Qwen多模态模型全解析
目录
1 qw-vl
1.1 命令解析与注意事项
1.2 API请求示例
2 qw-image
2.1 使用原生方式,需要显存较多
2.2 使用comfyui,显存占用少
1 qw-vl
qw-vl 视觉模型可以识别图片以及视频,目前已经支持vllm和sglang运行
https://github.com/QwenLM/Qwen3-VL
https://docs.vllm.ai/projects/recipes/en/latest/Qwen/Qwen2.5-VL.html#running-qwen25-vl-with-bf16-on-4xa100
1.1 命令解析与注意事项
启动 vLLM 服务的关键参数说明:
modelscope download --model Qwen/Qwen2.5-VL-7B-Instruct --local_dir /mnt/Qwen2.5-VL-7B-Instruct
export TOKENIZERS_PARALLELISM=false
vllm serve /mnt/Qwen2.5-VL-7B-Instruct \--host 0.0.0.0 \--port 8000 \--tensor-parallel-size 2 \--max-model-len 65535 \--mm-encoder-tp-mode data \--limit-mm-per-prompt '{"image":2,"video":0}' # 限制每提示图像/视频数量
1.2 API请求示例
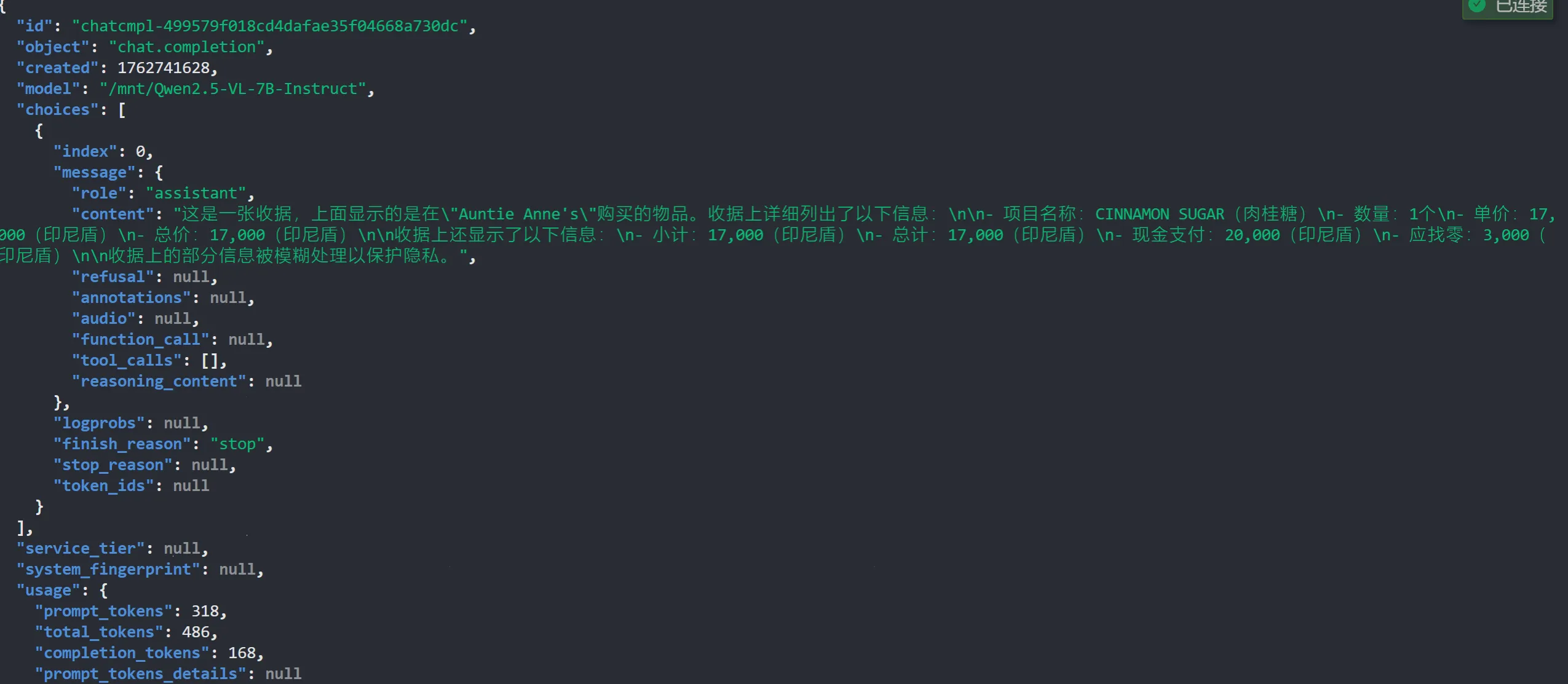
通过 curl 发送多模态请求:
curl -s -X POST "http://127.0.0.1:8000/v1/chat/completions" -H "Content-Type: application/json" -d '{"model": "/mnt/Qwen2.5-VL-7B-Instruct","messages": [{"role": "user","content": [{"type": "image_url","image_url": {"url": "https://ofasys-multimodal-wlcb-3-toshanghai.oss-accelerate.aliyuncs.com/wpf272043/keepme/image/receipt.png"}},{"type": "text","text": "描述了什么"}]}],"max_tokens": 2048}'|jq # 使用jq格式化JSON输出
2 qw-image
文生图模型
https://github.com/QwenLM/Qwen-Image
2.1 使用原生方式,需要显存较多
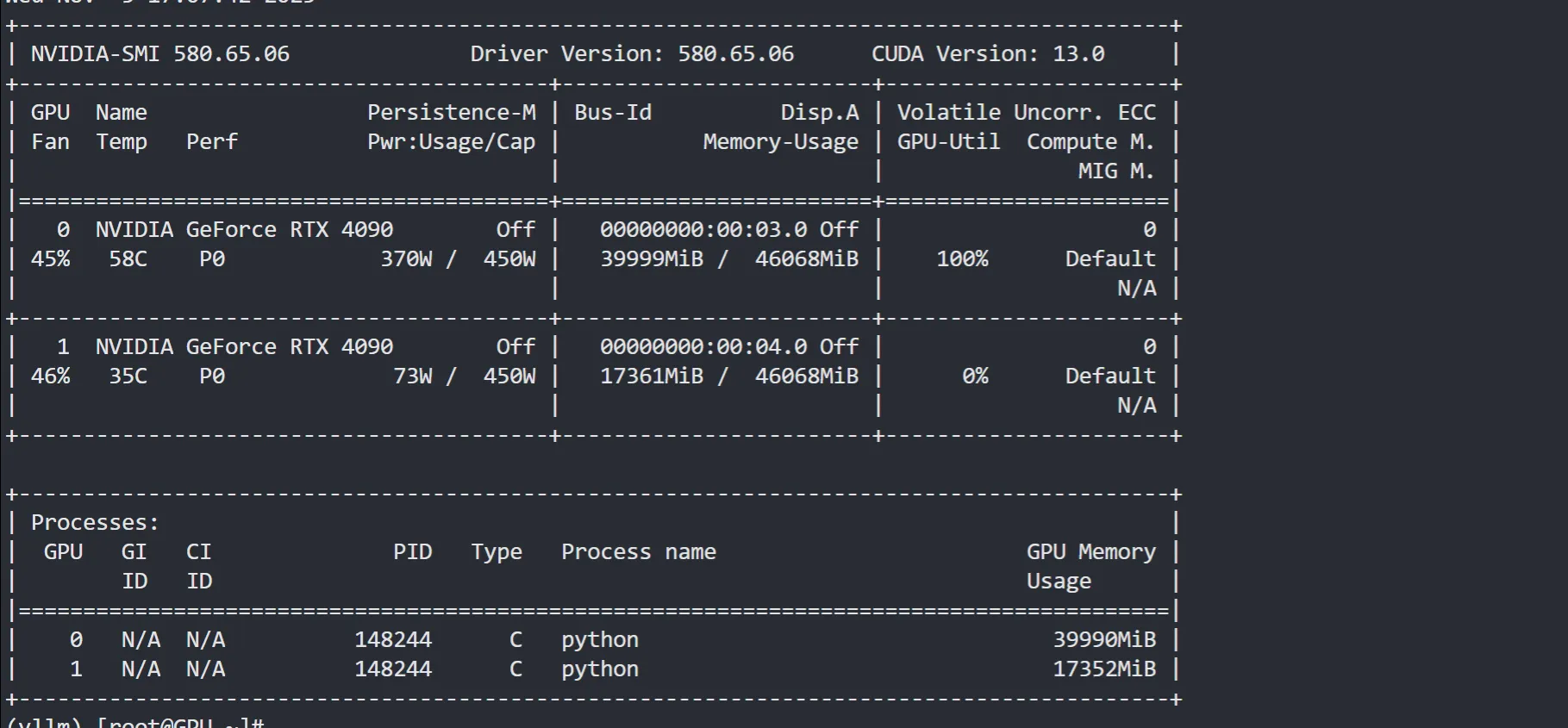
显存占用情况,一张卡跑不起来
modelscope download --model Qwen/Qwen-Image --local_dir /mnt/Qwen-Image
pip install torch torchvision accelerate diffusers
pip install --upgrade diffusers transformers accelerate
pip install git+https://github.com/huggingface/diffusersfrom diffusers import DiffusionPipeline
import torchmodel_name = "/mnt/Qwen-Image"# Load the pipeline
if torch.cuda.is_available():torch_dtype = torch.bfloat16device = "cuda"
else:torch_dtype = torch.float32device = "cpu"pipe = DiffusionPipeline.from_pretrained(model_name, torch_dtype=torch_dtype,device_map="balanced")
#pipe = pipe.to(device)positive_magic = {"en": ", Ultra HD, 4K, cinematic composition.", # for english prompt"zh": ", 超清,4K,电影级构图." # for chinese prompt
}# Generate image
prompt = '''A coffee shop entrance features a chalkboard sign reading "Qwen Coffee 😊 $2 per cup," with a neon light beside it displaying "通义千问". Next to it hangs a poster showing a beautiful Chinese woman, and beneath the poster is written "π≈3.1415926-53589793-23846264-33832795-02384197".'''negative_prompt = " " # Recommended if you don't use a negative prompt.# Generate with different aspect ratios
aspect_ratios = {"1:1": (1328, 1328),"16:9": (1664, 928),"9:16": (928, 1664),"4:3": (1472, 1104),"3:4": (1104, 1472),"3:2": (1584, 1056),"2:3": (1056, 1584),
}width, height = aspect_ratios["16:9"]image = pipe(prompt=prompt + positive_magic["en"],negative_prompt=negative_prompt,width=width,height=height,num_inference_steps=50,true_cfg_scale=4.0,generator=torch.Generator(device="cuda").manual_seed(42)
).images[0]image.save("example.png")

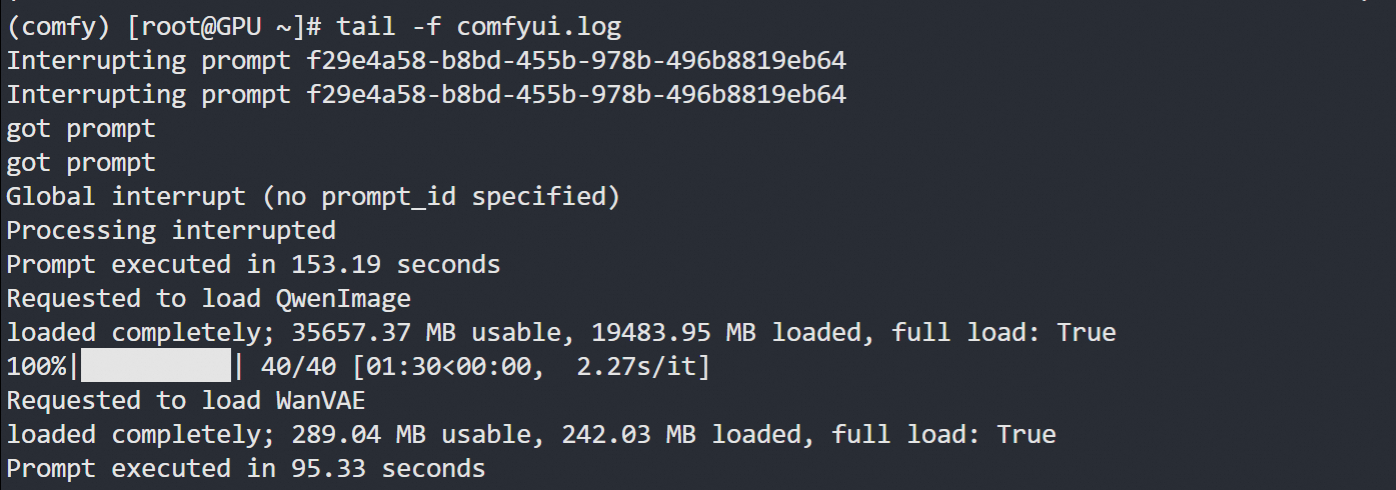
2.2 使用comfyui,显存占用少
ComfyUI是一个基于节点的开源可视化工具,用于构建和运行生成式AI工作流,主要用于Stable Diffusion等AI绘画任务
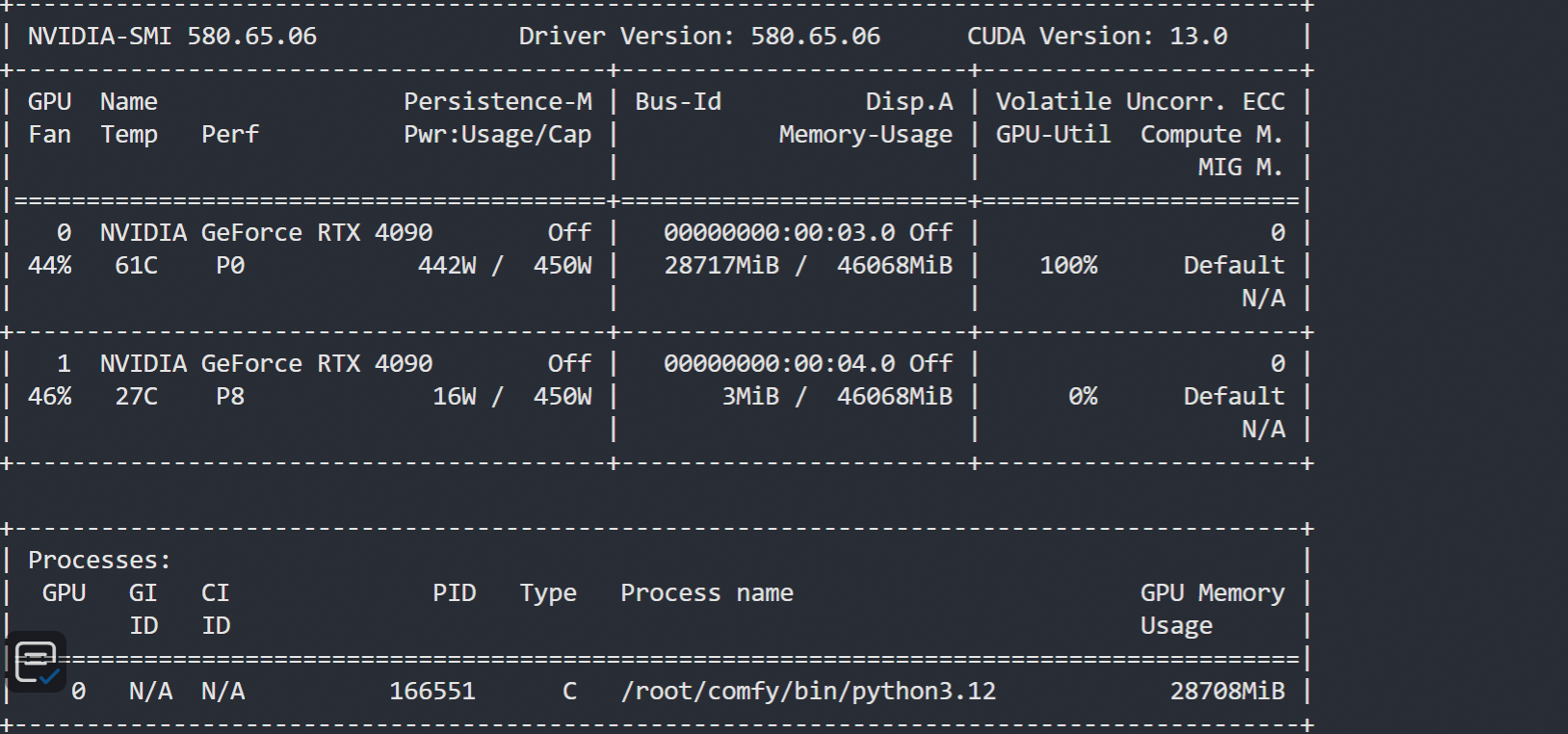
显存占用情况,比原生的要少很多就可以跑起来
https://comfyui-wiki.com/zh/install/install-comfyui/install-comfyui-on-linux
pip install comfy-cli
comfy --install-completion
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu128
comfy install
comfy launch -- --listen 0.0.0.0 --port 8188 &> comfyui.log &
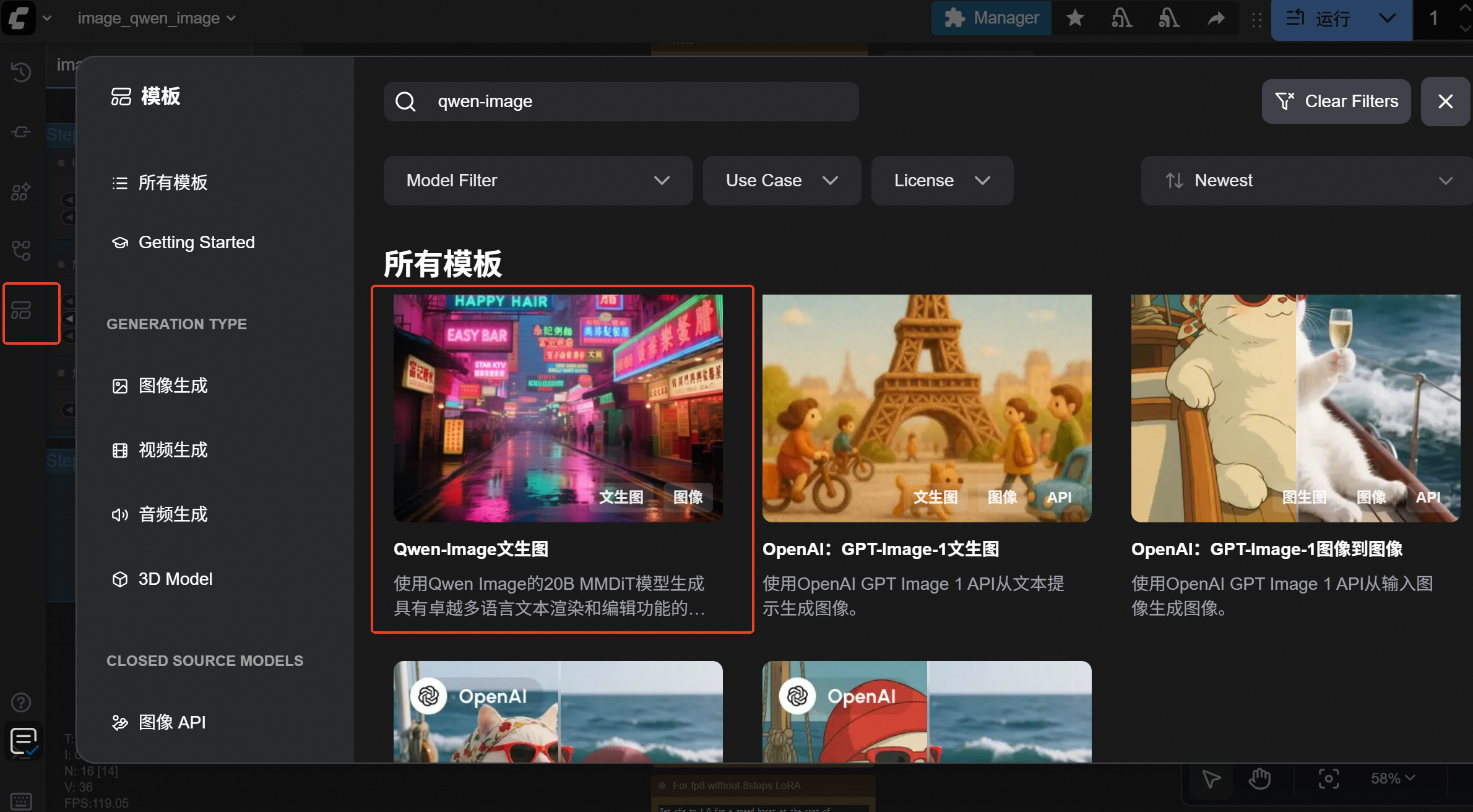
启动后选择内置模版
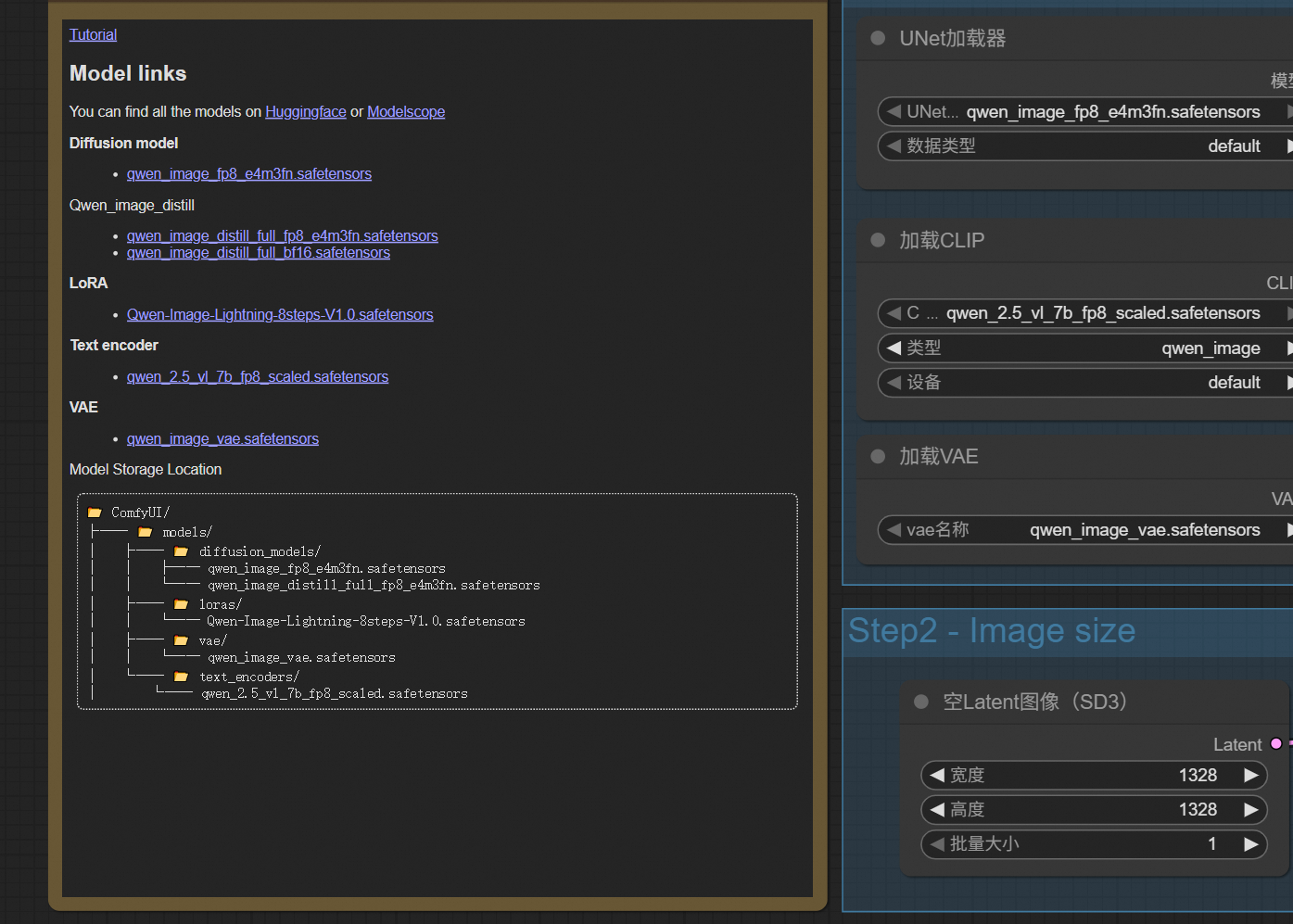
需要去huggingface下载对应模型放到指定位置
- vae / qwen_image_vae.safetensors
- text_encoders / qwen_2.5_vl_7b_fp8_scaled.safetensors
- loras / Qwen-Image-Lightning-8steps-V1.0.safetensors
- diffusion_models / qwen_image_fp8_e4m3fn.safetensors
点击运行
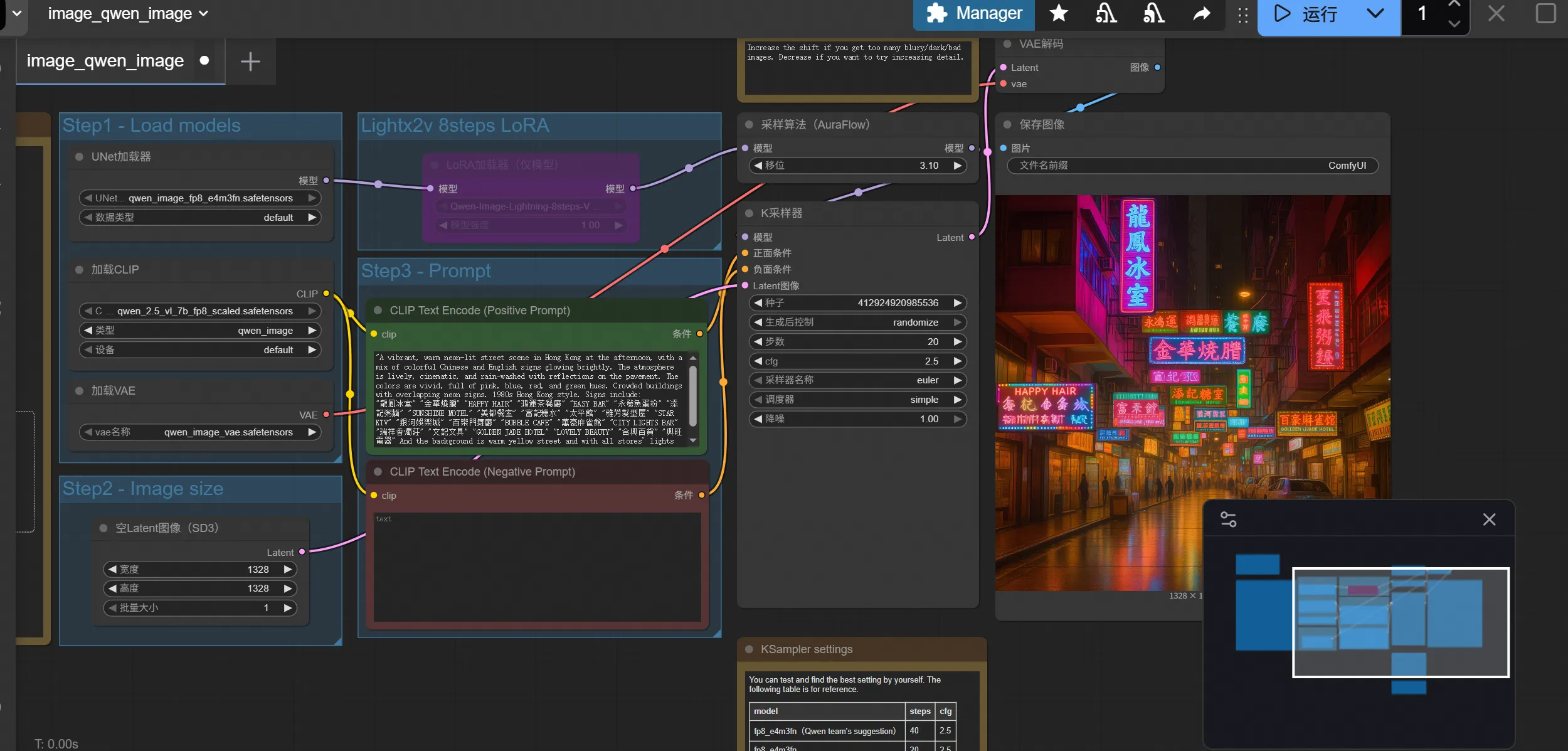
时间差不多在一分半