节
理论说通了,怎么落地实践呢?
模型选型👉
在HYPIR框架中,所使用的预训练扩散模型从根本上决定了修复效果的基准。模型越大、能力越强,提供的“分数先验”就越准确,最终的修复质量也越高。该论文实践了四种规模的扩散模型作为先验:SD2(0.8B),SDXL(2.6B),SD3(8B),Flux(12B)。
得益于预训练大模型的发展,使得本方案实施起来更为高效。
条件控制👉
包括四个部分,文本prompts,纹理丰富度控制,潜空间注入随机噪声和随机采样。

文本prompts——
- 训练时:为训练集中的每张图像自动生成文本描述(使用LLaVA等多模态大模型)。将这些文本描述作为条件输入提供给模型。
- 推理时:同样使用LLaVA为待修复的测试图像自动生成描述,或由用户手动输入。模型会根据文本提示来恢复缺失的细节、填充不可恢复的区域或调整风格。
纹理丰富度控制——
不同的图像本身具有不同的纹理密度,强制所有图像输出相同密度的纹理会导致问题:平滑区域被过度纹理化,而细节丰富区域则表现不足。因此引入一个可控制的纹理丰富度参数。该参数基于图像拉普拉斯响应(Laplacian)的统计特性,拉普拉斯值波动越大,表明纹理越丰富。
- 训练时:真实图像的纹理丰富度统计值作为条件输入,指导模型为不同图像生成合适的纹理量。
- 推理时:用户可以通过滑动条等方式动态调整此参数,控制输出图像的整体纹理锐利度和细节量。
保真度-生成性权衡——
对于严重退化的图像,严格遵循模糊的输入信号(高保真度)可能会产生伪影。而允许模型有一定的“创造性”(高生成性)则可以合成更逼真的纹理,但可能偏离原始输入。
在编码器得到的潜在表示 y中注入不同强度的随机噪声。噪声越大,对原始输入的依赖越弱,模型的“想象力”就越强。
在推理时,用户可以通过控制噪声注入的强度,来找到一个视觉质量最佳的平衡点。例如,处理一张布满网格压缩伪影的图片时,增加噪声(提高生成性)可以鼓励模型忽略网格,生成平滑的纹理。
随机采样——
一张退化图像可能对应多个合理的修复结果。为了提供多样性,HYPIR利用了“保真度-生成性权衡”中引入的噪声。通过改变注入噪声的随机种子,可以对同一张输入图像生成多种不同的修复结果。这为用户提供了选择空间,特别是当第一次生成的结果在某些局部不令人满意时。随着噪声尺度增大,采样空间也会变大。
HYPIR的条件控制能力不是后期添加的模块,而是其核心架构(继承扩散模型U-Net)的自然延伸。这使其成为一个功能极其丰富且用户友好的修复工具。
模型训练👉
数据集:约2000万张高质量图像块(patches),并配有文本描述。额外7万张人脸图像,可能用于增强对人脸细节的修复能力。采用与Real-ESRGAN相同的复杂退化管道来生成训练用的退化-清晰图像对,以模拟真实世界的复杂退化。
判别器:使用预训练的ConvNeXt模型作为骨干网络进行初始化。这是因为ConvNeXt能处理任意尺寸的输入,非常适合高分辨率训练,并能提取细粒度的图像特征来有效指导生成器。论文图10的对比实验表明,ConvNeXt作为判别器骨干优于DINO、CLIP等。
训练策略:
-
第一阶段:批量大小(Batch Size)为384,生成器和判别器的学习率均为 1×10−51×10−51×10−51×10−51×10−51×10−5,训练1万步。
-
第二阶段:通过梯度累积将有效批量大小提升至1536,学习率降至 5×10−65×10−65×10−65×10−65×10−65×10−6,再训练1万步。
-
EMA:使用指数移动平均,衰减因子为0.999,测试时使用EMA权重。
三、实验论证
实验这块分为三个部分:消融研究,对比实验和条件控制展示。
3.1 消融实验
以下实验均以SD2模型作为预训练模型。实验内容较多,这里大概总结一下。
🔬与其他初始化和训练方法比较
有意思的是BigGAN直接跑飞了,非常抽象。该实验证明了扩散初始化是提升质量的关键。

🔬判别器设计
探讨什么样的判别器能最好地指导生成器,对比了DINO, CLIP, 扩散U-Net, ConvNeXt。ConvNeXt胜出,它能处理原始分辨率图像,保留完整细节,因此其指导下的修复结果纹理最丰富、最准确。

从图中看,个人感觉CLIP也还不错。
🔬LoRA训练秩大小
比较不同LoRA秩(如64, 96, 128, 256, 1024)下的修复效果。增加LoRA秩(即增加可训练参数量)能在一定程度上提升性能,说明后续的对抗训练确实需要一定的模型容量来学习改进。但过高的秩会出现收益递减,因此需要在性能和计算成本间权衡。论文默认选择64是一个均衡点。

🔬退化预去除
没有退化预去除时,编码器可能会误解退化的图像内容,导致修复结果出现明显伪影和质量下降。而加入该策略后,修复结果的清晰度和准确性得到显著提升。

🔬 扩散先验
使用SD2, SDXL, SD3, Flux等不同模型初始化。模型越大,效果越好。更大的扩散模型能提供更准确的分数函数近似,并具有更强的捕捉复杂图像结构的能力。这证明了HYPIR框架的可扩展性:随着基础扩散模型的进步,其性能也能“水涨船高”。

3.2 对比实验
定性结果
-
合成数据:基于SD2的HYPIR生成的纹理已优于对比方法;基于Flux的HYPIR进一步提升了质量,恢复了异常清晰的结构细节(如大蒜和玻璃瓶的细微结构)。

-
真实世界图像:HYPIR在恢复面部特征、文本内容、建筑结构等复杂细节方面表现出色。

-
历史老照片:即使输入是严重退化、低分辨率的百年老照片,HYPIR也能有效将其重建为4K甚至6K的高清图像,保持惊人的细节保真度和结构完整性。

定量评估
由于感知质量难以用客观指标完全捕捉,论文采用了主客观相结合的评价。
-
用户研究(核心评价):
招募100名有图像处理经验的受试者,对修复结果进行0-10分的感知质量评分。HYPIR在两个评估轮次中均获得了最高的平均感知分数。并且,低分情况很少,证明了其效果的稳健性和可靠性。

-
客观指标(参考性质):
在DIV2K和RealPhoto60数据集上报告了多种指标(PSNR, SSIM, LPIPS, NIQE, MUSIQ等)。HYPIR在多数指标上名列前茅。但论文反复强调,这些指标可能被人为优化而并不完全代表视觉质量,用户研究才是更可靠的证据。

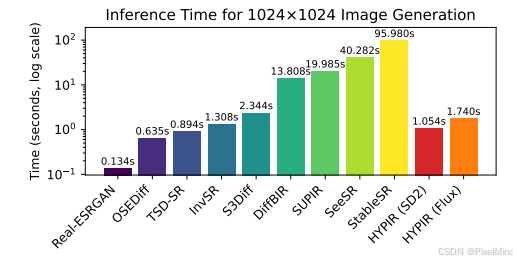
运行效率- 多步扩散模型:由于迭代采样,推理时间极长(如处理1024x1024图像需数秒到数十秒)。
- 单步模型:推理快,但往往以牺牲质量为代价。
- HYPIR:取得了突破性平衡。即使使用巨大的Flux模型(120亿参数),其推理速度也与其它单步方法相当,但生成的视觉质量却远高于它们。
3.3 条件控制展示
-
文本提示控制:
-
修复文本:展示如何通过输入正确的标语提示(如“Vote against Wilson…”),引导模型准确修复模糊的标语牌上的文字。没有提示则会产生错误字符。

-
消除歧义:对于像素极少、高度模糊的物体,通过不同提示(如“cows and sheep” vs “rocks and stones”)可以生成完全不同的、符合语义的合理内容。

-
-
纹理丰富度控制:
通过滑动条调节参数,可以直观地看到输出图像从“纹理平滑柔和”到“纹理锐利细节丰富”的连续变化。

-
保真度-生成性权衡:
示例显示,对于有严重压缩伪影或模糊的图像,提高“生成性”(增加噪声)可以有效地消除网格伪影或合成出合理的纹理,从而获得更好的视觉观感。

-
随机采样:
通过改变随机种子,为同一张退化图像生成多种不同的修复结果,提供了多样化的选择。

不得不说,整个实验部分还是非常丰富的。里面也有一些不错的点值得借鉴和参考
四、总结和思考
HYPIR 以 “扩散先验初始化 + GAN 对抗微调” 的极简思路,实现了高质量的图像复原效果。
- 数学原理层面,通过简化扩散模型的后验计算实现一步恢复,同时以定理形式证明了扩散初始化的优势
- 工程实现层面,通过 LoRA 微调、退化预去除等设计,兼顾了性能与效率。
最终,HYPIR 既继承了扩散模型的高逼真度与强可控性,且推理也十分高效。
其实现在单步扩散的方案最本质的一点,就是利用了预训练大模型的强大先验。在此基础上,才延伸出了各类方法范式。
感谢阅读,欢迎留言或私信,一起探讨和交流。
如果对你有帮助的话,也希望可以给博主点一个关注,感谢。