长沙理工《人工智能基础A》实验(上机)报告实验三 电商数据可视化/图像处理
作业描述:
一、下载所有作业文件并打开研究一下作业内容
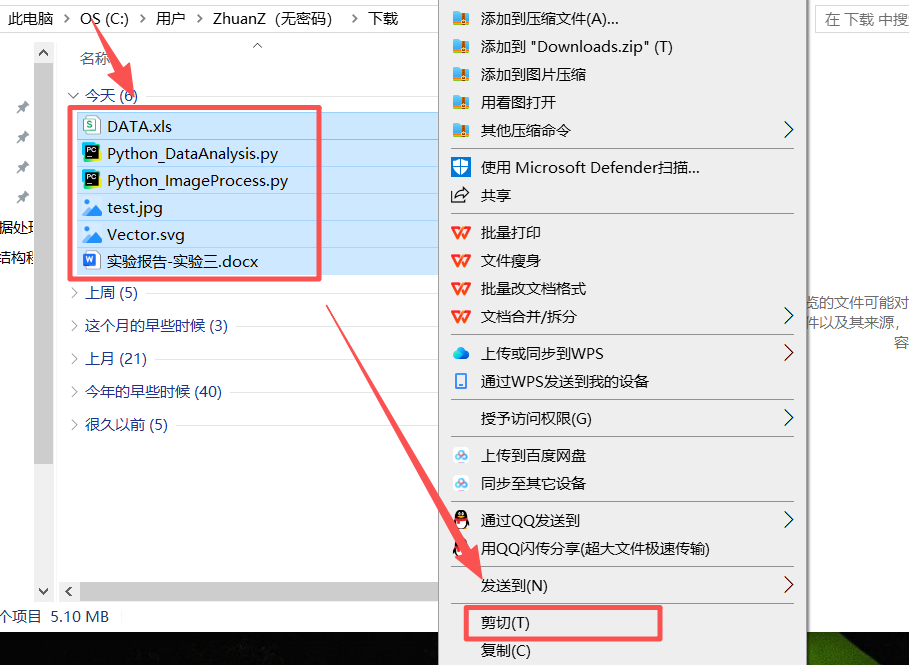
图 1 找到下载好的文件对应的目录下(也称文件夹下面),进入之后长按鼠标左键拖动鼠标选中刚刚下载好的所有文件之后右键鼠标,点击剪切(T),然后前往桌面新建一个文件夹用于存放作业文件
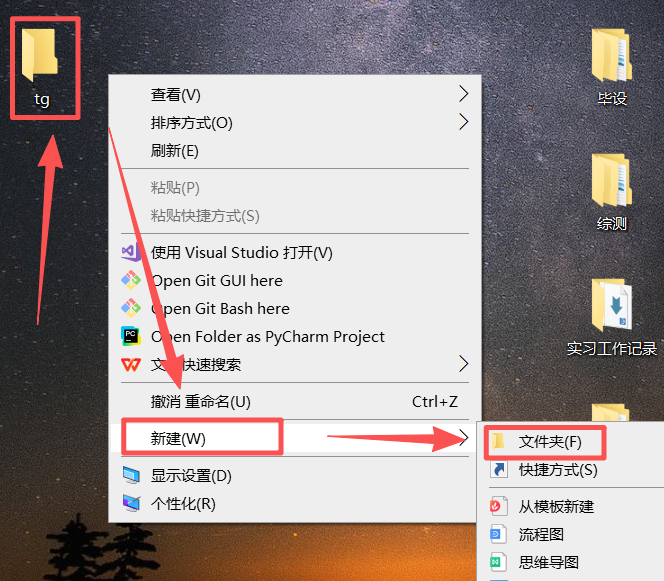
图 2 新建好的文件夹在桌面上,一开始是这种空文件夹的状态(文件夹起名最好全英文,这样可以避免电脑编码错误导致报错)担心有些同学不知道如何新建文件夹,这里说一下,鼠标左键点击空白位置,右键鼠标之后出现如图所示选项,依次选中就可以新建了
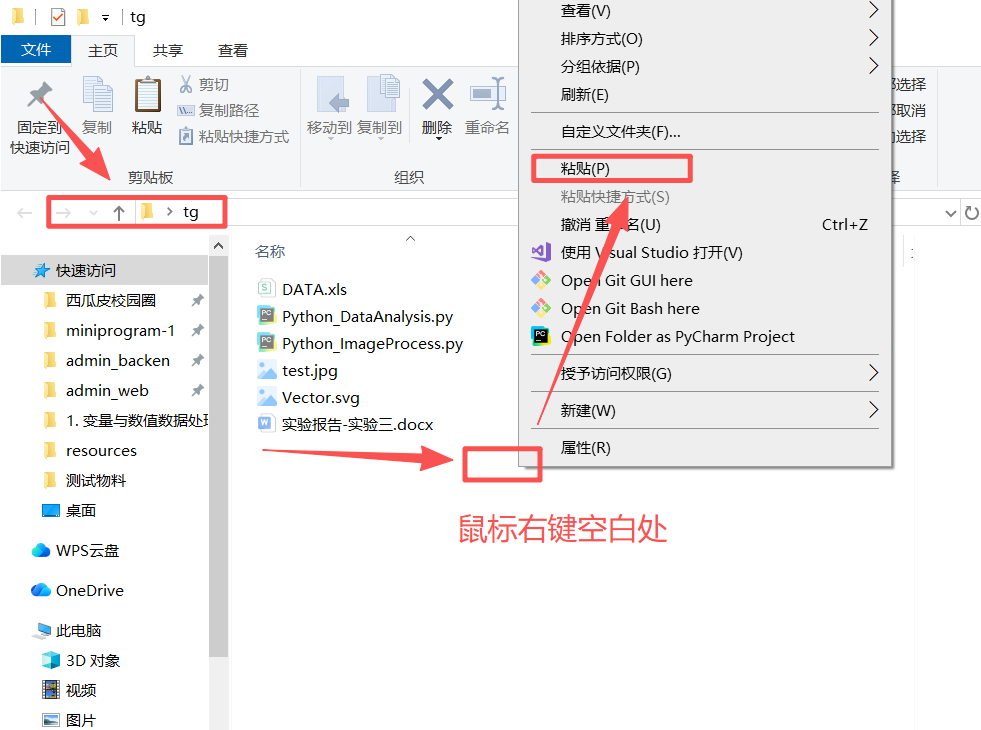
图 3 双击进入刚刚创建好的名为tg的文件夹(目录)下面,发现地址已经在这个文件夹下面了,然后鼠标右键空白处,滑动鼠标到粘贴按钮,鼠标左键点击粘贴按钮粘贴图1剪切好的多个文件,成功之后返回桌面可以发现效果如图4所示

图 4 装好文件的目录(也称文件夹)外观就像这样,这样就完成了初步准备工作,然后就可以点击进入各个可查看的文档了解作业内容了
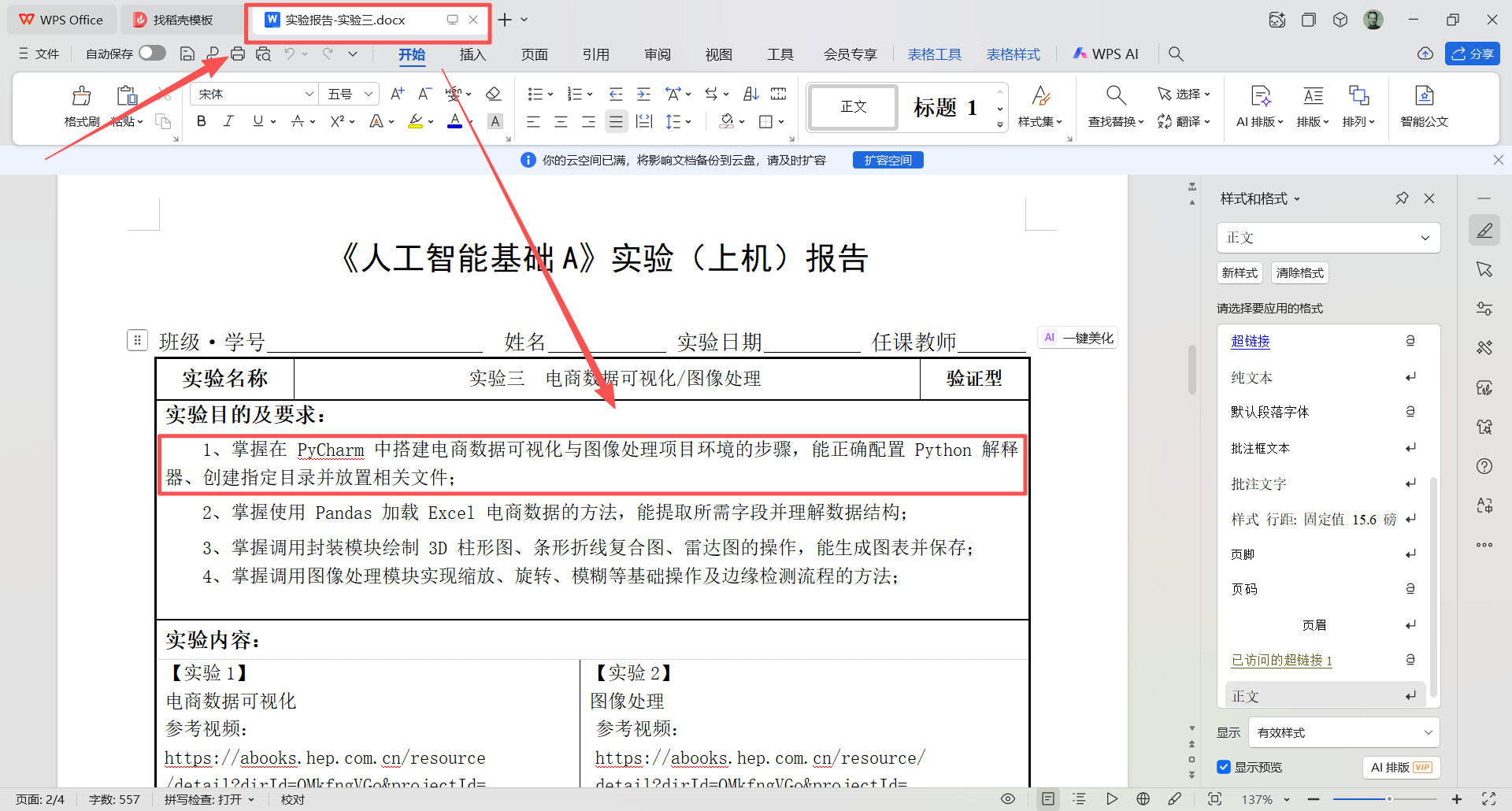
图 5 在 图 3 所示的目录(也称文件夹)名为 tg 的目录(也称文件夹)下面双击打开名为 实验报告-实验三.docx 的文件,看到如图所示内容,接下来分析需求,首先他要求安装pycharm,并配置Python 解释器(配置python解释器的意思是说,python解释器和pycharm是两个东西,pycharm是一个集成开发工具,这个开发工具本身并不具备运行python代码的能力,底层仍然是依赖python解释器运行代码,所以要先安装好python解释器,然后把python解释器的安装位置告诉pycharm这样pycharm才能调用python解释器执行程序)所以下一步的工作是下载安装pycharm
二、下载安装PyCharm
Windows系统上的pycharm下载链接地址:
https://www.jetbrains.com.cn/en-us/pycharm/download/download-thanks.html?platform=windows
Macos系统上的pycharm下载链接地址:https://www.jetbrains.com.cn/en-us/pycharm/download/download-thanks.html?platform=macM1
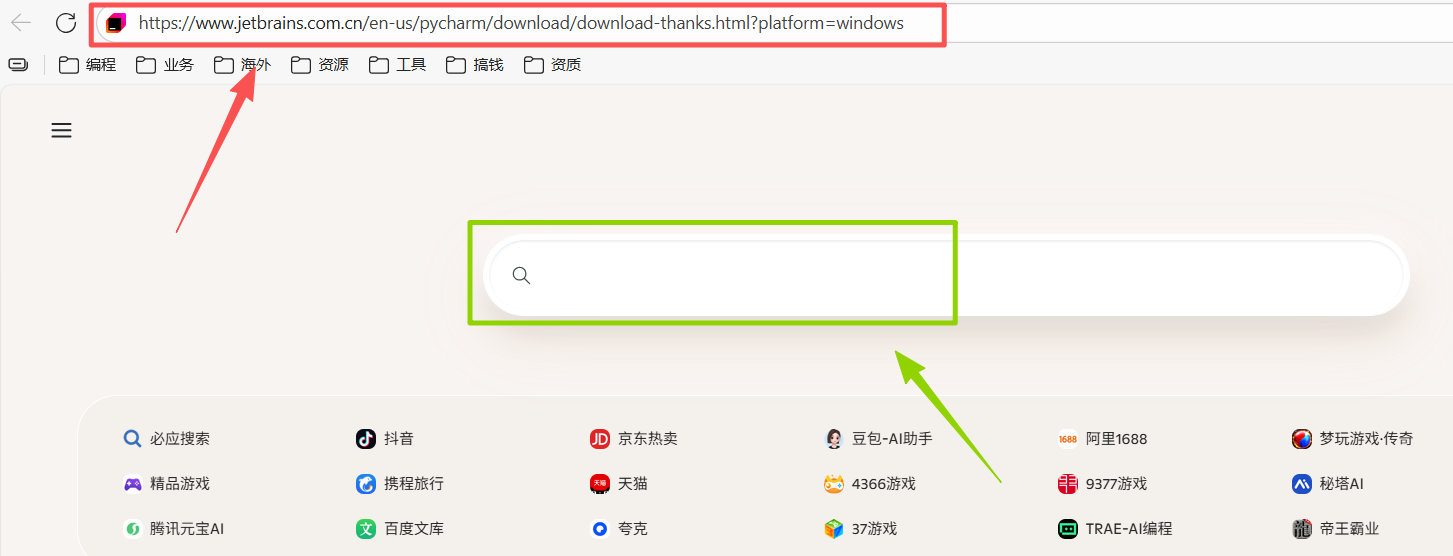
图 6 复制或者双击跳转访问我提供的链接,自己是windows系统就复制Windows的链接,反之复制Macos系统的链接,在一个导航栏(红色是导航栏绿色是搜索栏这两个不一样,要分清楚),在里面输入链接,然后点击回车键(也就是确认键,上面写的是enter,有进入,确认等意思),然后浏览器就会访问页面,并自动下载pycahrm
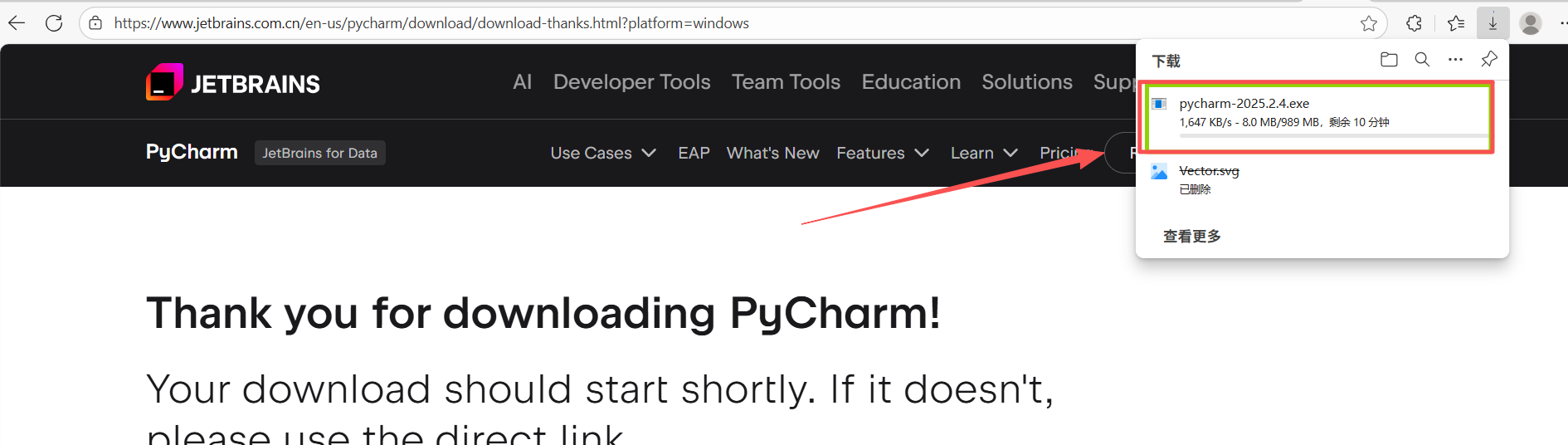
图 7 如图所示,下载差不多持续 600秒的时间,如果低于这个速度建议办个新的流量卡(哈哈,无情嘲笑)
图 8 本程序猿电脑一直都配置了pycharm,为了大家看得直观,我先卸载再重装(虽然麻烦但是比较管用,哈哈)
图 9 下载好以后,找到下载位置双击鼠标左键打开运行这个安装文件
图 10 双击之后系统会提示你是否运行该文件对系统进行操作,点击是,因为刚刚页面无法截图,所以没有截图,遇到这个弹窗点击下一步这个按钮
图 11 这里选择默认的安装位置即可(不需要做任何操作),点击下一步按钮即可
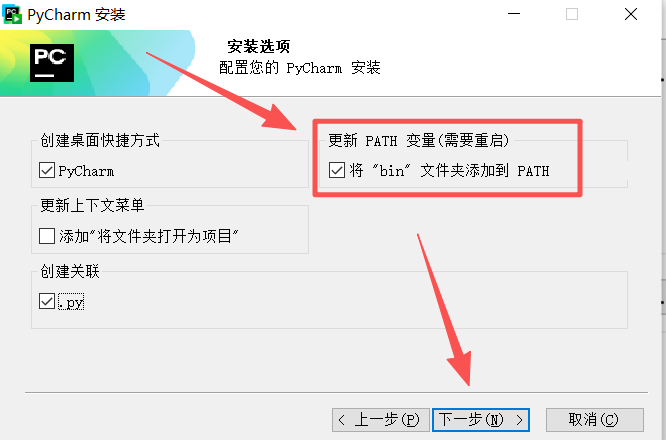
图 12 按照如图所示勾选,最重要的是勾选红色方框选中的这个按钮,然后点击下一步按钮
图 13 什么都不做,点击安装按钮
图 14 静静等待安装到安装完毕
图 15 勾选运行pycharm,然后点击完成按钮
图 16 遇到这个弹窗点击允许访问按钮,通过防火墙请求,然后就属于完成了网络授权和初步安装
三、配置python解释器给pycharm编辑器
参考我的实验2这篇文章的步骤二、三、四,完成python解释器的安装部署
长沙理工《人工智能基础A》实验(上机)报告实验二 Python编程基础实践2
这里给大家简单解释一下,python解释器和pycharm编辑器(又称为pycharm集成开发工具)的区别,1. python解释器是一个底层的python代码翻译工具,可以把你写好的python项目运行成可见的程序应用而pycharm则是一款集成开发工具,它是方便程序员编写代码的一款编辑器软件,使用它可以方便的编写代码;2. 为什么要进行配置环节呢,因为电脑其实很蠢,只有我们告诉pycharm我们的python解释器部署安装在哪,它才能找到它并使用它,不然pycharm就只是个花架子
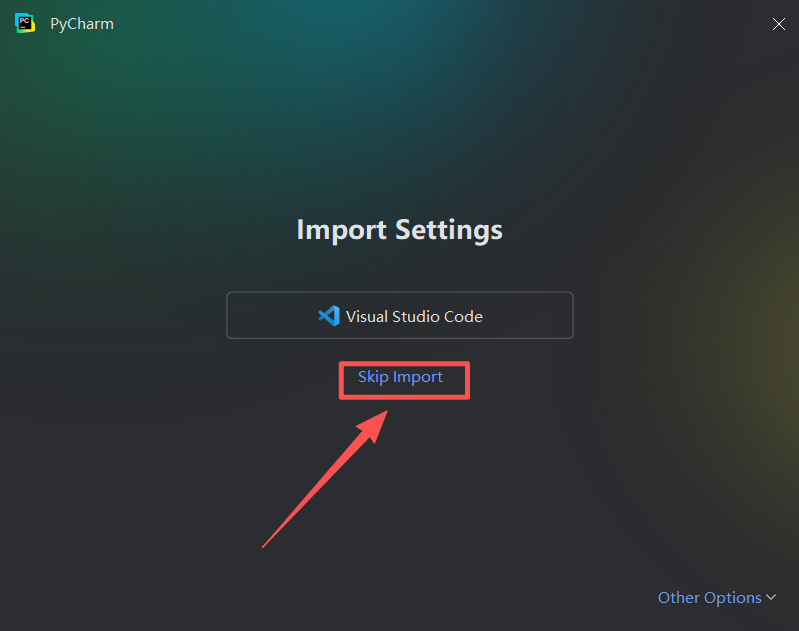
图 17 遇到这个页面直接点击 skip import 跳过引入(导入)的意思,因为我的电脑原先安装了别的集成开发工具,所以它识别到以后想要直接借用原有的设置跳过手动设置这一环节,我这里选择跳过导入
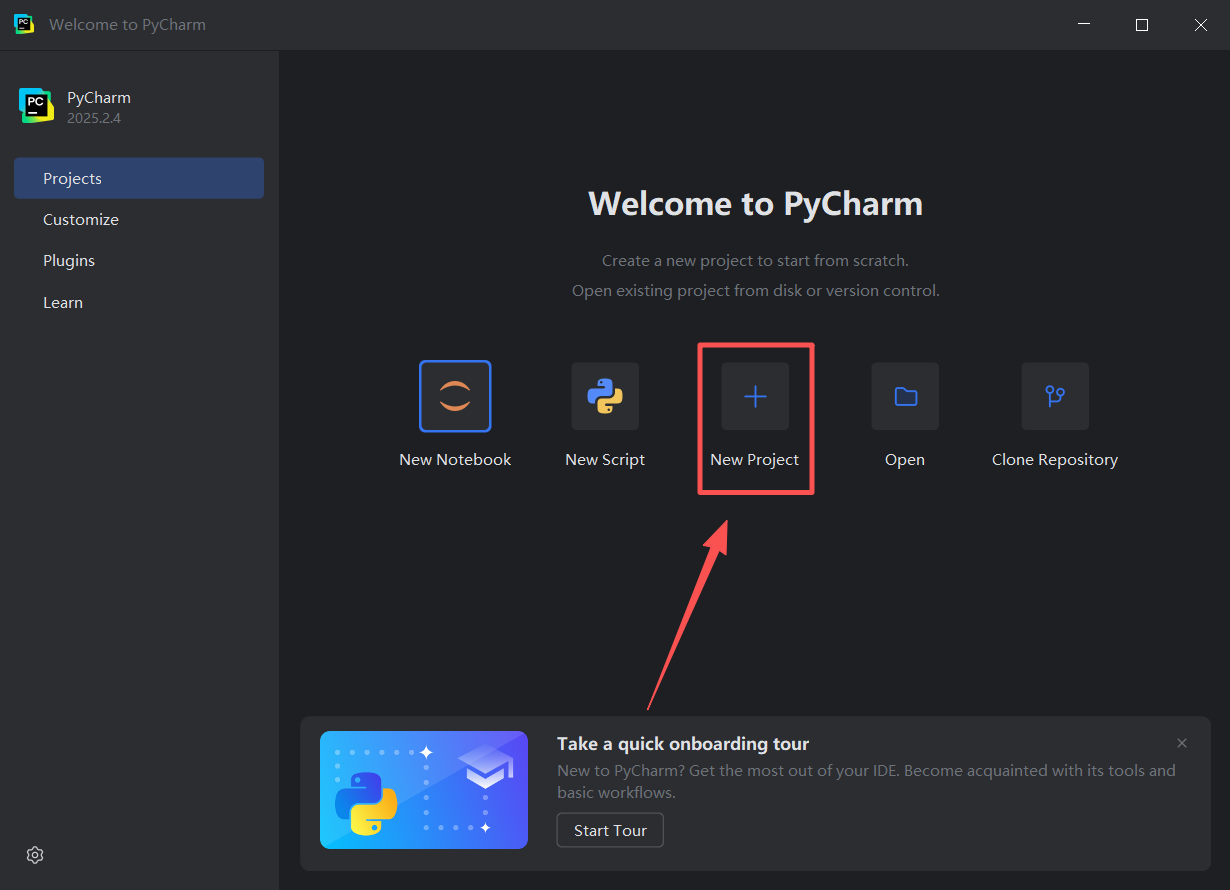
图 18 点击这个 new project 进入下一个界面
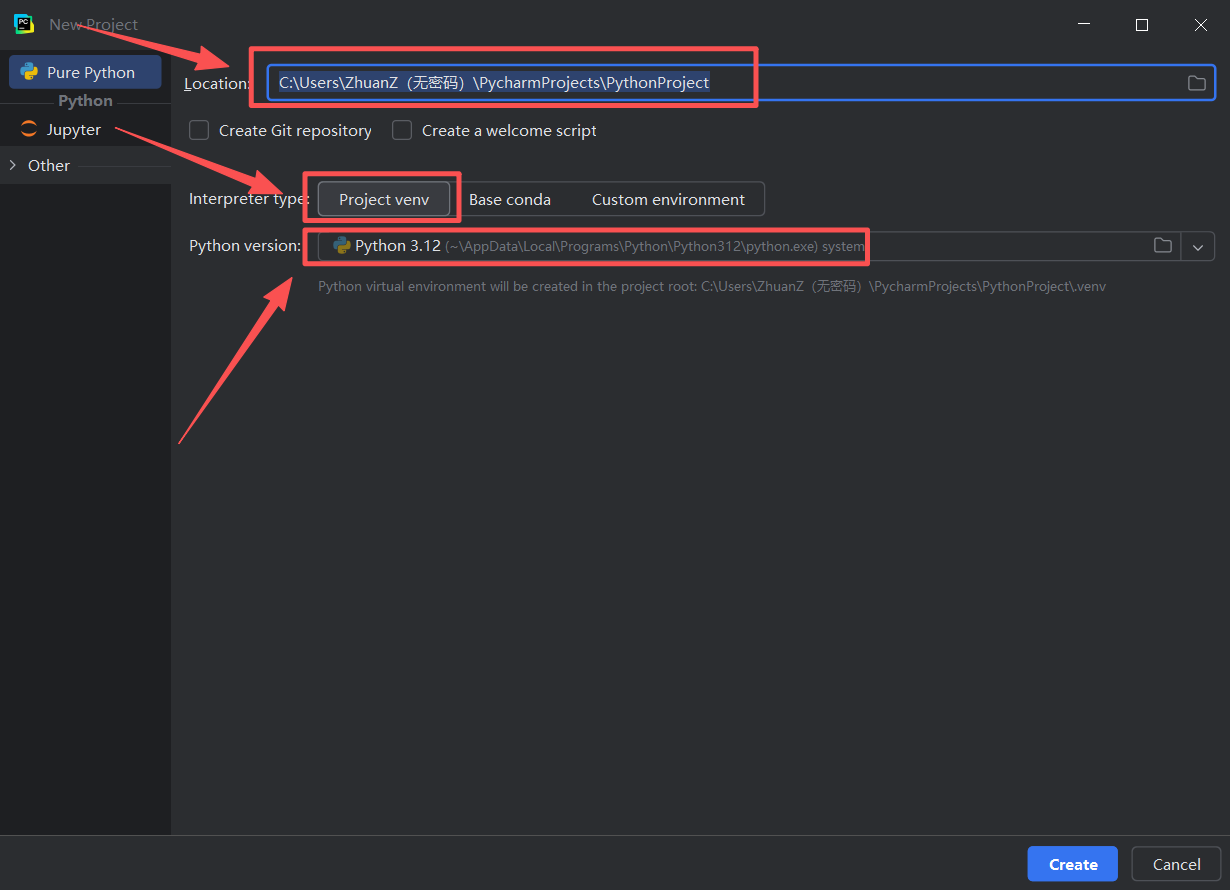
图 19 给大家介绍一下这三个方框代表的意思,从上到下依次是:1. 项目所在地址,这里待会要切换成我们刚刚创建的tg目录(也称文件夹)的地址(也称路径)2. 编译解释类型,当前无需太多了解,选择这个Project venv,它的意思是项目虚拟环境,venv是虚拟环境的缩写 3. python 版本的意思,是这里一般是你按照我在长沙理工《人工智能基础A》实验(上机)报告实验二 Python编程基础实践2
一文中,步骤二、三、四,完成配置好之后会自动选择的,如果没有完成配置就无法正确选择,所以一定要完成这篇文章的二三四步骤,(搞不定可以联系我,虽然不一定回复,哈哈)
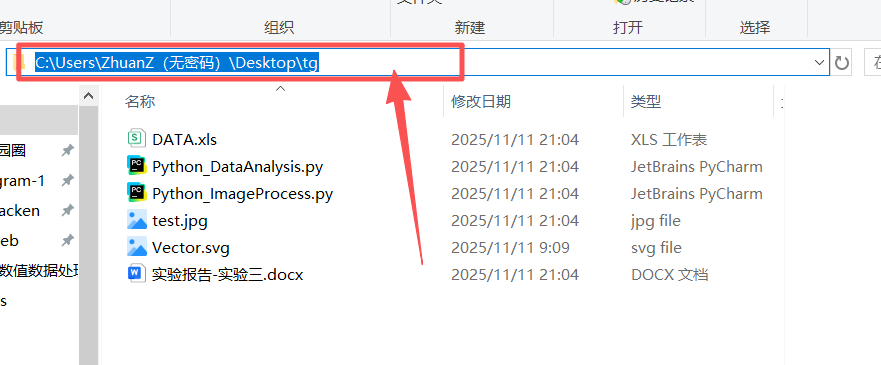
图 20 找到本文步骤一创建好的tg目录(也称文件夹),点击图中箭头所示的空白框区域,变成蓝色选中状态,手指同时按下键盘上的 ctrl和x这两个按钮,发现成功剪切(这是剪切的快捷键)了这个路径地址
图 21 然后找到之前的pycharm页面,在地址栏里面同时按下ctrl和v键,这是粘贴的快捷键(这样就完成了粘贴路径到对应位置),然后点击右下角蓝色create创建的意思
图 22 这个时候出现弹窗,意思就是,目录非空(因为这个目录【文件夹】下面存放了我们的文件,目录不为空,所以系统提示我们要怎么做,是创建项目还是打开这个项目),这里点击创建项目,因为pycharm的功能其实就是运行的时候在一个目录下面创建一个标记,拥有这个标记的目录会被pycharm识别为一个项目,现在这个项目并没有创建pycharm标记,所以点击创建按钮是可行的
图 23 进入这个页面,发现 框选的 .venv这个目录颜色特殊,下方的.py后缀的文件也有python的蟒蛇标志,说明配置成功,系统已经正常的完成了pycharm和python的建交
四、运行老师布置的任务
图 24 鼠标左键双击这个Python_DataAnalysis.py文件,pycharm会自动打开它,展示在右边
图 25 点击这个播放按钮,这是运行程序的意思
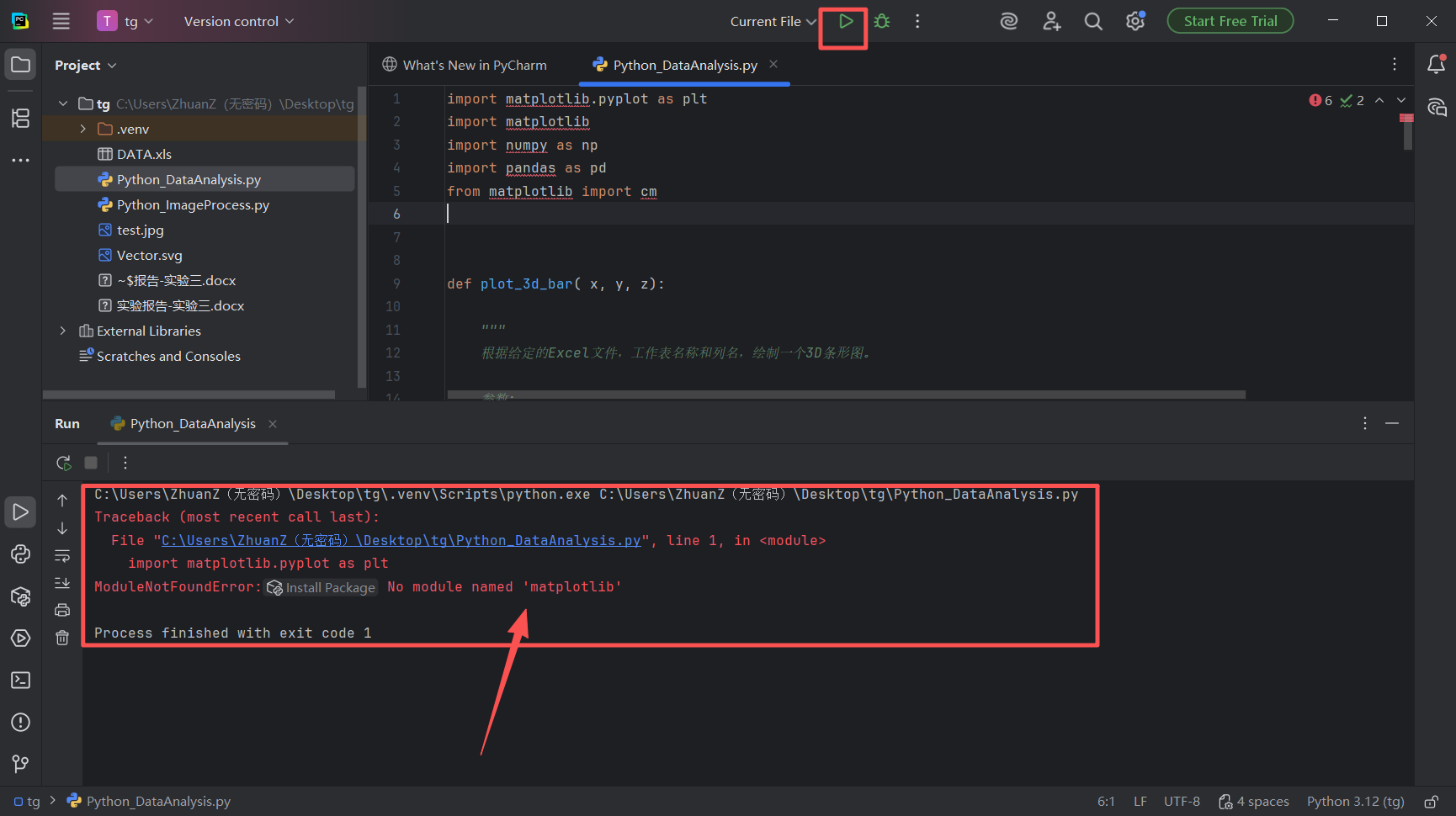
图 26 控制台报错输出红色提示 No module named 'matplotlib'
图 27 点击左下角这个按钮,这个按钮的名字叫做终端按钮(由一个箭头和下划线组成)
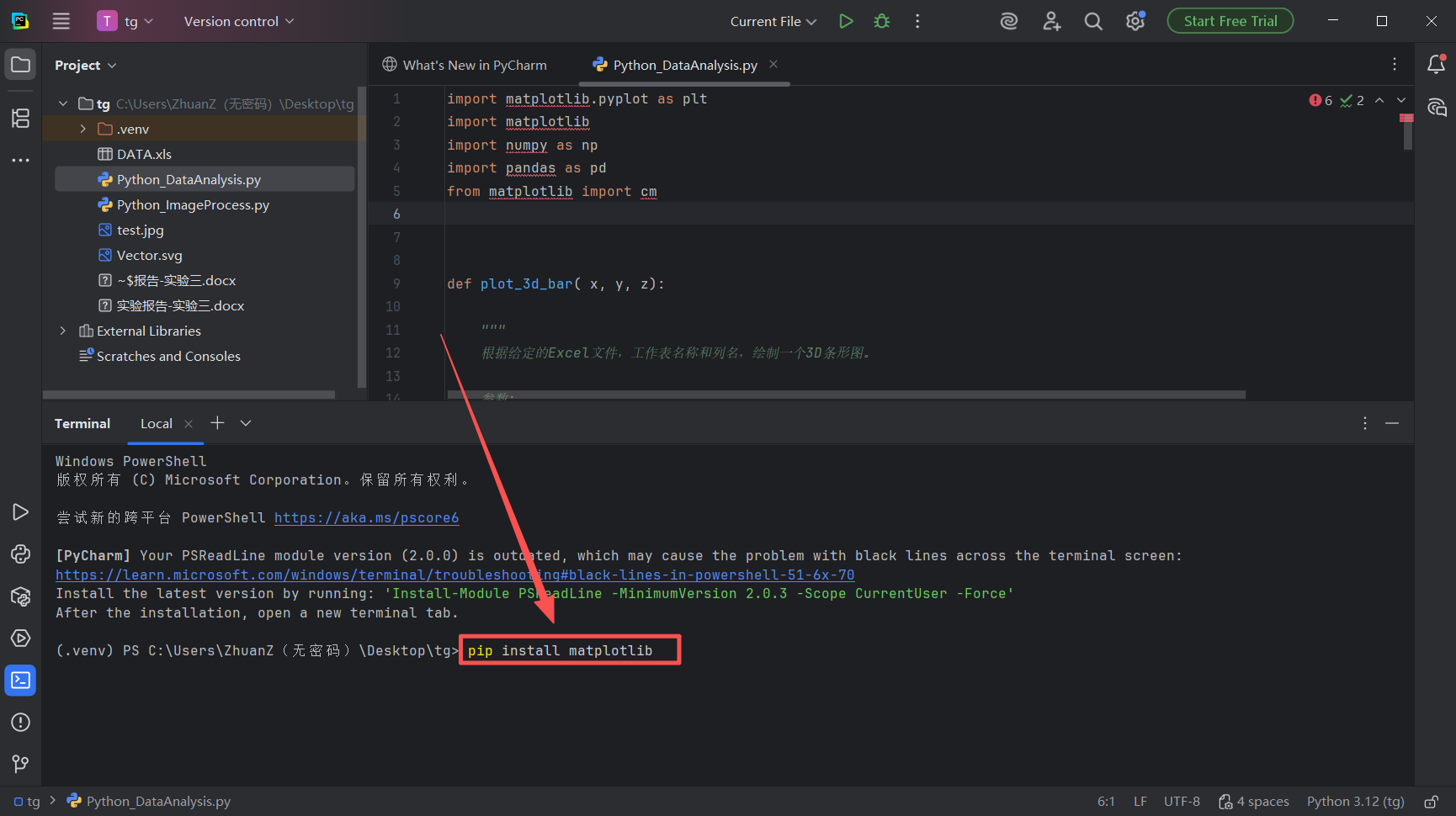
图 28 在图中所示区域,输入代码:pip install matplotlib,然后点击回车(也就是enter键)等待代码运行,这句代码意思是使用名为pip的python工具在python官方库下载一个名为matplotlib的绘图工具包
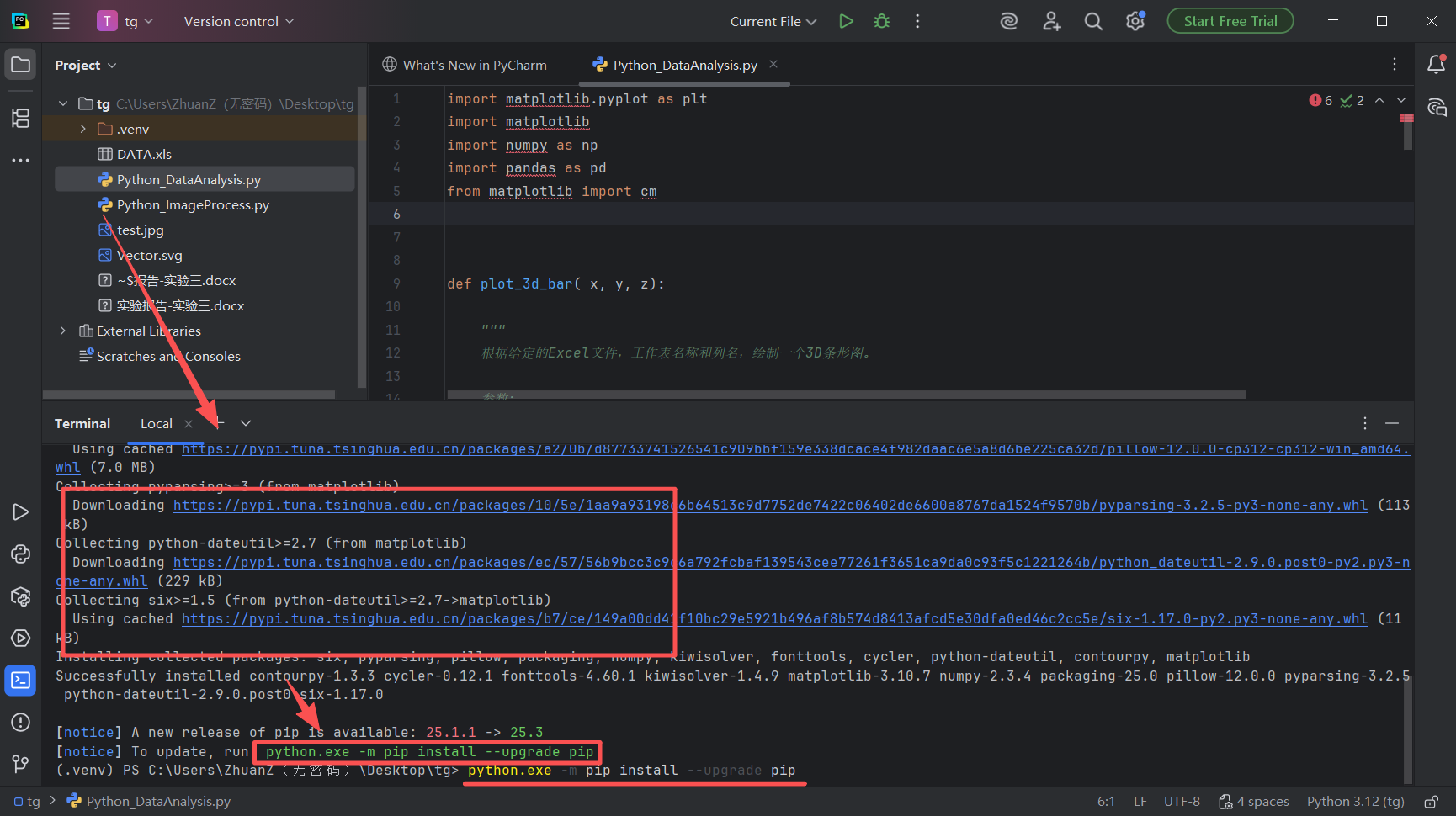
图 29 发现果然在下载一大片东西,报错提示请输入运行python.exe -m pip install --upgrade pip
这个意思是说:当前的pip版本不是最新的,建议你更新到最新pip,我们直接复制这个命令输入到下面画红线的位置,粘贴,然后回车,这样的话就会继续升级pip工具
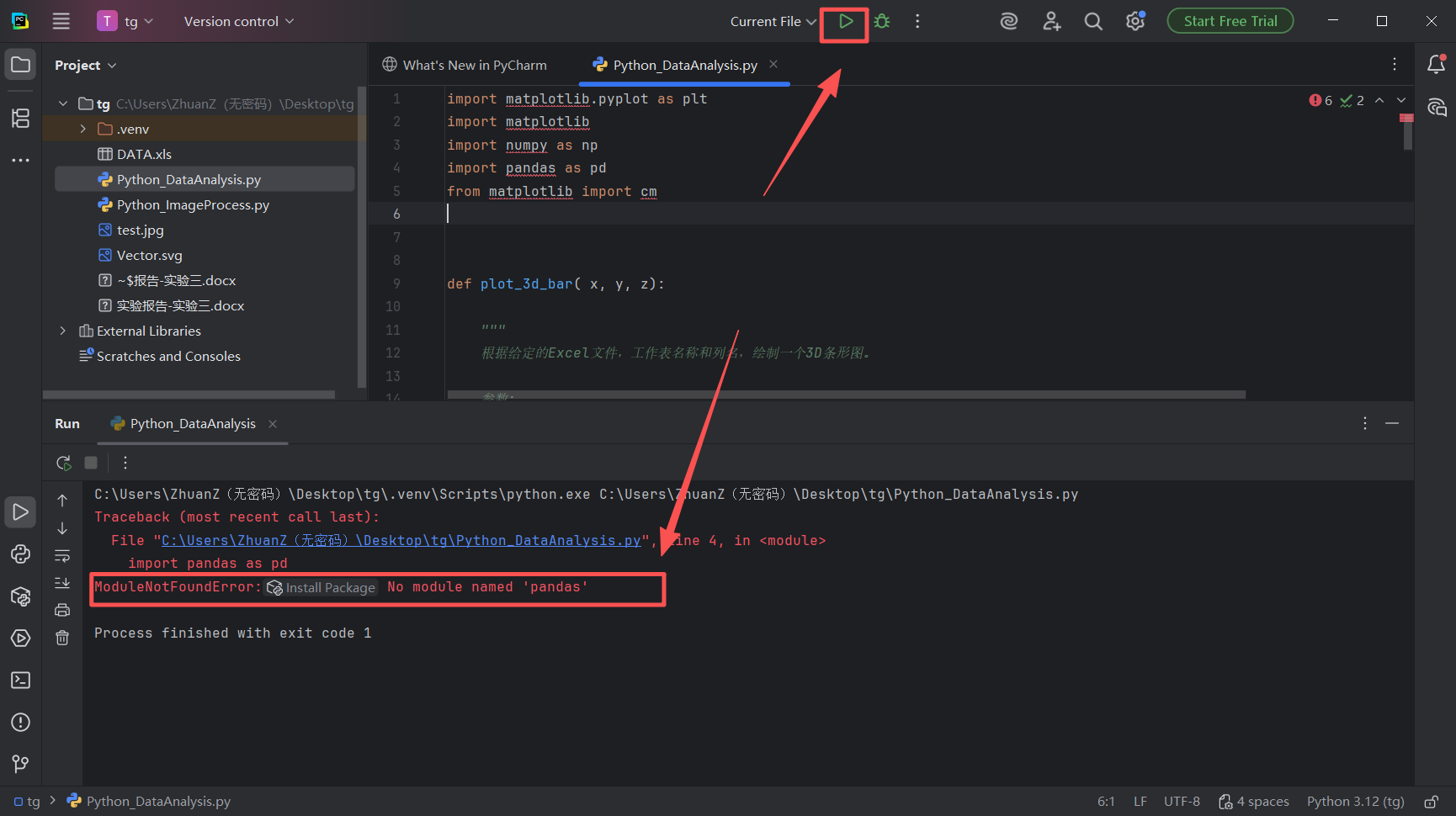
图 30 现在点击运行按钮,项目仍然报错 No module named 'pandas',我们重复前一个步骤,前往终端窗口输入pip install pandas,并按下回车键等待下载安装pandas包(不得不说,pycharm设计的非常美观,安装过程的数据流让我觉得赏心悦目)
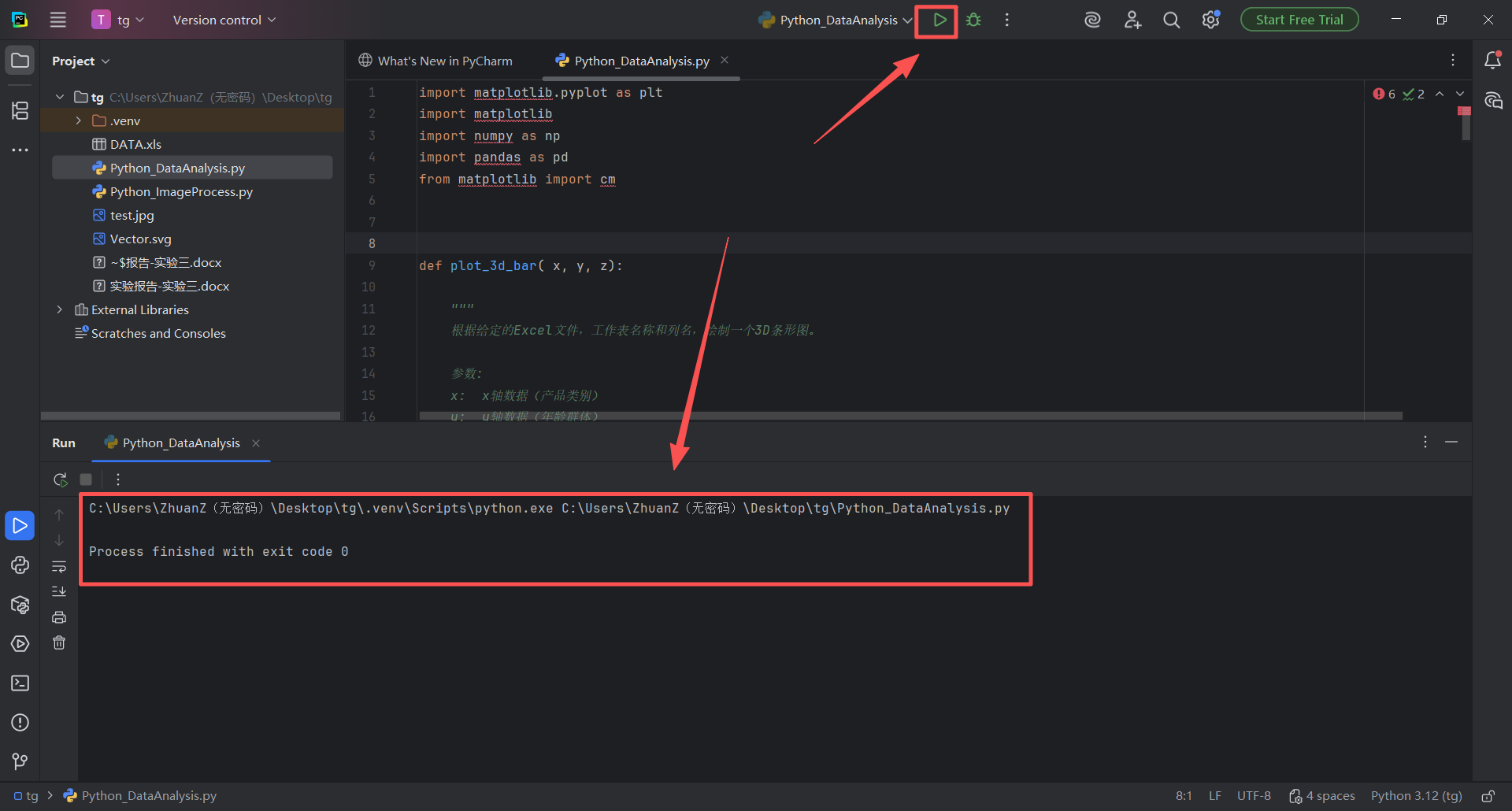
图 31 这个时候点击编译器的“播放”(运行)按钮,发现一点报错都没有,程序完美运行结束,但是没有任何展示画面,这是因为代码只是写好了,但是没有被调用,把下面这个代码复制,粘贴到代码最后面,然后点击运行
if __name__ == "__main__":# 示例数据x = ['产品A', '产品B', '产品C']y = ['年龄1', '年龄2', '年龄3']z = [100, 200, 150]# 调用函数绘制3D条形图plot_3d_bar(x, y, z)# 示例数据框df = pd.DataFrame({'产品': ['T恤', 'T恤', '裤子', '裤子'],'年龄群体': ['20-30', '30-40', '20-30', '30-40'],'销售金额': [100, 200, 150, 250]})# 调用函数绘制2D销售图plot_sales_2d(df, '产品', 'T恤', '年龄群体', '销售金额')# 调用函数绘制雷达图plot_radar(df, '产品', ['年龄群体'], '销售金额', ['20-30'])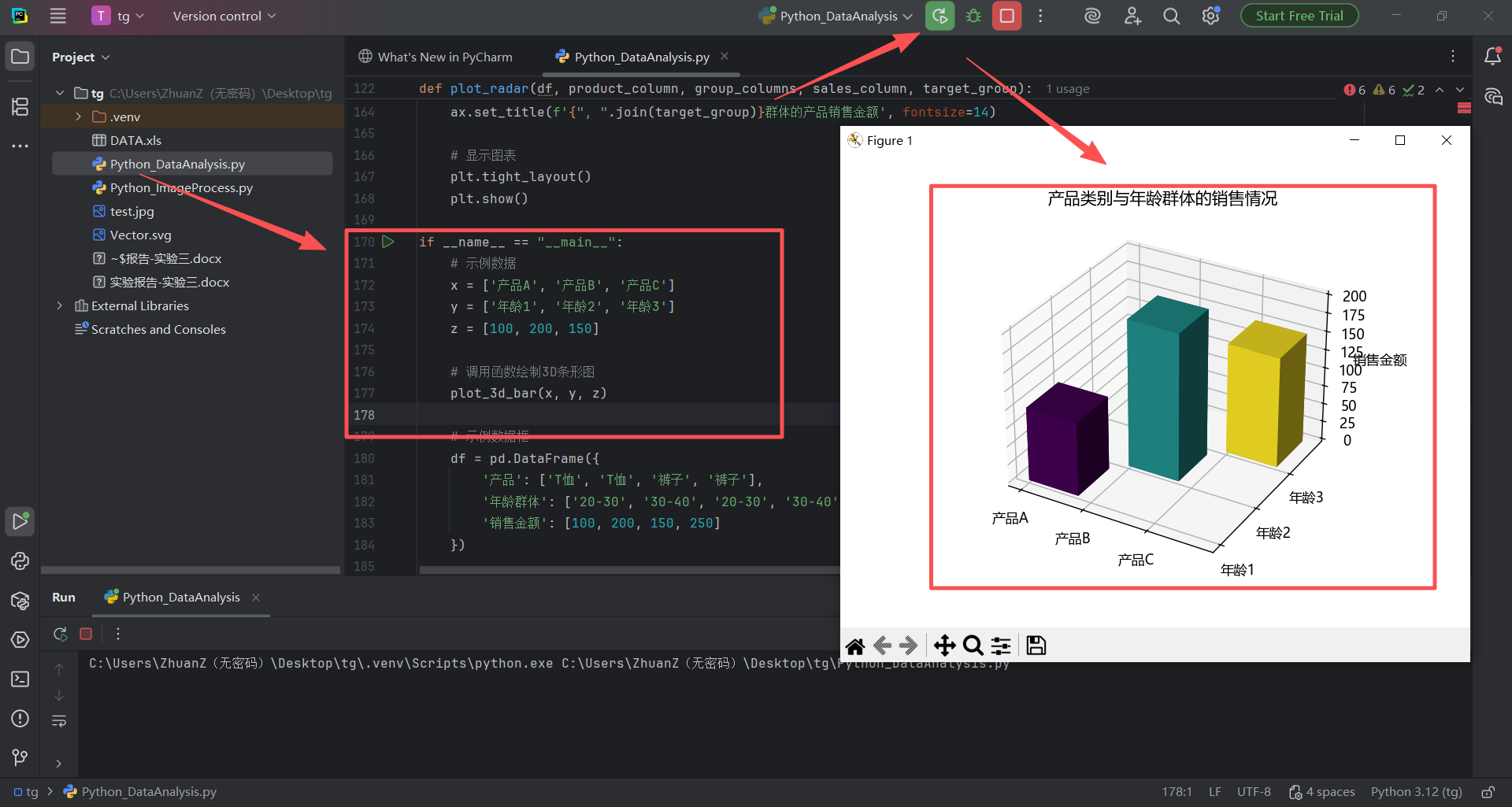
图 32 我把代码粘贴在代码Python_DataAnalysis.py文件的最后,点击运行按钮,得到输出结果,出现了3d效果的画面,到这里进入尾声了
五、修改代码实现读取excel数据,并显示自己的名字学号
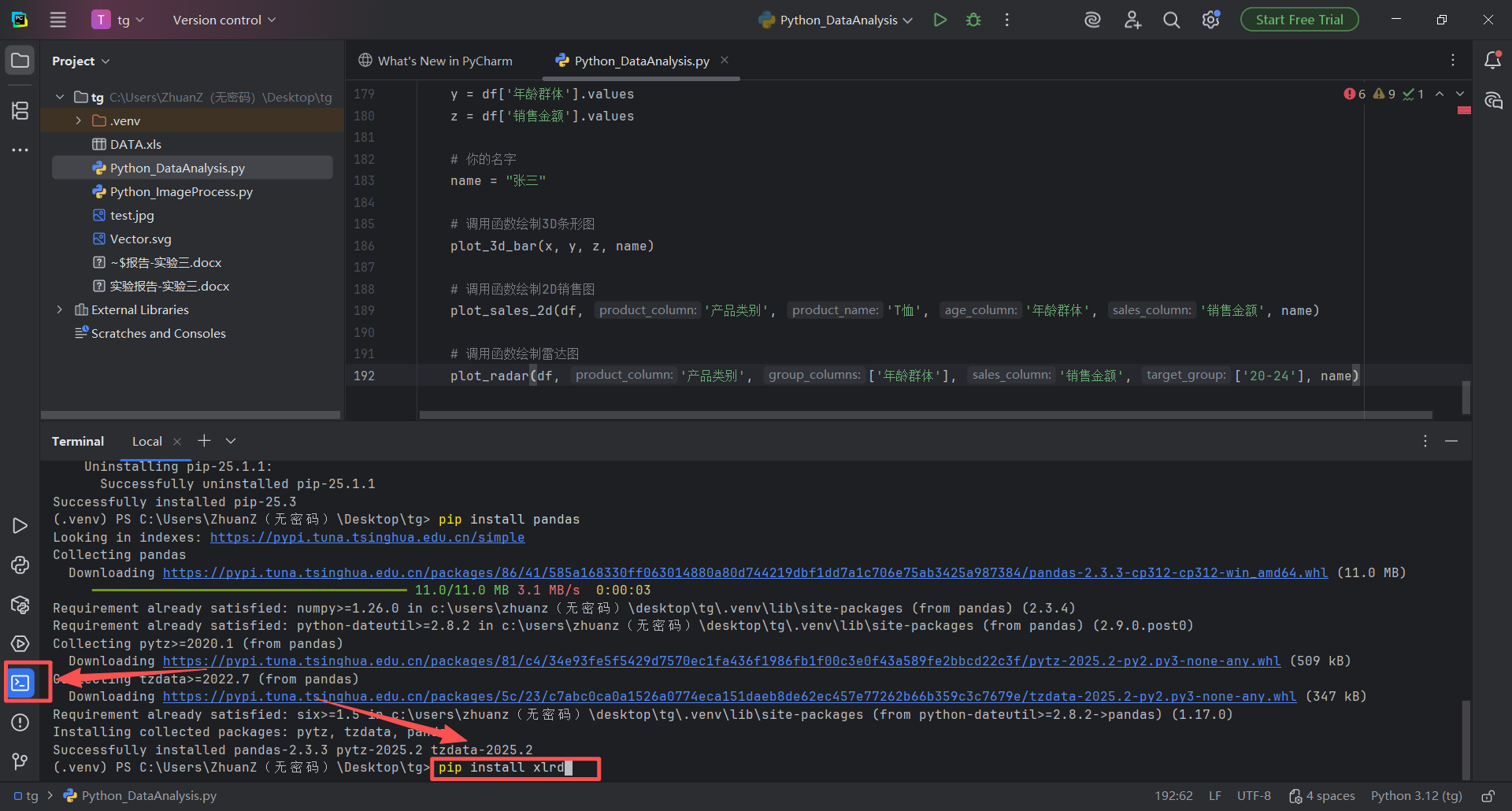
图 33 在终端区域输入pip install xlrd 并按下回车运行,安装好xlrd库
import os
import matplotlib
# 优先启用交互式后端(Windows常见为TkAgg),失败则使用默认后端
try:matplotlib.use('TkAgg')
except Exception:pass
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from matplotlib import cm# 设置中文字体,解决中文乱码问题
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei', 'SimHei']
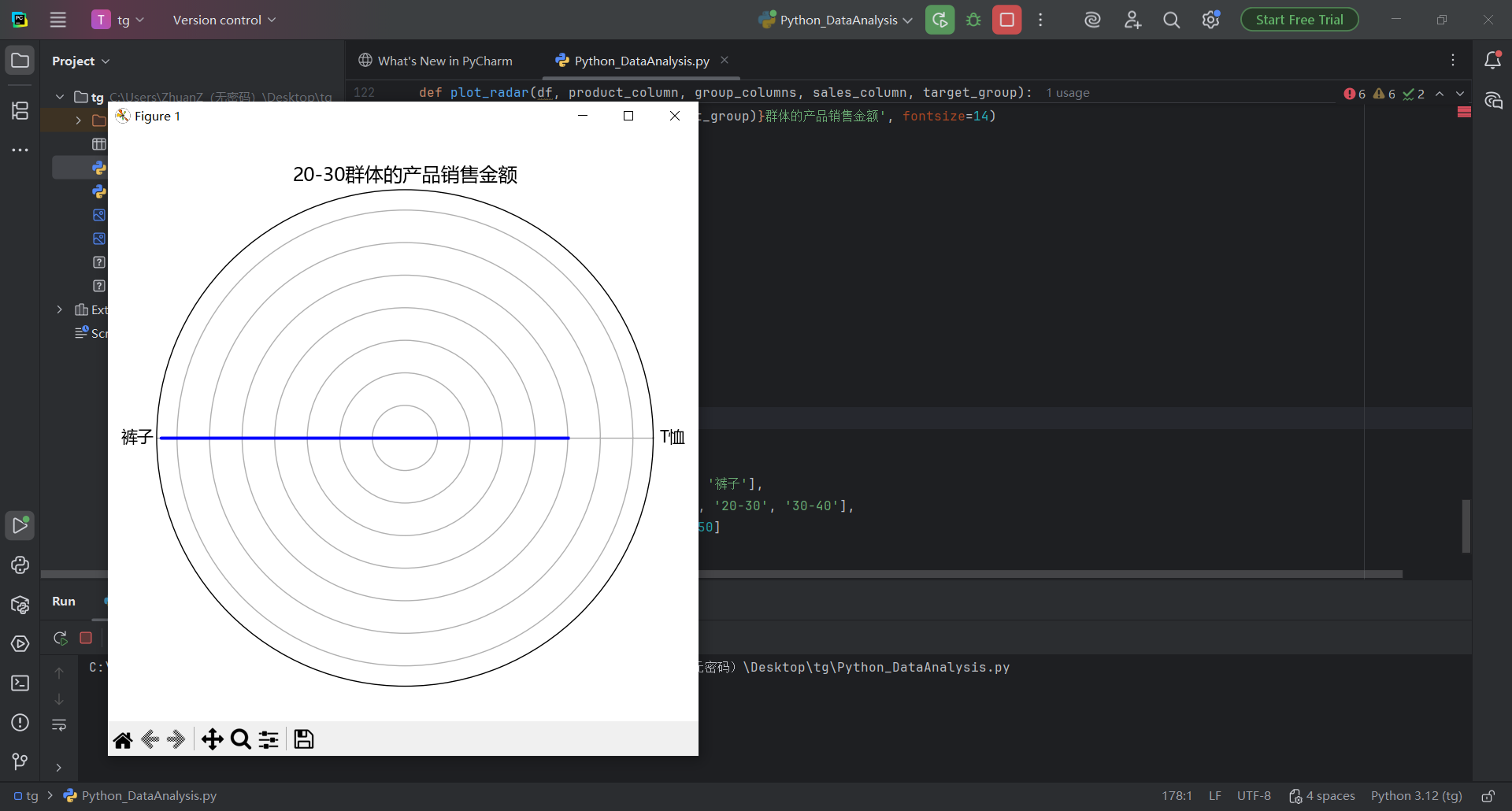
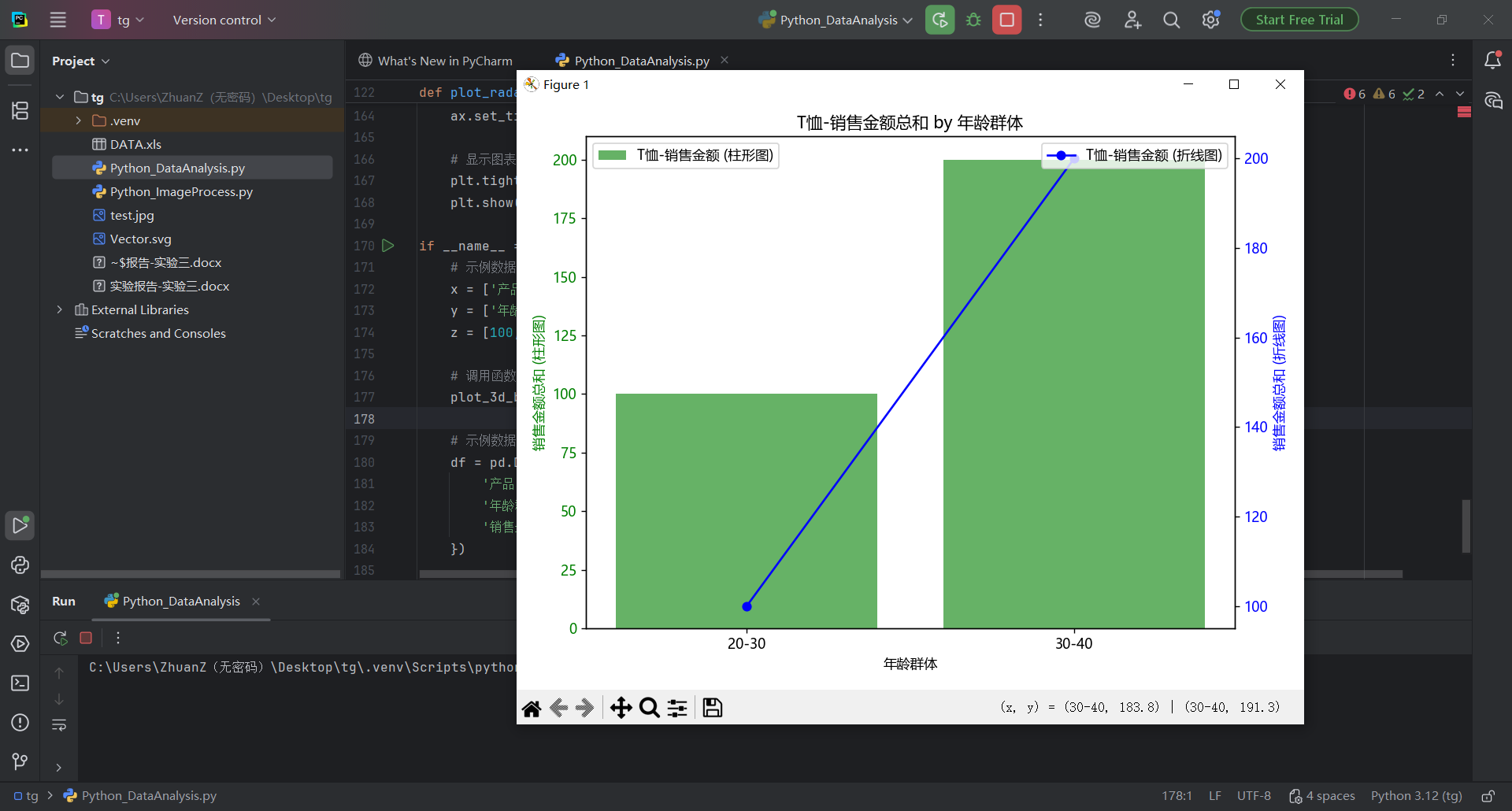
plt.rcParams['axes.unicode_minus'] = Falsedef _normalize_col_name(s):return str(s).strip().replace('\u3000', '').replace(' ', '')def load_dataframe(file_path, preferred_sheet=None):"""读取Excel并尽量匹配到'产品类别'、'年龄群体'、'销售金额'三列。如果preferred_sheet提供,则优先尝试该工作表;否则从所有工作表中选匹配最多的一张。返回:标准化列名后的DataFrame;失败返回None。"""try:sheets = pd.read_excel(file_path, sheet_name=None)except Exception as e:print(f'读取Excel失败:{e}')return Nonesynonyms = {'产品类别': ['产品类别', '商品类别', '类别', '品类', '产品类型', '产品种类'],'年龄群体': ['年龄群体', '年龄段', '年龄组', '年龄', '年龄范围'],'销售金额': ['销售金额', '销售额', '金额', '销售', '总金额', '订单金额']}normalized_synonyms = {k: {_normalize_col_name(v) for v in vs} for k, vs in synonyms.items()}def try_match(df):norm_map = {c: _normalize_col_name(c) for c in df.columns}found = {}for canon, candidates in normalized_synonyms.items():for original, norm in norm_map.items():if norm in candidates:found[canon] = originalbreakreturn foundchosen_df = Nonechosen_sheet_name = Nonebest_found = {}# 优先尝试preferred_sheetif preferred_sheet and preferred_sheet in sheets:df = sheets[preferred_sheet]found = try_match(df)best_found = foundif len(found) == 3:chosen_df = df.rename(columns={found['产品类别']: '产品类别',found['年龄群体']: '年龄群体',found['销售金额']: '销售金额'})chosen_sheet_name = preferred_sheetprint(f'使用工作表:{preferred_sheet}')return chosen_df# 遍历所有工作表,选择匹配最多的一张for sname, df in sheets.items():found = try_match(df)if len(found) > len(best_found):best_found = foundrename_map = {}if '产品类别' in found:rename_map[found['产品类别']] = '产品类别'if '年龄群体' in found:rename_map[found['年龄群体']] = '年龄群体'if '销售金额' in found:rename_map[found['销售金额']] = '销售金额'chosen_df = df.rename(columns=rename_map)chosen_sheet_name = snameif len(found) == 3:breakif chosen_df is None:print('未找到可用的工作表。')return Nonemissing = {k for k in ['产品类别', '年龄群体', '销售金额'] if k not in chosen_df.columns}if missing:print(f"工作表'{chosen_sheet_name}'缺少列:{', '.join(missing)}。实际列为:{list(chosen_df.columns)}")return Noneprint(f'使用工作表:{chosen_sheet_name}')return chosen_dfdef _add_name(fig, name):# 将名字置于图表上方fig.suptitle(name, fontsize=14, y=0.98)def plot_3d_bar(x, y, z, name, save_path=None):"""根据给定的数据绘制3D条形图,并在图表中添加名字。参数:x: x轴数据(产品类别)y: y轴数据(年龄群体)z: z轴数据(销售金额)name: 要显示的名字"""# 先按“产品类别-年龄群体”汇总,减少绘制数量df_raw = pd.DataFrame({'产品类别': x, '年龄群体': y, '销售金额': z})grouped = df_raw.groupby(['产品类别', '年龄群体'], as_index=False)['销售金额'].sum()# 唯一类别x_unique = grouped['产品类别'].unique()y_unique = grouped['年龄群体'].unique()# 创建索引映射x_index_map = {val: idx for idx, val in enumerate(x_unique)}y_index_map = {val: idx for idx, val in enumerate(y_unique)}x_indices = grouped['产品类别'].map(x_index_map).valuesy_indices = grouped['年龄群体'].map(y_index_map).values# 宽度与高度dx = np.full_like(x_indices, 0.8, dtype=float)dy = np.full_like(y_indices, 0.8, dtype=float)dz = grouped['销售金额'].values# 生成颜色映射colors = cm.viridis(np.linspace(0, 1, len(y_unique))) # 使用viridis颜色映射# 绘制3D条形图fig = plt.figure(figsize=(8, 6))ax = fig.add_subplot(111, projection='3d')# 为每个y轴类别指定一个颜色,并一次性绘制所有条形bar_colors = colors[y_indices]ax.bar3d(x_indices, y_indices, np.zeros_like(dz), dx, dy, dz, color=bar_colors, zsort='average')ax.view_init(elev=20, azim=35)# 设置x轴和y轴的标签ax.set_xticks(np.arange(len(x_unique))) # 设置x轴位置ax.set_xticklabels(x_unique) # 设置x轴标签为产品类别ax.set_yticks(np.arange(len(y_unique))) # 设置y轴位置ax.set_yticklabels(y_unique) # 设置y轴标签为年龄群体# 设置z轴的标签ax.set_zlabel('销售金额') # 设置z轴标签为销售金额# 设置轴标题ax.set_title('产品类别与年龄群体的销售情况')# 在图表上方添加名字_add_name(fig, name)plt.tight_layout(rect=[0, 0, 1, 0.95])if save_path:fig.savefig(save_path, dpi=150, bbox_inches='tight')plt.close(fig)else:plt.show()def plot_sales_2d(df, product_column, product_name, age_column, sales_column, name, save_path=None):"""绘制条形折线复合图,并在图表中添加名字。参数:df: 数据框product_column: 产品列名product_name: 产品名称age_column: 年龄群体列名sales_column: 销售金额列名name: 要显示的名字"""# 根据产品类别筛选数据product_sales = df[df[product_column] == product_name]if product_sales.empty:print(f"没有找到产品 '{product_name}' 的数据,跳过2D图绘制。")return# 计算每个年龄群体的销售金额总和sales_by_age = product_sales.groupby(age_column)[sales_column].sum().reset_index()# 创建图形fig, ax1 = plt.subplots(figsize=(8, 6))# 绘制柱形图ax1.bar(sales_by_age[age_column], sales_by_age[sales_column], color='g', alpha=0.6, label='{}-销售金额 (柱形图)'.format(product_name))ax1.set_xlabel('年龄群体')ax1.set_ylabel('销售金额总和 (柱形图)', color='g')ax1.tick_params(axis='y', labelcolor='g')# 创建第二个y轴ax2 = ax1.twinx()# 绘制折线图ax2.plot(sales_by_age[age_column], sales_by_age[sales_column], marker='o', color='b', linestyle='-',label='{}-销售金额 (折线图)'.format(product_name))ax2.set_ylabel('销售金额总和 (折线图)', color='b')ax2.tick_params(axis='y', labelcolor='b')# 设置标题ax1.set_title('{}-销售金额总和 by 年龄群体'.format(product_name))# 在图表上方添加名字_add_name(fig, name)# 显示图例ax1.legend(loc='upper left')ax2.legend(loc='upper right')# 保存或显示plt.tight_layout(rect=[0, 0, 1, 0.95])if save_path:fig.savefig(save_path, dpi=150, bbox_inches='tight')plt.close(fig)else:plt.show()def plot_radar(df, product_column, group_columns, sales_column, target_group, name, save_path=None):"""绘制雷达图,并在图表中添加名字。参数:df: 数据框product_column: 产品列名group_columns: 分组列名sales_column: 销售金额列名target_group: 目标群体name: 要显示的名字"""# 根据目标群体筛选数据(允许不筛选)filters = []if target_group:filters = target_group if isinstance(target_group, (list, tuple)) else [target_group]for group_column, target_value in zip(group_columns, filters):df = df[df[group_column] == target_value]if df.empty:tg = filters if filters else ['(全部)']print(f"没有找到符合条件的群体: {', '.join(map(str, tg))}")return# 计算每个产品类别的销售金额总和sales_by_product = df.groupby(product_column)[sales_column].sum().reset_index()# 提取产品类别和相应的销售金额categories = sales_by_product[product_column].valuessales_totals = sales_by_product[sales_column].values# 计算雷达图的角度angles = np.linspace(0, 2 * np.pi, len(categories), endpoint=False).tolist()# 雷达图的图形准备fig, ax = plt.subplots(figsize=(6, 6), subplot_kw=dict(polar=True))# 数据填充sales_totals = np.concatenate((sales_totals, [sales_totals[0]])) # 将第一个数据点重复,使得图形闭合angles += angles[:1] # 让角度圆周闭合# 绘制雷达图ax.fill(angles, sales_totals, color='b', alpha=0.6, label='销售金额总和')ax.plot(angles, sales_totals, color='b', linewidth=2)# 设置雷达图的标签ax.set_yticklabels([]) # 不显示y轴标签ax.set_xticks(angles[:-1])ax.set_xticklabels(categories, fontsize=12)# 设置标题ax.set_title(f'{", ".join(target_group)}群体的产品销售金额', fontsize=14)# 在图表上方添加名字_add_name(fig, name)# 保存或显示plt.tight_layout(rect=[0, 0, 1, 0.95])if save_path:fig.savefig(save_path, dpi=150, bbox_inches='tight')plt.close(fig)else:plt.show()if __name__ == "__main__":# 读取 Excel 文件(自动匹配列与工作表)file_path = "DATA.xls"df = load_dataframe(file_path, preferred_sheet="Sheet2")if df is None:raise SystemExit(1)# 示例数据x = df['产品类别'].valuesy = df['年龄群体'].valuesz = df['销售金额'].values# 你的名字(将显示在图表上方)name = "张三"# 直接本地显示图表(不通过预览网址)plot_3d_bar(x, y, z, name)plot_sales_2d(df, '产品类别', 'T恤', '年龄群体', '销售金额', name)plot_radar(df, '产品类别', ['年龄群体'], '销售金额', ['20-24'], name)把这段代码复制之后用下图方式粘贴到pycahrm运行,得到结果
图 34 在pycharm中编辑Python_DataAnalysis.py文件的页面,鼠标左键单击编辑器中任意位置,出现光标之后,使用全选快捷键(同时按下ctrl键和a字母键)然后按下粘贴快捷键(同时按下ctrl键和v字母键),这样改好的代码就粘贴到了Python_DataAnalysis.py文件中,然后点击运行按钮
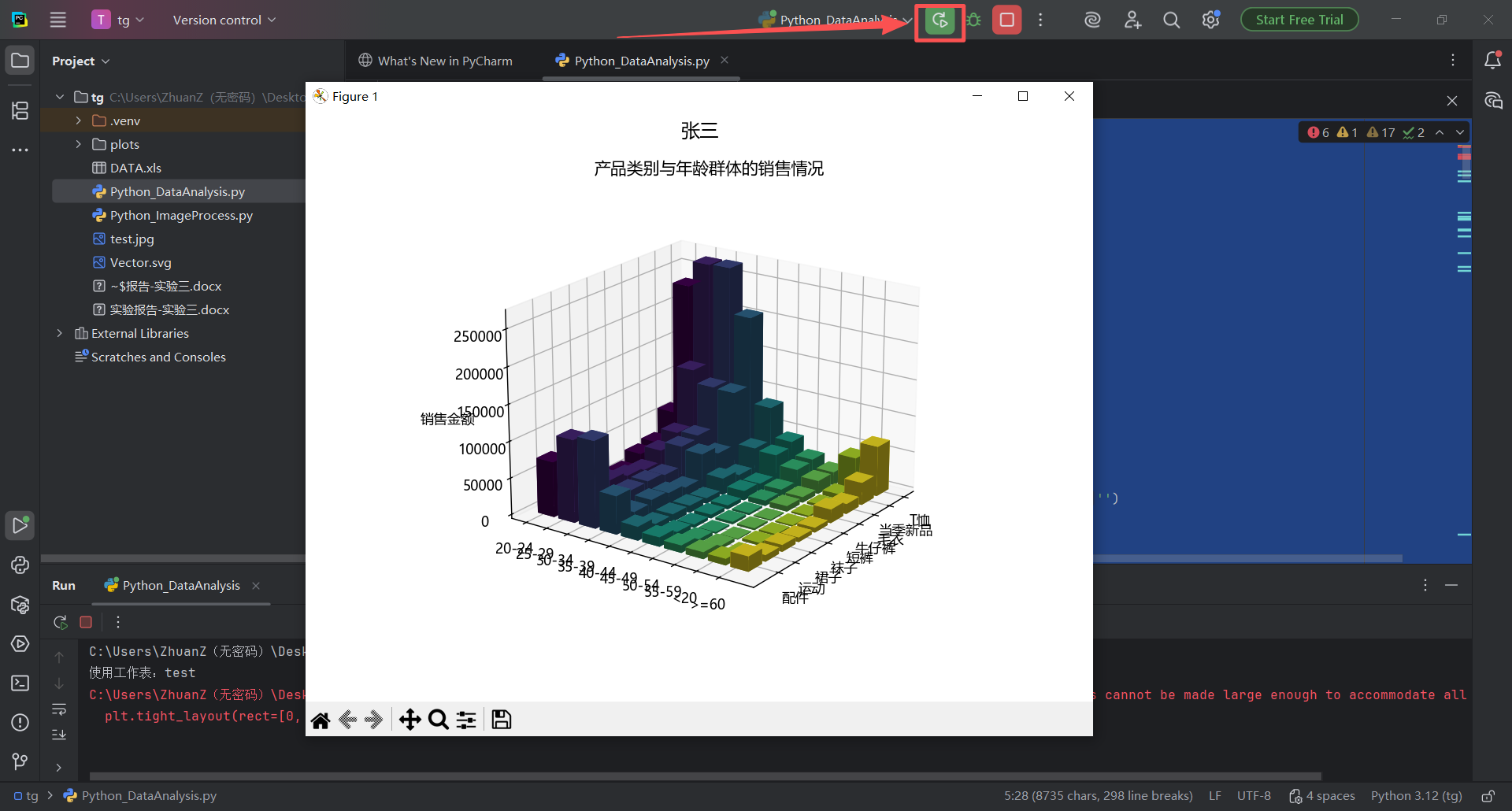
图 35 点击运行按钮,发现图标运行出来了,整个3d效果很不错,点击关闭按钮可以看到后面的图片
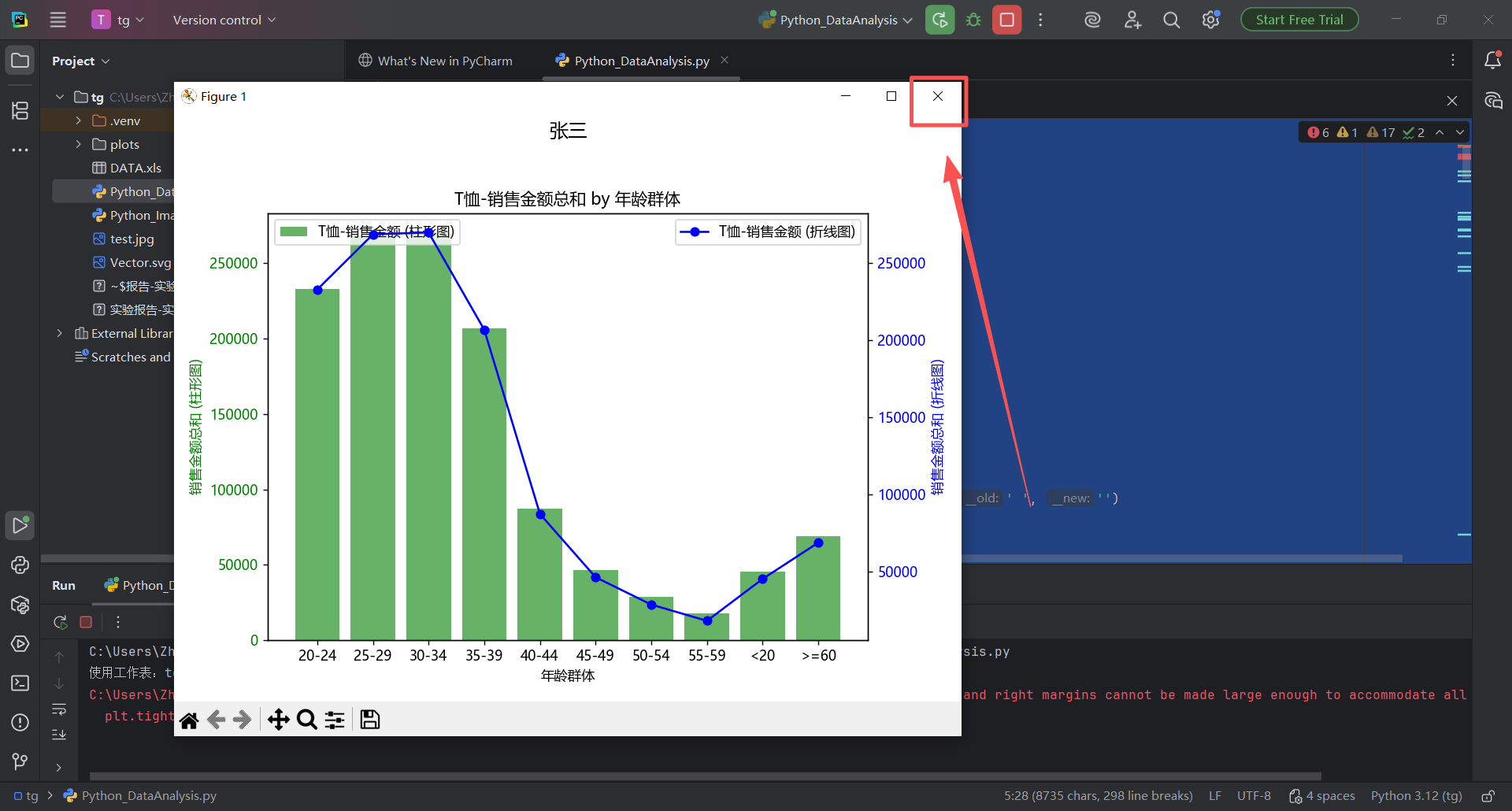
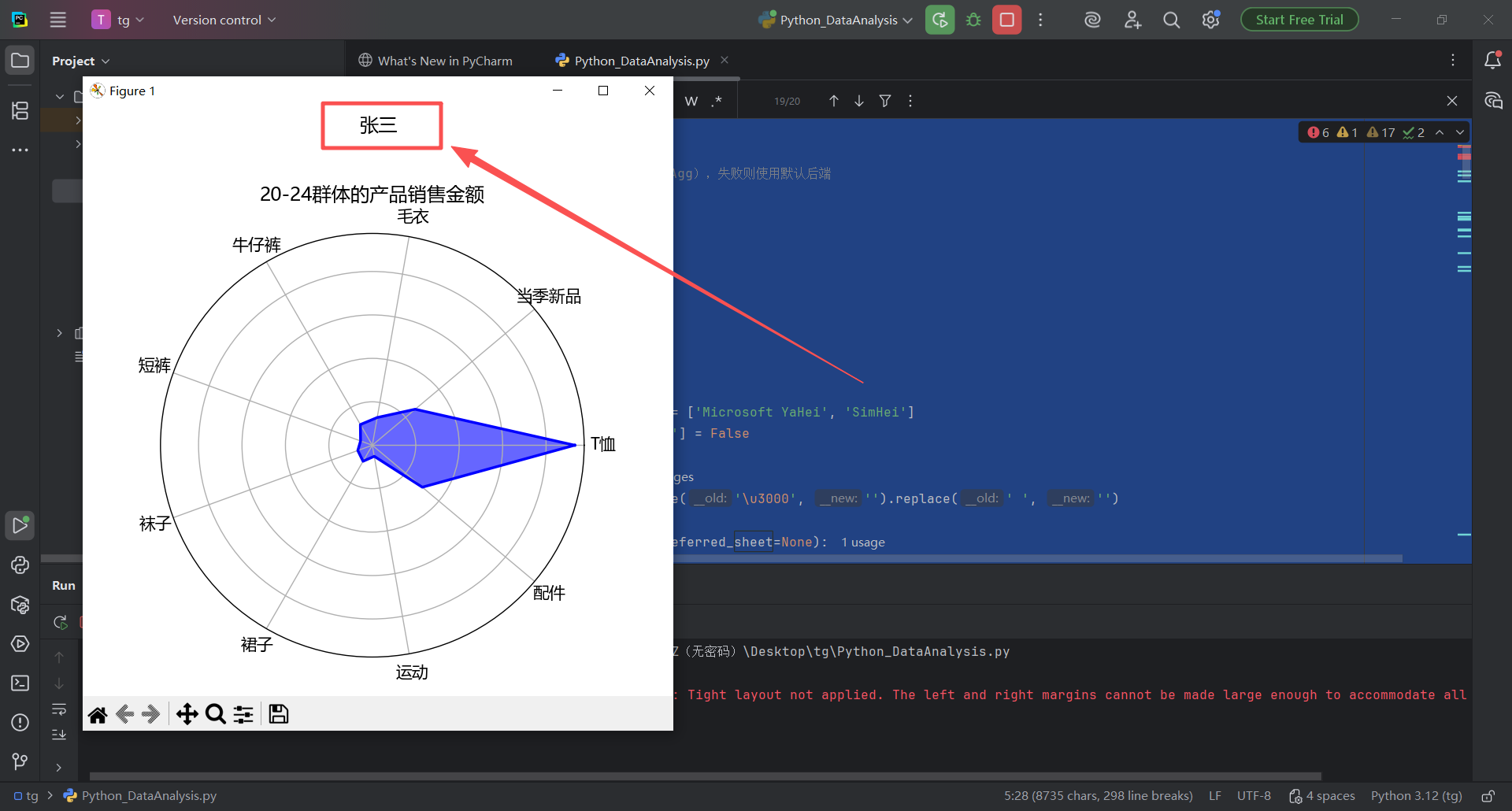
图 36 注意到图表名字是张三,还没有学号和头衔,下一步就是修改代码,改头衔和学号
图 38 进入pycharm中编辑Python_DataAnalysis.py文件的页面,鼠标左键单击,出现光标之后,使用搜素快捷键(同时按下ctrl键和f字母键),召唤出来图中框选的搜索栏(搜索栏输入器中可以快速检索想要查找的代码字段)
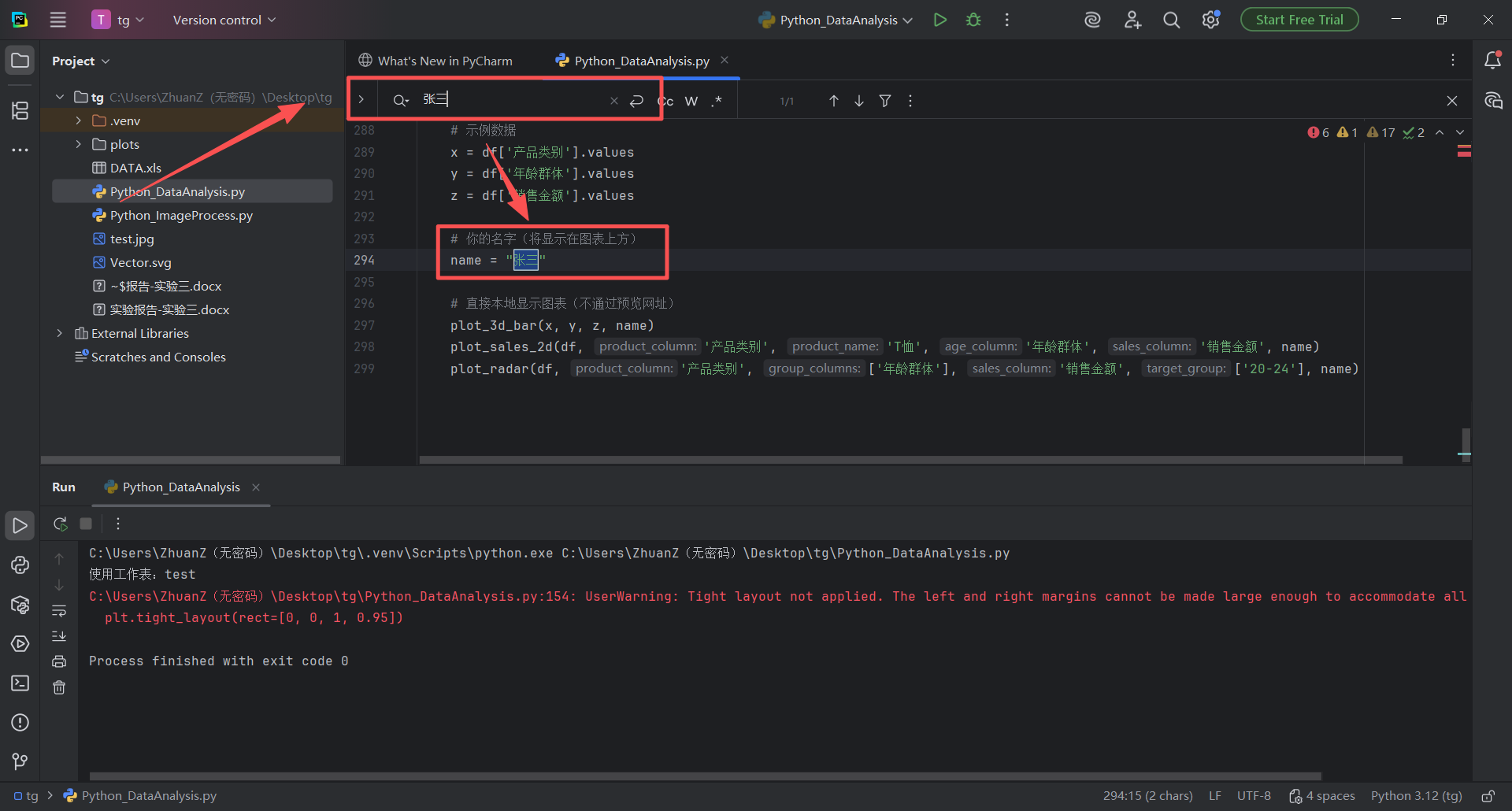
图 39 鼠标左键单击输入框,输入张三,pycharm自动检索到了张三,然后我们鼠标左键双击选中代码中的张三,并进行修改
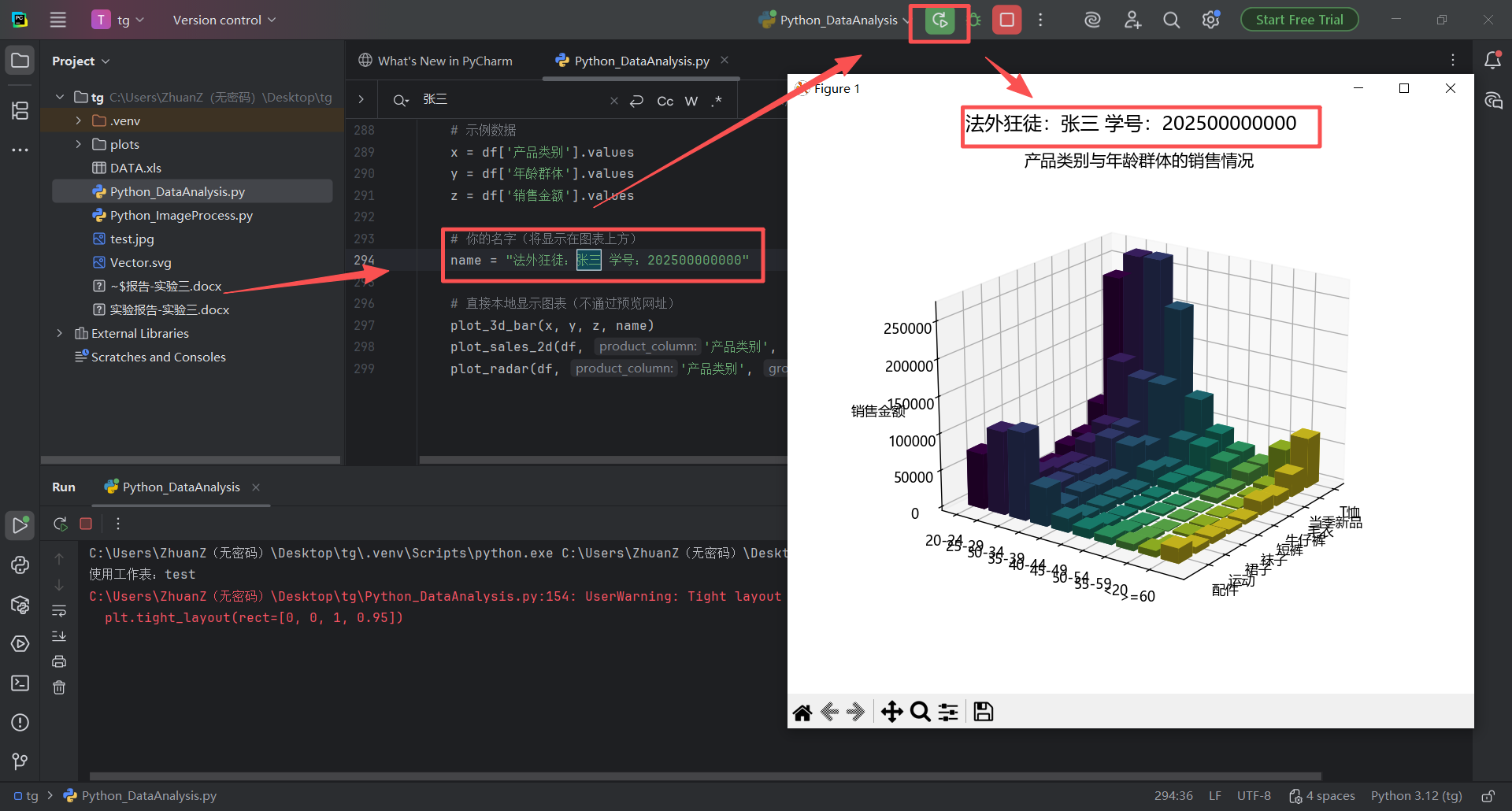
图 40 修改之后要注意双引号是英文的,双引号里面的内容可以随便修改,这行代码 name = "法外狂徒:张三 学号:202500000000" 的意思就是说:把 "法外狂徒:张三 学号:202500000000" 这个值使用赋值号(=号,在数学里是相等的意思,在代码里面这叫赋值符号)赋值给变量名为 name 的变量,传递这个变量打印在图表中就会在图表中显示对应的变量内容
修改之后点击运行,发现图表中的名字已然发生改变,张三成功成为法外狂徒,并打上了坐牢编号到这里,实验三的实验1部分内容已经完成
六、修改代码实现对图像进行缩放、旋转、模糊边缘等操作
代码已经编辑好,复制之后粘贴到编辑器运行可直接食用,哈哈
import os
import cv2
import numpy as np
import matplotlib.pyplot as plt# 设置中文字体,解决中文乱码问题
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei', 'SimHei']
plt.rcParams['axes.unicode_minus'] = Falsedef show_image(image_data, figsize, title, cmap=None, is_bgr=True, name_and_id=None):"""显示图像:param image_data: 图像数据:param figsize: 图像显示大小:param title: 图像标题:param cmap: 颜色映射(彩色图像通常不需要设置):param is_bgr: 传入的是OpenCV读取的BGR彩色图像,自动转换为RGB显示:param name_and_id: 显示在标题上的名字和学号"""plt.figure(figsize=figsize)if image_data is None:raise ValueError('show_image 接收到空图像数据')if image_data.ndim == 2:plt.imshow(image_data, cmap=cmap or 'gray')elif image_data.ndim == 3:if is_bgr:image_data = cv2.cvtColor(image_data, cv2.COLOR_BGR2RGB)plt.imshow(image_data)else:raise ValueError('不支持的图像维度')if name_and_id:plt.title(f"{name_and_id} - {title}")else:plt.title(title)plt.axis('off')plt.show()def _resolve_image_path(image_path):"""解析图像路径:若不存在则尝试使用同目录下的 test.jpg。"""if image_path and os.path.exists(image_path):return image_pathfallback = os.path.join(os.path.dirname(__file__), 'test.jpg')if os.path.exists(fallback):print(f"未找到指定图片,改用默认: {fallback}")return fallbackraise FileNotFoundError(f"找不到图像文件:{image_path},且默认文件不存在: {fallback}")def load_image(image_path, flags=cv2.IMREAD_COLOR):"""读取图像并进行空值校验;失败时抛出清晰错误。"""resolved = _resolve_image_path(image_path)img = cv2.imread(resolved, flags)if img is None:raise FileNotFoundError(f"无法读取图像:{resolved}。请检查路径或文件完整性。")return imgdef detect_edges(image_path, image_data=None, frame_color=[0, 255, 0]):"""边缘检测:param image_path: 图像路径:param image_data: 可选,直接传入图像数据:param frame_color: 边缘颜色,默认为绿色:return: 带有边缘的图像"""if image_data is None:image = load_image(image_path)else:image = image_data# Canny边缘检测edges = cv2.Canny(image, 100, 200)# 在原图上绘制边缘image_with_edges = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)image_with_edges[edges != 0] = frame_colorreturn image_with_edgesdef resize_image(image_path, width, height, name_and_id):"""图像缩放:param image_path: 图像路径:param width: 新宽度:param height: 新高度:param name_and_id: 显示在标题上的名字和学号:return: 缩放后的图像"""image = load_image(image_path)resized_image = cv2.resize(image, (width, height))show_image(resized_image, (10, 5), 'Resized Image', is_bgr=True, name_and_id=name_and_id)def rotate_image(image_path, degree, name_and_id):"""图像旋转:param image_path: 图像路径:param degree: 旋转角度:param name_and_id: 显示在标题上的名字和学号:return: 旋转后的图像"""image = load_image(image_path)center = (image.shape[1] // 2, image.shape[0] // 2)rotation_matrix = cv2.getRotationMatrix2D(center, degree, 1)rotated_image = cv2.warpAffine(image, rotation_matrix, (image.shape[1], image.shape[0]))show_image(rotated_image, (10, 5), 'Rotated Image', is_bgr=True, name_and_id=name_and_id)def blur_image(image_path, filter_size, name_and_id):"""图像模糊:param image_path: 图像路径:param filter_size: 模糊过滤器大小:param name_and_id: 显示在标题上的名字和学号:return: 模糊后的图像"""image = load_image(image_path)blurred_image = cv2.blur(image, (filter_size, filter_size))gaussian_blurred_image = cv2.GaussianBlur(image, (filter_size, filter_size), 0)plt.figure(figsize=(10, 5))plt.subplot(1, 3, 1)plt.title('Original Image')plt.imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))plt.axis('off')plt.subplot(1, 3, 2)plt.title('Mean Blurred Image')plt.imshow(cv2.cvtColor(blurred_image, cv2.COLOR_BGR2RGB))plt.axis('off')plt.subplot(1, 3, 3)plt.title('Gaussian Blurred Image')plt.imshow(cv2.cvtColor(gaussian_blurred_image, cv2.COLOR_BGR2RGB))plt.axis('off')if name_and_id:plt.suptitle(name_and_id)plt.show()def convert_color(image_path, name_and_id):"""图像色彩转换:param image_path: 图像路径:param name_and_id: 显示在标题上的名字和学号:return: 转换后的图像"""image = load_image(image_path)gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)hsv_image = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)plt.figure(figsize=(10, 5))plt.subplot(1, 3, 1)plt.title('Original Image')plt.imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))plt.axis('off')plt.subplot(1, 3, 2)plt.title('Gray Image')plt.imshow(gray_image, cmap='gray')plt.axis('off')plt.subplot(1, 3, 3)plt.title('HSV Image')plt.imshow(hsv_image)plt.axis('off')if name_and_id:plt.suptitle(name_and_id)plt.show()def equalize_image(image_path, name_and_id):"""图像均衡化:param image_path: 图像路径:param name_and_id: 显示在标题上的名字和学号:return: 均衡化后的图像"""image = load_image(image_path, cv2.IMREAD_GRAYSCALE)equalized_image = cv2.equalizeHist(image)plt.figure(figsize=(10, 5))plt.subplot(1, 2, 1)plt.title('Original Image')plt.imshow(image, cmap='gray')plt.axis('off')plt.subplot(1, 2, 2)plt.title('Equalized Image')plt.imshow(equalized_image, cmap='gray')plt.axis('off')if name_and_id:plt.suptitle(name_and_id)plt.show()def binary_image(image_path, thresh, maxval=255, name_and_id=''):"""图像二值化:param image_path: 图像路径:param thresh: 阈值:param maxval: 最大值,默认为255:param name_and_id: 显示在标题上的名字和学号:return: 二值化后的图像"""image = load_image(image_path, cv2.IMREAD_GRAYSCALE)_, binary_image = cv2.threshold(image, thresh, maxval, cv2.THRESH_BINARY)plt.imshow(binary_image, cmap='gray')if name_and_id:plt.title(f'{name_and_id} - Binary Image')else:plt.title('Binary Image')plt.axis('off')plt.show()if __name__ == '__main__':# 示例使用:默认读取同目录的 test.jpg(已提供)。image_path = 'test.jpg'name_and_id = "张三 - 20230001" # 替换为您的名字和学号resize_image(image_path, 300, 200, name_and_id) # 缩放图像rotate_image(image_path, 45, name_and_id) # 旋转图像blur_image(image_path, 5, name_and_id) # 模糊图像convert_color(image_path, name_and_id) # 色彩转换equalize_image(image_path, name_and_id) # 图像均衡化binary_image(image_path, 127, name_and_id=name_and_id) # 图像二值化edges_img = detect_edges(image_path)show_image(edges_img, (10, 5), 'Edges', is_bgr=False, name_and_id=name_and_id)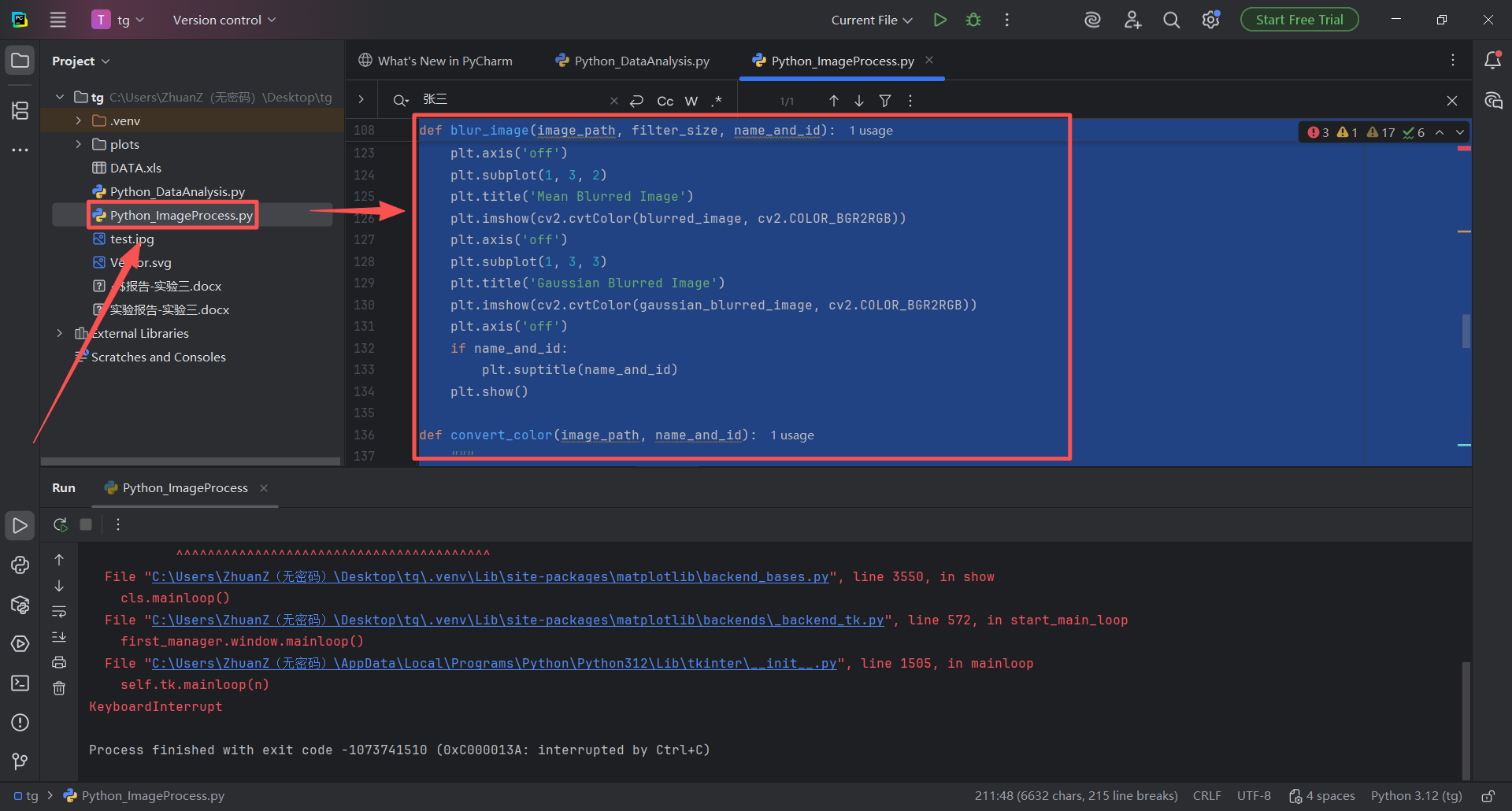
图 41 双击左侧项目目录(也称文件夹)下面的Python_ImageProcess.py代码文件,进入编辑器页面,鼠标左键单击编辑器中任意位置,出现光标之后,使用全选快捷键(同时按下ctrl键和a字母键)然后按下粘贴快捷键(同时按下ctrl键和v字母键),这样改好的代码就粘贴到了Python_ImageProcess.py文件中
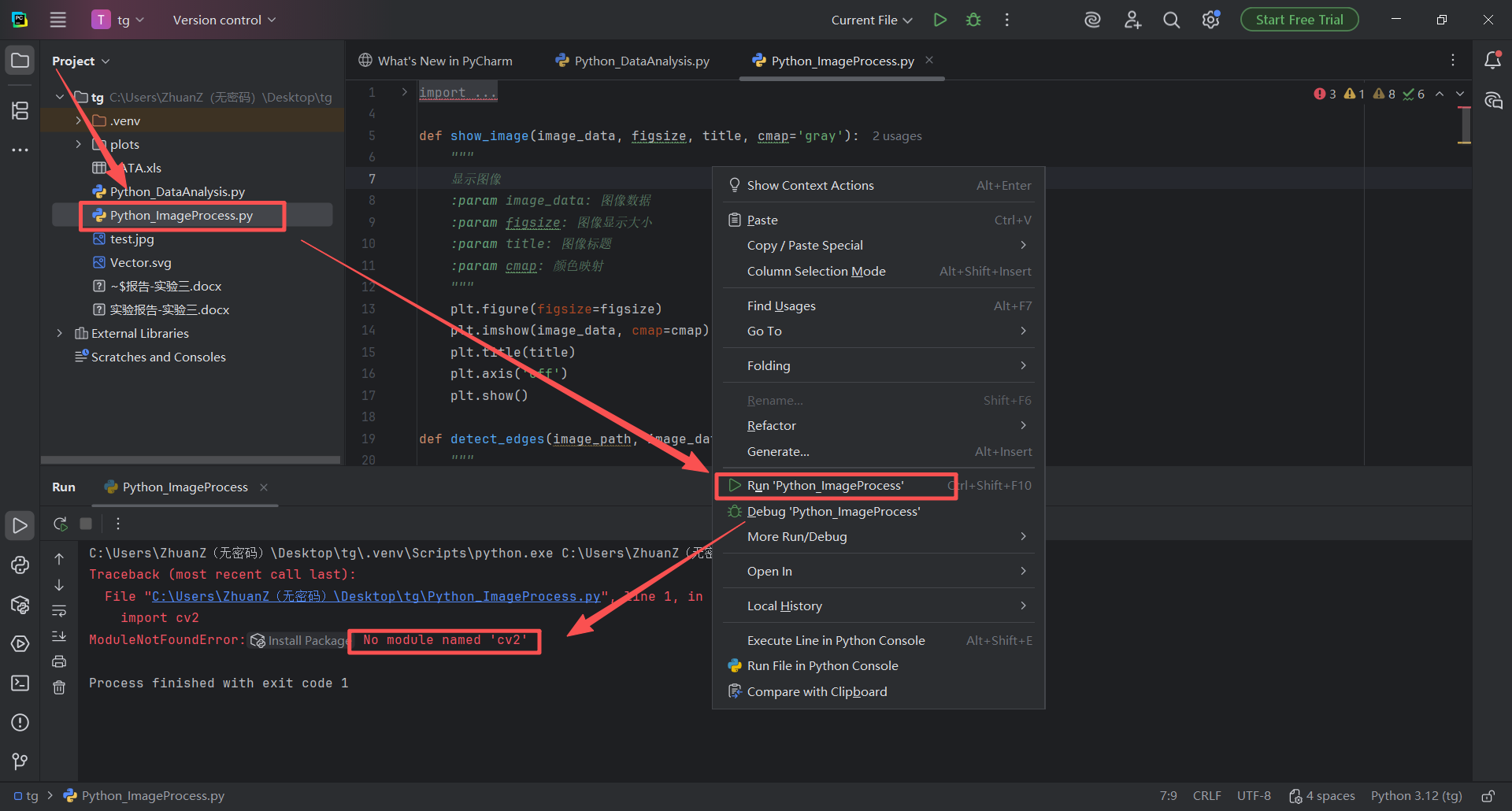
图 41 双击左侧项目目录(也称文件夹)下面的Python_ImageProcess.py代码文件,进入编辑器页面,鼠标左键单击编辑器中任意位置,出现光标之后,鼠标右键悬浮窗中有 Run 'Python_ImageProcess' 的字样(这是运行Python_ImageProcess文件的意思),单击这个字样按钮,控制台输出如图红色错误,这是因为我们的python解释器发现缺乏代码中需要使用到的cv2包(也称库),这种情况就需要安装对应的包和库了
图 42 点击终端按钮进入终端,在命令行输入安装opencv库(也称包)的代码,这里代码有点长我直接给出代码块(示例教程图42 里面的代码和下面有一点区别,下面代码块里面是清华的镜像源,因为外网的地址下载会出错,所以使用国内允许的这个镜像源地址)
pip install opencv-python -i https://pypi.tuna.tsinghua.edu.cn/simple复制之后用粘贴快捷键(同时按下ctrl键和v字母键)粘贴到终端命令行窗口即可,然后点击enter键,安装代码开始自动运行
图 43 看到这个提示说明已经安装opencv库(也称包)成功了,然后点击运行按钮
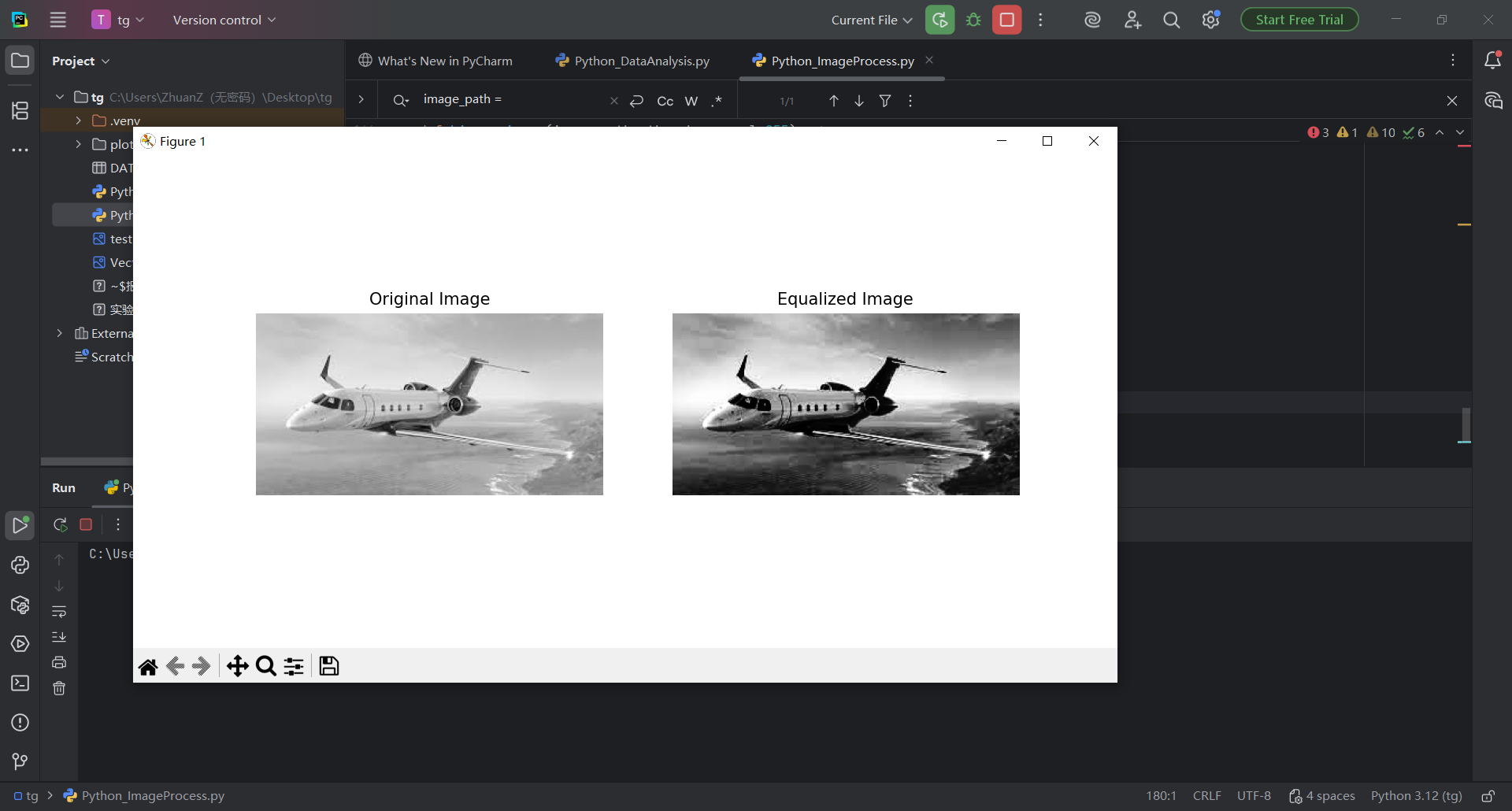
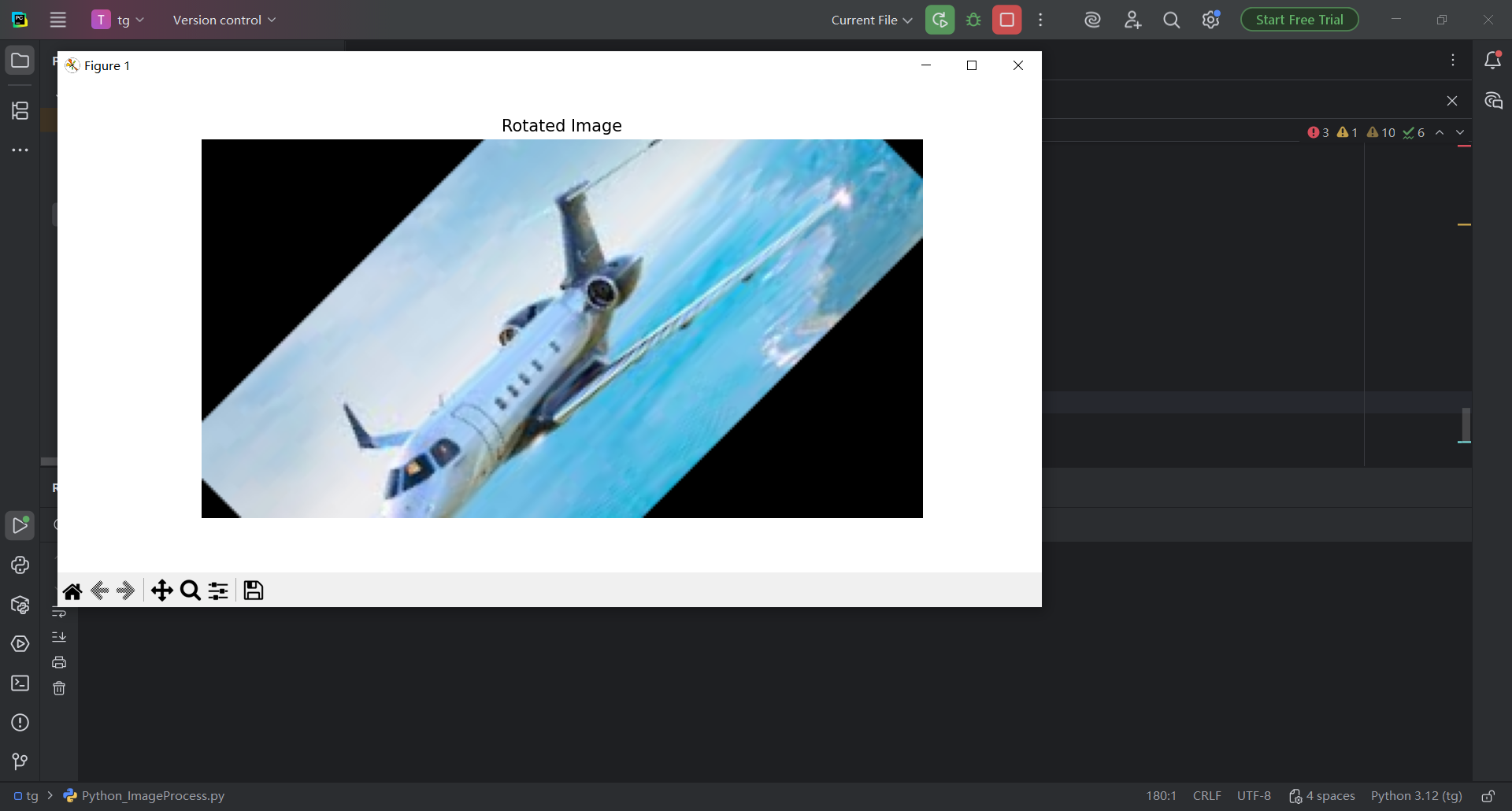
图 44 运行效果非常炸裂,但是还要给图片加上自己的名字
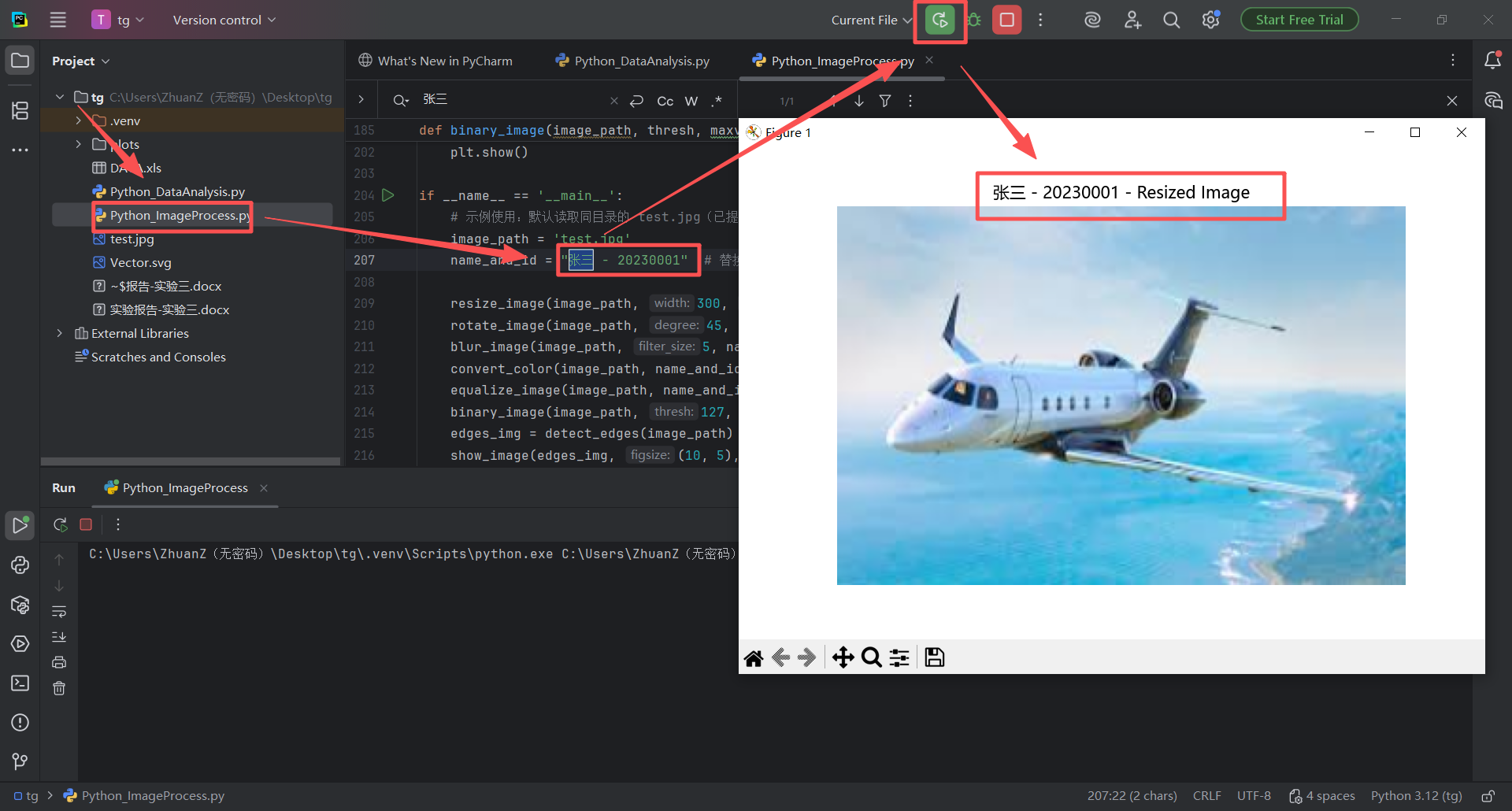
图 45 同样的替换名字学号的步骤,双击Python_ImageProcess.py文件进入pycharm的代码编辑器页面,然后使用搜索快捷键(同时按下ctrl键和f字母键),在搜索栏输入张三,找到指定变量,修改名字和内容,然后点击运行按钮即可
有疑问欢迎评论留言,还是要多练习,祝各位道友加油!学弟学妹加油!哈哈