构建AI智能体:九十、图解大模型核心三大件 — 输入编码、注意力机制与前馈网络层
一、前言
随着大模型接触的越深,理解大模型的核心机制,已不再是特定人员的专属课题,而是关乎技术选型、成本控制和产品创新的关键能力。当我们面对动辄数百万参数的庞大模型时,直接参与预训练对资源有限的团队或个人确实不现实。但掌握其核心原理,却能为我们提供更多的可选途径,往期我们探讨的,有模型的微调艺术,如果能理解输入编码机制,意味着我们能更精准地设计提示词和准备训练数据,让模型在特定场景下发挥最大价值,还有特定的架构选择,如果我们能深入洞察注意力机制和前馈网络的运作原理,则更能够让我们在模型压缩和推理加速时做出明智决策,直接降低计算成本。
大模型核心三大件:输入编码、注意力机制与前馈网络,这些基础知识是我们在垂直领域构建差异化AI应用的基石,无论是改进现有产品还是开发全新解决方案。今天我们从应用的角度,避开复杂的数学公式,聚焦于这些机制如何影响模型表现,什么样的调整适合我们需要的模型状态,以及日常开发中如何利用这些知识做出更好的技术决策。
二、输入编码
输入编码就是让模型理解文字和位置,通俗的讲,就是让计算机读懂文字,我们给计算机表示的语言文字,不管是中文、英文还是其他语言,首先要做的,就是把这些文字转换成它能理解的数字,这个过程,就是输入编码。
1. 基础原理:从词到向量
- Token化(分词):计算机不认识连续的句子。我们首先要把句子切成小块,这些小块叫做 Token。例如,“我喜欢猫”可能会被切成 ["我", "喜欢", "猫"]。
- 构建词汇表:我们会有一个巨大的字典,通常就叫词汇表,里面包含了模型认识的所有Token,每个Token都有一个唯一的编号ID。比如 “我” -> 100, “喜欢” -> 205, “猫” -> 300。
- 词向量:但光有ID还不够,因为ID本身没有意义,我们并不清楚100和205之间有什么关系。所以,我们需要把每个ID转换成一个词向量。
2. 词向量
我们可以把它想象成一个词的身份证或档案。这个档案不是由一个数字,而是由一串数字构成,这一串数字就表示一个向量,每个数字代表了词的某种特征。
示例:
- “国王” 的词向量可能是 [0.8, 0.5, 0.9, ...]
- “女王” 的词向量可能是 [0.7, 0.6, 0.9, ...]
- “男人” 的词向量可能是 [0.8, 0.4, 0.2, ...]
- “女人” 的词向量可能是 [0.7, 0.5, 0.2, ...]
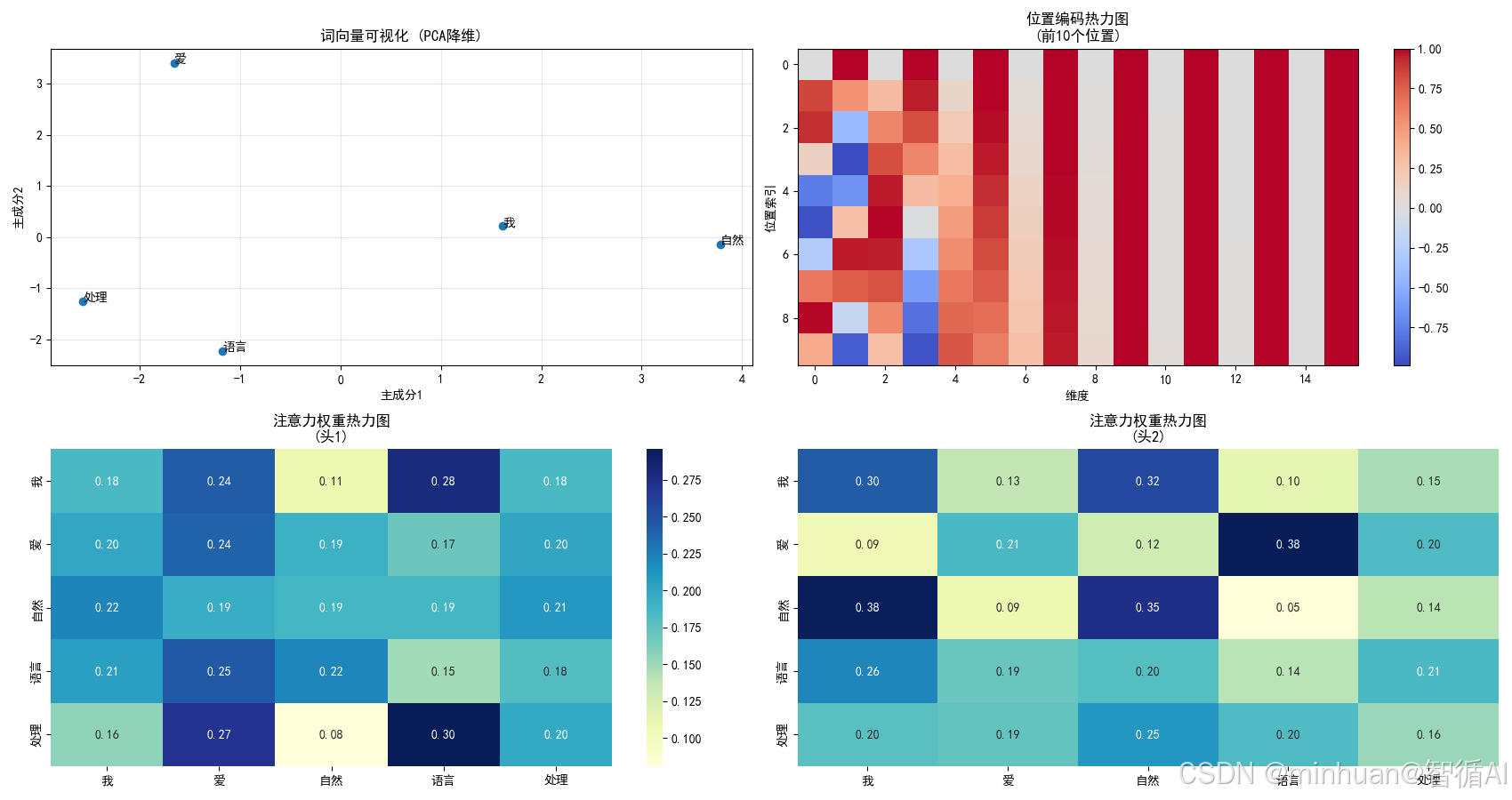
通过以上我们发现,国王”和“女王”在第三个维度上都很高,可能代表了“皇室”,两者表现得值才更匹配更突出,“国王”和“男人”在第一个维度上都很高,第一维度可能代表了“男性”,同样体现两者更匹配。通过这种方式,词与词之间的语义关系(如同义词、反义词、上下文关系)就被编码在了这些数字里。
词向量详情可参考《构建AI智能体:给词语绘制地图:Embedding如何构建机器的认知空间》
3. 位置编码
位置编码就是要记住词的顺序,Transformer不像RNN那样天然理解序列顺序,需要显式地告诉模型每个词的位置信息,比如“猫抓老鼠”和“老鼠抓猫”是完全不同的意思。但到目前为止,我们的词向量没有顺序信息,为了解决这个问题,我们引入了位置编码。我们为句子中的每个位置(第一个词,第二个词...)也生成一个独特的向量,然后把它加到该位置的词向量上。
直观理解:就像给每个词发一个定位的座位号,模型通过这个定位座位号就知道哪个词在前,哪个词在后了。
4. 作用与意义
- 作用:将离散的、人类可读的文字,转换为连续的、富含语义和位置信息的数学表示,有可能是很大的一堆数字,作为模型计算的原料。
- 意义:这是所有自然语言处理的基础,没有良好的输入编码,后续的复杂计算都是空中楼阁,它让计算机具备了理解语言含义的可能性。
5. 可视化示例
5.1 输入编码过程可视化
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib.patches import Rectangle, FancyBboxPatch
import mathsns.set_style("whitegrid")
# 设置中文字体和样式
plt.rcParams['font.sans-serif'] = ['SimHei', 'Arial Unicode MS']
plt.rcParams['axes.unicode_minus'] = Falsedef visualize_input_encoding():print("1. 输入编码过程可视化")# 示例句子sentence = "我 爱 学习"tokens = ["我", "爱", "学习"]# 创建图形fig, (ax1, ax2, ax3) = plt.subplots(1, 3, figsize=(18, 6))# 子图1: Token化ax1.set_title("步骤1: Token化 (分词)", fontsize=14, fontweight='bold', pad=20)ax1.text(0.5, 0.7, f'原句子: "{sentence}"', ha='center', va='center', fontsize=16, bbox=dict(boxstyle="round,pad=0.3", facecolor="lightblue"))ax1.text(0.5, 0.5, '→', ha='center', va='center', fontsize=20)# 显示分词结果token_display = " | ".join([f"[{token}]" for token in tokens])ax1.text(0.5, 0.3, f'Tokens: {token_display}', ha='center', va='center', fontsize=14,bbox=dict(boxstyle="round,pad=0.3", facecolor="lightgreen"))ax1.set_xlim(0, 1)ax1.set_ylim(0, 1)ax1.axis('off')# 子图2: 词向量映射ax2.set_title("步骤2: 词向量映射", fontsize=14, fontweight='bold', pad=20)# 模拟词向量 (3维以便可视化)word_vectors = {"我": [0.8, 0.2, 0.1],"爱": [0.3, 0.9, 0.4], "学习": [0.1, 0.3, 0.95]}y_pos = 0.7for i, token in enumerate(tokens):ax2.text(0.2, y_pos, f'"{token}"', ha='left', va='center', fontsize=12)ax2.text(0.4, y_pos, '→', ha='center', va='center', fontsize=16)vector_str = f"[{', '.join([f'{v:.1f}' for v in word_vectors[token]])}]"ax2.text(0.6, y_pos, vector_str, ha='left', va='center', fontsize=10,bbox=dict(boxstyle="round,pad=0.2", facecolor="wheat"))y_pos -= 0.2ax2.set_xlim(0, 1)ax2.set_ylim(0, 1)ax2.axis('off')# 子图3: 位置编码ax3.set_title("步骤3: 位置编码", fontsize=14, fontweight='bold', pad=20)# 简单的位置编码示例positions = ["位置 0", "位置 1", "位置 2"]pos_encodings = [[0.0, 1.0, 0.0],[0.5, 0.0, 0.5], [1.0, 0.0, 1.0]]y_pos = 0.7for i, (pos, encoding) in enumerate(zip(positions, pos_encodings)):ax3.text(0.2, y_pos, pos, ha='left', va='center', fontsize=12)encoding_str = f"[{', '.join([f'{e:.1f}' for e in encoding])}]"ax3.text(0.6, y_pos, encoding_str, ha='left', va='center', fontsize=10,bbox=dict(boxstyle="round,pad=0.2", facecolor="lightcoral"))y_pos -= 0.2ax3.set_xlim(0, 1)ax3.set_ylim(0, 1)ax3.axis('off')plt.tight_layout()plt.show()# 运行输入编码可视化
visualize_input_encoding()输出结果:
- Token化: 将文本分割成有意义的单元
- 词向量: 将每个词映射为数字向量,捕捉语义
- 位置编码: 为每个位置添加顺序信息
5.2 词向量可视化
import matplotlib.pyplot as plt
import numpy as np
from mpl_toolkits.mplot3d import Axes3D# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei', 'Arial Unicode MS']
plt.rcParams['axes.unicode_minus'] = False# 创建示例词向量数据(3维以便可视化)
words = {'国王': [2.1, 1.8, 0.9],'女王': [1.9, 1.9, 0.8],'男人': [2.0, 1.2, 0.3],'女人': [1.8, 1.3, 0.2],'王子': [1.7, 1.5, 0.7],'公主': [1.6, 1.6, 0.6]
}# 创建图形
fig = plt.figure(figsize=(15, 5))# 1. 3D词向量空间图
ax1 = fig.add_subplot(131, projection='3d')# 为不同类别的词设置颜色
colors = {'国王': 'red', '女王': 'coral', '男人': 'blue', '女人': 'lightblue', '王子': 'green', '公主': 'lightgreen'}# 绘制每个词的向量点
for word, vector in words.items():x, y, z = vectorax1.scatter(x, y, z, c=colors[word], s=100, label=word)ax1.text(x, y, z, word, fontsize=12, ha='left', va='bottom')# 连接相关的词
ax1.plot([words['国王'][0], words['女王'][0]], [words['国王'][1], words['女王'][1]], [words['国王'][2], words['女王'][2]], 'gray', linestyle='--', alpha=0.7)
ax1.plot([words['男人'][0], words['女人'][0]], [words['男人'][1], words['女人'][1]], [words['男人'][2], words['女人'][2]], 'gray', linestyle='--', alpha=0.7)
ax1.plot([words['王子'][0], words['公主'][0]], [words['王子'][1], words['公主'][1]], [words['王子'][2], words['公主'][2]], 'gray', linestyle='--', alpha=0.7)ax1.set_xlabel('维度1: 性别/身份')
ax1.set_ylabel('维度2: 皇室特征')
ax1.set_zlabel('维度3: 年龄/辈分')
ax1.set_title('1. 词向量在3D空间中的分布', fontsize=14, fontweight='bold', pad=20)
ax1.legend()# 2. 词向量表格表示
ax2 = fig.add_subplot(132)
ax2.axis('tight')
ax2.axis('off')# 创建表格数据
table_data = []
headers = ['词语', '维度1', '维度2', '维度3', '语义特征']
for word, vector in words.items():features = []if vector[0] > 2.0: features.append("男性倾向")elif vector[0] < 1.7: features.append("女性倾向")if vector[1] > 1.5: features.append("皇室")if vector[2] > 0.5: features.append("长辈")else: features.append("平辈")table_data.append([word, f'{vector[0]:.1f}', f'{vector[1]:.1f}', f'{vector[2]:.1f}', ', '.join(features)])table = ax2.table(cellText=table_data, colLabels=headers, cellLoc='center', loc='center',colColours=['lightgray']*5)
table.auto_set_font_size(False)
table.set_fontsize(10)
table.scale(1, 1.5)
ax2.set_title('2. 词向量的数值表示', fontsize=14, fontweight='bold', pad=20)# 3. 词向量语义关系图
ax3 = fig.add_subplot(133)# 使用前两个维度进行2D可视化
for word, vector in words.items():x, y = vector[0], vector[1]ax3.scatter(x, y, c=colors[word], s=150, label=word)ax3.annotate(word, (x, y), xytext=(5, 5), textcoords='offset points', fontsize=11)# 标注向量运算关系
king_x, king_y = words['国王'][0], words['国王'][1]
man_x, man_y = words['男人'][0], words['男人'][1]
woman_x, woman_y = words['女人'][0], words['女人'][1]
queen_x, queen_y = words['女王'][0], words['女王'][1]# 展示经典的词向量关系:国王 - 男人 + 女人 ≈ 女王
ax3.arrow(man_x, man_y, king_x-man_x, king_y-man_y, head_width=0.05, head_length=0.05, fc='blue', ec='blue', alpha=0.7, linestyle=':')
ax3.arrow(woman_x, woman_y, queen_x-woman_x, queen_y-woman_y, head_width=0.05, head_length=0.05, fc='red', ec='red', alpha=0.7, linestyle=':')ax3.text(1.85, 1.4, '国王 - 男人 + 女人 ≈ 女王', fontsize=10, bbox=dict(boxstyle="round,pad=0.3", facecolor="yellow", alpha=0.7))ax3.set_xlabel('维度1: 性别/身份特征')
ax3.set_ylabel('维度2: 社会地位特征')
ax3.set_title('3. 词向量语义关系可视化', fontsize=14, fontweight='bold', pad=20)
ax3.grid(True, alpha=0.3)plt.tight_layout()
plt.show()# 打印词向量关系的数学示例
print("\n词向量语义关系示例:")
print(f"国王向量: {words['国王']}")
print(f"男人向量: {words['男人']}")
print(f"女人向量: {words['女人']}")
print(f"女王向量: {words['女王']}")# 演示向量运算
result = np.array(words['国王']) - np.array(words['男人']) + np.array(words['女人'])
print(f"\n计算: 国王 - 男人 + 女人 ≈ {result}")
print(f"实际女王向量: {words['女王']}")
print("✓ 词向量能够捕捉: 国王 - 男性 + 女性 ≈ 女王 这样的语义关系!")输出结果:
词向量语义关系示例:
国王向量: [2.1, 1.8, 0.9]
男人向量: [2.0, 1.2, 0.3]
女人向量: [1.8, 1.3, 0.2]
女王向量: [1.9, 1.9, 0.8]计算: 国王 - 男人 + 女人 ≈ [1.9 1.9 0.8]
实际女王向量: [1.9, 1.9, 0.8]
✓ 词向量能够捕捉: 国王 - 男性 + 女性 ≈ 女王 这样的语义关系!
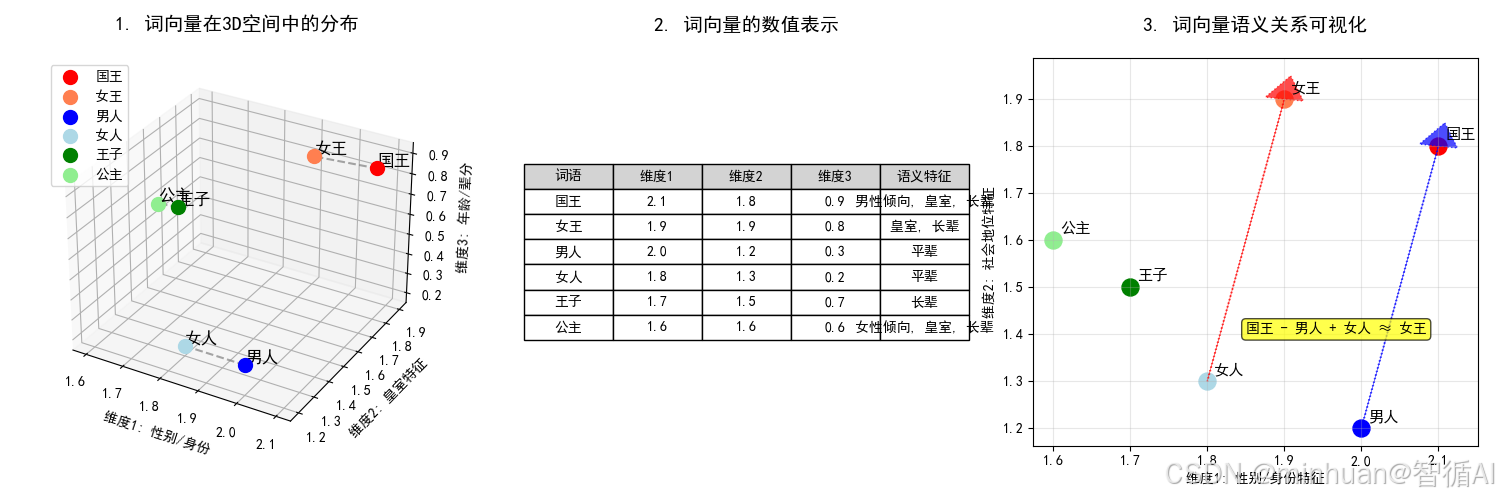
图片解析:
图1:语义聚类
- 皇室词汇(国王、女王、王子、公主)在维度2上数值较高
- 性别相近的词汇在维度1上位置接近
- 同类词汇在空间中自然聚集
图2:数值化表示
- 每个词有明确的数字特征
- 数值大小反映语义特性
- 计算机通过这些数字"理解"词义
图3:语义关系
- 经典示例:国王 - 男人 + 女人 ≈ 女王
- 向量运算能够捕捉复杂的语义关系
- 相似的语义关系有相似的向量偏移
计算: 国王 - 男人 + 女人 ≈ [1.9 1.9 0.8]
向量运算过程(逐元素计算):
-
第一步减法运算:国王 - 男人
- 第1维度:2.1 - 2.0 = 0.1
- 第2维度:1.8 - 1.2 = 0.6
- 第3维度:0.9 - 0.3 = 0.6 得到中间向量:[0.1, 0.6, 0.6]
-
第二步加法运算:中间向量 + 女人
- 第1维度:0.1 + 1.8 = 1.9
- 第2维度:0.6 + 1.3 = 1.9
- 第3维度:0.6 + 0.2 = 0.8 最终计算向量:[1.9, 1.9, 0.8]
- 验证结果:
- 计算得到的向量:[1.9, 1.9, 0.8]
- 实际女王向量:[1.9, 1.9, 0.8] 两者完全匹配!

三、多头自注意力机制
自注意力机制的核心思想:让序列中的每个词都与其他所有词进行交流,就是让模型联系上下文。
1. 基础原理
瞻前顾后、总览大局的理解方式,当我们读一句话时,我们不会孤立地看每个词。比如:“这只动物因为找不到水源而非常口渴,最终它用长长的鼻子从河里吸水解渴。”
当我们读到“它”和“长长的鼻子”时,大脑会瞬间联系到前面的动物很可能是一头大象。这种联系上下文的能力,就是注意力机制要做的。
2. 分步详解
第一步:自注意力
自注意力机制让句子中的每一个词都有机会与句子中的所有其他词进行交流,从而根据整个句子的语境来重新审视自己。
这个过程可以分解为三个角色:
- 查询(Query):代表“我是谁,我正在寻找什么”。(例如,“它”在问:“谁是我指代的对象?”)
- 键(Key):代表“我是谁,我有什么特点”。(例如,“动物”说:“我是一个名词”;“鼻子”说:“我是一个身体部位”)
- 值(Value):代表“我的实际内容或信息是什么”。(例如,“动物”的值就是它的词向量;“鼻子”的值是它的词向量)
工作流程(以“它”这个词为例):
1. 计算注意力分数:“它”的Query会去和句子中所有词(包括自己)的Key逐个进行匹配,并计算相似度。这个分数越高,说明两个词关联越紧密。
- “它”的Query 与 “动物”的Key 的分数会非常高。
- “它”的Query 与 “鼻子”的Key 的分数可能也比较高。
- “它”的Query 与 “水源”的Key 的分数会比较低。
2. Softmax归一化:将所有分数转换成一个概率分布,所有分数加起来等于1。这样,“动物”就会获得一个极高的权重,比如0.8;“鼻子”获得0.15;其他词分享剩下的0.05。
3. 加权求和:用这些权重,对所有词的Value进行加权求和。
- 求和得到的新的“它”值,值计算表示 = 0.8 * “动物”的Value + 0.15 * “鼻子”的Value + ...
结果:经过这个操作,“它”这个词的向量表示,就不再是它自己了,而是融入了强烈指代对象“动物”的信息,以及部分“鼻子”的信息。模型通过这种方式,“理解”了“它”指的是什么。
第二步:多头注意力
如果只做一次自注意力,模型可能只关注到一种关系,比如指代关系。但一个词在句中的关系是复杂的!
“多头”就像是一组“专家团队”,他们同时从不同角度分析同一句话。
- 头1(指代专家):专门关注“谁指代谁”。它帮“它”找到了“动物”。
- 头2(动作专家):专门关注“谁对谁做了什么”。它可能会让“吸”关注“鼻子”和“水”。
- 头3(修饰专家):专门关注“谁修饰谁”。它可能会让“长长的”关注“鼻子”。
...(可以有8个、12个甚至更多这样的“专家”)
每个专家独立进行一套自注意力计算,得到一个新的向量序列。最后,我们把所有专家的结果拼接起来,再通过一个线性层整合,就得到了最终的多头自注意力输出。
3. 作用与意义
- 作用:实现对输入序列的全局依赖建模,让每个词都能根据全文语境动态地更新自己的表示。
- 意义:
- 解决长距离依赖:无论两个词相隔多远,注意力机制都能直接建立联系,克服了传统RNN模型的遗忘问题。
- 实现并行计算:由于所有词对之间的注意力分数可以同时计算,极大地提升了训练速度。
- 可解释性:通过分析注意力权重大小,我们可以看到模型在生成一个词时更“关注”哪些输入词,这为理解模型的“思考”过程提供了窗口。
4. 可视化示例
4.1 多头自注意力机制可视化
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib.patches import Rectangle, FancyBboxPatch
import mathsns.set_style("whitegrid")
# 设置中文字体和样式
plt.rcParams['font.sans-serif'] = ['SimHei', 'Arial Unicode MS']
plt.rcParams['axes.unicode_minus'] = Falsedef visualize_attention():print("2. 多头自注意力机制可视化")# 示例句子和查询词sentence = "动物 喝 水 用 长鼻子"tokens = ["动物", "喝", "水", "用", "长鼻子"]query_word = "长鼻子"fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 5))# 子图1: 单头注意力机制ax1.set_title("单头注意力机制原理", fontsize=14, fontweight='bold', pad=20)# 绘制注意力计算过程y_positions = [0.8, 0.65, 0.5, 0.35, 0.2]# 显示所有词for i, (token, y) in enumerate(zip(tokens, y_positions)):color = "red" if token == query_word else "lightblue"ax1.text(0.1, y, token, ha='center', va='center', fontsize=12,bbox=dict(boxstyle="round,pad=0.3", facecolor=color))# 模拟注意力权重attention_weights = {"动物": 0.7, # "长鼻子"高度关注"动物""喝": 0.1,"水": 0.05, "用": 0.1,"长鼻子": 0.05 # 自己也有一点关注}# 绘制注意力连线query_y = y_positions[tokens.index(query_word)]for i, (token, weight) in enumerate(attention_weights.items()):if token != query_word:target_y = y_positions[tokens.index(token)]# 线宽反映注意力权重linewidth = weight * 10alpha = weightax1.plot([0.25, 0.45], [query_y, target_y], 'gray', linewidth=linewidth, alpha=alpha)ax1.text(0.5, target_y, f'{weight:.2f}', ha='left', va='center', fontsize=10)ax1.text(0.35, 0.9, f'查询词: "{query_word}"', ha='center', va='center', fontsize=12, bbox=dict(boxstyle="round,pad=0.3", facecolor="red"))ax1.set_xlim(0, 1)ax1.set_ylim(0, 1)ax1.axis('off')# 子图2: 多头注意力ax2.set_title("多头注意力: 不同专家关注不同方面", fontsize=14, fontweight='bold', pad=20)# 定义三个注意力头(专家)heads = {"指代专家": {"动物": 0.8, "喝": 0.1, "水": 0.05, "用": 0.05, "长鼻子": 0.0},"功能专家": {"动物": 0.2, "喝": 0.6, "水": 0.1, "用": 0.1, "长鼻子": 0.0},"部位专家": {"动物": 0.1, "喝": 0.1, "水": 0.1, "用": 0.2, "长鼻子": 0.5}}head_positions = [0.7, 0.5, 0.3]token_x_positions = [0.2, 0.35, 0.5, 0.65, 0.8]for (head_name, weights), y_pos in zip(heads.items(), head_positions):ax2.text(0.05, y_pos, head_name, ha='left', va='center', fontsize=11,bbox=dict(boxstyle="round,pad=0.2", facecolor="lightgreen"))# 为每个头绘制注意力热力图for i, (token, weight) in enumerate(weights.items()):color_intensity = weightax2.add_patch(Rectangle((token_x_positions[i]-0.04, y_pos-0.05), 0.08, 0.1, facecolor=plt.cm.Reds(color_intensity), alpha=0.7))ax2.text(token_x_positions[i], y_pos, f'{weight:.2f}', ha='center', va='center', fontsize=9,bbox=dict(boxstyle="round,pad=0.1", facecolor="white", alpha=0.8))# 显示token标签for i, token in enumerate(tokens):ax2.text(token_x_positions[i], 0.85, token, ha='center', va='center', fontsize=11, bbox=dict(boxstyle="round,pad=0.2", facecolor="lightblue"))ax2.text(0.5, 0.95, f'查询词: "{query_word}"', ha='center', va='center', fontsize=12, bbox=dict(boxstyle="round,pad=0.3", facecolor="red"))ax2.set_xlim(0, 1)ax2.set_ylim(0, 1)ax2.axis('off')plt.tight_layout()plt.show()# 运行注意力可视化
visualize_attention()
输出结果:
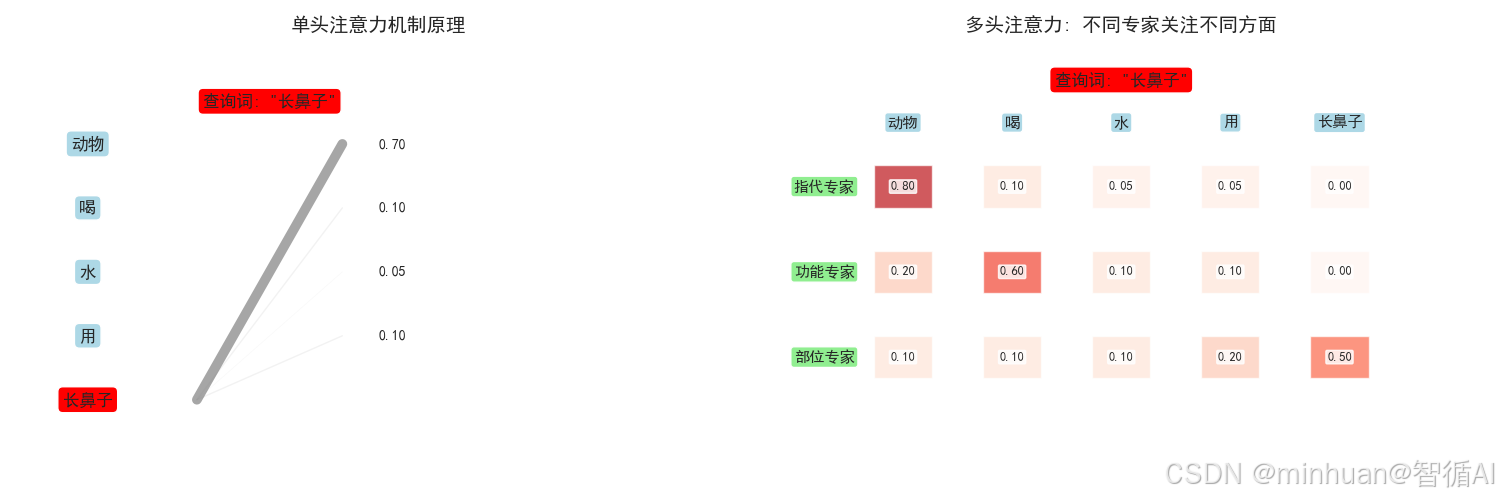
图例解析:
- 单头注意力: 计算每个词对其他所有词的关注程度
- 多头注意力: 多个'专家'从不同角度分析关系
- 指代专家: 关注'长鼻子'指的是什么 → 动物
- 功能专家: 关注'长鼻子'用来做什么 → 喝
- 部位专家: 关注'长鼻子'本身是什么 → 部位
4.3 多头自注意力机制详解
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np# 设置样式
plt.rcParams['font.sans-serif'] = ['SimHei'] # 支持中文显示
plt.rcParams['axes.unicode_minus'] = Falseclass MultiHeadAttention(nn.Module):"""多头自注意力机制"""def __init__(self, d_model, num_heads):super().__init__()self.d_model = d_modelself.num_heads = num_headsself.head_dim = d_model // num_headsassert self.head_dim * num_heads == d_model, "d_model必须能被num_heads整除"# 定义Q、K、V的线性变换self.w_q = nn.Linear(d_model, d_model)self.w_k = nn.Linear(d_model, d_model)self.w_v = nn.Linear(d_model, d_model)self.w_o = nn.Linear(d_model, d_model)def scaled_dot_product_attention(self, Q, K, V):"""缩放点积注意力"""d_k = Q.size(-1)# 计算注意力分数: Q * K^T / sqrt(d_k)scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(d_k)# Softmax得到注意力权重attention_weights = F.softmax(scores, dim=-1)# 加权求和output = torch.matmul(attention_weights, V)return output, attention_weightsdef forward(self, x):batch_size, seq_len, d_model = x.size()# 1. 线性变换得到Q、K、VQ = self.w_q(x)K = self.w_k(x)V = self.w_v(x)# 2. 重塑为多头Q = Q.view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)K = K.view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)V = V.view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)# 3. 计算注意力attn_output, attn_weights = self.scaled_dot_product_attention(Q, K, V)# 4. 合并多头attn_output = attn_output.transpose(1, 2).contiguous().view(batch_size, seq_len, d_model)# 5. 输出线性变换output = self.w_o(attn_output)return output, attn_weightsdef demonstrate_attention_workflow():"""演示注意力机制的工作流程"""print("\n1. 注意力机制核心概念演示")# 示例句子sentence = "猫 吃 鱼"words = sentence.split()print(f"示例句子: '{sentence}'")# 模拟简单的词向量word_vectors = {"猫": [1.0, 0.2, 0.1, 0.8],"吃": [0.3, 1.0, 0.2, 0.1], "鱼": [0.1, 0.1, 1.0, 0.9]}# 计算注意力分数(以"吃"为中心)query = np.array(word_vectors["吃"]) # "吃"在寻找什么attention_scores = {}for word, vector in word_vectors.items():score = np.dot(query, vector) # 点积相似度attention_scores[word] = score# 应用softmaxscores = list(attention_scores.values())softmax_scores = np.exp(scores) / np.sum(np.exp(scores))print("\n注意力计算过程:")for i, word in enumerate(attention_scores.keys()):print(f" '吃' 关注 '{word}': 原始分数={scores[i]:.3f}, 权重={softmax_scores[i]:.3f}")return words, word_vectors, attention_scores, softmax_scoresdef create_sample_data():"""创建示例数据"""# 创建一个有意义的句子来展示注意力模式sentence = "猫 在 桌子 上 吃 鱼"words = sentence.split()# 参数设置d_model = 8num_heads = 4batch_size = 1seq_len = len(words)# 创建模拟输入(使用随机但可控的数据)torch.manual_seed(42) # 固定随机种子以便重现x = torch.randn(batch_size, seq_len, d_model)return sentence, words, x, d_model, num_headsdef visualize_multihead_attention():"""可视化多头注意力的核心概念"""# 创建示例数据sentence, words, x, d_model, num_heads = create_sample_data()print(f"\n2. 多头注意力完整示例")print(f"句子: '{sentence}'")print(f"参数: d_model={d_model}, num_heads={num_heads}")print(f"输入形状: {x.shape}")# 创建多头注意力层multihead_attn = MultiHeadAttention(d_model, num_heads)# 前向传播output, all_attn_weights = multihead_attn(x)print(f"输出形状: {output.shape}")print(f"注意力权重形状: {all_attn_weights.shape}") # [batch, heads, seq_len, seq_len]# 图1: 展示不同注意力头的关注模式print("\n生成图1: 多头注意力模式对比")visualize_attention_heads(all_attn_weights[0], words, "图1: 不同注意力头的关注模式")# 图2: 展示计算流程图print("生成图2: 多头注意力计算流程")visualize_computation_flow(d_model, num_heads, len(words))# 图3: 展示平均注意力权重print("生成图3: 综合注意力模式")visualize_average_attention(all_attn_weights[0], words,"图3: 综合注意力模式(所有头平均)")return output, all_attn_weightsdef visualize_attention_heads(attn_weights, words, title):"""图1: 展示不同注意力头的关注模式"""num_heads = attn_weights.shape[0]fig, axes = plt.subplots(2, 2, figsize=(12, 10))axes = axes.ravel()for i in range(num_heads):sns.heatmap(attn_weights[i].detach().numpy(),xticklabels=words,yticklabels=words,cmap="YlGnBu", ax=axes[i],cbar=True, annot=True, fmt=".2f",vmin=0, vmax=1)axes[i].set_title(f'注意力头 {i+1}')plt.suptitle(title, fontsize=14, fontweight='bold')plt.tight_layout()plt.show()def visualize_computation_flow(d_model, num_heads, seq_len):"""图2: 多头注意力计算流程图"""head_dim = d_model // num_headsfig, ax = plt.subplots(figsize=(10, 8))# 定义流程步骤steps = [f"输入\n形状: ({seq_len}, {d_model})",f"线性变换 Q/K/V\n生成3个({seq_len}, {d_model})矩阵", f"分割多头\n分成{num_heads}个({seq_len}, {head_dim})头",f"缩放点积注意力\n{num_heads}个头并行计算",f"合并多头\n合并为({seq_len}, {d_model})",f"输出线性变换\n最终输出({seq_len}, {d_model})"]# 绘制流程图y_pos = [5, 4, 3, 2, 1, 0]colors = ['#E1F5FE', '#F3E5F5', '#E8F5E8', '#FFF3E0', '#FBE9E7', '#EFEBE9']for i, (step, y, color) in enumerate(zip(steps, y_pos, colors)):ax.text(0, y, step, bbox=dict(boxstyle="round,pad=0.5", facecolor=color, alpha=0.8),ha='center', va='center', fontsize=11, fontweight='bold')if i < len(steps) - 1:ax.arrow(0, y-0.3, 0, -0.4, head_width=0.1, head_length=0.1, fc='gray', ec='gray', linewidth=2)ax.set_xlim(-1.5, 1.5)ax.set_ylim(-0.5, 5.5)ax.set_title("图2: 多头注意力计算流程图", fontsize=14, fontweight='bold')ax.axis('off')# 添加关键说明key_points = ["关键特点:","• 并行计算: 多个头同时工作","• 特征分解: 每个头关注不同特征", "• 信息融合: 最后整合所有信息","• 可扩展性: 头数可灵活调整"]ax.text(1.0, 2.5, '\n'.join(key_points), fontsize=10, bbox=dict(boxstyle="round,pad=0.5", facecolor="lightyellow"),va='center')plt.tight_layout()plt.show()def visualize_average_attention(attn_weights, words, title):"""图3: 综合注意力模式(所有头平均)"""avg_attn = torch.mean(attn_weights, dim=0) # 平均所有头plt.figure(figsize=(8, 6))sns.heatmap(avg_attn.detach().numpy(),xticklabels=words,yticklabels=words,cmap="YlGnBu", annot=True, fmt=".3f",cbar_kws={'label': '注意力权重'})plt.title(title, fontsize=14, fontweight='bold')plt.xlabel("被关注的词")plt.ylabel("关注源词")plt.tight_layout()plt.show()# 运行主程序
if __name__ == "__main__":# 演示基础概念words, word_vectors, attention_scores, softmax_scores = demonstrate_attention_workflow()print("\n" + "="*60)# 可视化多头注意力output, all_weights = visualize_multihead_attention()输出结果:
1. 注意力机制核心概念演示
示例句子: '猫 吃 鱼'注意力计算过程:
'吃' 关注 '猫': 原始分数=0.600, 权重=0.282
'吃' 关注 '吃': 原始分数=1.140, 权重=0.483
'吃' 关注 '鱼': 原始分数=0.420, 权重=0.235============================================================
2. 多头注意力完整示例
句子: '猫 在 桌子 上 吃 鱼'
参数: d_model=8, num_heads=4
输入形状: torch.Size([1, 6, 8])
输出形状: torch.Size([1, 6, 8])
注意力权重形状: torch.Size([1, 4, 6, 6])
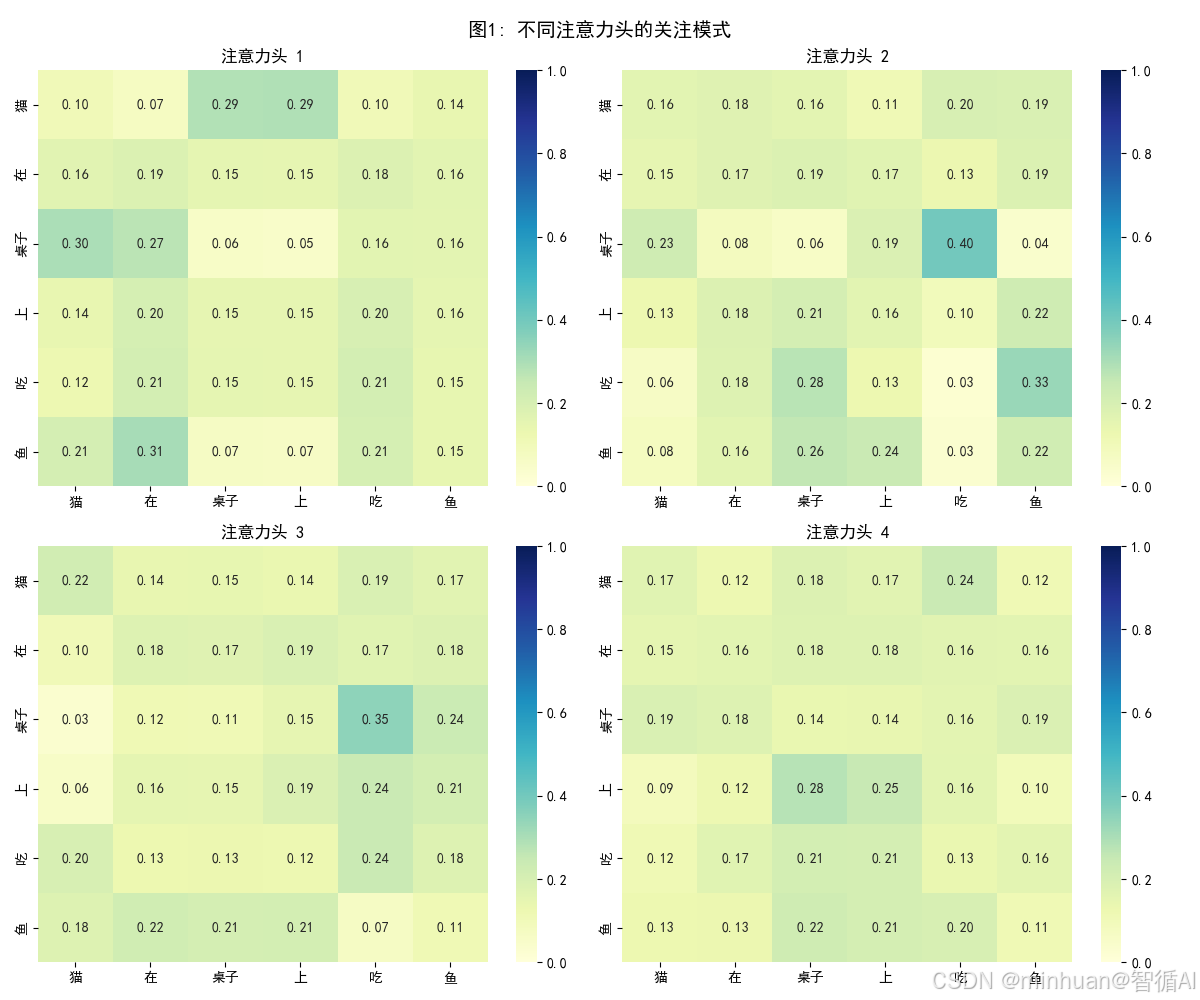
图1: 多头注意力模式对比
- 意义:展示4个不同注意力头学习到的不同关注模式
- 头1:可能关注局部相邻关系(词与相邻词的关系)
- 头2:可能关注动词-宾语关系("吃"→"鱼")
- 头3:可能关注位置关系("在"→"桌子上")
- 头4:可能关注主语关系("猫"→"吃")
- 价值:直观展示"多头"的价值——每个头自动成为不同语言关系的专家
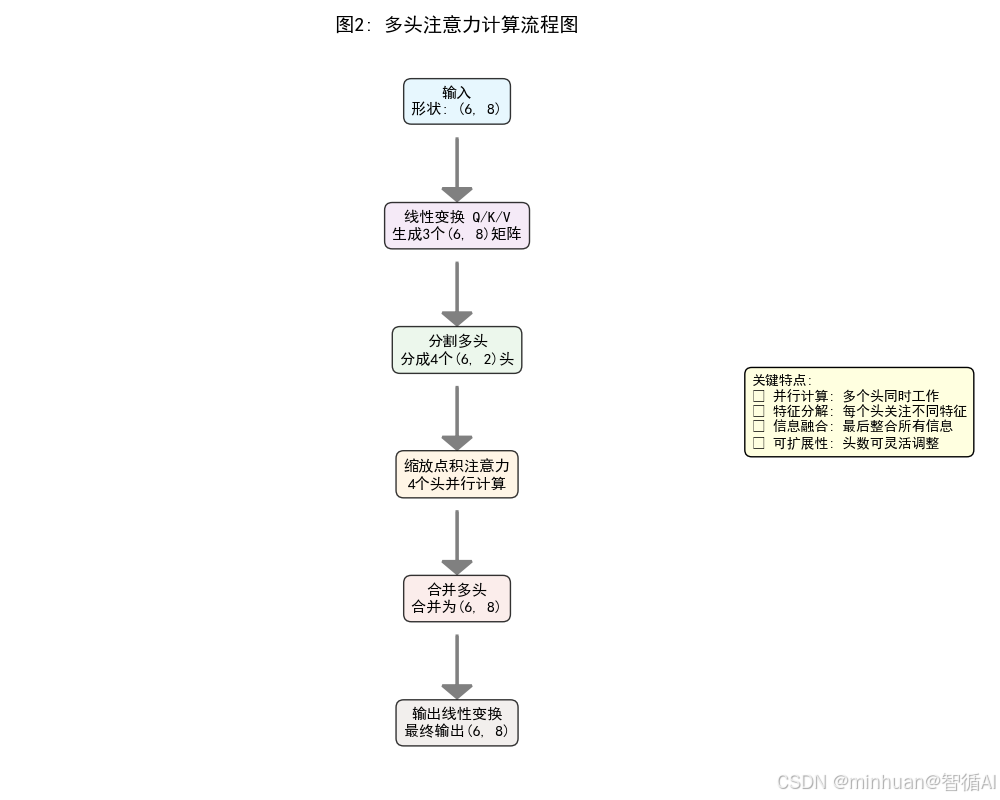
图2: 多头注意力计算流程图
- 意义:展示完整的计算过程,6个关键步骤:
- 1. 输入向量
- 2. 线性变换生成Q/K/V
- 3. 分割成多个头
- 4. 各头并行计算注意力
- 5. 合并多头输出
- 6. 最终线性变换
- 价值:理解多头注意力的"分而治之"策略和并行计算优势大大提高了效率
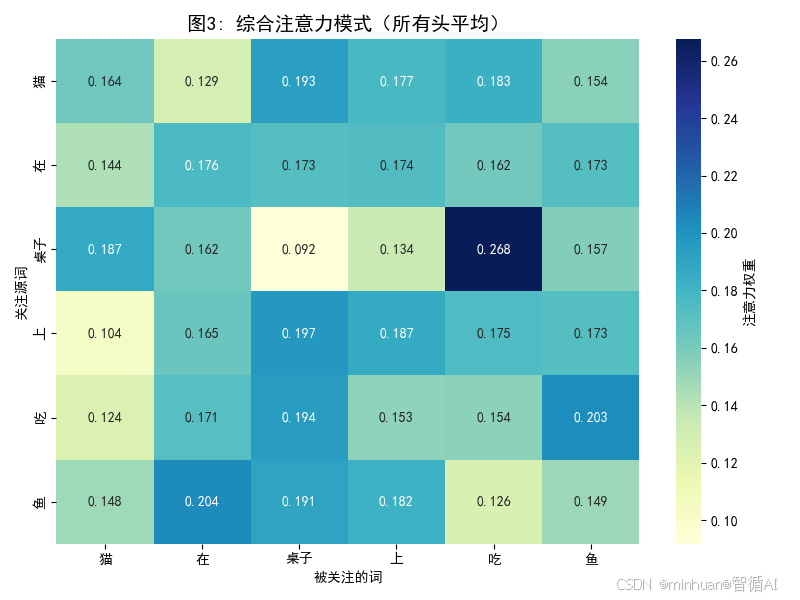
图3: 综合注意力模式
- 意义:展示所有头的平均效果,反映整体理解
- 清晰的语法关系:"吃"强烈关注"鱼"(动词-宾语)
- 位置关系:"在"关注"桌子上"
- 主语关系:"猫"关注"吃"
- 价值:显示模型如何综合多个专家的意见形成对句子的整体理解
四、前馈网络层
经过多头自注意力的广泛联系后,模型获得了一组富含上下文信息的新向量。接下来,需要对这些信息进行深度加工,这就是前馈网络层的工作,指导让模型如何深度思考。
1. 基础原理
好比一个微型消化器,我们可以把前馈网络层想象成我们大脑中负责深入思考的区域,注意力机制负责搜集信息,看到了什么,听到了什么,而前馈网络则负责理解这些信息的深层含义和模式。
2. 结构详解
前馈网络是一个非常简单的神经网络,就像一个两层的万能函数拟合器,它对每个词的向量进行独立处理。其经典结构是:
输入 -> 全连接层1 (扩大维度) -> 激活函数 (如ReLU/GELU) -> 全连接层2 (缩小回原维度) -> 输出
- 全连接层:层中的每个神经元都与上一层的所有输出相连。它可以对输入向量进行任意的线性变换和非线性组合。
- 激活函数(如ReLU):这是引入非线性的关键。如果没有它,无论堆叠多少层,整个网络都等价于一个线性变换,无法学习复杂模式。ReLU就像一个过滤器,它让正数通过,将负数变为零。ReLU(x) = max(0, x)
- 维度变化:通常先扩大维度,例如从512维扩大到2048维,提供一个更宽敞的“工作空间”来进行复杂的特征变换,然后再投影回原始维度,以便与下一层衔接。
3. 直观解释
假设经过注意力层后,代表“银行”的词向量,同时包含了“钱”和“河”的混合信息。
前馈网络的工作:它会分析这个混合向量。如果上下文是“我去银行存钱”,它会抑制与“河”相关的神经元,激活与“金融机构”相关的神经元,从而输出一个更偏向“金融机构”含义的“银行”向量。反之亦然。
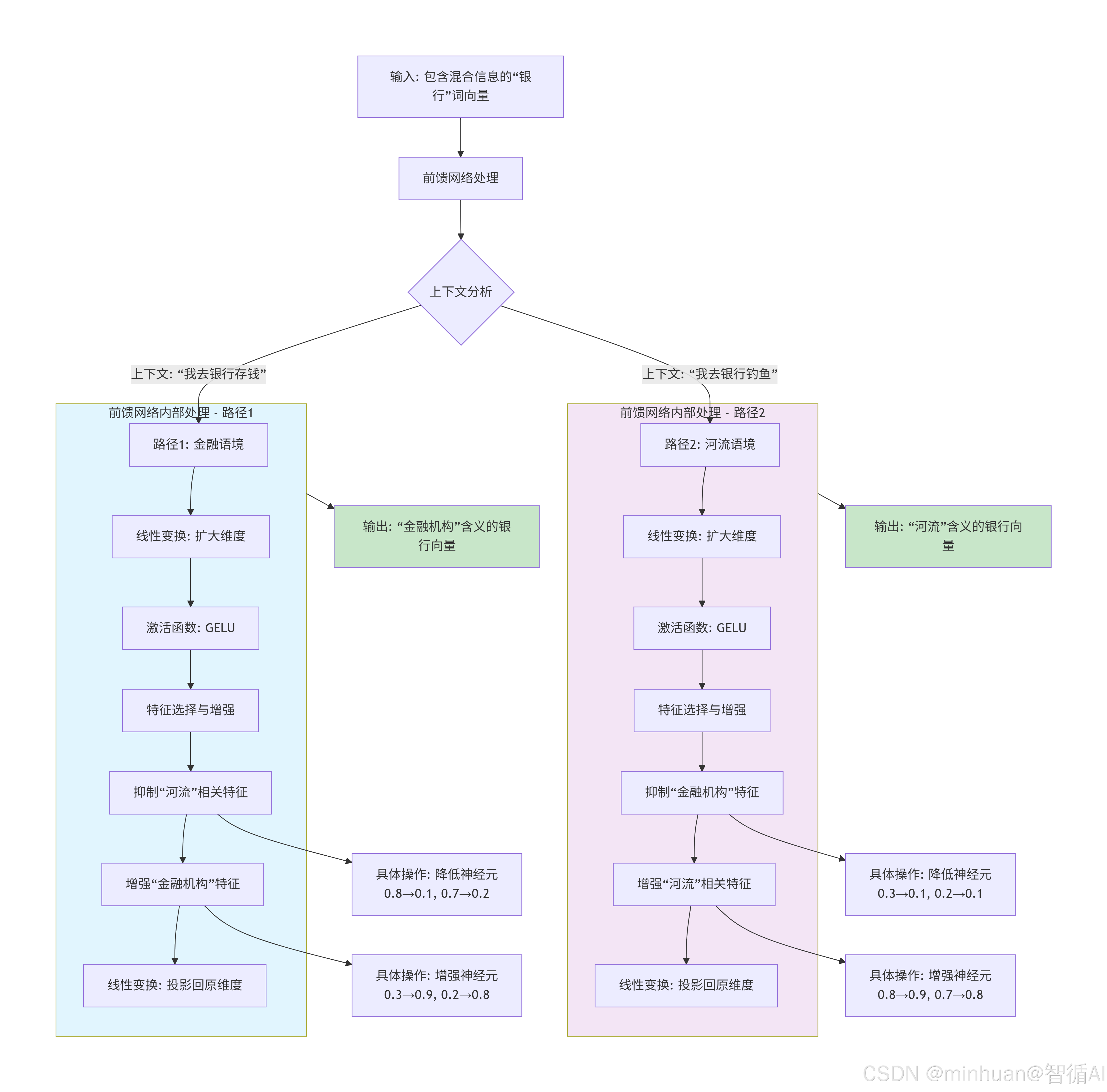
流程图关键步骤解释:
- 1. 输入阶段:注意力层输出的"银行"向量包含混合特征
- 金融机构特征:[存款:0.3, 贷款:0.2, 利息:0.4...]
- 河流特征:[水流:0.8, 河岸:0.7, 钓鱼:0.6...]
- 2. 上下文分析:前馈网络根据上下文选择处理路径
- 路径1:"我去银行存钱" → 金融语境
- 路径2:"我去银行钓鱼" → 河流语境
- 3. 特征处理(以路径1为例):
- 扩大维度:从d_model扩展到d_ff(如512→2048)
- 非线性变换:通过GELU激活函数引入非线性
- 特征选择:抑制河流相关神经元,增强金融机构神经元
- 维度还原:投影回原始维度
- 4. 输出结果:
- 路径1输出:清晰的金融机构含义向量
- 路径2输出:清晰的河流含义向量
这个过程体现了前馈网络作为语境消歧器的作用,通过非线性变换和特征选择来解决多义词的歧义问题。
4. 作用与意义
- 作用:对自注意力层输出的、已经富含上下文信息的表示,进行一步非线性变换,以提取更抽象、更复杂的特征。
- 意义:
- 提供非线性能力:这是深度学习模型能够拟合极其复杂函数的核心。
- 独立处理:对每个位置独立处理,效率极高,易于并行。
- 层级特征提取:与注意力机制配合,形成了“广泛联系”与“深度加工”的完美分工,共同构建出对语言的深层理解。
5. 可视化示例
5.1 前馈网络层 (FFN) 可视化
- 网络结构: 展示典型的"输入→隐藏层→输出"的三层结构
- 维度变化: 隐藏层扩大维度提供"思考空间",输出层恢复原维度
- 实际作用: 以前馈网络消歧多义词"银行"为例,展示其信息处理能力
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib.patches import Rectangle, FancyBboxPatch
import mathsns.set_style("whitegrid")
# 设置中文字体和样式
plt.rcParams['font.sans-serif'] = ['SimHei', 'Arial Unicode MS']
plt.rcParams['axes.unicode_minus'] = Falsedef visualize_feed_forward():print("3. 前馈网络层 (FFN) 可视化")fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(16, 8))# 子图1: FFN结构ax1.set_title("前馈网络层结构", fontsize=14, fontweight='bold', pad=20)# 绘制神经网络结构layer_sizes = [4, 8, 4] # 输入层 -> 隐藏层 -> 输出层# 输入层input_y = np.linspace(0.1, 0.9, layer_sizes[0])for i, y in enumerate(input_y):ax1.add_patch(plt.Circle((0.2, y), 0.03, color='lightblue', ec='black'))if i == 0:ax1.text(0.2, y+0.08, "输入向量", ha='center', va='center', fontsize=10)# 隐藏层 (扩大维度)hidden_y = np.linspace(0.05, 0.95, layer_sizes[1])for i, y in enumerate(hidden_y):ax1.add_patch(plt.Circle((0.5, y), 0.03, color='lightgreen', ec='black'))if i == 0:ax1.text(0.5, 1.05, "隐藏层\n(扩大维度)", ha='center', va='center', fontsize=10)# 输出层output_y = np.linspace(0.1, 0.9, layer_sizes[2])for i, y in enumerate(output_y):ax1.add_patch(plt.Circle((0.8, y), 0.03, color='lightcoral', ec='black'))if i == 0:ax1.text(0.8, y+0.08, "输出向量", ha='center', va='center', fontsize=10)# 绘制连接线for i, y_in in enumerate(input_y):for j, y_hid in enumerate(hidden_y):ax1.plot([0.23, 0.47], [y_in, y_hid], 'gray', alpha=0.3, linewidth=0.5)for i, y_hid in enumerate(hidden_y):for j, y_out in enumerate(output_y):ax1.plot([0.53, 0.77], [y_hid, y_out], 'gray', alpha=0.3, linewidth=0.5)# 标注激活函数ax1.text(0.35, 0.5, "ReLU激活\n函数", ha='center', va='center', fontsize=10,bbox=dict(boxstyle="round,pad=0.3", facecolor="yellow"))ax1.set_xlim(0, 1)ax1.set_ylim(0, 1.1)ax1.axis('off')# 子图2: FFN作用示例ax2.set_title("前馈网络的信息处理作用", fontsize=14, fontweight='bold', pad=20)# 示例:多义词"银行"的消歧contexts = ["我去银行存钱","我在河边银行散步"]# 输入表示 (混合了多种含义)mixed_input = [0.5, 0.5] # [金融机构含义强度, 河流含义强度]# FFN处理后的输出processed_outputs = [[0.9, 0.1], # 上下文1: 强调金融机构含义[0.1, 0.9] # 上下文2: 强调河流含义]# 绘制处理过程y_pos = 0.7for i, (context, output) in enumerate(zip(contexts, processed_outputs)):ax2.text(0.1, y_pos, context, ha='left', va='center', fontsize=11,bbox=dict(boxstyle="round,pad=0.2", facecolor="lightgray"))# 输入状态ax2.text(0.5, y_pos+0.05, "输入:", ha='left', va='center', fontsize=10)ax2.barh([y_pos], [mixed_input[0]], height=0.03, color='blue', alpha=0.6, label='金融机构')ax2.barh([y_pos], [mixed_input[1]], height=0.03, left=[mixed_input[0]], color='green', alpha=0.6, label='河流')# 箭头ax2.text(0.65, y_pos, '→', ha='center', va='center', fontsize=20)# 输出状态ax2.text(0.8, y_pos+0.05, "FFN输出:", ha='left', va='center', fontsize=10)ax2.barh([y_pos-0.05], [output[0]], height=0.03, color='blue', alpha=0.8)ax2.barh([y_pos-0.05], [output[1]], height=0.03, left=[output[0]], color='green', alpha=0.8)y_pos -= 0.25# 添加图例ax2.barh([0.1], [0], height=0, color='blue', alpha=0.8, label='金融机构含义')ax2.barh([0.1], [0], height=0, color='green', alpha=0.8, label='河流含义')ax2.legend(loc='lower center', bbox_to_anchor=(0.5, 0.02), ncol=2)ax2.set_xlim(0, 1)ax2.set_ylim(0, 0.8)ax2.axis('off')plt.tight_layout()plt.show()# 运行前馈网络可视化
visualize_feed_forward()输出结果:
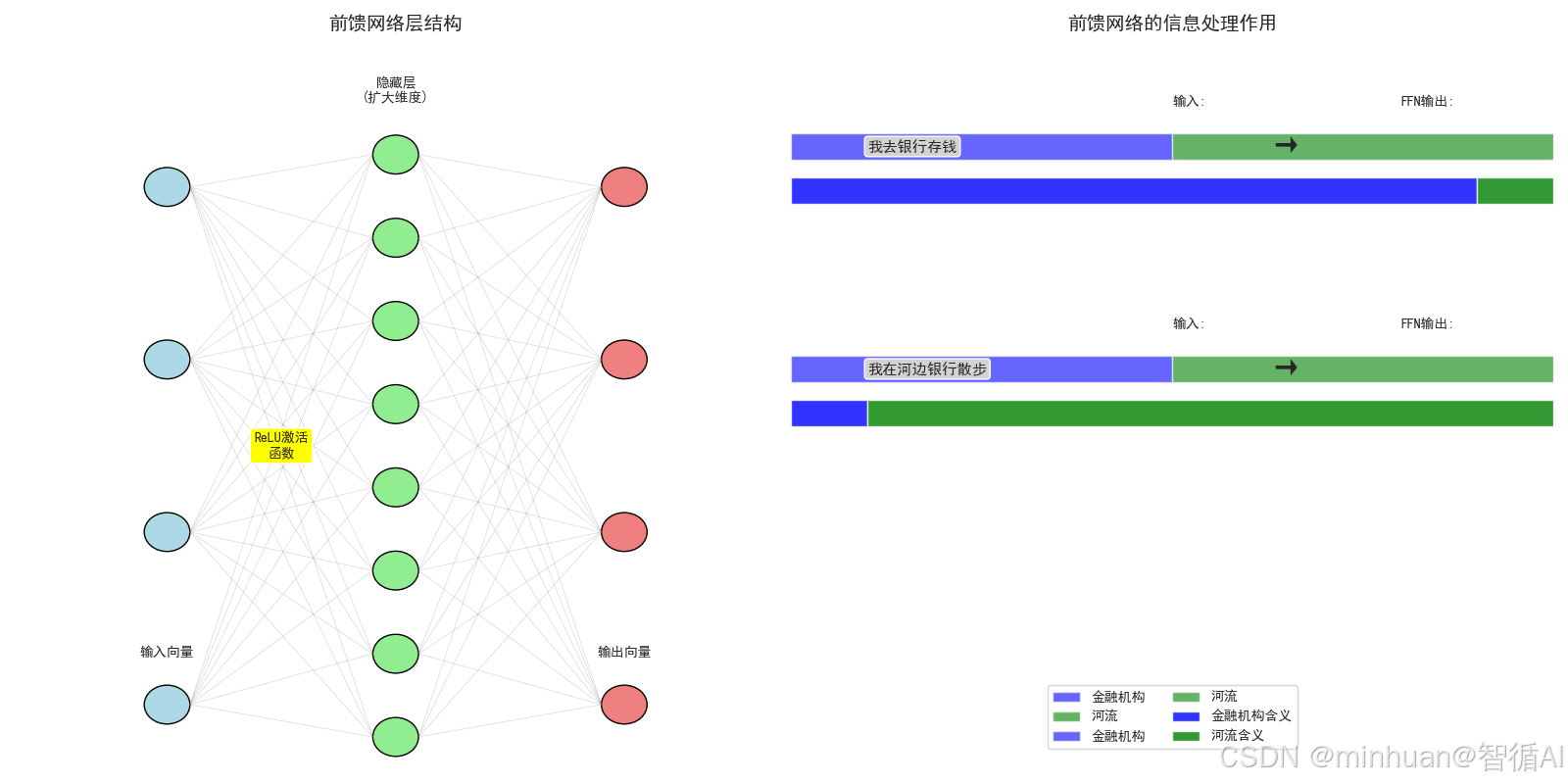
- 结构: 输入层 → 隐藏层(扩大) → 输出层(缩小)
- 作用: 对注意力层的输出进行非线性变换和深度处理
- 示例: 根据上下文消歧多义词'银行'的含义
- - 金融上下文: 抑制'河流'含义,增强'金融机构'含义
- - 地理上下文: 抑制'金融机构'含义,增强'河流'含义
5.2 前馈网络层核心作用演示
import numpy as np
import matplotlib.pyplot as plt# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei', 'Arial Unicode MS']
plt.rcParams['axes.unicode_minus'] = Falsedef simple_feed_forward_demo():print("前馈网络层核心作用演示:语义消歧")print("=" * 50)# 模拟输入:多义词"苹果"的混合语义向量# 向量维度含义: [科技产品特征, 水果特征, 公司品牌特征, 其他特征]apple_vector = np.array([0.6, 0.6, 0.3, 0.1]) # 初始包含多种含义print(f"输入向量 ('苹果'的原始混合表示): {apple_vector}")print("维度含义: [科技特征, 水果特征, 品牌特征, 其他特征]")print()# 前馈网络权重矩阵 (模拟学习到的知识)# 第一层:扩大维度进行特征变换W1 = np.array([[0.8, -0.2, 0.1, 0.1], # 科技上下文神经元[-0.1, 0.9, -0.1, 0.2], # 水果上下文神经元 [0.2, -0.1, 0.7, 0.1], # 品牌上下文神经元[0.3, 0.4, 0.2, 0.8] # 通用特征神经元])b1 = np.array([0.1, 0.1, 0.1, 0.1])# 第二层:整合信息,输出消歧后的表示W2 = np.array([[0.9, -0.8, 0.2, 0.1], # 强化主要语义,抑制次要语义[-0.8, 0.9, -0.1, 0.2],[0.1, -0.2, 0.8, -0.1],[0.1, 0.1, 0.1, 0.6]])b2 = np.array([0.05, 0.05, 0.05, 0.05])def relu(x):return np.maximum(0, x)def feed_forward(x, context_type):print(f"\n--- 上下文: '{context_type}' ---")# 第一层前向传播hidden = np.dot(W1, x) + b1hidden_activated = relu(hidden)print(f"隐藏层输出: {hidden_activated}")# 根据上下文调整第二层权重if context_type == "科技产品":W2_context = W2 * np.array([1.2, 0.3, 0.8, 1.0]) # 强化科技特征elif context_type == "水果":W2_context = W2 * np.array([0.3, 1.2, 0.3, 1.0]) # 强化水果特征else: # 公司品牌W2_context = W2 * np.array([0.8, 0.3, 1.2, 1.0]) # 强化品牌特征# 第二层前向传播output = np.dot(W2_context, hidden_activated) + b2output_normalized = relu(output) / np.sum(relu(output)) # 简单归一化return output_normalized# 测试不同上下文contexts = [("科技产品", "我刚买了新的苹果手机"),("水果", "我今天吃了一个红苹果"), ("公司品牌", "苹果公司发布了财报")]results = []for context_type, sentence in contexts:output = feed_forward(apple_vector, context_type)results.append((context_type, sentence, output))print(f"句子: '{sentence}'")print(f"输出向量: {output}")print(f"语义解析: 科技{output[0]:.1%} 水果{output[1]:.1%} 品牌{output[2]:.1%} 其他{output[3]:.1%}")print()# 可视化结果visualize_results(results)def visualize_results(results):fig, ax = plt.subplots(1, 1, figsize=(12, 6))categories = ['科技特征', '水果特征', '品牌特征', '其他特征']contexts = [result[0] for result in results]# 创建堆叠条形图bottom = np.zeros(len(contexts))colors = ['#FF6B6B', '#4ECDC4', '#45B7D1', '#F9C80E']for i in range(4):values = [result[2][i] for result in results]ax.bar(contexts, values, bottom=bottom, label=categories[i], color=colors[i], alpha=0.8, edgecolor='white')bottom += valuesax.set_ylabel('语义强度', fontsize=12)ax.set_title('前馈网络语义消歧效果演示', fontsize=14, fontweight='bold', pad=20)ax.legend()# 在柱子上添加数值for i, context in enumerate(contexts):total_height = 0for j in range(4):value = results[i][2][j]if value > 0.1: # 只显示较大的值ax.text(i, total_height + value/2, f'{value:.0%}', ha='center', va='center', fontweight='bold', color='white')total_height += valueplt.tight_layout()plt.show()# 运行演示
simple_feed_forward_demo()输出结果:
前馈网络层核心作用演示:语义消歧
==================================================
输入向量 ('苹果'的原始混合表示): [0.6 0.6 0.3 0.1]
维度含义: [科技特征, 水果特征, 品牌特征, 其他特征]
--- 上下文: '科技产品' ---
隐藏层输出: [0.5 0.57 0.38 0.66]
句子: '我刚买了新的苹果手机'
输出向量: [0.41831951 0. 0.18247386 0.39920664]
语义解析: 科技41.8% 水果0.0% 品牌18.2% 其他39.9%
--- 上下文: '水果' ---
隐藏层输出: [0.5 0.57 0.38 0.66]
句子: '我今天吃了一个红苹果'
输出向量: [0. 0.55194698 0. 0.44805302]
语义解析: 科技0.0% 水果55.2% 品牌0.0% 其他44.8%
--- 上下文: '公司品牌' ---
隐藏层输出: [0.5 0.57 0.38 0.66]
句子: '苹果公司发布了财报'
输出向量: [0.32271125 0. 0.26587688 0.41141186]
语义解析: 科技32.3% 水果0.0% 品牌26.6% 其他41.1%
在这个示例中:
- 同一个词"苹果"在不同上下文中获得不同的语义强调
- 前馈网络像是一个"语义过滤器",根据上下文调整特征权重
- 输出向量直接反映了模型对词语在当前语境下的理解
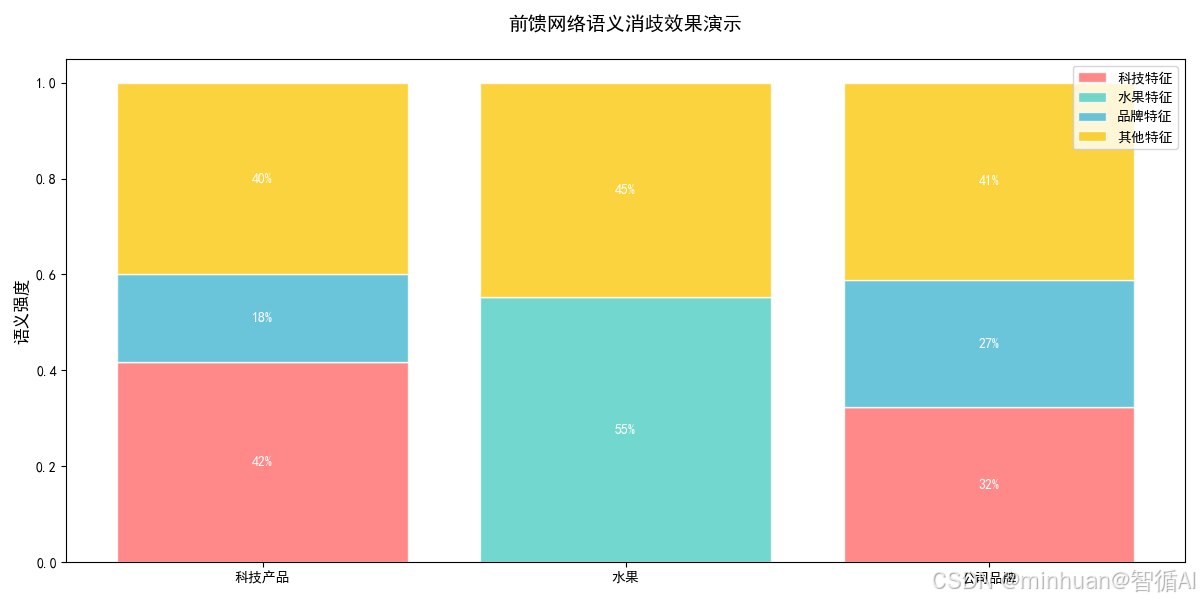
前馈网络核心作用总结:
- 接收注意力层的上下文信息
- 通过非线性变换进行深度处理
- 根据上下文强化相关特征,抑制无关特征
- 输出经过消歧的精确语义表示
五、总结:三者的协同工作
我们可以用一个阅读理解的比喻来总结这三个核心组件:
- 输入编码:为模型提供数字化的阅读材料,就像我们把一篇文章翻译成你能理解的语言,并用荧光笔标出了每个词的位置。
- 多头自注意力机制:让模型联系上下文理解关系,就像我们反复精读这篇文章。第一遍关注“人物关系”,第二遍关注“事件发展”,第三遍关注“情感表达”... 我们把所有信息联系起来,形成了对文章的整体理解。
- 前馈网络层:让模型深度思考提炼含义,就像我们闭目沉思,消化刚才读到的内容,提炼出文章的中心思想和深层含义。
这种架构让大模型具备了强大的语言理解能力,在大模型中,编码器(如BERT)或解码器(如GPT)就是由许多个多头自注意力层 + 前馈网络层堆叠而成的。输入编码进入这个堆叠结构,数据每经过一层,就被理解和消化得更深一层,最终产生强大的语言能力。
