SlaugFL论文阅读学习
SlaugFL: Efficient Edge Federated Learning With Selective GAN-Based Data Augmentation
论文提出SlaugFL—— 一种基于选择性 GAN 数据增强的通信高效边缘联邦学习方案,旨在解决联邦学习中non-IID 数据导致的模型性能下降与高通信开销问题。其核心是通过筛选代表性设备共享局部类别原型(而非原始数据),结合Stable Diffusion 模型与 ChatGPT生成域匹配的 GAN 训练数据,训练 ACGAN 以生成 IID 数据;设备端通过 “增强数据校准” 与 “隐私友好(p-f)全局类别原型校准” 的双校准策略优化局部模型。实验表明,SlaugFL 在 CIFAR-10/CIFAR-100 及真实数据集 MIO-TCD 上,较主流方法最高降低52.49% 通信开销,最高提升14.44% 模型精度,且能抵抗成员推断与数据重构攻击,保护数据隐私。
摘要
近年来,联邦学习(Federated Learning, FL)被广泛用于实现分布式且保护隐私的机器学习。与通常采用所有用户数据独立同分布(Independent and Identically Distributed, IID)的集中式训练不同,由于边缘设备个体产生的数据呈非独立同分布(non-IID)特性,联邦学习面临显著的通信开销大和模型性能下降问题。现有研究通过全局锚点校准局部模型或共享全局数据来解决上述问题,但这些方法要么假设中央服务器已拥有全局数据集,要么要求参与设备共享原始数据,这不仅会产生额外的通信开销,还会引发隐私担忧。 本文提出一种新型的、基于选择性生成对抗网络(Generative Adversarial Network, GAN)数据增强的通信高效边缘联邦学习方案——SlaugFL。该方案选择具有代表性的设备,使其向中央服务器共享特定的局部类别原型(local class prototypes),用于GAN模型训练,并借助训练好的GAN提升联邦学习性能。具体而言,在服务器端,我们利用强大的生成模型(稳定扩散模型(Stable Diffusion Model)和ChatGPT)生成多样化的带标签候选数据;为确保GAN生成的数据与设备本地数据具有相似的域特性,我们利用所选的局部类别原型从带标签候选数据中筛选出理想的GAN训练样本。在设备端,我们提出一种包含两种校准方式的双校准方法:通过训练好的GAN模型对设备的非独立同分布数据进行增强(设备利用该GAN模型生成独立同分布数据集),使设备的局部模型可直接通过增强数据实现校准;同时,利用生成的独立同分布数据构建隐私友好(privacy-free, p-f)全局类别原型,进一步校准设备的局部模型。两种校准方式相结合,有效提升了设备局部模型的性能。 大量实验结果表明,与当前主流方法相比,SlaugFL在保证相同精度的前提下,可显著降低通信开销,降幅最高达52.49%。
引言
近年来,面向各类物联网(IoT)应用的深度学习模型发展迅速[1]。在这类应用中,海量与特定领域相关的传感数据从大量传感器中采集,随后被输入到学习模型中,以支持各类智能应用[2]。在传统的集中式机器学习中,所有设备的数据都会被收集到中央服务器进行训练。然而,随着人们对数据隐私的关注度不断提升以及相关法规(如欧盟的《通用数据保护条例》,GDPR)的出台,联邦学习(Federated Learning, FL)作为一种极具潜力的分布式机器学习模式应运而生——它能够在不暴露任何参与者本地数据的前提下开展模型训练。 联邦平均(FedAvg)[3]是应用最广泛的联邦学习方法之一,其通过加权平均的方式聚合来自各设备的模型参数。为降低通信开销,FedAvg在每一轮训练中会随机选择一部分设备,让这些设备上传其优化后的模型。但FedAvg的效率仍有待提升,尤其是在设备数据存在统计异质性(即数据分布不一致)的场景下——这也是导致联邦学习收敛速度慢、通信开销大的关键原因之一[4]。 在集中式学习中,服务器可收集所有原始数据,因此通常能获得所有设备数据的独立同分布(IID)样本。但在联邦学习中,由于底层设备呈分散分布,每个设备基于自身异质性(非独立同分布,non-IID)的用户数据进行本地训练,很容易导致局部模型出现偏差。例如,在街道场景下拍摄的图像,很难反映智能工厂环境中的数据特征。这种偏差会使得联邦学习模型的收敛时间大幅延长,进而显著增加训练延迟与通信开销。
为降低非独立同分布(non-IID)数据的负面影响,研究人员提出了一系列后续工作,旨在从模型精度和通信效率两方面进一步优化联邦学习(FL)性能。我们将这些工作划分为两大方向: 1. 设备局部模型校准[5]、[6]、[7]、[8]、[9]、[10]:这类研究从模型层面和特征层面揭示了非独立同分布数据导致的设备间模型不一致问题。为解决该问题,它们通过引入特定的全局锚点(global anchor)来修正设备的局部训练过程。 2. 全局数据共享[11]、[12]、[13]、[14]、[15]:其中部分工作通过向参与设备共享全局数据集,弥补设备上缺失的数据类型[11]、[13]。然而,在许多实际场景中,全局数据集并非总能获取。另一部分工作[12]、[14]、[15]则基于生成对抗网络(Generative Adversarial Network, GAN)进行数据增强,帮助设备获得独立同分布(IID)数据集。
然而,上述现有研究仍存在三个严重局限:1)为训练生成对抗网络(GAN)而进行的数据收集会产生高昂的通信开销;2)构建所需的全局锚点或GAN模型训练数据集时,会带来额外的隐私风险;3)所获取的独立同分布(IID)数据未被充分用于优化训练过程,这可能导致不必要的收敛时间延长与通信开销增加。 ### 补充说明: - 术语解释:“global anchors”(全局锚点)指在联邦学习中用于校准各设备局部模型的全局参考基准(如全局模型参数、全局类别原型等),可减少非独立同分布(non-IID)数据导致的设备间模型偏差。
为解决上述局限,本文提出一种基于选择性生成对抗网络(GAN)数据增强的通信高效联邦学习(FL)方案——SlaugFL。该方案具有以下三大显著特征: 首先,为避免服务器端生成对抗网络(GAN)模型训练因数据收集产生通信开销,我们无需收集所有设备的原始数据。相反,我们利用服务器端对局部模型的测试结果,筛选出一小部分特定设备;这些被选中的代表性设备仅需向中央服务器共享其特定的局部类别原型¹,既降低了通信开销,又保护了设备本地数据隐私,且这些来自代表性设备的原型有望覆盖大部分数据类型。为确保生成的独立同分布(IID)数据的特征分布与设备本地数据的特征分布相近(即生成的IID数据与设备本地数据具有相似的域特性),我们利用这些选中的局部类别原型,从强大生成模型(稳定扩散模型[16]与ChatGPT)生成的带标签候选数据中筛选出理想的GAN训练样本。此外,我们还证明,在缺乏带标签候选数据的情况下,也可直接利用这些选中的局部类别原型训练GAN模型。 其次,借助训练好的GAN模型,每个设备都能生成与自身本地数据域特性相似的IID数据。由此,设备的局部模型可通过增强后的本地数据直接得到性能提升。 最后,考虑到设备可利用GAN生成的IID数据构建隐私友好(p-f)局部类别原型²,我们利用共享的隐私友好局部类别原型经加权平均得到的隐私友好全局类别原型,对局部模型进行校准,这一过程进一步提升了联邦学习的性能。 在上述创新的推动下,联邦学习在不同非独立同分布(non-IID)数据场景中的性能均能得到显著提升。我们在不同非IID数据设置下,基于CIFAR-10和CIFAR-100数据集对SlaugFL进行了验证,结果表明,该方案的性能优于当前主流方法。
txt 注释 1. **局部类别原型(local class prototype)**:指通过特征提取器从设备本地某一类数据中提取的嵌入特征向量的均值,可作为该类数据的代表性特征,无需暴露原始数据。 2. **隐私友好(p-f)局部类别原型**:基于GAN生成的IID数据构建的局部类别原型,由于生成数据不包含设备原始数据的隐私信息,因此称为“隐私友好”原型。
本文贡献如下:
- 我们提出了SlaugFL:一种基于选择性生成对抗网络(GAN)数据增强的通信高效联邦学习(FL)方案。通过收集特定的局部类别原型用于GAN模型训练,可大幅降低额外的通信开销;同时,传输这些选定的局部类别原型能够保护设备的本地数据隐私。
- 我们提出了两种GAN模型训练场景:一种是利用筛选后的GAN训练数据训练GAN模型,另一种是直接利用这些选定的局部类别原型训练GAN模型。通过这种方式,我们训练的生成对抗网络(GAN)模型所输出的数据,将能够与设备原始数据具有相似的域特性。
- 我们在客户端提出了一种双校准方法,该方法利用增强后的数据和隐私友好(p-f)全局类别原型对局部模型进行校准。此方法大幅减少了通信轮次,同时提升了模型精度。
- 我们对SlaugFL带来的通信开销与隐私问题进行了形式化分析,并在两种联邦学习基准数据集上、多种非独立同分布(non-IID)数据设置下,对SlaugFL进行了实验评估。结果表明,所提方案可将通信开销降低高达52.49%,并将模型精度提升高达14.44%。
本文其余部分结构如下:第二节回顾相关工作,并总结本文工作与现有文献的差异;第三节介绍联邦学习、基于原型的域适应以及辅助分类器生成对抗网络(ACGAN)的预备知识;第四节详细阐述所提出的SlaugFL方案;第五节从通信效率和模型性能两方面验证算法有效性;第六节对全文进行总结。
术语说明
- **domain**(域):在机器学习中,指数据的分布特性,若两个数据集“域相似”,则意味着它们的数据分布(如特征分布、类别分布)具有较高一致性,可减少模型因数据分布差异导致的性能下降。
- **p-f global class prototypes**(隐私友好全局类别原型):“p-f”为“privacy-free”的缩写,指基于生成数据(非原始隐私数据)构建的全局类别原型,通过聚合客户端的隐私友好局部类别原型得到,用于校准局部模型且不泄露原始数据隐私。
- **auxiliary classifier GAN(ACGAN)**:辅助分类器生成对抗网络,在传统GAN基础上增加分类器模块,可生成带类别标签的目标数据,适用于有监督的数据增强场景。
相关工作
联邦学习(FL)已被广泛应用于工业工程、医疗健康等众多隐私敏感型领域。高通信开销与模型性能下降始终是阻碍联邦学习高效运行的关键问题,其核心原因之一在于设备端用户数据具有异构性(非独立同分布,non-IID),这一问题近年来已引发学术界的广泛关注。目前,针对非独立同分布数据的联邦学习研究可分为两类:1)设备端局部模型校准;2)全局数据共享。
设备端局部模型校准 设备间的数据非独立同分布特性,会导致局部模型与全局模型存在不一致性。现有研究从两个互补维度解决这一不一致问题: 其一,在模型层面,聚焦于设备间模型训练方向的不一致性。解决该问题的核心思路是借助特定“锚点”修正局部模型的训练方向[5]、[6]、[7]。例如,FedProx[5]以全局模型为锚点,通过计算局部模型与锚点的偏差,修正局部模型的训练方向;Scaffold[6]的核心思想是引入全局控制变量与设备端控制变量,以此校准局部模型的梯度——在局部训练阶段,将全局控制变量与局部控制变量的偏差项加入训练目标函数,实现对局部模型的修正;MOON[7]则在模型层面引入对比学习,通过比较局部模型与全局模型提取的 latent 特征(隐特征),调整局部模型的训练方向。 其二,在特征层面,关注设备间隐特征分布的不一致性。近期研究[8]、[9]、[10]通过对设备端共享的局部类别原型(local class prototypes)进行平均,构建全局类别原型(global class prototypes),并将其作为锚点;基于该全局类别原型,每个设备可修正本地隐特征分布,进而提升联邦学习(FL)性能。
然而,这些方法[5]、[6]、[7]在各类非独立同分布(non-IID)数据场景下,仅能有限提升联邦学习性能,无法大幅降低通信开销。对于[8]、[9]、[10]这类需覆盖所有类别的全局类别原型方法而言,它们在每轮通信中都会从所有设备(而非选定设备)收集局部类别原型,这无疑会产生额外的通信成本。
全局数据共享 全局数据共享的核心思路是:直接共享一个可用数据集,或基于从参与设备收集的数据训练生成对抗网络(GAN)模型,再将该模型分发给所有设备[11]、[12]、[13]、[14]、[15],使设备能在本地生成所需类别的数据。在非独立同分布联邦学习场景中,参与设备基于自身非独立同分布数据集训练模型,导致训练后的局部模型无法识别其训练数据集中“缺失类别”的样本。将非独立同分布数据集调整为独立同分布(IID)数据集,可有效提升模型性能。因此,在实际应用中,向所有参与者共享“类别分布均匀”的全局数据是一种常用方案。 为改进联邦平均(FedAvg)算法,Zhao等人[11]与Huang等人[13]假设服务器端存储有与分类任务相关的公共数据集,并通过分发该公共数据集来缓解设备数据的非独立同分布问题。与依赖全局数据集的思路不同,Jeong等人利用GAN合成所需数据:他们在服务器端训练一个GAN模型,再将其发送给参与者,使参与者能在本地生成缺失类别的数据[12]。为实现“无数据依赖”的GAN模型训练,Zhu等人[14]从收集到的分类层中提取用户数据信息,用于训练可生成含全局信息隐特征的GAN模型。Tang等人[15]则向未训练的风格生成对抗网络(style-GAN)中输入噪声,在服务器端生成与任务无关的独立同分布数据集,再将其广播给参与设备,从而在保护隐私的前提下提升联邦学习模型性能。
全局数据共享的核心局限 1. 共享数据集[11]、[13]需与任务相关,而在许多实际应用中,满足特定数据分布要求(如涵盖所有类别样本)的任务相关公共数据集并非总能获取; 2. 与任务无关的数据集[15]在“局部训练轮次较多”(如5轮局部训练)的场景下,无法有效校准局部模型;而减少局部训练轮次又会增加通信成本; 3. 为训练用于生成所需样本的GAN模型[12],需从所有设备收集数据,这不仅会产生大量额外通信开销,还会泄露设备本地数据隐私; 4. 相较于共享数据样本,共享隐特征[14]的知识传递能力有限,在部分极端非独立同分布数据场景下,难以实现模型快速收敛。
差异总结 SlaugFL采用全局数据共享的思路,与现有研究相比,具有两大核心创新: 第一,现有研究需设备上传本地原始数据用于GAN训练,而SlaugFL采用“选择性方案”——通过模型测试过程精准推断设备关联性,仅选择代表性设备的局部类别原型,用于服务器端GAN训练; 第二,考虑到参与设备可利用接收到的GAN模型生成“域相似”的独立同分布数据集,SlaugFL除了用增强后的本地数据集训练局部模型外,还提出“在特征层面以隐私保护方式校准局部模型”,进一步加速训练过程。 在非独立同分布的CIFAR-10与CIFAR-100数据集上的实验结果表明,与现有主流方法相比,SlaugFL大幅降低了通信成本,同时提升了模型精度。
关键术语补充说明 - **privacy-sensitive applications**:隐私敏感型领域,指涉及用户隐私数据(如医疗记录、工业生产数据)的应用场景,需严格保护数据不泄露。 - **latent features**:隐特征,指通过模型(如神经网络)提取的、无法直接观察但能表征数据核心信息的特征向量。 - **local/global class prototypes**:局部/全局类别原型,分别指单个设备、全局范围内某一类数据的隐特征均值,可作为该类数据的代表性特征,用于减少数据异构性带来的模型偏差。
预备知识
3.1 联邦学习(FL)
首先考虑多分类任务。设实例空间为X⊂RrX \subset \mathbb{R}^rX⊂Rr,标签空间为Y⊂RCY \subset \mathbb{R}^CY⊂RC。给定一个由参数www控制的模型fw:X→Yf_w: X \to Yfw:X→Y,当向该模型输入实例x∈Xx \in Xx∈X时,模型会输出一个概率向量[fw(x)1,…,fw(x)C][f_w(x)_1, \dots, f_w(x)_C][fw(x)1,…,fw(x)C]。例如,fw(x)cf_w(x)_cfw(x)c(c∈[1,C]c \in [1, C]c∈[1,C])表示实例xxx属于类别ccc的概率。 对于该多分类任务,训练数据集D={(x1,y1),…,(xn,yn)}={X,Y}⊂X×YD = \{(x_1, y_1), \dots, (x_n, y_n)\} = \{X, Y\} \subset X \times YD={(x1,y1),…,(xn,yn)}={X,Y}⊂X×Y的经验风险可定义为: L(D;w)=1n∑j∈[n]ℓ(f(xj;w),yj)(1) \mathcal{L}(D; w) = \frac{1}{n} \sum_{j \in [n]} \ell(f(x_j; w), y_j) \tag{1} L(D;w)=n1j∈[n]∑ℓ(f(xj;w),yj)(1) 其中ℓ(⋅)\ell(\cdot)ℓ(⋅)为损失函数。为提高预测精度,我们通过最小化经验风险确定最优模型参数,目标函数如下: w∗=minwL(D;w)(2) w^* = \min_{w} \mathcal{L}(D; w) \tag{2} w∗=wminL(D;w)(2) 接下来考虑联邦学习场景:整个训练数据D=⋃k∈[M]DkD = \bigcup_{k \in [M]} D^kD=⋃k∈[M]Dk非均匀地分布在MMM个设备上。具体而言,每个设备kkk拥有私有训练数据Dk={(x1k,y1k),…,(xnkk,ynkk)}={Xk,Yk}D^k = \{(x_1^k, y_1^k), \dots, (x_{n_k}^k, y_{n_k}^k)\} = \{X^k, Y^k\}Dk={(x1k,y1k),…,(xnkk,ynkk)}={Xk,Yk},且DkD^kDk服从未知分布PkP_kPk。联邦平均(FedAvg)[3]是联邦学习中应用最广泛的协同训练框架之一,其协同训练过程如下: - 在第ttt轮通信(t∈[0,T]t \in [0, T]t∈[0,T])中,中央服务器首先将最新模型参数wtw_twt广播给选定的设备; - 每个设备kkk将接收到的模型参数wtw_twt作为自身当前模型参数wtk=wtw_t^k = w_twtk=wt,并在私有数据集DkD^kDk上训练模型fwtk(x)f_{w_t^k}(x)fwtk(x),以最小化局部目标函数: wtk∗=minwtkLk(Dk;wtk)(3) w_t^{k*} = \min_{w_t^k} \mathcal{L}_k(D^k; w_t^k) \tag{3} wtk∗=wtkminLk(Dk;wtk)(3) 随后执行局部更新算法(LocalUpdate(·),参见算法1),得到最优局部模型参数wtkw_t^kwtk; - 中央服务器聚合选定的KKK个设备的模型参数更新{wtk}k∈[K]\{w_t^k\}_{k \in [K]}{wtk}k∈[K],通过加权平均得到新的全局模型参数: wt+1=∑k=1Kpk⋅wtk w_{t+1} = \sum_{k=1}^K p_k \cdot w_t^k wt+1=k=1∑Kpk⋅wtk 其中pk=∣Dk∣∣DK∣p_k = \frac{|D^k|}{|D^K|}pk=∣DK∣∣Dk∣,DK=⋃k∈[K]DkD^K = \bigcup_{k \in [K]} D^kDK=⋃k∈[K]Dk,∣Dk∣|D^k|∣Dk∣表示数据集DkD^kDk的样本数量。(4)
算法1:
设备局部更新算法
输入:设备编号kkk、局部训练轮次HHH、从中央服务器接收的模型wtw_twt
输出:更新后的局部模型www
-
将接收到的模型参数作为当前模型参数:w=wtw = w_tw=wt
-
对局部训练轮次h=1,…,Hh = 1, \dots, Hh=1,…,H:
a. 将数据集DkD^kDk划分为大小为bbb的批次
b. 对每个批次(X,Y)(X, Y)(X,Y):
i. 计算损失梯度:∇wLk(X,Y;w)\nabla_w \mathcal{L}_k(X, Y; w)∇wLk(X,Y;w)
ii. 更新模型参数:w=w−η⋅∇wLk(X,Y;w)w = w - \eta \cdot \nabla_w \mathcal{L}_k(X, Y; w)w=w−η⋅∇wLk(X,Y;w)(η\etaη为学习率)
-
返回更新后的模型参数www
3.2 基于原型的域适应
在多分类任务中,分类模型通常由特征提取器ψ(⋅)\psi(\cdot)ψ(⋅)和预测器g(⋅)g(\cdot)g(⋅)组成,可表示为fw=ψw1∘gw2f_w = \psi_{w_1} \circ g_{w_2}fw=ψw1∘gw2,其中w=(w1,w2)w = (w_1, w_2)w=(w1,w2)(w1w_1w1为特征提取器参数,w2w_2w2为预测器参数)。 给定某一类别的图像实例集合Dc={(x,y)∈D∣y=c}D_c = \{(x, y) \in D \mid y = c\}Dc={(x,y)∈D∣y=c},特征提取器会生成该类实例的嵌入特征向量集合{zc,1,…,zc,∣Dc∣}\{z_{c,1}, \dots, z_{c, |D_c|}\}{zc,1,…,zc,∣Dc∣},其中zc,j=ψw1(xj)z_{c,j} = \psi_{w_1}(x_j)zc,j=ψw1(xj)(xj∈Dcx_j \in D_cxj∈Dc)。该类别嵌入特征向量集合的均值可表示为: Zc=1∣Dc∣∑j=1∣Dc∣zc,j(5) Z_c = \frac{1}{|D_c|} \sum_{j=1}^{|D_c|} z_{c,j} \tag{5} Zc=∣Dc∣1j=1∑∣Dc∣zc,j(5) 该均值被称为“类别原型”[17]、[18],可作为某一类别嵌入特征的代表性指标。在域适应领域[19],原型常被用于提升模型性能:例如,若一个模型在“真实猫图片”数据集DS={XS,YS}D_S = \{X_S, Y_S\}DS={XS,YS}上训练,但在“卡通猫图片”数据集DT={XT,YT}D_T = \{X_T, Y_T\}DT={XT,YT}上性能下降,域适应方法可通过最小化源分布PSP_SPS(真实猫图片分布)与目标分布PTP_TPT(卡通猫图片分布)的特征分布差异,缓解模型性能退化。 结合原型,域适应中的优化问题可表示为: Ld=mind(ZS,ZT)(6) \mathcal{L}_d = \min d(Z_S, Z_T) \tag{6} Ld=mind(ZS,ZT)(6) 其中d(⋅)d(\cdot)d(⋅)为距离度量(如ℓ2\ell_2ℓ2损失、近年来广泛应用的对比损失[20]等),ZSZ_SZS、ZTZ_TZT分别为源域与目标域的类别原型集合。本文中,我们利用域适应方法解决设备与中央服务器之间的特征分布偏移问题。
3.3 辅助分类器生成对抗网络(ACGAN)
传统生成对抗网络(GAN)[21]需输入随机高斯噪声向量rrr,生成服从训练数据分布的随机类别图像。但在实际应用中,我们通常希望GAN能生成指定类别的图像。为解决这一问题,Mirza等人提出条件生成对抗网络(CGAN)[22],将训练数据的标签信息引入传统GAN的训练过程,其目标函数为: LCGAN=minθGmaxθDV(D,G)(7) \mathcal{L}_{CGAN} = \min_{\theta^G} \max_{\theta^D} V(D, G) \tag{7} LCGAN=θGminθDmaxV(D,G)(7) 其中价值函数V(D,G)V(D, G)V(D,G)定义为: V(D,G)=Ex∼Pdata[logD(x∣y)]+Er∼Pr[log(1−D(G(r∣y)))](8) V(D, G) = \mathbb{E}_{x \sim P_{data}}[\log D(x \mid y)] + \mathbb{E}_{r \sim P_r}[\log(1 - D(G(r \mid y)))] \tag{8} V(D,G)=Ex∼Pdata[logD(x∣y)]+Er∼Pr[log(1−D(G(r∣y)))](8) 式中,yyy为类别标签,PdataP_{data}Pdata为训练数据分布,PrP_rPr为噪声分布;判别器DDD由参数θD\theta^DθD控制,生成器GGG由参数θG\theta^GθG控制。 由于GAN的训练过程是“对抗训练”——更强的判别器能推动生成器性能提升,基于这一思路,研究者提出辅助分类器生成对抗网络(ACGAN)[23]。ACGAN是CGAN的扩展,新增了一个分类器QQQ,其损失函数分为两部分: LA=Ex∼Pdata[logD(x∣y)]+Er∼Pr[log(1−D(G(r∣y)))](9) \mathcal{L}_A = \mathbb{E}_{x \sim P_{data}}[\log D(x \mid y)] + \mathbb{E}_{r \sim P_r}[\log(1 - D(G(r \mid y)))] \tag{9} LA=Ex∼Pdata[logD(x∣y)]+Er∼Pr[log(1−D(G(r∣y)))](9) LB=Ex∼Pdata[logQ(x∣y)]+Er∼Pr[logQ(G(r∣y))](10) \mathcal{L}_B = \mathbb{E}_{x \sim P_{data}}[\log Q(x \mid y)] + \mathbb{E}_{r \sim P_r}[\log Q(G(r \mid y))] \tag{10} LB=Ex∼Pdata[logQ(x∣y)]+Er∼Pr[logQ(G(r∣y))](10)
其中分类器QQQ由参数θQ\theta^QθQ控制。需注意的是,判别器DDD与分类器QQQ仅在最后一个输出层存在差异:DDD用于判断样本“真实/生成”,QQQ用于预测样本类别。 ACGAN的参数优化规则为:通过最大化LA+B=LA+LB\mathcal{L}_{A+B} = \mathcal{L}_A + \mathcal{L}_BLA+B=LA+LB得到判别器最优参数θD\theta^DθD;通过最大化LB−A=LB−LA\mathcal{L}_{B-A} = \mathcal{L}_B - \mathcal{L}_ALB−A=LB−LA得到生成器最优参数θG\theta^GθG。本文选择ACGAN作为生成模型,因其能根据指定类别标签生成更多样、更精细的图像。
4. SlaugFL的主要设计
本节首先阐述本研究的设计动机,随后详细介绍所提出的SlaugFL算法。
4.1 设计动机
本研究的设计源于以下两点观察: 1)GAN训练数据集可通过当前主流的稳定扩散(SD)模型与ChatGPT获取: 现有方法构建GAN训练数据集时,需参与设备共享部分本地数据(第二节已讨论),但这种方式受效率与隐私问题限制,在实际应用中难以落地。近年来,稳定扩散(SD)模型与大型语言模型(LLM)[24](如ChatGPT)的快速发展,为获取目标数据提供了新可能。
首先,我们观察到,在图像真实性与多样性方面,SD模型[16]的图像合成能力优于生成对抗网络(GAN)、变分自编码器(VAE)等现有生成模型[25]。与GAN模型不同,SD模型是一种文本条件图像生成模型,其训练基于公开可用的大规模图文对数据集,能够通过不同的文本描述(提示词,prompts)生成多样化图像。因此,我们认为,相较于公开的预训练GAN模型,公开的预训练SD模型更适合用于生成GAN训练数据(第五节F2部分将通过对比实验验证这一观点)。其次,生成带标签候选数据时,核心挑战在于保持同类图像的多样性。当前主流的大型语言模型ChatGPT(由OpenAI开发)已展现出强大的文本生成能力,借助ChatGPT,可轻松为同一类别生成不同的文本描述。将SD模型与ChatGPT结合,能够以隐私保护的方式获取目标GAN训练数据,无需共享设备本地数据。
2)独立同分布(IID)域相似数据可进一步用于设备局部模型校准: 如第二节所述,现有方法会聚合由设备本地非独立同分布(non-IID)数据生成的局部类别原型,并对其进行加权平均以得到全局类别原型;随后将全局类别原型作为全局锚点,迫使选定设备的嵌入特征分布向全局锚点分布靠拢,从而实现设备模型校准。 由此,我们思考:除了利用IID域相似数据扩充设备本地non-IID数据外,这类数据是否还能进一步发挥作用?我们的直观推测是:与从non-IID数据中获取的全局类别原型相比,从IID域相似数据中获取的全局类别原型,对设备局部模型的校准效果更优。
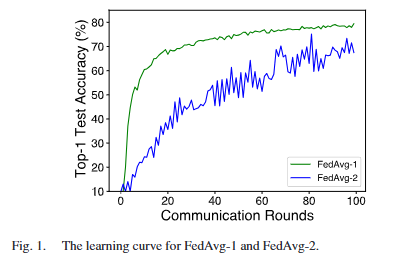
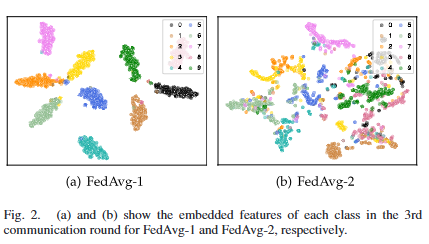
为验证这一推测,我们设计了对比实验:采用两种不同方式运行联邦平均(FedAvg)算法(分别记为FedAvg-1和FedAvg-2)。首先,针对两种算法,我们均采用non-IID分布方式将CIFAR-10数据集分配给50个参与设备(non-IID划分策略详见第五节A2部分);其中,为FedAvg-1额外准备了由SD模型生成的IID数据集,并将其广播至所有设备——该IID数据集与CIFAR-10域相似,且每个类别包含1000张图像。其次,两种算法的设备模型在局部训练阶段,均利用对应的全局类别原型对局部模型进行校准;局部训练完成后,所有设备均需将更新后的局部模型与局部类别原型上传至中央服务器。需特别说明的是:FedAvg-2的局部类别原型由设备本地non-IID数据生成,而FedAvg-1的局部类别原型由设备本地IID域相似数据生成,因此两种算法的全局类别原型存在差异。 经过100轮通信后,我们对比了FedAvg-1与FedAvg-2的全局模型收敛情况。图1验证了我们的推测:FedAvg-1的全局模型收敛速度更快、精度更高。为探究背后原因,我们进一步对比了两种全局类别原型的特征分布差异。为简化分析,每轮通信中,我们直接聚合所有设备的嵌入特征(而非局部类别原型)。从图2可观察到:在同一通信轮次(如第3轮),与FedAvg-2相比,FedAvg-1中各类别的嵌入特征在特征空间中的聚类更紧密,这意味着其对应的全局类别原型可分性更强。 因此,从独立同分布(IID)域相似数据中获取的全局类别原型具有更优的校准效果。基于这一观察,我们认为,独立同分布(IID)域相似数据可进一步用于设备局部模型的校准。
B. 整体框架
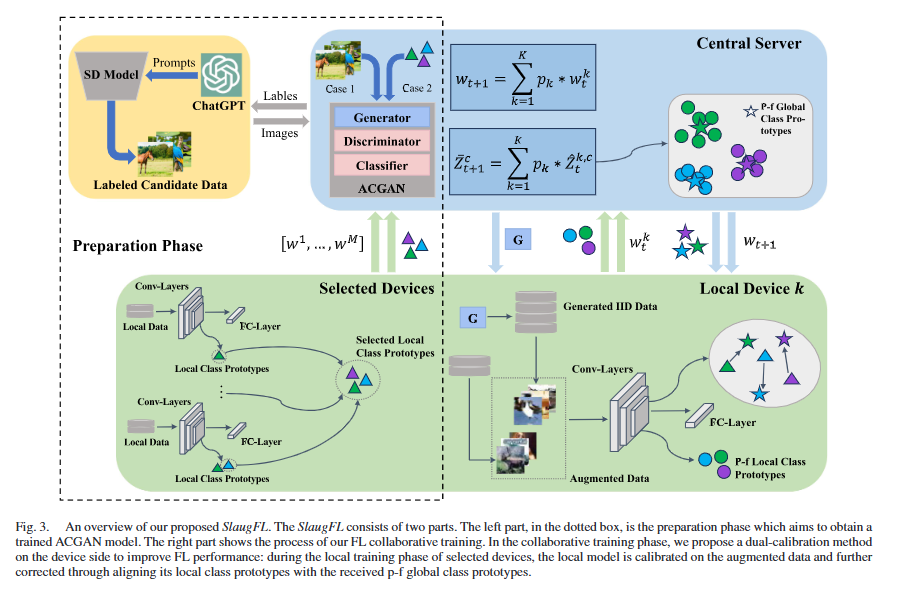
从宏观层面来看,SlaugFL(见图3)采用全局数据共享的思路,从模型精度与通信效率两方面提升联邦学习(FL)的性能。为实现这一目标,我们借助训练好的辅助分类器生成对抗网络(ACGAN)模型来生成所需样本,并设计了一个准备阶段。具体而言,我们将稳定扩散(SD)模型与ChatGPT相结合,生成多样化的带标签候选数据;考虑到带标签候选数据与设备原始数据之间存在域偏移问题,我们提出选择性数据收集(SDC)算法,通过选定的局部类别原型为每类数据筛选出目标候选样本。随后,我们使用筛选后的带标签候选数据训练ACGAN模型,或直接利用这些选定的局部类别原型训练ACGAN模型。ACGAN模型训练完成后,我们将生成器G广播至所有设备。 在每一轮通信中,每个被选中的设备k都会利用生成器G生成独立同分布(IID)数据,以扩充自身的非独立同分布(non-IID)数据。为提升联邦学习性能,我们在设备端提出双校准方法,该方法结合两种校准方式:1)第一种校准方式是利用增强后的数据训练局部模型,需注意的是,增强数据由GAN生成的IID数据集与原始non-IID数据集组成;2)第二种校准方式是在特征层面校准局部模型,以进一步消除设备间的模型不一致性。我们让每个被选中的设备利用 GAN 生成的独立同分布(IID)数据构建隐私友好(p-f)局部类别原型。这些隐私友好局部类别原型被上传至中央服务器,中央服务器分别对接收的模型参数和隐私友好局部类别原型执行聚合平均操作。设备的局部模型通过将自身的局部类别原型与来自中央服务器的隐私友好全局类别原型对齐,实现模型校准。需特别说明的是,SlaugFL 中存在两类原型:第一类是选定的局部类别原型,仅用于筛选目标候选样本或训练 ACGAN 模型;第二类是隐私友好局部类别原型,仅用于构建隐私友好全局类别原型,为设备局部模型校准提供支持。
C. 准备阶段
1)带标签候选数据的生成
我们利用公开可用的预训练稳定扩散(SD)模型³,基于联邦学习任务中的类别标签生成带标签候选数据DcandD^{\text{cand}}Dcand。所采用的SD模型在大规模数据集LAION-2B(en) [26]上训练而成,该数据集包含23.2亿个图文对,能够确保生成图像的多样性。为维持同类图像的多样性,我们借助ChatGPT为同一类别生成不同的提示词(prompts)。作为大型语言模型,ChatGPT可接收文本指令并生成相应的文本输出。例如,为获取“飞机”类别的不同提示词,我们首先与ChatGPT发起对话,发送文本指令“请生成100个描述飞机的不同提示词”,随后ChatGPT会输出一系列描述“飞机”的提示词(如“在蓝天上飞行的飞机”)。需注意的是,受文本长度限制,ChatGPT单次仅输出部分生成的提示词;如需继续生成,可发送“继续”等文本指令。为实现提示词的批量连续生成,我们开发了一个脚本与ChatGPT交互。本研究中,每个类别生成2000个提示词,并将这些提示词输入SD模型,最终得到带标签候选图像集DcandD^{\text{cand}}Dcand。
2)信息性ACGAN训练数据筛选
由于ChatGPT可能生成部分不合理的提示词,导致DcandD_{\text{cand}}Dcand中包含无效图像。例如:生成的“飞机”图像中未包含飞机主体;生成的“猫”图像为卡通风格,与设备摄像头拍摄的真实猫图像存在域差异。这些无效图像与设备本地数据的特征分布差距较大,会降低设备模型的训练精度。因此,必须筛选掉此类无效样本,保留特征分布与设备本地数据相近的带标签候选样本,作为ACGAN的训练数据。
为实现这一目标,我们从域适应视角出发,通过计算设备本地数据的类别原型与带标签候选样本的嵌入特征之间的距离,筛选出目标样本。距离越小的候选样本,越有可能来自设备本地数据的分布;我们将处于特定距离范围内的候选样本称为“信息性样本”。 为确定用于提取嵌入特征的模型,我们的直观思路如下:当面临不平衡训练数据时,存在偏倚的数据会使模型的判别倾向于训练数据中样本数量最多的类别。在非独立同分布(non-IID)联邦学习场景中,我们可为每个类别筛选出“类别代表模型”——这类模型对自身所属类别的预测置信度最高。对于设备本地数据的类别原型,它们应具有相互独立性,以便从带标签候选样本中筛选出类别间差异显著的数据样本。 由此,我们思考:由选定的类别代表模型学习到的类别原型是否具有可分性?为验证这一点,我们设计了一个简单实验:将CIFAR-10数据集[27]以非独立同分布的方式分配给100个参与设备。实验步骤如下: 1. 每个设备将其本地数据按7:3的比例划分为训练集和验证集,并在训练集上进行10轮迭代训练; 2. 从100个设备中,为10个类别分别筛选出性能最优的10个代表模型; 3. 利用这10个类别代表模型,分别从各自的本地训练集和验证集中提取嵌入特征; 4. 采用t-SNE[28]算法对收集到的嵌入特征进行可视化。 如图4所示,实验结果表明:1)选定的类别代表模型训练效果良好,因为训练样本与验证样本的特征分布几乎完全重叠;2)各类别的嵌入特征相互分离,这意味着对应的类别原型具有可分性。
关键术语与补充说明 1. informative samples(信息性样本):指与设备本地数据特征分布相近、能为模型训练提供有效信息的候选样本,筛选后可作为高质量ACGAN训练数据; 2. class representative models(类别代表模型):针对每个类别筛选的、对该类别预测置信度最高的设备局部模型,其学习到的类别原型具有更强的代表性和可分性; 3. t-SNE:t分布随机邻域嵌入(t-Distributed Stochastic Neighbor Embedding),是一种常用的高维数据降维与可视化算法,可将高维嵌入特征映射到二维/三维空间,便于观察类别分离情况; 4. 实验逻辑:通过验证“类别代表模型的特征可分性”,为后续利用这类模型提取的类别原型筛选候选样本提供合理性支撑——只有原型可分,才能有效区分候选样本的类别归属,确保筛选后的数据符合设备本地数据分布。
接下来,我们正式提出用于信息性样本筛选的选择性数据收集(SDC)算法(详见算法2):
SDC算法

1)M个客户端中的每个客户端均在本地执行H轮训练,并上传其训练后的模型: 具体而言,每个客户端将其本地数据DkD^kDk按7:3的比例划分为训练集DtrainkD_{\text{train}}^kDtraink和验证集DvalkD_{\text{val}}^kDvalk。随后,每个客户端在DtrainkD_{\text{train}}^kDtraink上执行局部更新(LocalUpdate(·))流程(H设为10)以训练局部模型,并采用早停(early stopping)策略防止模型过拟合。本地训练完成后,训练好的局部模型参数wkw^kwk将发送至中央服务器。
2)中央服务器在全局测试数据上对每个设备的模型进行测试: 在服务器端,接收的各设备模型会在全局测试集DtestgD_{\text{test}}^gDtestg上进行测试——因为全局测试性能可作为判断设备本地数据标签分布倾向的重要依据。例如,若设备k在类别a和类别b的数据样本上表现良好,但在其他类别上表现较差,则其本地数据DkD^kDk很可能以类别a和类别b的数据为主。
3)我们为每个类别筛选局部类别原型,而非收集设备原始数据: 考虑到若允许参与设备直接上传原始数据,将违反联邦学习中的隐私规则,因此我们仅要求目标类别集合CtarkC_{\text{tar}}^kCtark非空的设备,上传其对应的局部类别原型。具体来说,对于每个设备k,服务器需判断该设备是否拥有目标类别的数据,并将该数据类别记录到对应的聚类集合CtarkC_{\text{tar}}^kCtark中。例如,对于设备k,若其在全局测试集DtestgD_{\text{test}}^gDtestg中类别c数据上的Top-1测试准确率qckq_c^kqck在所有设备中最高,则类别{c}将被添加到其记录聚类集合CtarkC_{\text{tar}}^kCtark中,这表明设备k被选为该类别的代表性设备,其需上传由特征提取器ψw1k(⋅)\psi_{w_1^{k}}(\cdot)ψw1k(⋅)从类别c的验证数据Dval,ckD_{val,c}^kDval,ck中提取的c类局部类别原型Zk,cZ^{k,c}Zk,c。与此同时,被选中设备k的模型将被选为类别c的代表性模型wk,cw^{k,c}wk,c。值得注意的是,与共享本地原始数据相比,共享局部类别原型可避免大量通信开销,关于该方法引入的通信成本,我们将在第四节F部分展开讨论。
4)利用代表性模型集合Θrep\Theta^{rep}Θrep与选定的局部类别原型集合ZselZ^{sel}Zsel筛选信息性ACGAN训练样本: 为筛选出每个类别c的信息性样本,我们采用余弦距离作为筛选准则,具体如下:
Dcinfo={(xˋ,y)∈Dccand:y=c,dcos(ψw1k,c(xˋ),Zk,c)≤δ}(11) \mathcal{D}_{c}^{info} = \left\{(\grave{x}, y) \in \mathcal{D}_{c}^{cand} : y = c, d_{cos}\left(\psi_{w_1^{k,c}}(\grave{x}), Z^{k,c}\right) \leq \delta\right\} \tag{11} Dcinfo={(xˋ,y)∈Dccand:y=c,dcos(ψw1k,c(xˋ),Zk,c)≤δ}(11)
其中dcos(⋅)=1−cosim(⋅)d_{cos}(\cdot) = 1 - cosim(\cdot)dcos(⋅)=1−cosim(⋅),cosim(⋅)cosim(\cdot)cosim(⋅)表示余弦相似度。基于该筛选准则,我们可得到信息性ACGAN训练数据集Dinfo=⋃c∈[C]Dcinfo\mathcal{D}^{info} = \bigcup_{c \in [C]} \mathcal{D}_{c}^{info}Dinfo=⋃c∈[C]Dcinfo。本文中,为构建信息性ACGAN训练数据集Dinfo\mathcal{D}^{info}Dinfo,我们根据筛选准则(11),从带标签候选数据Dcand\mathcal{D}^{cand}Dcand中为每个类别选取排名前1000的图像。
3)ACGAN训练:受限于公开可用的预训练稳定扩散(SD)模型的训练数据,我们所采用的SD模型可能无法生成部分类别的数据。因此,我们针对ACGAN训练考虑以下两种场景:
1)所采用的SD模型能够为联邦学习(FL)任务中的每个类别生成候选样本(场景1): 在此场景下,我们直接在服务器端利用筛选得到的信息性训练数据集Dinfo\mathcal{D}^{info}Dinfo训练ACGAN模型。当ACGAN模型通过损失函数(9)和(10)完成合理训练后,即可生成目标类型的图像。
2)所采用的SD模型无法为联邦学习任务中的每个类别生成候选样本(场景2): 为使生成器生成合格图像,判别器与分类器需用信息性数据训练。因此,在缺乏信息性训练数据集Dinfo\mathcal{D}^{info}Dinfo的情况下,无法直接采用上述ACGAN训练方法。近期研究[29]、[30]表明,通过最小化源数据分布与合成数据分布之间的最大均值差异(MMD)[31]的经验估计值,合成数据可捕捉源数据分布特征。受此启发,我们对源数据分布与生成数据分布之间的MMD经验估计值进行优化。给定待生成数据的标签y,生成器输出对应的生成图像x~y=G(r,y;θG)\tilde{x}_y = G(r, y; \theta^G)x~y=G(r,y;θG)。生成数据与联邦学习设备本地数据之间的分布差异可通过以下公式衡量:
Lmmd=dℓ2(Ec,Zc)(12) \mathcal{L}_{mmd} = d_{\ell_2}\left(E^c, Z^c\right) \tag{12} Lmmd=dℓ2(Ec,Zc)(12)
其中,ZcZ^cZc来自ACGAN原型集合Zs=⋃c∈[C]{Zs,c:Zs,c=1U∑j=1Uψw1k,c(x~c,j),x~c,j∈Dcs,U=∣Dcs∣}Z^s = \bigcup_{c \in [C]} \{Z^{s,c} : Z^{s,c} = \frac{1}{U} \sum_{j=1}^{U} \psi_{w_1^{k,c}}(\tilde{x}_{c,j}), \tilde{x}_{c,j} \in D_c^s, U = |D_c^s|\}Zs=⋃c∈[C]{Zs,c:Zs,c=U1∑j=1Uψw1k,c(x~c,j),x~c,j∈Dcs,U=∣Dcs∣},且源自每轮训练中ACGAN生成的数据DsD^sDs;Ec∼PselE^c \sim P_{sel}Ec∼Psel来自集合ZselZ^{sel}Zsel。 此外,为避免生成器生成“固定风格模式”样本的模型坍缩问题,我们采用文献[32]中的多样性损失,以鼓励生成器输出多样化样本,公式如下:
Ldiv=(dℓ1(G(r1,y;θG),G(r2,y;θG))dℓ1(r1,r2))(13) \mathcal{L}_{div} = \left( \frac{d_{\ell_1}\left(G(r_1, y; \theta^G), G(r_2, y; \theta^G)\right)}{d_{\ell_1}(r_1, r_2)} \right) \tag{13} Ldiv=(dℓ1(r1,r2)dℓ1(G(r1,y;θG),G(r2,y;θG)))(13)
最终,在此场景下,我们直接训练不含判别器与分类器的ACGAN,其训练损失函数可表示为:
minθGEr∼Pr,y∼Pgen,E∼Psel[Lmmd+λdiv⋅Ldiv](14) \min_{\theta^G} \mathbb{E}_{r \sim \mathcal{P}_r, y \sim \mathcal{P}_{gen}, E \sim \mathcal{P}_{sel}} \left[ \mathcal{L}_{mmd} + \lambda_{div} \cdot \mathcal{L}_{div} \right] \tag{14} θGminEr∼Pr,y∼Pgen,E∼Psel[Lmmd+λdiv⋅Ldiv](14)
需注意的是,现有研究[14]、[33]为实现数据合成,要求设备向中央服务器暴露本地标签分布,这会侵犯设备隐私。因此,我们令Pgen\mathcal{P}_{gen}Pgen服从均匀分布,从而无需获取与EcE^cEc相关的数据标签分布。本文中,针对10类别数据,我们设λdiv=5×103\lambda_{div} = 5 \times 10^3λdiv=5×103;针对100类别数据,设λdiv=1×104\lambda_{div} = 1 \times 10^4λdiv=1×104。
为区分两种场景下训练的ACGAN模型所生成的数据,我们将场景1中ACGAN生成的数据称为“强合成数据”,将场景2中ACGAN生成的数据称为“弱合成数据”。
D. 设备端双校准
训练完成的生成器GGG能为联邦学习(FL)性能提升带来两方面益处:
1)生成数据与联邦学习设备本地数据具有相似域特性,可直接用于提升局部模型的分类能力;
2)生成数据可用于构建隐私友好(p-f)全局类别原型,进一步校准设备端局部模型。因此,我们从以下两个维度对局部模型进行校准。
1)利用增强数据校准局部模型: 为提升局部模型性能,最直接的策略是通过接收的ACGAN模型,将设备本地非独立同分布(non-IID)数据增强为独立同分布(IID)数据。但需注意,若直接按此策略生成合成数据,合成数据会继承原数据的non-IID特性。结合第四节A2部分的研究动机(IID合成数据比non-IID合成数据更能提升模型性能),我们选择生成与设备本地数据DkD^kDk规模相等的IID合成数据Dk_synD^{k\_syn}Dk_syn,用于扩充设备本地数据。增强后的数据Dk_syn∪DkD^{k\_syn} \cup D^kDk_syn∪Dk可缓解设备间数据异构性,并通过分类损失提升联邦学习性能,分类损失公式如下:
Lcla=Lce(σ(f(x;wk)),y)+λsynLce(σ(f(x^;wk)),y^)(15) \mathcal{L}_{cla} = \mathcal{L}_{ce}\left(\sigma\left(f\left(x; w^k\right)\right), y\right) + \lambda_{syn}\mathcal{L}_{ce}\left(\sigma\left(f\left(\hat{x}; w^k\right)\right), \hat{y}\right) \tag{15} Lcla=Lce(σ(f(x;wk)),y)+λsynLce(σ(f(x^;wk)),y^)(15) 其中,(x,y)∼Pk_loc(x, y) \sim \mathcal{P}_{k\_loc}(x,y)∼Pk_loc和(x^,y^)∼Pk_syn(\hat{x}, \hat{y}) \sim \mathcal{P}_{k\_syn}(x^,y^)∼Pk_syn分别从设备本地数据DkD^kDk和合成数据Dk_synD^{k\_syn}Dk_syn中采样得到。由于设备本地数据DkD^kDk与合成数据Dk_synD^{k\_syn}Dk_syn之间仍存在一定域偏移,我们引入超参数λsyn\lambda_{syn}λsyn来控制合成数据对模型训练的影响。对于强合成数据与弱合成数据,λsyn\lambda_{syn}λsyn均设为0.5。
2)利用隐私友好(p-f)全局类别原型校准局部模型: 第四节A2部分的研究动机表明,IID合成数据可进一步用于模型校准;此外,基于IID合成数据构建的全局类别原型能规避隐私风险。基于此,我们从域适应视角出发,通过最小化“由本地数据DkD^kDk生成的局部类别原型”与“p-f全局类别原型”之间的特征分布差异,进一步校准局部模型。 其中,本地类别原型Ztk=⋃c∈[O]{Ztk,c:Ztk,c=1U∑j=1Uψwt,1k(xc,j),xc,j∈Dck,U=∣Dck∣}Z_t^k = \bigcup_{c \in [O]} \{Z_t^{k,c} : Z_t^{k,c} = \frac{1}{U} \sum_{j=1}^U \psi_{w_{t,1}^k}(x_{c,j}), x_{c,j} \in D_c^k, U = |D_c^k|\}Ztk=⋃c∈[O]{Ztk,c:Ztk,c=U1∑j=1Uψwt,1k(xc,j),xc,j∈Dck,U=∣Dck∣}(O≤CO \leq CO≤C,OOO为设备本地数据包含的类别数,CCC为任务总类别数);p-f全局类别原型Zˉt\bar{Z}_tZˉt由设备上传的“基于IID合成数据生成的p-f局部类别原型Z^t\hat{Z}_tZ^t”聚合得到。通过这种方式,所有局部模型将尝试维持一致的可分离嵌入特征空间,从而实现更快的模型收敛速度与更高的模型精度。 为实现这一目标,我们引入距离度量Lsep\mathcal{L}_{sep}Lsep。现有研究[8]、[10]表明,对比损失比ℓ2\ell_2ℓ2损失更能提升模型性能,因为对比损失可使不同类别的聚类在特征空间中距离更远。具体而言,这些研究利用对比损失使样本xc,jx_{c,j}xc,j的嵌入特征向对应类别的全局原型靠拢,同时远离其他类别的全局原型。本文同样采用对比损失作为距离度量,公式如下: Lsep=−logexp(cosim(Zˉtc,Zti)/β)∑c=1Cexp(cosim(Zˉtc,Zti)/β)(16) \mathcal{L}_{sep} = -\log \frac{\exp\left(\text{cosim}\left(\bar{Z}_t^c, Z_t^i\right)/\beta\right)}{\sum_{c=1}^C \exp\left(\text{cosim}\left(\bar{Z}_t^c, Z_t^i\right)/\beta\right)} \tag{16} Lsep=−log∑c=1Cexp(cosim(Zˉtc,Zti)/β)exp(cosim(Zˉtc,Zti)/β)(16) 其中,β\betaβ为标量温度参数,ZtiZ_t^iZti来自局部类别原型集合ZtkZ_t^kZtk,Zˉtc∼Ppfgp\bar{Z}_t^c \sim \mathcal{P}_{pfgp}Zˉtc∼Ppfgp来自p-f全局类别原型集合Zˉt\bar{Z}_tZˉt。 与现有研究[8]、[9]、[10]相比,本文方法存在两点差异:1)我们的对比损失使局部类别原型向对应p-f全局类别原型靠拢,同时远离其他类别的p-f全局原型;通过三次重复实验发现,使用局部类别原型比使用样本嵌入特征能实现更高的精度与更低的方差;2)如第二节所述,为使全局类别原型覆盖所有类别,现有研究每轮通信需收集所有设备的局部类别原型;而本文方法每轮通信仅需选定设备上传p-f局部类别原型Z^tk\hat{Z}_t^kZ^tk,这一优势得益于IID合成数据的特性。 结合公式Lcla\mathcal{L}_{cla}Lcla与Lsep\mathcal{L}_{sep}Lsep,设备端局部模型训练的整体目标函数可表示为:
minwkE(x,y)∼Pk_loc,(x^,y^)∼Pk_syn,Zˉt∼Ppfgp[Lcla+λsepLsep](17) \min_{w^k} \mathbb{E}_{(x,y) \sim \mathcal{P}_{k\_loc}, (\hat{x},\hat{y}) \sim \mathcal{P}_{k\_syn}, \bar{Z}_t \sim \mathcal{P}_{pfgp}} \left[\mathcal{L}_{cla} + \lambda_{sep}\mathcal{L}_{sep}\right] \tag{17} wkminE(x,y)∼Pk_loc,(x^,y^)∼Pk_syn,Zˉt∼Ppfgp[Lcla+λsepLsep](17) 本文中,超参数设置为λsep=1\lambda_{sep}=1λsep=1,β=0.5\beta=0.5β=0.5。通过上述双校准方法更新局部模型后,每个客户端利用IID合成数据Dk_synD^{k\_syn}Dk_syn(而非涉及隐私的本地数据DkD^kDk)更新p-f局部类别原型Z^tk=⋃c∈[C]{Z^tk,c:Z^tk,c=1U∑j=1Uψwt,1k(x^c,j),x^c,j∈Dck_syn,U=∣Dck_syn∣}\hat{Z}_t^k = \bigcup_{c \in [C]} \{\hat{Z}_t^{k,c} : \hat{Z}_t^{k,c} = \frac{1}{U} \sum_{j=1}^U \psi_{w_{t,1}^k}(\hat{x}_{c,j}), \hat{x}_{c,j} \in D_c^{k\_syn}, U = |D_c^{k\_syn}|\}Z^tk=⋃c∈[C]{Z^tk,c:Z^tk,c=U1∑j=1Uψwt,1k(x^c,j),x^c,j∈Dck_syn,U=∣Dck_syn∣},并将其上传至中央服务器。
E. SlaugFL算法
本研究提出的SlaugFL算法以联邦平均(FedAvg)算法为基础,核心流程总结于算法3中。首先,算法引入准备阶段,目标是训练出性能良好的ACGAN模型,并将其分发给所有参与设备。具体而言,我们采用当前最先进的文本-图像生成模型——稳定扩散(SD)模型,生成带标签的候选数据;为构建信息性ACGAN训练数据集DinfoD^{info}Dinfo,我们提出选择性数据收集(SDC)算法,从候选数据中筛选出目标样本。准备阶段完成后,中央服务器将训练好的生成器GGG广播至MMM个设备,并启动联邦学习协同训练。 与FedAvg算法不同,在服务器端,除了对模型权重进行加权平均外,中央服务器还需执行一项额外的聚合操作——对收集到的隐私友好(p-f)局部类别原型进行平均。随后,中央服务器在第ttt轮通信中,将新的全局模型权重与新的p-f全局类别原型广播给本轮选中的设备。 在设备端,每个设备利用接收到的生成器GGG生成强合成数据或弱合成数据,用于扩充本地的非独立同分布(non-IID)数据,且该数据生成与扩充操作仅需执行一次。通过数据扩充,局部模型性能可直接得到提升;此外,我们采用对比损失最小化“本地类别原型”与“p-f全局类别原型”之间的特征分布差异,进一步优化局部模型。当设备端完成局部迭代训练后,将利用更新后局部模型的特征提取器,构建新的p-f局部类别原型,用于下一轮服务器端的聚合操作。经过TTT轮通信后,最终得到训练完成的全局模型wTw_TwT。
F. SlaugFL的通信成本分析
与FedAvg算法相比,SlaugFL产生的额外通信成本主要来自两部分:准备阶段,以及服务器与设备之间的协同训练过程。为简化分析,我们定义以下参数:dmd_mdm为模型参数数量,dpd_pdp为类别原型的维度,dgd_gdg为生成器GGG的参数数量。 在准备阶段,MMM个设备需将各自训练好的局部模型发送至中央服务器,随后中央服务器收集CCC个类别的局部类别原型,因此准备阶段的总通信成本为Mdm+CdpM d_m + C d_pMdm+Cdp。ACGAN模型训练完成后,中央服务器将训练好的生成器GGG广播至MMM个设备,这一过程产生的通信成本为MdgM d_gMdg。 在协同训练阶段,SlaugFL要求中央服务器将当前的p-f全局类别原型发送给本轮选中的KKK个设备,同时这些设备需将新的p-f局部类别原型回传至中央服务器。经过TTT轮通信后,该阶段产生的额外通信成本为T×2KCdpT \times 2 K C d_pT×2KCdp。 综上,SlaugFL引入的总额外通信成本可表示为: M(dm+dg)+Cdp+2TKCdpM (d_m + d_g) + C d_p + 2 T K C d_pM(dm+dg)+Cdp+2TKCdp。 对于FedAvg算法,经过TTT轮训练通信后,模型参数交换产生的通信成本为2TKdm2 T K d_m2TKdm。因此,SlaugFL的额外通信成本与FedAvg的模型参数交换成本之比可估算为:
R=M(dm+dg)+Cdp+2TKCdp2TKdm≈M(dm+dg)2TKdm+Cdpdm=Re(18) R = \frac{M (d_m + d_g) + C d_p + 2 T K C d_p}{2 T K d_m} \approx \frac{M (d_m + d_g)}{2 T K d_m} + \frac{C d_p}{d_m} = R_e \tag{18} R=2TKdmM(dm+dg)+Cdp+2TKCdp≈2TKdmM(dm+dg)+dmCdp=Re(18)
其中,近似关系≈\approx≈成立的依据是Cdp≪2TKdmC d_p \ll 2 T K d_mCdp≪2TKdm(即类别原型的总数据量远小于模型参数交换的数据量)。 我们在第五节E部分对整体成本(包括上述额外成本与通信轮次)进行了实验评估,结果表明:SlaugFL引入的额外成本规模较小,且通过减少通信轮次节省的开销,远大于该额外成本。 # E. SlaugFL算法 本研究提出的SlaugFL算法以联邦平均(FedAvg)算法为基础,核心流程总结于算法3中。首先,算法引入准备阶段,目标是训练出性能良好的ACGAN模型,并将其分发给所有参与设备。具体而言,我们采用当前最先进的文本-图像生成模型——稳定扩散(SD)模型,生成带标签的候选数据;为构建信息性ACGAN训练数据集DinfoD^{info}Dinfo,我们提出选择性数据收集(SDC)算法,从候选数据中筛选出目标样本。准备阶段完成后,中央服务器将训练好的生成器GGG广播至MMM个设备,并启动联邦学习协同训练。 与FedAvg算法不同,在服务器端,除了对模型权重进行加权平均外,中央服务器还需执行一项额外的聚合操作——对收集到的隐私友好(p-f)局部类别原型进行平均。随后,中央服务器在第ttt轮通信中,将新的全局模型权重与新的p-f全局类别原型广播给本轮选中的设备。 在设备端,每个设备利用接收到的生成器GGG生成强合成数据或弱合成数据,用于扩充本地的非独立同分布(non-IID)数据,且该数据生成与扩充操作仅需执行一次。通过数据扩充,局部模型性能可直接得到提升;此外,我们采用对比损失最小化“本地类别原型”与“p-f全局类别原型”之间的特征分布差异,进一步优化局部模型。当设备端完成局部迭代训练后,将利用更新后局部模型的特征提取器,构建新的p-f局部类别原型,用于下一轮服务器端的聚合操作。经过TTT轮通信后,最终得到训练完成的全局模型wTw_TwT。 # F. SlaugFL的通信成本分析 与FedAvg算法相比,SlaugFL产生的额外通信成本主要来自两部分:准备阶段,以及服务器与设备之间的协同训练过程。为简化分析,我们定义以下参数:dmd_mdm为模型参数数量,dpd_pdp为类别原型的维度,dgd_gdg为生成器GGG的参数数量。 在准备阶段,MMM个设备需将各自训练好的局部模型发送至中央服务器,随后中央服务器收集CCC个类别的局部类别原型,因此准备阶段的总通信成本为Mdm+CdpM d_m + C d_pMdm+Cdp。ACGAN模型训练完成后,中央服务器将训练好的生成器GGG广播至MMM个设备,这一过程产生的通信成本为MdgM d_gMdg。 在协同训练阶段,SlaugFL要求中央服务器将当前的p-f全局类别原型发送给本轮选中的KKK个设备,同时这些设备需将新的p-f局部类别原型回传至中央服务器。经过TTT轮通信后,该阶段产生的额外通信成本为T×2KCdpT \times 2 K C d_pT×2KCdp。 综上,SlaugFL引入的总额外通信成本可表示为: M(dm+dg)+Cdp+2TKCdpM (d_m + d_g) + C d_p + 2 T K C d_pM(dm+dg)+Cdp+2TKCdp。 对于FedAvg算法,经过TTT轮训练通信后,模型参数交换产生的通信成本为2TKdm2 T K d_m2TKdm。因此,SlaugFL的额外通信成本与FedAvg的模型参数交换成本之比可估算为: R=M(dm+dg)+Cdp+2TKCdp2TKdm≈M(dm+dg)2TKdm+Cdpdm=Re(18) R = \frac{M (d_m + d_g) + C d_p + 2 T K C d_p}{2 T K d_m} \approx \frac{M (d_m + d_g)}{2 T K d_m} + \frac{C d_p}{d_m} = R_e \tag{18} R=2TKdmM(dm+dg)+Cdp+2TKCdp≈2TKdmM(dm+dg)+dmCdp=Re(18) 其中,近似关系≈\approx≈成立的依据是Cdp≪2TKdmC d_p \ll 2 T K d_mCdp≪2TKdm(即类别原型的总数据量远小于模型参数交换的数据量)。 我们在第五节E部分对整体成本(包括上述额外成本与通信轮次)进行了实验评估,结果表明:SlaugFL引入的额外成本规模较小,且通过减少通信轮次节省的开销,远大于该额外成本。
实验评估
本节旨在验证所提出的SlaugFL算法的有效性。我们在两个主流联邦学习基准数据集上,结合多种非独立同分布(non-IID)数据场景开展实验。为充分展现SlaugFL的性能,第五节B部分将其与现有主流方法进行对比,对比维度包括模型精度与通信效率;第五节C部分分析相关超参数对算法性能的影响;第五节D部分剖析SlaugFL的隐私安全性;第五节E部分评估SlaugFL引入的额外通信成本;第五节F部分通过消融实验验证所引入的稳定扩散(SD)模型与ChatGPT的有效性;最后,为进一步验证SlaugFL的性能,第五节G部分在真实数据集与真实边缘设备上对其进行评估。 所有实验均采用三个不同的随机种子重复执行三次:后续表格中,每个条目均包含平均值与标准差结果;后续图表中,每条曲线均采用三次实验结果的平均值绘制。
A. 实验设置
1)基线方法:我们选取6种现有主流方法作为对比基线,包括FedAvg[3]、FedProx[5]、Scaffold[6]、Moon[7]、VHL[15]和FedGen[14]。
2)数据集与非独立同分布(non-IID)数据分布模拟: 我们在两个常用的联邦学习基准数据集(CIFAR-10和CIFAR-100[27])上开展实验。其中,CIFAR-10包含10个类别的互联网图像,每个类别有6000张图像;CIFAR-100的任务难度高于CIFAR-10,包含100个图像类别,每个类别有600张图像。这两个数据集均用于图像分类任务。
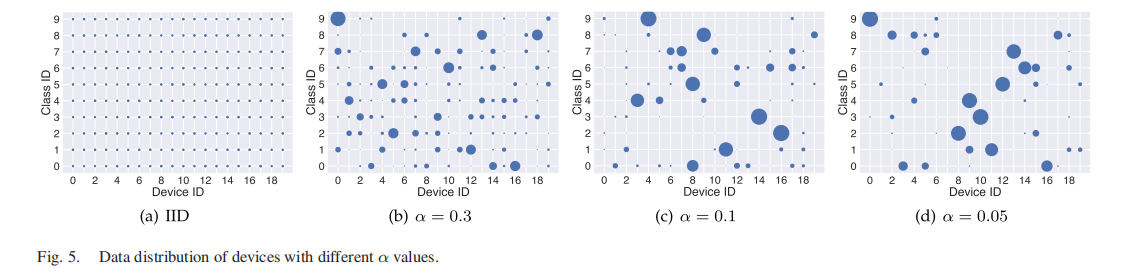
为模拟设备端数据的non-IID分布,我们采用狄利克雷分布(Dirichlet distribution)Dir(α)Dir(\alpha)Dir(α)[34]。参数α\alphaα用于控制设备数据的异构程度:α\alphaα值越小,设备间的数据量不均衡程度越高,类别分布偏差也越大。具体而言,实验中设置三种non-IID数据场景:当α=0.05\alpha=0.05α=0.05时,每个类别的图像几乎仅归属于一个设备,对应极端non-IID场景;设置α=0.3\alpha=0.3α=0.3模拟常见non-IID场景;设置α=0.1\alpha=0.1α=0.1模拟挑战性non-IID场景。需注意的是,各设备的数据量存在差异,这与实际non-IID场景更贴合。 此外,在局部模型训练阶段,我们对SlaugFL及所有对比方法均采用“随机裁剪(RandomCrop)”和“随机水平翻转(RandomHorizontalFlip)”两种数据增强技术。我们通过气泡图(图5)展示20个设备在三种不同α\alphaα值下的数据分布情况:气泡大小代表分配给对应设备的数据量,α\alphaα值越小,各设备的数据分布偏差越显著。在第四节A2部分的实验中,CIFAR-10数据集的α\alphaα值设为0.1。
3)模型架构: 在CIFAR-10和CIFAR-100数据集上,SlaugFL与所有对比方法均采用ResNet18[35]作为联邦学习的局部模型架构。ResNet18包含5个卷积组、1个平均池化层和1个全连接(FC)层,我们将其分为两部分:特征提取器ψ(⋅)\psi(\cdot)ψ(⋅)(包含5个卷积组和平均池化层)和预测器g(⋅)g(\cdot)g(⋅)(即全连接层)。ResNet18的输入图像尺寸为32×32,特征提取器的输出维度为512。 针对两种ACGAN训练场景,我们采用不同的ACGAN架构: - 场景1(SD模型可生成所有类别候选数据):为提升合成图像质量,采用广泛使用的公开ACGAN架构⁴; - 场景2(SD模型无法生成部分类别候选数据):由于弱合成数据的模式较简单,ACGAN生成器采用与文献[36]中相同的架构。 关于生成器的噪声维度:场景1中,10类别数据和100类别数据的噪声维度均设为110(针对100类别数据,我们搭建10个ACGAN模型,每个模型仅负责10个类别的训练);场景2中,10类别数据的噪声维度设为100,100类别数据的噪声维度设为256。对于FedGen,我们调整其GAN模型架构以适配实验所用数据集,具体采用文献[36]中FedGen的GAN模型架构。 > ⁴[在线获取] 链接:https://github.com/clvrai/ACGAN-PyTorch
4)超参数设置: 实验采用典型的联邦学习架构:每个参与设备拥有本地数据,中央服务器负责与设备间的信息收发。超参数设置参考使用CIFAR-10/CIFAR-100数据集的对比基线方法[3]、[7]、[15],具体如下: - 参与联邦协同训练的设备总数M=100M=100M=100; - 实验验证SlaugFL与所有对比基线可在300轮内收敛,因此最大通信轮次T=300T=300T=300; - 采用10%的设备选择比例(常用比例),每轮通信从100个设备中随机选取K=10K=10K=10个设备进行参数聚合; - 局部模型训练阶段:批次大小b=64b=64b=64,每个设备执行H=10H=10H=10轮局部训练;采用随机梯度下降(SGD)优化器,初始学习率设为0.01,权重衰减设为5×10−45\times10^{-4}5×10−4,并采用指数衰减策略(衰减因子为0.998); - ACGAN模型训练:采用Adam优化器以加快收敛,初始学习率设为0.01,权重衰减设为1×10−41\times10^{-4}1×10−4;FedGen的GAN模型也采用相同的学习率与权重衰减值; - FedProx和Moon通过额外超参数μ\muμ控制惩罚项权重:参考文献[7]、[33],FedProx的μ=0.01\mu=0.01μ=0.01,Moon的μ=1\mu=1μ=1。 除非特别说明,上述超参数均为默认设置。此外,所有方法均基于PyTorch[37]框架实现。
B. 性能对比
本小节从以下两个维度评估所提出的SlaugFL算法性能:
1)模型精度: 我们在不同非独立同分布(non-IID)数据场景下开展模型精度对比实验,将SlaugFL与6种主流算法进行性能较量。SlaugFL分为两种实验场景:场景1对应ACGAN的训练场景1,场景2对应ACGAN的训练场景2。 表1展示了所有方法在non-IID CIFAR-10和CIFAR-100数据集上的Top-1测试精度。实验结果表明,随着α\alphaα值减小(数据异构性增强),所有方法的Top-1测试精度均逐渐下降;而SlaugFL在不同non-IID场景下均优于所有对比算法。特别在极端non-IID数据场景(α=0.05\alpha=0.05α=0.05)中,SlaugFL在两个数据集上均展现出显著性能优势:在CIFAR-10上,SlaugFL(场景1)的精度比次优方法VHL高出14.44%;在CIFAR-100上,SlaugFL(场景1)比FedProx高出3.93%。此外,SlaugFL(场景2)与SlaugFL(场景1)的对比结果表明,在极端non-IID场景中,强合成数据对提升模型精度具有重要作用。在挑战性non-IID场景(α=0.1\alpha=0.1α=0.1)和常见non-IID场景(α=0.3\alpha=0.3α=0.3)中,SlaugFL同样实现了可观的精度提升——例如在non-IID CIFAR-100(α=0.3\alpha=0.3α=0.3)上,SlaugFL(场景1)比次优方法Moon的精度提升3.70%。 值得注意的是,VHL在面对大量类别和较大局部训练轮次时(如本实验中non-IID CIFAR-100数据集与局部训练轮次H=10H=10H=10),无法有效校准局部模型[15];而FedGen仅在极端CIFAR-10数据场景(α=0.05\alpha=0.05α=0.05)下,精度高于FedAvg、Scaffold和Moon。这是因为FedGen仅校准模型的分类层,而分类层在整个模型中占比极小,仅靠校准分类层不足以应对复杂数据集(如CIFAR-100)。上述结果充分证明,SlaugFL在提升模型精度方面具有切实有效性。
2)通信效率: 为评估SlaugFL的通信效率,我们在三种non-IID数据分布下的CIFAR-10和CIFAR-100数据集上开展对比实验,从两个角度衡量通信效率:① 达到目标Top-1测试精度所需的通信轮次;② 经过200轮通信后,算法能达到的Top-1测试精度。
表2展示了CIFAR-10数据集上的实验结果。在极端non-IID数据场景(α=0.05\alpha=0.05α=0.05)中:经过200轮通信,次优方法VHL的Top-1测试精度为41.22%,而SlaugFL(场景1)将其提升11.87%;达到30%的目标Top-1测试精度时,VHL平均需要80.67轮,而SlaugFL(场景1)仅需38.33轮,相较于VHL大幅降低通信开销(最高达52.49%)。此外,SlaugFL(场景2)达到30%精度平均需要141.33轮,相较于FedAvg、Scaffold和Moon(需注意,Moon仅一次达到30%精度),仍加快了模型收敛速度。在挑战性non-IID场景(α=0.1\alpha=0.1α=0.1)和常见non-IID场景(α=0.3\alpha=0.3α=0.3)中,SlaugFL依旧能提升模型收敛速度——例如在挑战性non-IID场景(α=0.1\alpha=0.1α=0.1)下,达到相同的65%目标Top-1测试精度时,SlaugFL相较于次优方法VHL,通信成本至少降低21.78%(最高达50.50%)。
表3展示了CIFAR-100数据集上的实验结果,进一步体现了SlaugFL的优势,其性能优于所有对比算法。以极端non-IID数据场景(α=0.05\alpha=0.05α=0.05)为例:经过200轮通信,次优方法FedProx的Top-1测试精度为50.04%,而SlaugFL(场景2)将其提升4.40%;达到45%的目标Top-1测试精度时,FedProx平均需要134.33轮,而SlaugFL(场景2)仅需86.00轮,减少了35.98%的通信成本。此外,在常见non-IID场景(α=0.3\alpha=0.3α=0.3)下,达到相同的60%目标Top-1测试精度时,SlaugFL相较于次优方法FedProx,通信成本至少降低31.08%(最高达39.93%)。
综上,① 在相同通信轮次下,SlaugFL能实现更高的Top-1测试精度;② 达到目标Top-1测试精度时,SlaugFL所需通信轮次更少。我们还绘制了所有方法在α=0.1\alpha=0.1α=0.1的CIFAR-10和CIFAR-100数据集上的测试精度曲线(图6)。从图中可清晰观察到,SlaugFL在模型收敛速度上始终优于所有对比算法。上述所有结果表明,在各类non-IID数据场景下,SlaugFL相较于现有主流方法均具有竞争力,且在降低通信成本方面优势显著(在α=0.05\alpha=0.05α=0.05的CIFAR-10数据集上达到30%目标Top-1测试精度时,通信成本最高降低52.49%)。
C. 相关超参数分析
本节分别研究不同局部训练轮次HHH、不同选中设备数量KKK以及不同选中局部类别原型数量SSS对算法性能的影响。
1)局部训练轮次的影响: 从直观上看,局部训练轮次HHH过大或过小均会对模型精度产生负面影响。当HHH较小时,各设备的局部模型无法充分训练,易导致模型欠拟合;当HHH较大时,局部模型则会出现过拟合现象。 为探究HHH的影响,我们选取另外四个常用的轮次值:1、5、15和20,并相应地将最大通信轮次TTT分别设置为3000、600、200和150——这样设置是为了确保四种不同参数组合下,模型的总训练轮次保持一致(均为3000轮)。此外,SlaugFL与所有对比方法的实验均在α=0.1\alpha=0.1α=0.1的非独立同分布(non-IID)CIFAR-10数据集上进行。 图7展示了所有方法在不同局部训练轮次下的Top-1测试精度。结果显示,随着HHH的增加,所有方法的Top-1测试精度均先上升,并在H=5H=5H=5时达到最高值;当H>5H>5H>5时,所有方法的精度均出现下降。这一现象可解释为:较大的HHH会使局部模型过度聚焦于本地数据特征,导致各设备局部模型之间的差异(发散度)增大,进而影响全局模型性能。 需注意的是,仅当H=5H=5H=5时,VHL的精度略高于SlaugFL;在其他所有HHH值下,SlaugFL均优于所有对比方法,其中SlaugFL(场景1)的表现尤为突出。
2)选中设备数量的影响: 为探究不同选中设备数量KKK的影响,我们选取另外四个常用的设备选择比例:15%、20%、25%和30%(若总设备数为100,则对应的选中设备数量分别为15、20、25和30)。本实验在α=0.1\alpha=0.1α=0.1的非独立同分布(non-IID)CIFAR-10数据集上开展。 如图8所示,随着KKK的增加,模型精度逐渐提升;在不同选中设备数量下,SlaugFL均保持较高性能(效率)。 需特别说明的是,VHL的性能与SlaugFL相当。
3)选中局部类别原型数量的影响: 在本文提出的准备阶段(算法2)中,选中局部类别原型的数量SSS等于训练数据集的类别数。以CIFAR-10数据集为例,我们从设备中总共选中10个局部类别原型。 为探究不同选中局部类别原型数量对SlaugFL性能的影响,实验在α=0.1\alpha=0.1α=0.1的非独立同分布(non-IID)CIFAR-10数据集上开展。除默认值(CIFAR-10数据集对应S=10S=10S=10)外,我们还选取另外四个数值:1、5、15和20,具体设置规则如下: - 当SSS小于训练数据集类别数时(如S=1S=1S=1或S=5S=5S=5):从10个类别中随机选取1个或5个作为目标类别,筛选出“在这些目标类别上Top-1测试精度最高”的设备,要求其向服务器上传对应的局部类别原型。例如,若设置S=5S=5S=5,选择性数据收集(SDC)算法会筛选5个对应设备上传局部类别原型; - 当SSS大于训练数据集类别数时(如S=15S=15S=15或S=20S=20S=20):若设置S=15S=15S=15,除筛选“在10个类别上Top-1测试精度最高”的10个设备外,SDC算法还会额外筛选5个设备(这些设备在5个随机类别的Top-1测试精度排名第二);若设置S=20S=20S=20,SDC算法会筛选20个设备(这些设备在10个类别上的Top-1测试精度为最高或第二高),并要求其上传对应的局部类别原型。 需注意的是,在这些选中的局部类别原型中,若某一类别对应多个局部类别原型,我们会对这些原型取平均值,确保每个类别仅对应一个局部类别原型。随后,我们利用这些选中的局部类别原型开展后续操作:要么筛选目标GAN训练样本,并基于这些样本训练GAN模型(即SlaugFL场景1);要么直接利用这些原型训练GAN模型(即SlaugFL场景2)。 如图9所示,当选中局部类别原型数量SSS从1增加到10时,SlaugFL的Top-1测试精度逐渐上升,这是因为更多的选中原型能提升GAN模型的训练质量;当S>10S>10S>10时,由于对选中原型进行了均值处理,SlaugFL的精度略有下降。从Top-1测试精度结果可知,SSS的最优值为10(即CIFAR-10数据集的类别数)。此外,当S>10S>10S>10时,还会产生更多额外通信成本。因此,在本设计中,我们将选中局部类别原型的数量设置为训练数据集的类别数。
D. SlaugFL的隐私性分析
在准备阶段,我们提出的选择性数据收集(SDC)算法首先要求每个设备上传其训练后的局部模型wkw^kwk,随后从被选中的设备kkk中收集局部类别原型Zk,cZ^{k,c}Zk,c。为探究被选中的局部类别原型Zk,cZ^{k,c}Zk,c及对应的训练后局部模型(即代表性模型)wk,cw^{k,c}wk,c是否会泄露设备本地数据隐私,我们针对两种常见攻击方式展开分析:成员推断攻击与数据重构攻击。
成员推断攻击的防御性 若要对局部类别原型Zk,cZ^{k,c}Zk,c实施成员推断攻击,攻击者需掌握生成Zk,cZ^{k,c}Zk,c所用到的数据的具体信息(例如图像数量)。但在SlaugFL中,每个设备不会向其他设备或中央服务器泄露任何关于其验证集数据的信息——需注意,Zk,cZ^{k,c}Zk,c是从设备本地数据划分出的验证集中生成的,该验证集占设备本地数据的30%(详见第四节C2部分)。因此,对Zk,cZ^{k,c}Zk,c实施成员推断攻击是不可行的。
数据重构攻击的防御性 由于类别原型是某类数据实例嵌入特征向量的均值,数据重构攻击成为最主要的隐私威胁。我们设定如下攻击场景:攻击者获取局部类别原型Zk,cZ^{k,c}Zk,c与代表性模型wk,cw^{k,c}wk,c,并采用文献[33]、[38]中的特征逆推方法,验证设备本地数据是否可被重构。 数据重构攻击的具体实施流程为:攻击者首先向重构网络(如自编码器网络)输入随机噪声向量,生成重构图像;随后将该重构图像输入代表性模型wk,cw^{k,c}wk,c,提取其嵌入特征向量;重构网络的目标是生成包含与Zk,cZ^{k,c}Zk,c相关原始信息的图像,实现方式是最小化Zk,cZ^{k,c}Zk,c与提取的嵌入特征向量之间的距离。
我们在α=0.1\alpha=0.1α=0.1的非独立同分布(non-IID)CIFAR-10数据集上开展数据重构攻击实验,并考虑两种极端情况(每种被选中的局部类别原型Zk,cZ^{k,c}Zk,c仅由两张图像生成): 1)对于前5个类别的Zk,cZ^{k,c}Zk,c:从被选中设备的验证集中随机选取两张图像生成原型; 2)对于后5个类别的Zk,cZ^{k,c}Zk,c:从被选中设备的验证集中随机选取一张图像,再通过随机裁剪(RandomCrop)、随机旋转(RandomRotation)等数据增强技术生成另一张图像,最终用这两张图像生成原型。 数据重构攻击的结果如图10所示:在上述两种情况下,重构图像与原始图像存在显著差异,攻击者无法从重构图像中获取任何关于原始图像的信息。此外,在实际应用中,Zk,cZ^{k,c}Zk,c通常由两张以上的图像生成,这会进一步增加数据重构攻击的难度。 综上,我们认为SlaugFL能够有效保护设备本地数据隐私。
为进一步保护数据隐私,可将部分隐私保护技术与SlaugFL相结合。例如,在上传局部类别原型前,可采用差分隐私技术[39]为其添加噪声,或直接通过密码学技术[40]对其进行加密。
E. 额外通信成本评估
由于这些超参数已知,我们根据公式(18),在CIFAR-10和CIFAR-100训练任务的超参数默认设置下,直接计算出了额外通信成本占比ReR_eRe。需特别说明的是,在CIFAR-100(场景1)中,生成器的最终参数数量为1.6M×101.6\text{M} \times 101.6M×10,这是因为我们为100类数据训练了10个ACGAN模型。对于ResNet18模型,由于其特征提取器的输出维度为512,因此类别原型的参数维度dpd_pdp为512。 如表4所示,ReR_eRe的最大值为4.48%。考虑到SlaugFL最多可减少52.49%的通信轮次,我们认为所提方法节省的开销远大于引入的额外成本。
F. 消融实验
本小节通过消融实验验证所引入的ChatGPT组件与稳定扩散(SD)模型组件的有效性。所有消融实验均采用第五节A4部分所述的默认超参数设置。
1)ChatGPT组件的有效性验证 我们从两个维度验证ChatGPT在SlaugFL中的有效性:
(1)SD模型生成图像的类内多样性 对比“未结合ChatGPT的SD模型”(采用类别标签替代提示词)与“结合ChatGPT的SD模型”生成图像的类内多样性。图11展示了两类模型的生成结果:虚线左侧为未结合ChatGPT的SD模型生成的图像,右侧为结合ChatGPT的SD模型生成的图像。显然,右侧图像的类内多样性更丰富——以鸟类图像为例,结合ChatGPT的SD模型生成的鸟类图像包含五种不同的鸟类物种。
(2)SlaugFL的性能提升效果 通过消融实验验证:移除设计中的ChatGPT后,SlaugFL是否仍能实现同等性能提升。我们将移除ChatGPT的方法记为“SlaugFL(无ChatGPT)”,并选取SlaugFL(场景1)作为基线(注:SlaugFL(场景2)是SD模型无法为所有类别生成候选样本的情况,未使用ChatGPT与SD模型,因此不适合作为基线)。实验在非独立同分布(non-IID)CIFAR-10数据集上开展: - 模型精度方面(表5):SlaugFL(无ChatGPT)的性能出现下降,在三种不同non-IID数据场景下,精度分别损失1.39%、0.18%和0.74%; - 通信效率方面(表6):SlaugFL(场景1)优于SlaugFL(无ChatGPT)——相同通信轮次下,SlaugFL(场景1)的Top-1测试精度更高;达到目标Top-1测试精度时,SlaugFL(场景1)所需轮次更少。 上述实验结果表明,ChatGPT能有效提升SlaugFL的性能,这一提升得益于ChatGPT为生成图像带来的更丰富类内多样性。
2)SD模型组件的有效性验证 我们将SD模型与BigGAN模型[41]进行对比——BigGAN是ImageNet ILSVRC 2012数据集[42]上的主流生成模型,该数据集对GAN模型具有挑战性,包含1000个类别、约130万张图像。从三个维度验证SD模型的优势:
(1)生成样本的质量 如图12所示,虚线左侧为BigGAN模型生成的图像,右侧为结合ChatGPT的SD模型生成的图像。BigGAN的样本质量无法达到结合ChatGPT的SD模型水平(例如,BigGAN生成的飞机图像存在不完整问题);此外,在生成图像的类内多样性方面,BigGAN也劣于结合ChatGPT的SD模型。
(2)数据类别的多样性 由于GAN模型的对抗性训练目标,其存在模式坍缩[32]和训练难度大等问题,难以在大规模数据集(如大规模图文对数据集)上训练,因此现有GAN模型能生成的数据类别有限。相比之下,SD模型的训练过程更稳定,可在更大规模数据集上训练(例如包含23.2亿个图文对的LAION-2B(en)数据集[26]),训练后的SD模型能提供更丰富的数据类别——这与本设计中“生成模型需尽可能覆盖更多数据类别”的需求高度契合。
(3)SlaugFL的性能提升效果 通过消融实验验证SD模型的有效性:选取SlaugFL(场景1)作为基线,将SD模型替换为BigGAN模型的方法记为“SlaugFL(BigGAN)”⁵。由于BigGAN无法生成“鹿(deer)”类数据,我们从CIFAR-10数据集中剔除该类数据,得到CIFAR-9数据集,并在non-IID CIFAR-9数据集上开展对比实验: - 模型精度方面(表7):SlaugFL(BigGAN)的性能出现下降,在三种不同non-IID数据场景下,精度分别损失1.45%、0.83%和0.44%; - 通信效率方面(表8):SlaugFL(BigGAN)无法达到SlaugFL(场景1)的通信效率提升效果——例如在三种不同non-IID数据场景下,目标通信轮次结束后,SlaugFL(场景1)的Top-1测试精度更高。 上述实验结果表明,SD模型的应用对SlaugFL的性能提升至关重要。
⁵ 预训练BigGAN模型可通过以下链接获取:https://github.com/huggingface/pytorch-pretrained-BigGAN
G. 真实联邦学习应用场景验证
本节在真实数据集与真实边缘设备上对SlaugFL进行测试。具体而言,我们采用10台配备32GB内存的NVIDIA Jetson AGX Orin作为边缘设备(图13)——该设备广泛应用于边缘人工智能场景。我们假设将SlaugFL应用于自动驾驶领域中具有重要意义的车辆类型分类任务,并选取车辆类型分类数据集MIO-TCD[43]作为基准数据集。 为节省训练时间,我们从MIO-TCD数据集中抽取子集,对每个类别随机选取10%的样本。训练前,将MIO-TCD子集的样本尺寸调整为32×32;对于该子集,狄利克雷分布(Dirichlet distribution)的参数α设为0.1。实验的最大通信轮次为200,每轮通信的设备选择比例设为20%。参考文献[36]的设置,在MIO-TCD数据集上,将FedProx的超参数μ设为1×10⁻⁴;其他设置与第五节A3和第五节A4部分一致。 除使用10台真实边缘设备外,为充分验证SlaugFL的性能,在相同设置下,我们还模拟了100台设备参与车辆类型分类训练任务。实验结果如表9和表10所示: - 从表9可见,在设备数量不同的两种场景下,SlaugFL的性能均优于所有对比基线;尤其在设备数量较多(如100台设备)的场景中,SlaugFL的性能优势更显著,其精度比各基线方法高出1.83%~5.37%; - 从表10可见,SlaugFL显著提升了通信效率。例如,在两种不同设备数量的场景下,要达到65%的目标Top-1测试精度,SlaugFL分别仅需4.00轮和6.00轮通信。
结论
本文提出了一种面向通信高效联邦学习的新型选择性数据增强方案——SlaugFL。该方案通过筛选代表性设备,收集特定的局部类别原型用于训练生成对抗网络(GAN);训练完成的GAN可用于扩充设备本地的非独立同分布(non-IID)数据。此外,我们在设备端提出了双校准方法,以提升联邦学习性能。大量实验结果表明,与现有主流方法相比,SlaugFL能显著降低通信成本,最高降幅达52.49%。