DBLoss: Decomposition-based Loss Function for Time Series Forecasting 论文阅读
基本信息
发表刊物
NeurIPS 2025
作者信息

解决的问题
文章指出了现有基于距离的损失函数(如 MSE)在时间序列预测中存在的核心局限性。问题源于它们对时间序列的季节性和趋势成分缺乏针对性的优化:
基于距离的损失函数的局限性
忽略预测范围内的固有结构
它们通常只关注 预测值 和 真实值 在整体上的差异(即点对点的距离),而没有考虑到时间序列在预测范围内所固有的结构化信息(季节性、趋势)。
预测误差的局限性分析
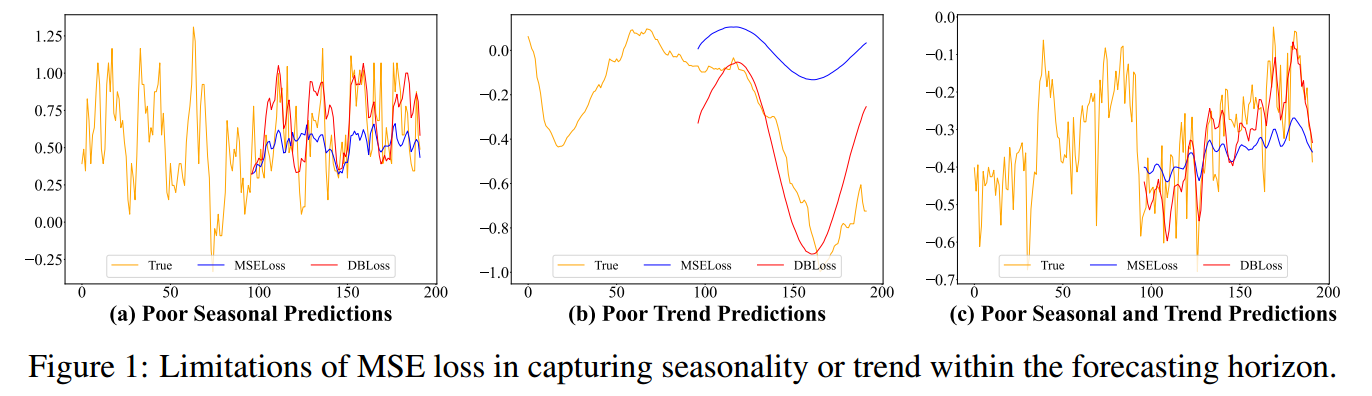
| 预测表现 | 核心问题 |
季节性预测不佳 | 模型未能准确捕捉时间序列的周期性变化。 例如在气温数据中,模型可能正确预测了平均气温,但未能预测出每天的最高/最低气温的周期性波动。 |
趋势预测不佳 | 模型未能准确捕捉时间序列的长期增长或下降的走势。例如,在股票价格预测中,模型可能在短期内表现尚可,但无法预测出整体的上升或下降趋势。 |
季节性和趋势预测均不佳 | 这是最严重的情况,模型对时间序列的两种主要结构性变化都未能准确建模。 |
核心洞察:缺乏归纳偏置(Inductive Bias)
即使预测模型在前向传播(即模型内部的计算过程)中使用了分解技术来分别处理季节性和趋势,但是损失函数本身(如 MSE)仍然是一个整体性的、不区分成分的度量。
这导致一个关键问题:
归纳偏置(Inductive Bias)没有被有效地应用到最终的预测结果中。
模型虽然在内部努力学习了趋势和季节性,但由于损失函数只惩罚总误差,它无法强制模型将学习到的趋势和季节性信息体现在最终的预测值中。
DBLoss 正是为了在损失函数层面引入这种归纳偏置,从而直接优化分解后的季节性和趋势分量。
论文解决的问题(核心创新点)
论文提出一个简单有效的基于分解的损失函数(Decomposition-Based Loss function)
DBLoss 的核心思想:
在预测范围内,使用指数移动平均等方法将时间序列分解为季节性和趋势分量。
然后,对每个分量分别计算损失。
最后,将这些分量损失加权组合起来,作为最终的损失函数来训练模型。
DBLoss 能够确保模型在训练过程中更加关注并准确地捕捉时间序列中的季节性和趋势信息,从而显著提高时间序列预测的性能。
论文的方法
DBLoss旨在通过在损失函数层面引入时间序列的分解结构,来直接优化季节性(Seasonality)和趋势(Trend)分量的预测。
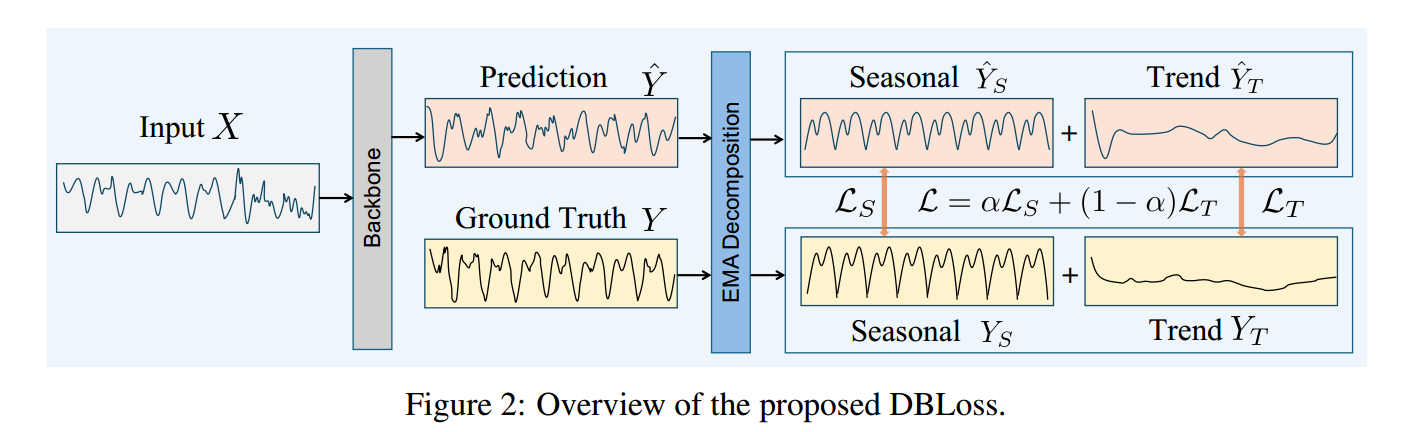
EMA Decomposition Module
DBLoss 首先 将时间序列的真实值和预测值进行分解,以提取出它们的季节性分量和趋势分量。
分解选择: 论文选择了指数移动平均 (EMA) 进行分解。
目标: 将时间序列
(可以是
或
) 分解为 Trend 和 Seasonality 。
算法流程

计算趋势分量 ():
通过定义 指数移动平均 (EMA) 权重
和相应的除数
(基于平滑因子
)。
计算加权数据的累积和
。
将累积和除以除数,得到趋势分量:
计算季节性分量 (
):
季节性分量被定义为原始时间序列减去趋势分量的残差:
通过这个模块,可以得到:
真实值分量:
(真实季节性),
(真实趋势)
预测值分量:
(预测季节性),
(预测趋势)
Weighted Loss Function
A. 分量损失定义
DBLoss 定义了两个核心分量损失,并使用了不同的距离度量:
季节性损失 (
): 采用
范数(即均方误差 MSE)来衡量季节性分量的差异。
趋势损失 ($L_T$): 采用 $L_1$ 范数(即平均绝对误差 MAE)来衡量趋势分量的差异。
B. 尺度对齐机制
为了防止季节性或趋势分量由于它们固有的尺度差异而在优化过程中产生支配性影响,论文引入了尺度对齐机制,对 进行调整。
对齐后的趋势损失 ():
:这是一个梯度分离操作。它确保了梯度不会通过对齐比例项(
)反向传播,从而避免了
之间的优化干扰。
C. 最终总损失 (Total Loss)
最终的 DBLoss ( ) 是季节性损失
和对齐后的趋势损失
的加权和:
: 一个可调参数,用于平衡季节性损失和对齐后的趋势损失在总优化目标中的贡献。
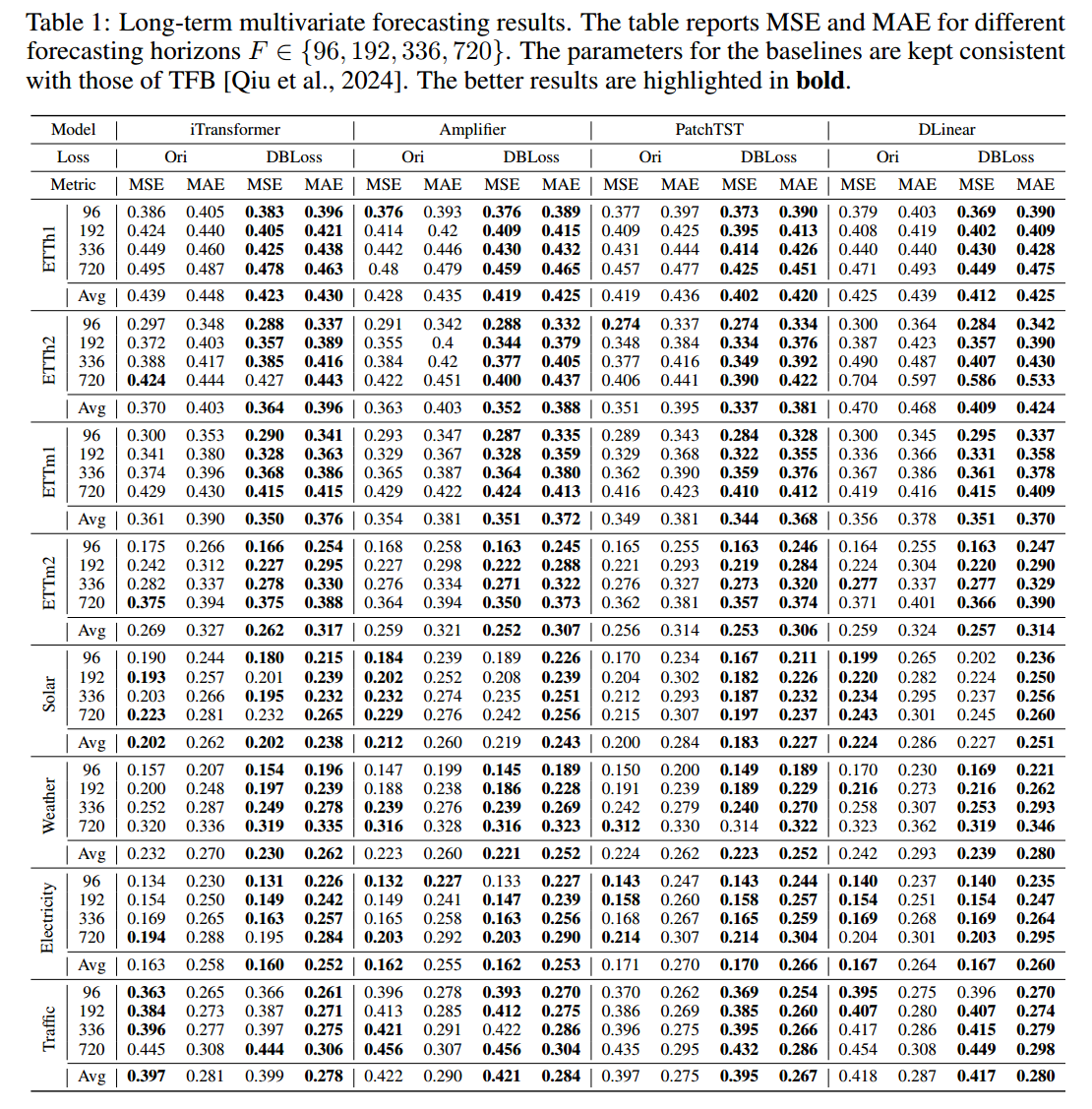
实验
实验部分旨在证明 DBLoss 作为一个通用损失函数,能够显著提升现有最先进(State-of-the-Art, SOTA)时间序列预测模型的性能。
Setup
数据集
以八个著名的预测基准作为目标数据集进行实验:
ETT (ETTh1, ETTh2, ETTm1, ETTm2 ), Solar, Weather, Electricity, and Traffic
Backbones
选择八个最先进的(SOTA)时间序列预测模型作为基线:
- 四个时间序列特定模型:iTransformer,Amplifier ,PatchTST、DLinear
- 四个时间序列基础模型:CALF、UniTS 、TTM 和 GPT4TS
Implementation Details
评价指标:MAE 和 MSE
预测区间:{ 96,192, 336, 720}
统一评估基准 (TFB): 利用 TFB (Time Series Forecasting Benchmark) 平台进行统一评估
使用 TFB 提供的最优基线脚本,只将训练时的损失函数替换为 DBLoss,而没有对模型架构、超参数、优化器等做任何其他修改。
Main Results