Spark3.3.2上用PySpark实现词频统计
文章目录
- 1. 实战概述
- 2. 实战步骤
- 2.1 编译安装Python3.7.7
- 2.1.1 安装相关依赖
- 2.1.2 下载Python 3.7.7
- 2.1.3 编译安装Python 3.7.7
- 2.1.4 给Python3.7.7配置环境变量
- 2.1.5 验证Python3.7.7是否安装成功
- 2.1.6 分发Python3.7.7到两个从节点
- 2.1.7 分发环境配置文件到两个从节点
- 2.1.8 让两个从节点环境配置生效
- 2.2 准备数据文件
- 2.2.1 创建数据文件
- 2.2.2 创建HDFS目录
- 2.2.3 上传文件到HDFS指定目录
- 2.3 基于PySpark采用Spark RDD实现词频统计
- 2.3.1 基于文本文件创建RDD
- 2.3.2 按空格拆分作扁平化映射
- 2.3.3 将单词数组映射成二元组数组
- 2.3.4 将二元组数组进行归约
- 2.3.5 将词频统计结果按次数降序排列
- 2.3.6 一步搞定词频统计
- 2.4 基于PySpark采用Spark SQL实现词频统计
- 2.4.1 读取HDFS文件生成数据帧
- 2.4.2 基于数据帧创建临时视图,供SQL查询使用
- 2.4.3 使用Spark SQL编写词频统计查询
- 2.4.4 收集并逐行打印结果
- 3. 实战总结
1. 实战概述
- 本实战基于 Spark 3.3.2 与 Python 3.7.7,通过统一集群 Python 环境并上传文本至 HDFS,分别使用 RDD 和 Spark SQL 两种方式实现词频统计。前者通过函数式算子链完成分词、计数与排序,后者借助 DataFrame 与 SQL 语句实现声明式分析,全面展示了 PySpark 批处理的核心编程范式与实践流程。
2. 实战步骤
- 说明:Spark 3.3.2 最低要求是 Python 3.7+
2.1 编译安装Python3.7.7
2.1.1 安装相关依赖
-
执行命令:
yum groupinstall -y "Development Tools"
-
执行命令:
yum install -y zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel gdbm-devel db4-devel libpcap-devel xz-devel expat-devel
-
执行命令:
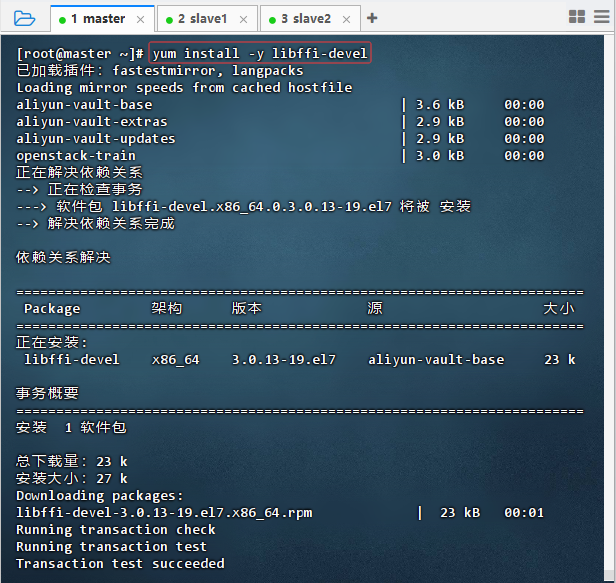
yum install -y libffi-devel
2.1.2 下载Python 3.7.7
-
执行命令:
cd /tmp
-
执行命令:
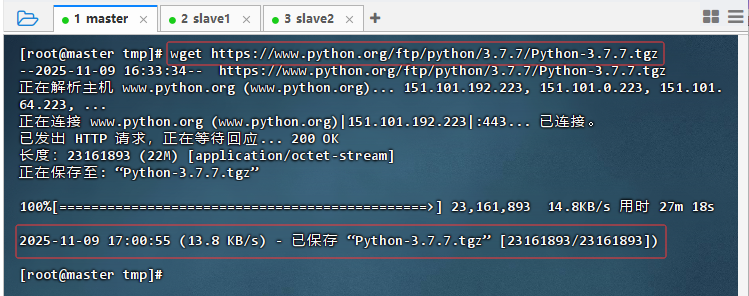
wget https://www.python.org/ftp/python/3.7.7/Python-3.7.7.tgz
-
执行命令:
tar -zxvf Python-3.7.7.tgz,解压到当前目录
2.1.3 编译安装Python 3.7.7
-
执行命令:
cd Python-3.7.7
-
执行命令:
./configure --prefix=/usr/local/python3.7.7 --enable-optimizations --with-ensurepip=install,进行配置

-
执行命令:
make -j4 && make install,进行编译和安装,这个过程比较耗时,会进行源码编译,并测试
2.1.4 给Python3.7.7配置环境变量
-
执行命令:
vim /etc/profile
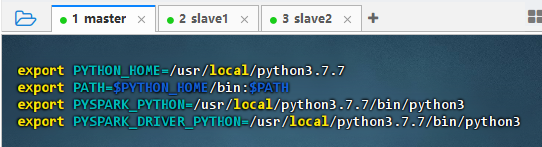
export PYTHON_HOME=/usr/local/python3.7.7 export PATH=$PYTHON_HOME/bin:$PATH export PYSPARK_PYTHON=/usr/local/python3.7.7/bin/python3 export PYSPARK_DRIVER_PYTHON=/usr/local/python3.7.7/bin/python3 -
执行命令:
source /etc/profile,让配置生效
2.1.5 验证Python3.7.7是否安装成功
- 执行命令:
python3
2.1.6 分发Python3.7.7到两个从节点
- 执行命令:
scp -r $PYTHON_HOME root@slave1:$PYTHON_HOME

- 执行命令:
scp -r $PYTHON_HOME root@slave2:$PYTHON_HOME

2.1.7 分发环境配置文件到两个从节点
- 执行命令:
scp /etc/profile root@slave1:/etc/profile
- 执行命令:
scp /etc/profile root@slave2:/etc/profile
2.1.8 让两个从节点环境配置生效
-
在slave1从节点上执行命令:
source /etc/profile
-
在slave2从节点上执行命令:
source /etc/profile
2.2 准备数据文件
2.2.1 创建数据文件
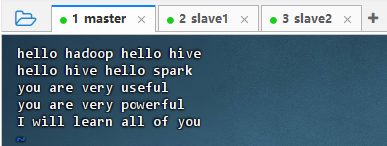
- 执行命令:
vim test.txt
2.2.2 创建HDFS目录
- 执行命令:
hdfs dfs -mkdir -p /wordcount/input
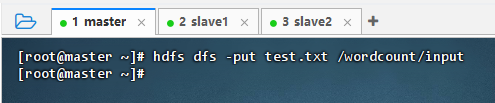
2.2.3 上传文件到HDFS指定目录
- 执行命令:
hdfs dfs -put test.txt /wordcount/input
2.3 基于PySpark采用Spark RDD实现词频统计
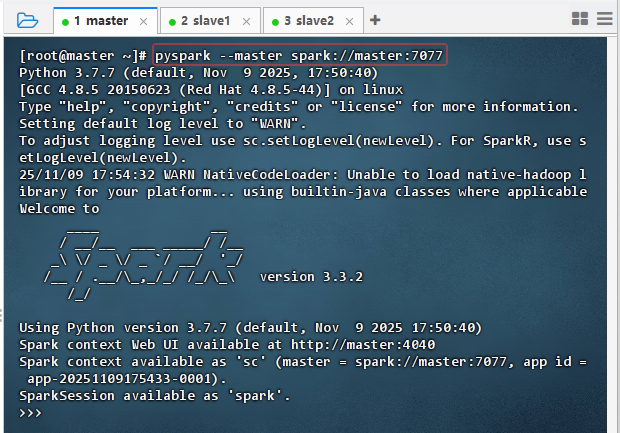
- 启动HDFS服务和Spark集群,然后执行命令:
pyspark --master spark://master:7077
2.3.1 基于文本文件创建RDD
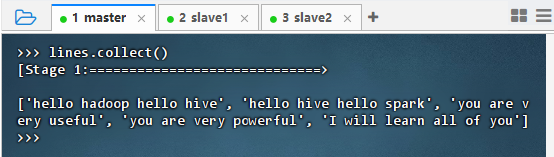
- 执行命令:
lines = sc.textFile("hdfs://master:9000/wordcount/input/test.txt")

- 执行命令:lines.collect()
2.3.2 按空格拆分作扁平化映射
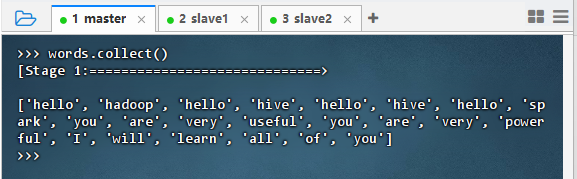
- 执行命令:
words = lines.flatMap(lambda line : line.split(' '))

- 执行命令:
words.collect()
- 执行命令:
tuplewords.collect()
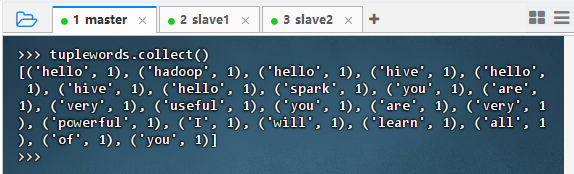
2.3.3 将单词数组映射成二元组数组
- 执行命令:
tuplewords = words.map(lambda word : (word, 1))
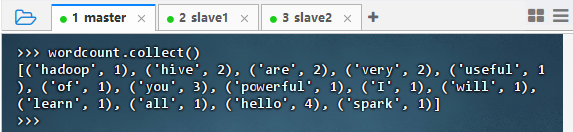
2.3.4 将二元组数组进行归约
- 执行命令:
wordcount = tuplewords.reduceByKey(lambda a, b : a + b)

- 执行命令:
wordcount.collect(),查看词频统计结果
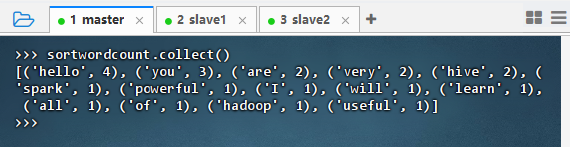
2.3.5 将词频统计结果按次数降序排列
- 执行命令:
sortwordcount = wordcount.sortBy(lambda wc : wc[1], False)

- 命令说明:此命令对
wordcountRDD 按值(词频)降序排序,lambda wc: wc[1]提取键值对中的值,False表示降序。结果保存为sortwordcount。 - 执行命令:
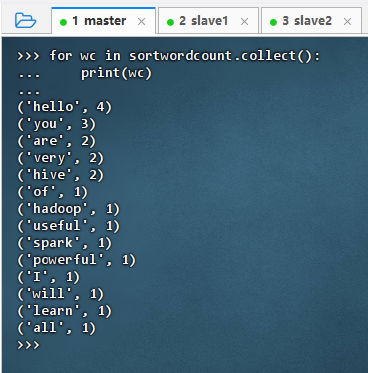
sortwordcount.collect(),查看排序词频统计结果
- 分行输出词频统计结果
2.3.6 一步搞定词频统计
-
执行代码
for wc in sc.textFile("hdfs://master:9000/wordcount/input/test.txt") \.flatMap(lambda line: line.split(' ')) \.map(lambda word: (word, 1)) \.reduceByKey(lambda a, b: a + b) \.sortBy(lambda wc: wc[1], False) \.collect():print(wc)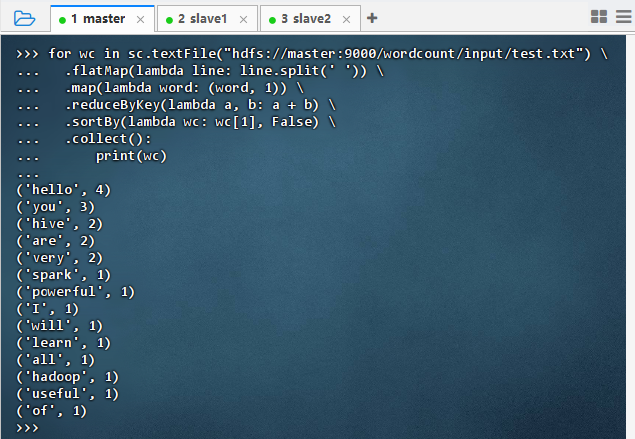
2.4 基于PySpark采用Spark SQL实现词频统计
2.4.1 读取HDFS文件生成数据帧
- 每行一个字符串,列名为 “value”
- 执行命令:
lines_df = spark.read.text("hdfs://master:9000/wordcount/input/test.txt")

2.4.2 基于数据帧创建临时视图,供SQL查询使用
- 执行命令:
lines_df.createOrReplaceTempView("lines")
2.4.3 使用Spark SQL编写词频统计查询
-
执行代码
result = spark.sql("""SELECT word, COUNT(*) AS countFROM (SELECT explode(split(value, ' ')) AS wordFROM lines) tWHERE word != '' AND word IS NOT NULLGROUP BY wordORDER BY count DESC """)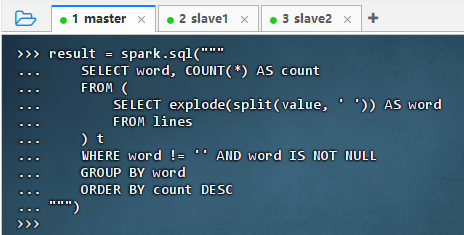
-
执行命令:
result.show()
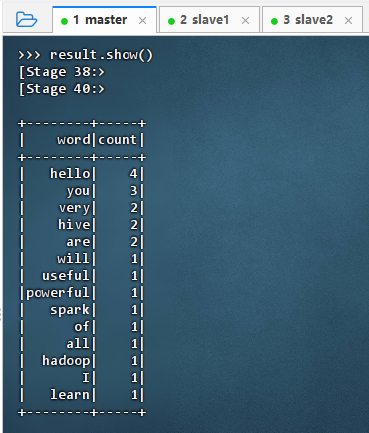
2.4.4 收集并逐行打印结果
-
执行代码
for row in result.collect():print(f"('{row[0]}', {row[1]})")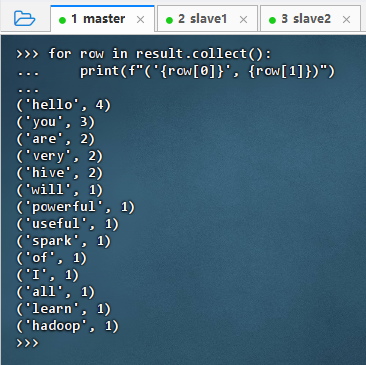
3. 实战总结
- 本次实战围绕 Spark 3.3.2 构建高可用 PySpark 环境并完成词频统计任务。首先在主节点编译安装 Python 3.7.7,配置环境变量,并将完整 Python 环境及
/etc/profile同步至所有从节点,确保集群中PYSPARK_PYTHON版本一致,避免运行时版本冲突。随后将本地文本文件上传至 HDFS,分别采用 RDD 编程模型 和 Spark SQL 两种方式实现词频统计:RDD 方式通过flatMap、map、reduceByKey和sortBy等算子链式处理数据;Spark SQL 方式则利用DataFrame、explode、split及 SQL 语句完成声明式分析,并正确处理列名冲突问题。两种方法均成功输出按频次降序排列的词频结果,验证了环境配置的正确性与 Spark 多范式编程的灵活性,为后续大数据开发奠定坚实基础。