Redis 底层运行机制与原理浅析
文章目录
- 一、核心架构:事件驱动与单线程模型
- 二、内存数据结构与动态编码
- 三、内存管理与碎片整理
- 1. 内存分配器
- 2. 内存淘汰策略
- 3. 主动碎片整理(Active Defrag)
- 四、持久化机制:RDB 与 AOF
- 1. RDB(快照持久化)
- 2. AOF(日志持久化)
- 五、复制与集群架构
- 1. 主从复制流程
- 2. 集群(Cluster)原理
- 六、高级特性实现
- 1. Lua 脚本引擎
- 2. I/O 多线程(Redis 6.0+)
- 3. 模块系统
- 总结
一、核心架构:事件驱动与单线程模型
Redis 采用 单线程事件驱动架构,通过 epoll/kqueue 实现 I/O 多路复用。其核心事件循环(aeEventLoop)持续监听两类事件:
- 文件事件:Socket 可读/可写状态(客户端请求/响应)
- 时间事件:定时任务(如过期键清理、持久化触发)
工作流程:主线程通过 epoll_wait() 等系统调用获取就绪事件 → 调用对应处理器(如 readQueryFromClient 解析命令)→ 执行命令 → 返回结果。这种设计避免了多线程锁竞争,但需确保单线程操作高效。
二、内存数据结构与动态编码
Redis 通过 redisObject 结构统一管理数据,其字段包括:
- type:数据类型(String/List 等)
- encoding:内部编码(如 ziplist/hashtable)
- lru:LRU 时间戳(内存淘汰用)
- refcount:引用计数(内存回收依据)
- ptr:指向实际数据的指针
动态编码优化策略:
| 数据类型 | 编码方式 | 触发条件 | 性能特点 |
|---|---|---|---|
| String | int/embstr/raw | 整数 → int;≤44字节 → embstr;大对象 → raw | embstr 减少内存分配次数 |
| List | quicklist | Redis 3.2+ 替代 ziplist/linkedlist,由 ziplist 节点+双向链表组成 | 平衡内存与操作效率 |
| Hash | ziplist/hashtable | 元素少且值小 → ziplist;超阈值 → hashtable | 节省小对象内存 |
| Set | intset/hashtable | 全为整数 → intset;否则 → hashtable | 整数集合压缩存储 |
| ZSet | ziplist/skiplist | 元素少且分数小 → ziplist;否则 → skiplist | 跳表支持快速范围查询 |
| Stream | radix tree + listpack | 基数树索引消息 ID,listpack 存储消息内容 | 高效支持消息遍历 |
编码转换:当数据量超过阈值(如 ziplist 大小 > hash-max-ziplist-entries)时自动切换编码。
三、内存管理与碎片整理
1. 内存分配器
默认使用 jemalloc,其优势:
- 按内存大小分级(small/large/huge)分配
- 减少外部碎片,碎片率通常 ≈1.03
- 支持后台线程异步释放内存(Lazy Free)
2. 内存淘汰策略
当达到 maxmemory 限制时触发:
- LRU/LFU 近似算法:随机采样 5 个键(maxmemory-samples配置),淘汰最符合策略的键
- LFU 实现:用概率计数器记录访问频率,并随时间衰减
3. 主动碎片整理(Active Defrag)
- 触发:碎片率 > active-defrag-threshold-lower(默认 10%)
- 过程:扫描内存 → 复制碎片化对象到新位置 → 释放原内存
- 限制:需配合 jemalloc,每周期 CPU 占用 ≤ active-defrag-cycle-max(默认 25%)
四、持久化机制:RDB 与 AOF
1. RDB(快照持久化)
- 流程:fork() 子进程 → 子进程遍历内存生成 RDB 文件 → 替换旧文件
- COW 优化:父进程继续处理请求,仅当内存页被修改时复制
- 触发:save(阻塞)、bgsave(后台)、配置自动触发(如 save 900 1)
2. AOF(日志持久化)
- 流程:所有写命令追加到 AOF 缓冲区 → 根据策略(always/everysec/no)同步至磁盘
- 重写:fork() 子进程生成精简版 AOF(只保留当前数据状态)
- 混合持久化(Redis 4.0+):AOF 重写时嵌入 RDB 格式头,加速恢复
性能对比:
| 特性 | RDB | AOF |
|---|---|---|
| 文件大小 | 小(二进制) | 大(文本命令) |
| 恢复速度 | 快 | 慢 |
| 数据安全 | 可能丢失快照间数据 | 最多丢失 1 秒数据 |
五、复制与集群架构
1. 主从复制流程
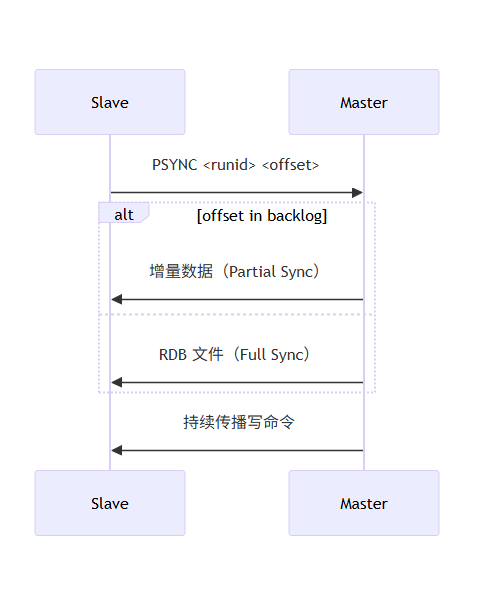
- 复制积压缓冲区:主节点维护环形缓冲区(默认 1MB),保存近期写命令
- 无磁盘复制:RDB 数据直接流式传输到从节点,跳过磁盘 I/O(repl-diskless-sync yes)
2. 集群(Cluster)原理
- 分片机制:16384 个哈希槽均匀分布到节点
- Gossip 协议:节点间定期交换状态(PING/PONG/MEET/FAIL 消息)
- 故障转移:当主节点下线,从节点发起投票选举新主节点
六、高级特性实现
1. Lua 脚本引擎
- 原子性:单线程执行脚本期间阻塞其他命令
- 执行环境:伪客户端模式调用 Redis 命令
- 复制:主节点传播 EVALSHA + 脚本 SHA1,从节点通过 repl_scriptcache_dict 缓存
2. I/O 多线程(Redis 6.0+)
- 线程分工:I/O 线程负责网络读写,主线程执行命令
- 配置:io-threads 4 启用线程,io-threads-do-reads yes 启用读线程化
- 效果:吞吐量提升 2 倍,但命令仍串行执行保证正确性
3. 模块系统
- 加载:MODULE LOAD /path/to/module.so
- API:RedisModule_CreateCommand 注册新命令
- 交互:通过模块 API 访问核心数据结构(如 RedisModule_StringSet)
总结
Redis 的底层运行机制是一个精心设计的系统工程:
-
以内存为核心,提供了极快的访问速度。
-
精巧的数据结构,在速度与内存之间取得了最佳平衡。
-
单线程 Reactor 模型,避免了并发复杂性,配合 I/O 多路复用轻松应对高并发。
-
灵活可配的持久化方案(RDB, AOF, 混合),满足了不同场景下的数据安全需求。
-
渐进式的优化策略(渐进式 rehash、惰性删除、后台线程化),保证了服务的平滑运行。