C++ vector 全面解析:从接口使用到底层机制
目录
- 前言
- 一、vector的介绍及使用
- 1.1 vector的介绍
- 二、vector的使用
- 2.1 构造
- 2.1.1 explicit关键字
- 2.2 流插入流提取
- 2.3 vector的扩容机制
- 2.4 resize
- 2.5 operator[ ]和at
- 2.6 修改相关的接口
- 三、vector的隐式类型转换
- 3.1 push_back和emplace_back的使用差异
- 四、vector 在OJ中的使用
- 4.1 只出现一次的数字
- 结语


前言
大家好啊,我是云泽Q,欢迎阅读我的文章,一名热爱计算机技术的在校大学生,喜欢在课余时间做一些计算机技术的总结性文章,希望我的文章能为你解答困惑~
一、vector的介绍及使用
1.1 vector的介绍
vector这个单词还有向量的意思,但其底层就是顺序表

先看图中vector的模板声明:
class T:这是元素类型的参数。我们可以传入任意类型(如int、double、自定义类Person等),vector会据此实例化出 “存储该类型元素的动态数组”
class Alloc = allocator< T >:这是内存分配器的参数(默认使用 STL 的allocator< T >)。分配器负责vector的内存分配与释放,这个参数让vector的内存管理更灵活(一般场景用默认分配器即可),若觉得库中的内存池在特殊情况下不符合自己的要求,也可以自己写一个
注意:这里的vector与string有一些不同
std::vector本身就是类模板,使用时必须显式指定类型参数(如vector< int >、vector< double >),否则无法直接使用;
std::string不是模板,它是basic_string模板针对char类型的具体实例(通过typedef定义的别名),使用时无需指定类型参数(直接写string即可)。
二、vector的使用
vector的接口设计和string非常相似,但是也有自身的一些特点
2.1 构造
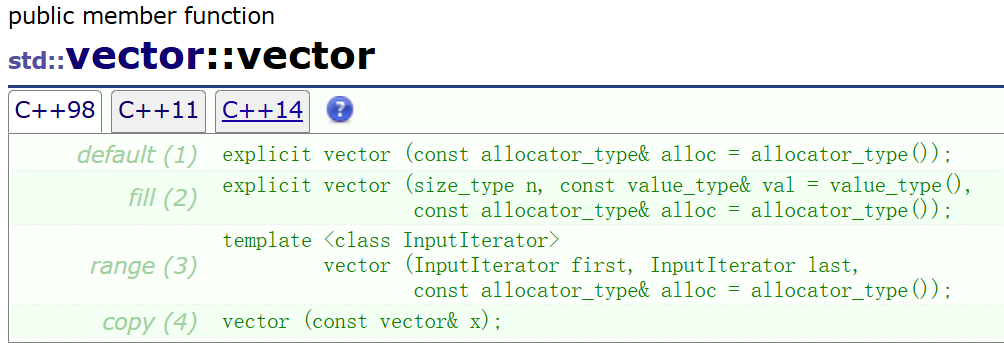
看一下STL中的vector提供的4个构造版本
- 先看第一种vector构造函数中也有内存分配器参数的设计,虽然默认分配器std::allocator< T >能满足绝大多数常规场景,但在一些特殊需求下(如内存池优化、共享内存管理、自定义内存统计等),这时候这个分配器参数的设计就可以供用户自定义分配器来替代默认实现。

第二个版本

第三个版本

这里迭代器区间构造给的参数是一个模板,也就是说可以传自己的迭代器,也可以传其他的迭代器。
第四个版本


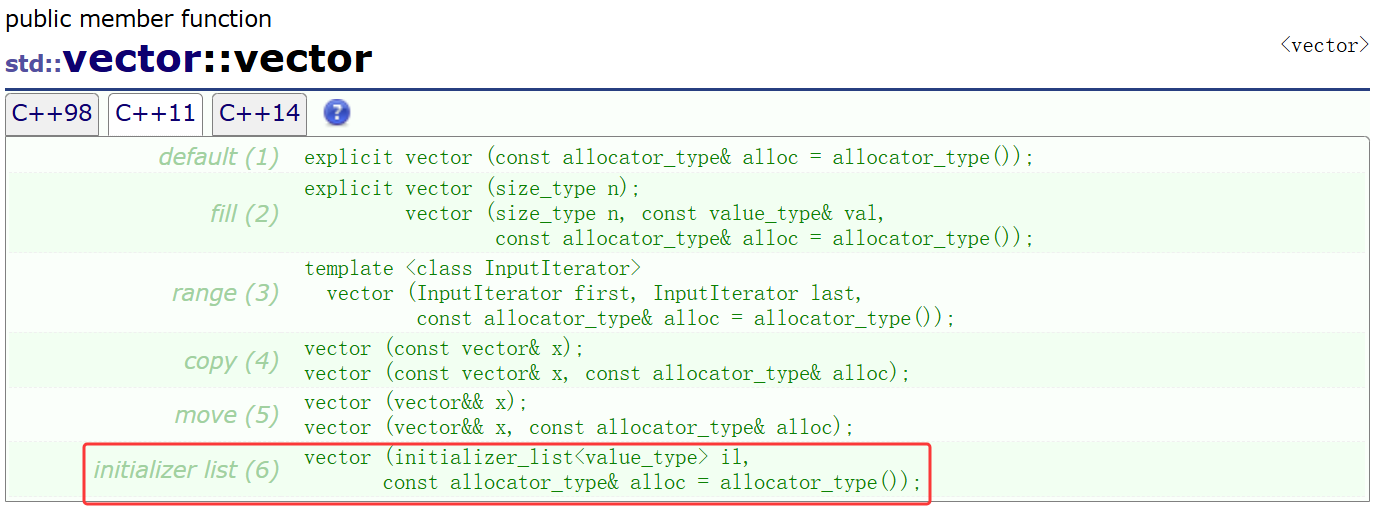
再看一下C++11提供的一个额外接口,该接口就支持用一个花括号列表(内部无论几个值都可以)去初始化vector的对象了
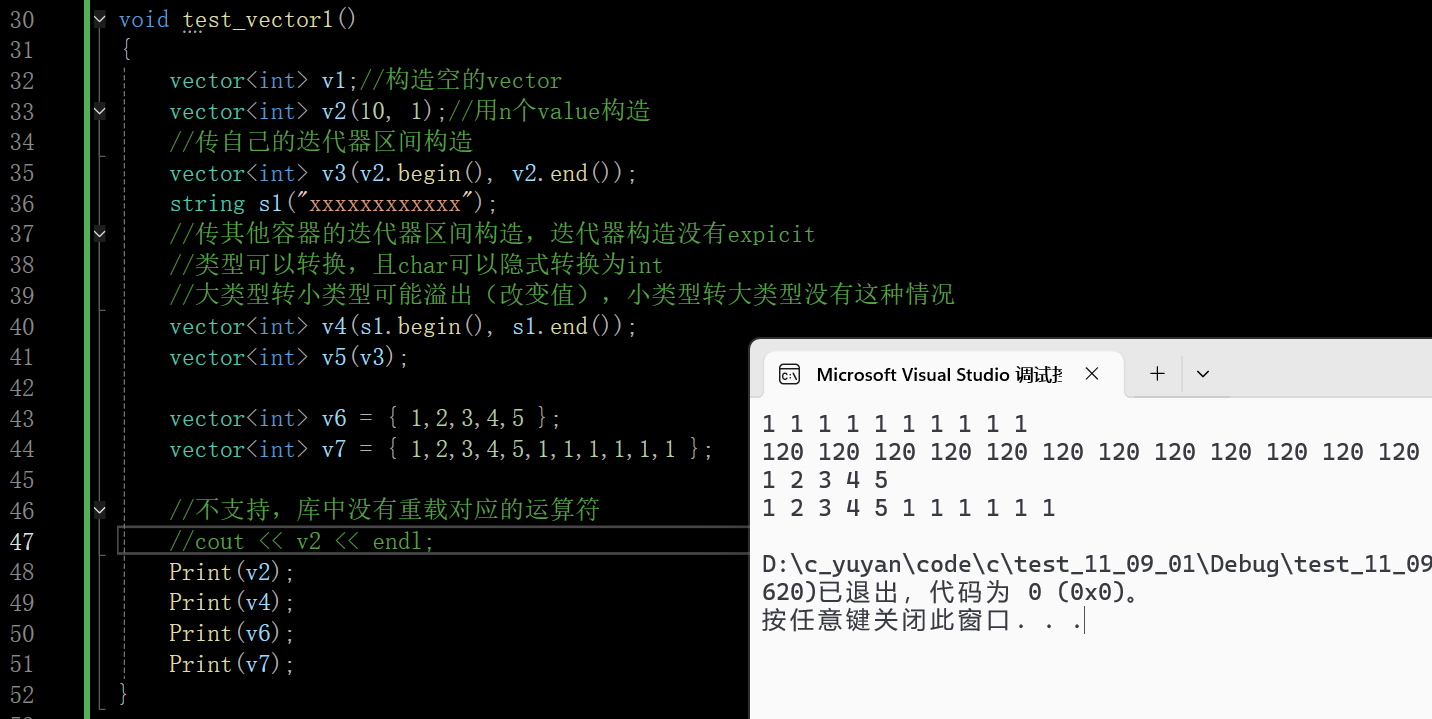
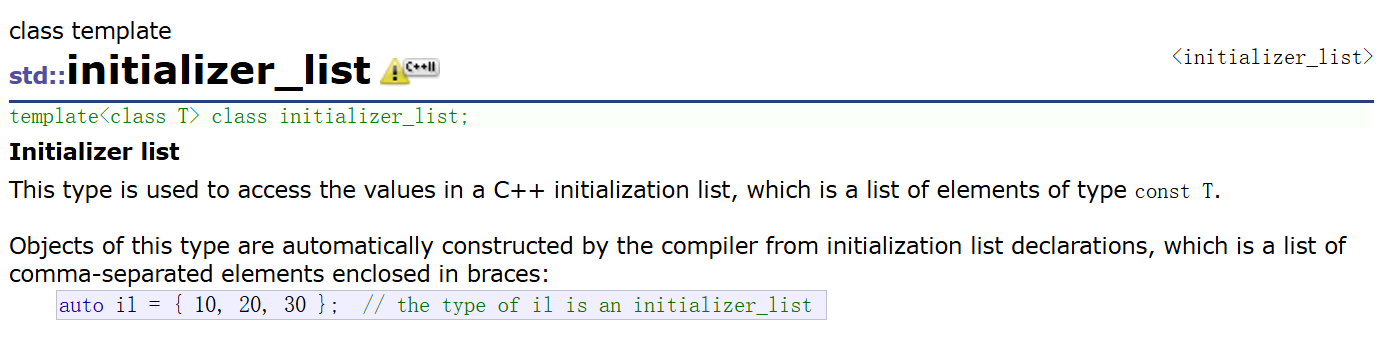
{1,2,3,4,5}初始化v6、v7时,是调用vector的initializer_list构造函数:编译器先把{1,2,3,4,5}封装成initializer_list< int >类型的临时对象 il,然后将这个对象作为参数传递给vector的 initializer_list 构造函数,最终完成v6和v7的元素初始化
initializer_list 底层的内部就是两个指针,可以说是在栈上开了一个临时数组把花括号内的值存下来,两个指针分别是开始的指针和指向最后一个数据的下一个位置的指针,成员函数size就是两个指针相减

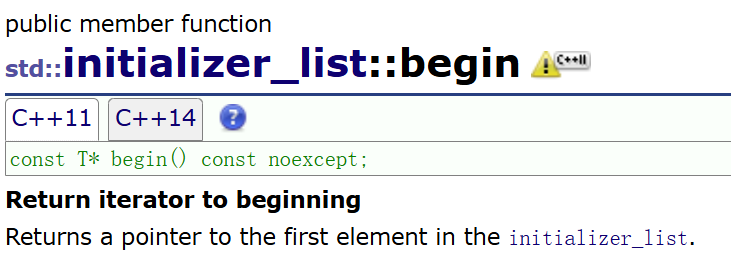
其begin是个迭代器(本质上迭代器的行为是模拟指向数组指针的行为),也意味着 initializer_list 可以用范围for,范围for本质上就是转换为用迭代器(也有begin相关类似指针的东西)
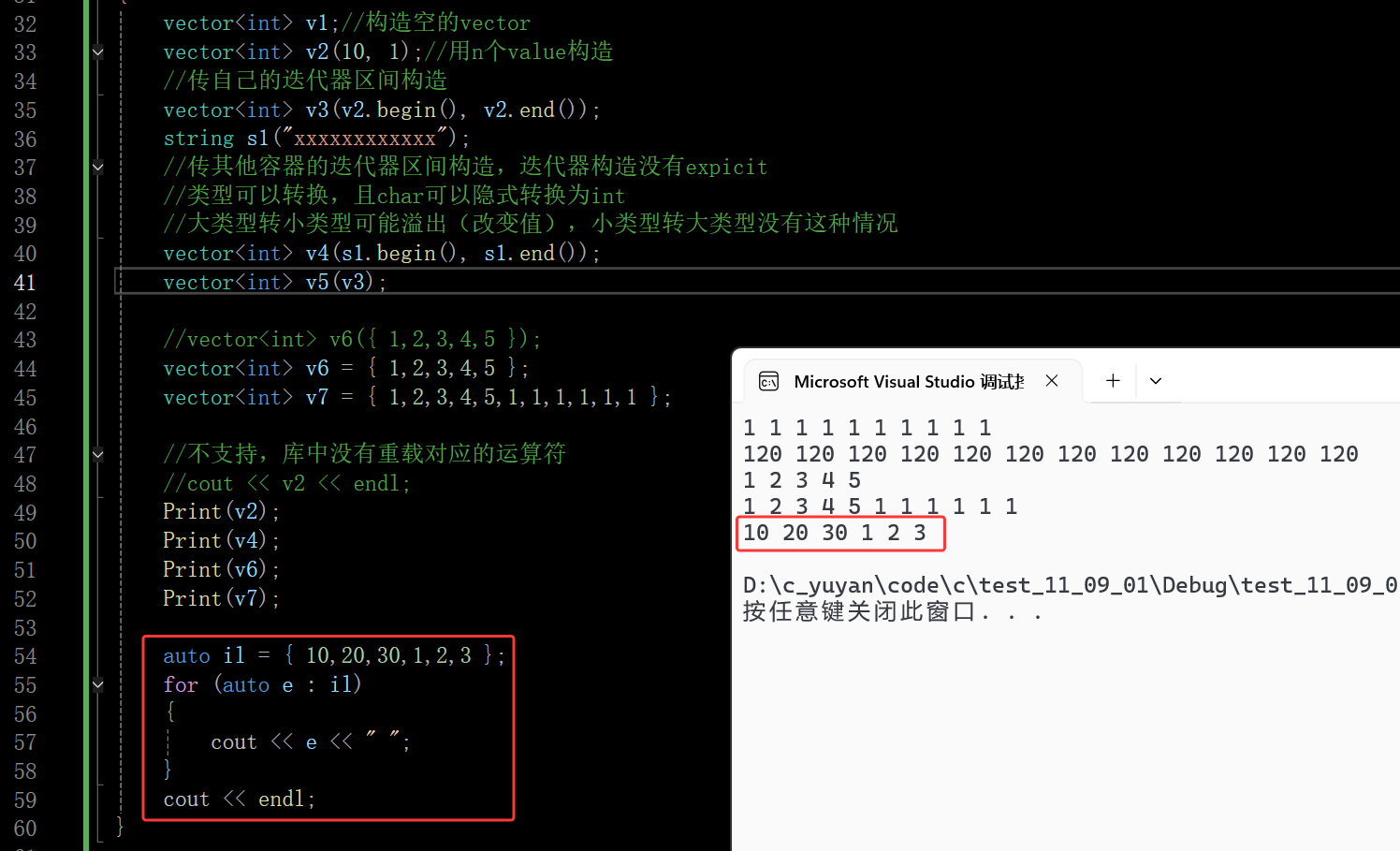
内部的底层就是相当于写一个范围for遍历对象 il,然后将结果push_back到vector中
其他容器也可以这样初始化,其中string用起来比较鸡肋,所以前面的文章没写
2.1.1 explicit关键字
这里详细补充一下explicit关键字的作用
如果一个类的构造函数是单参数(或除了第一个参数外其余参数都有默认值)的,C++ 允许“隐式类型转换”—— 即可以用该参数的类型 “直接赋值” 给类对象,编译器会自动调用构造函数完成转换。
没有explicit的情况:
class MyString {
public:// 单参数构造函数:用一个int创建指定长度的字符串MyString(int length) { // 假设这里是创建length个字符的逻辑}
};void printString(MyString s) { /* 打印字符串 */ }int main() {// 隐式转换:编译器会自动调用MyString(5),把int 5转换成MyString对象printString(5); // 等价于 printString(MyString(5)); return 0;
}
这种隐式转换可能违背开发者的意图—— 比如printString期望的是MyString类型,但传入int也能运行,容易隐藏逻辑错误(比如开发者可能误把 “长度” 传成了其他含义的int)。
当构造函数被explicit修饰后,编译器会禁止这种 “隐式类型转换”,必须显式调用构造函数才能创建对象。
上面的例子(添加explicit):
class MyString {
public:// explicit修饰后,禁止隐式转换explicit MyString(int length) { // 构造逻辑}
};void printString(MyString s) { /* 打印字符串 */ }int main() {// 错误!编译器不允许隐式转换,会提示类型不匹配// printString(5); // 必须显式调用构造函数,意图更明确printString(MyString(5)); return 0;
}
2.2 流插入流提取
说粗糙一些就是打印,库中的vector不支持流插入流提取(库中没有重载对应的函数),编译器不知道怎么输出vector中的数据。库中的string是支持的,string就是把串中的字符依次输出即可
//不支持,库中没有重载对应的运算符
//cout << v2 << endl;
想打印要自己手搓
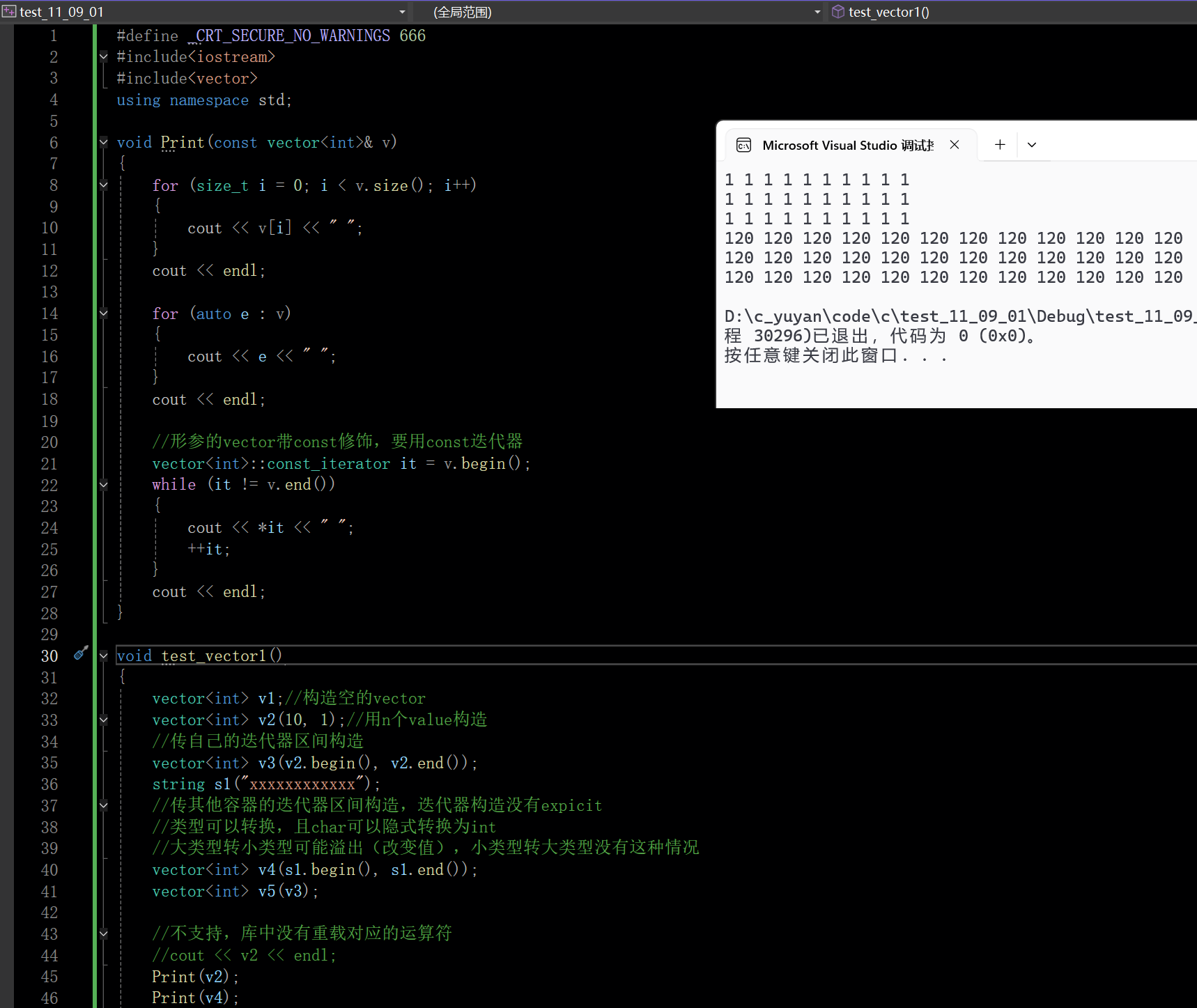
如图x的ASCII码值未120
2.3 vector的扩容机制
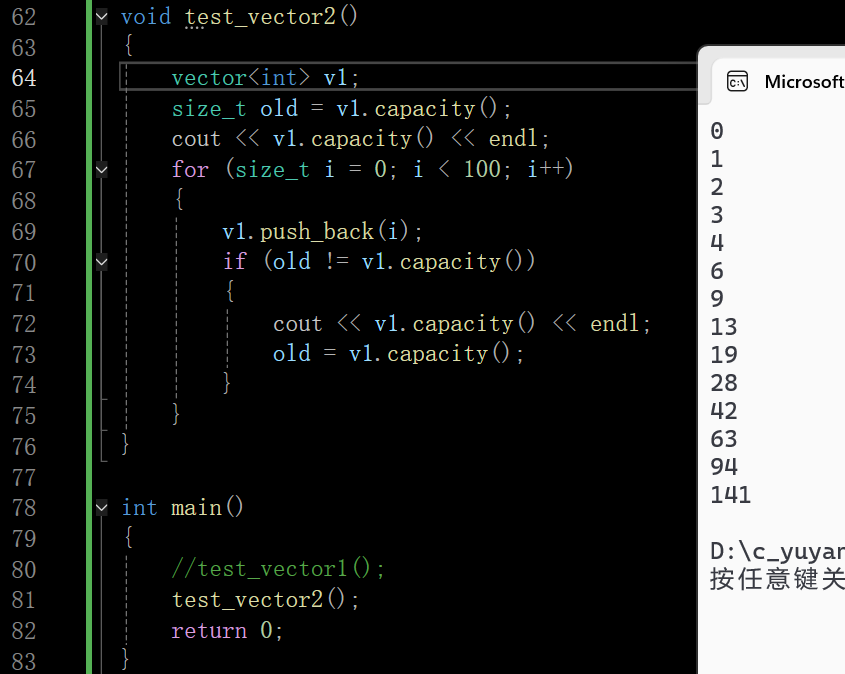
可以看到vector和string也一样保持稳定的1.5倍扩容,string的扩容第一次是2倍(小于15的时候是存在栈上的_buff数组中,_buff满了之后直接在堆上开了2倍的空间,后面保持1.5倍)
也就是数组结构的增长扩容,VS一贯的方式还是1.5倍扩容
若提前知道插入100个数据就可以使用reserve减少扩容提高效率
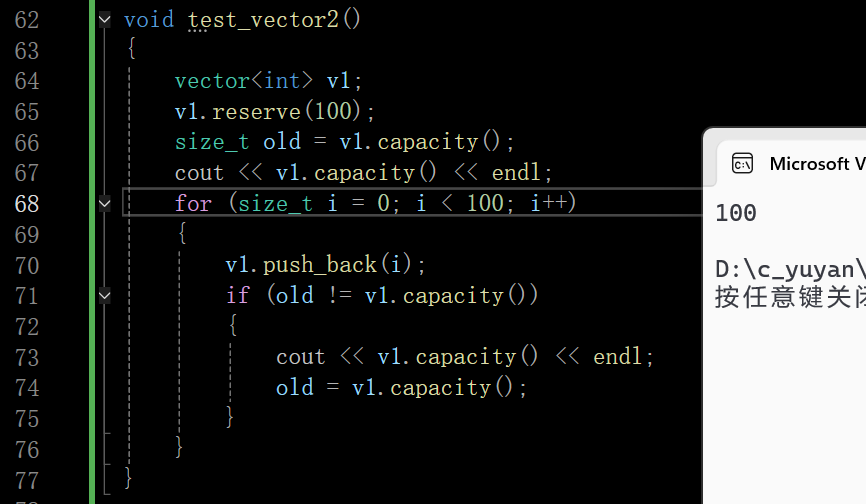
vector和string的reserve还有所不同,string的reserve还会对齐,需要100的时候实际上还可能多开一点,vector容器中要100开100
下面在Release模式下测试一下效率的提升
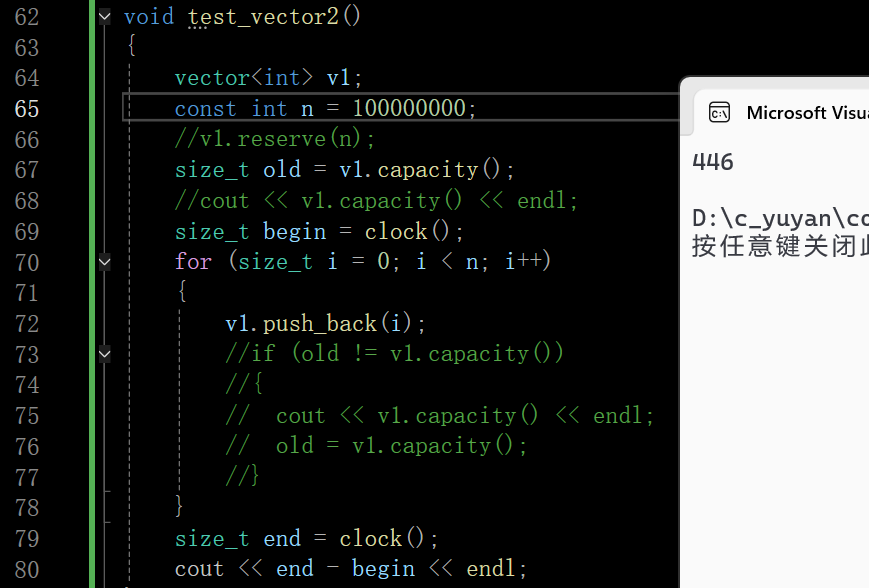
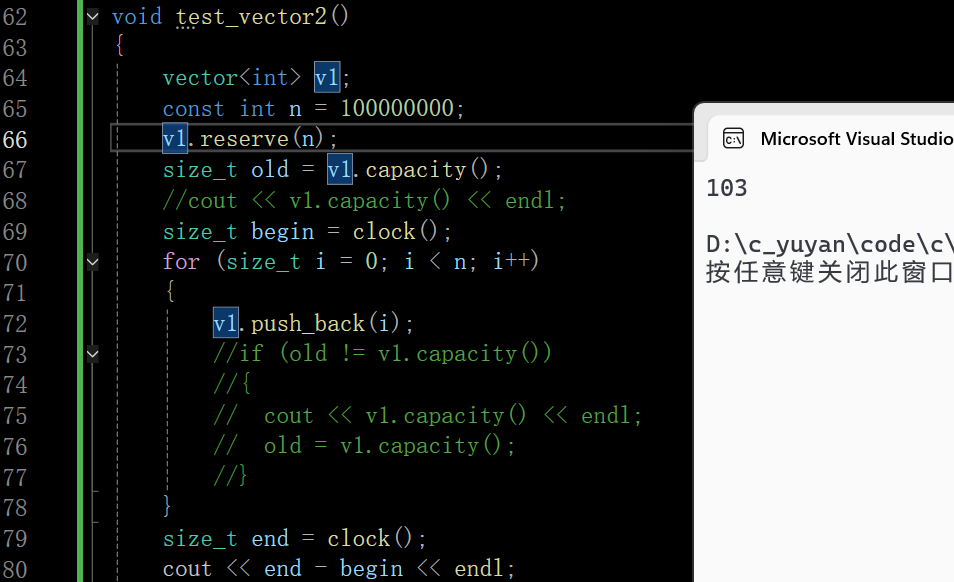
且vector的reserve是不会缩容的

向缩容调用下面的接口

可以缩容到size大小
2.4 resize
resize可以插入和删除数据
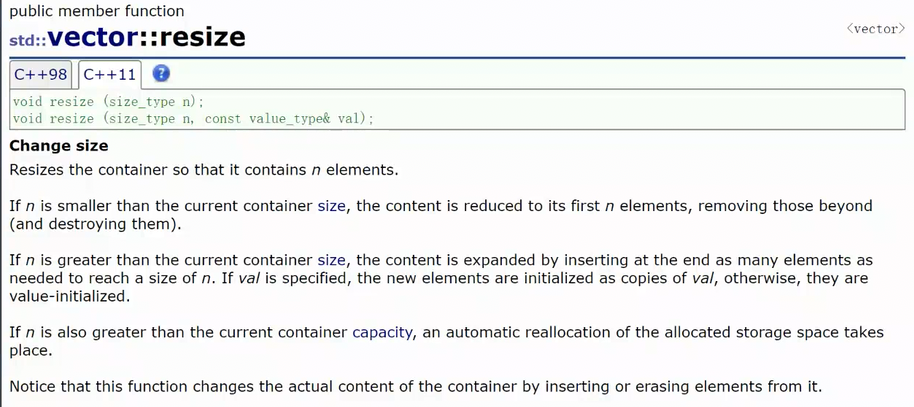
reserve开空间是不插入数据的,resize就是开空间+初始化的效果,已经有值的话已经有的数据不会动,而是会在后面插入数据
2.5 operator[ ]和at

operator[ ]越界访问会断言报错,这是编译器的额外调试增强功能,at和operator具有相同的功能,但是其越界会抛异常
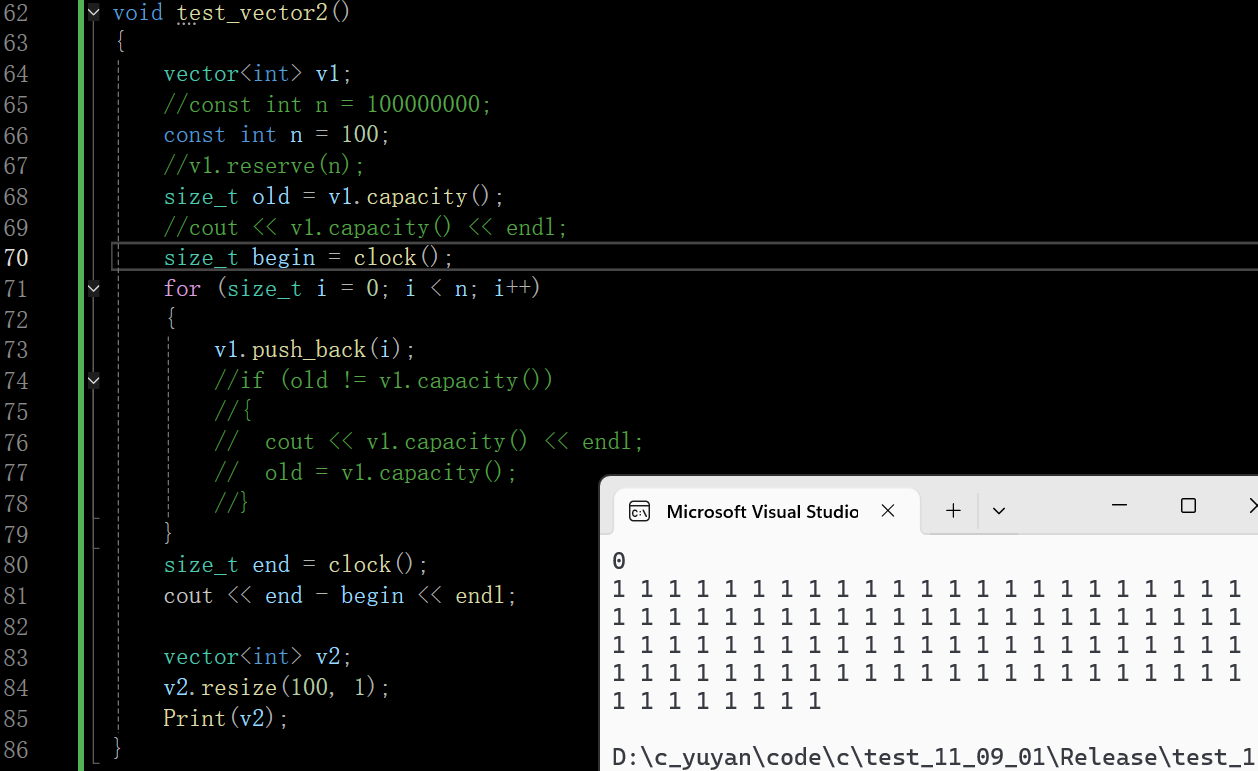
2.6 修改相关的接口
string提供的头插头删insert和erase主要是通过下标和长度来控制


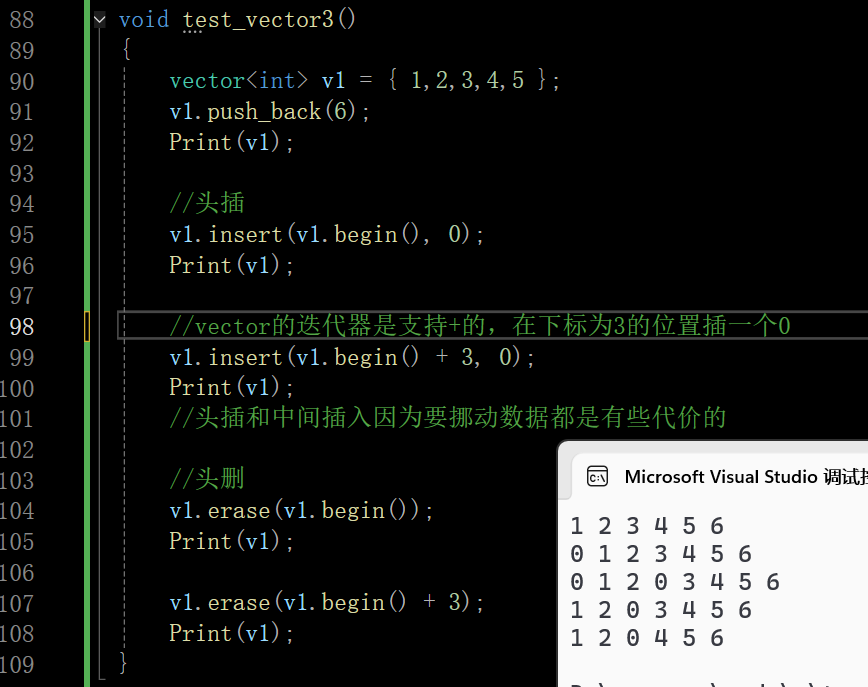
vector主要通过迭代器来控制
三、vector的隐式类型转换
下面展示一下隐式类型转换的魅力
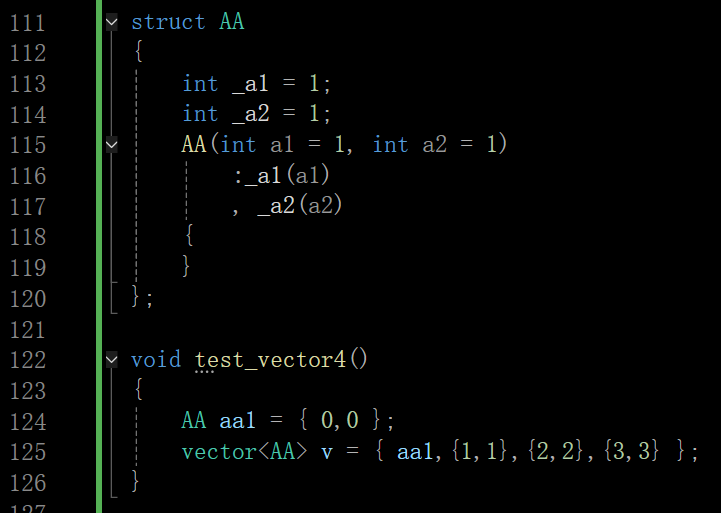
结构体 AA 的构造函数接受两个 int 类型参数(多参数的构造函数支持隐式类型转换),且没有被 explicit 修饰。这是允许 “隐式类型转换” 的关键(explicit 会禁止构造函数的隐式调用)
代码中 vector< AA > v = { {1,1}, {2,2}, {3,3} }; 的初始化逻辑:对于每个内部列表 {1,1}、{2,2}、{3,3},编译器会隐式调用 AA 的构造函数,将两个 int 值转换为 AA 类型的对象。例如,{1,1} 会被隐式转换为 AA(1, 1),这属于 “用户定义的隐式类型转换”(通过类的构造函数实现从 (int, int) 到 AA 的类型转换)。这些转换后的 AA 对象,再通过 vector 的 initializer_list 构造函数,最终初始化 vector< AA > 的元素。
尤其注意这里的两套花括号:外围的花括号是 initializer_list,内层的花括号是多参数构造函数的隐式类型转换
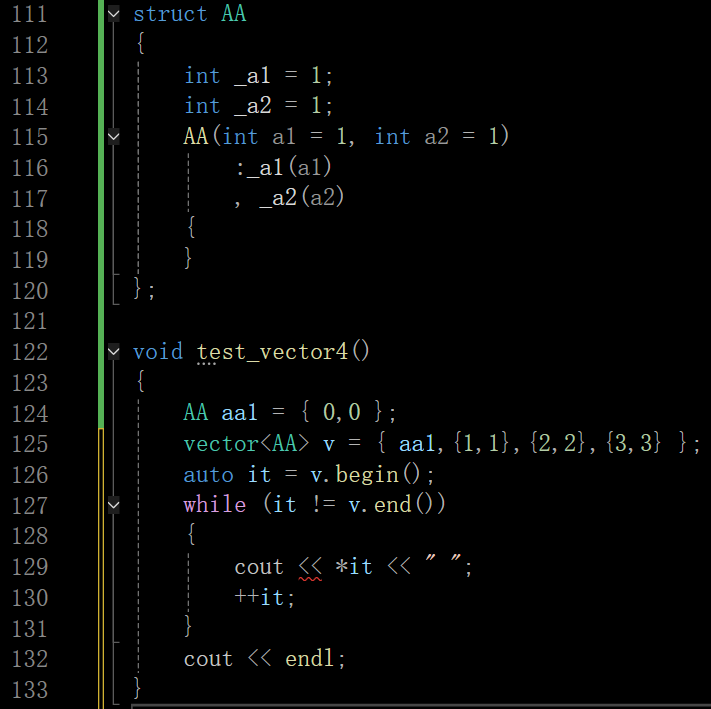
这里迭代器访问编译不通过的原因:
代码中vector< AA > v的迭代器it解引用后是AA类型的对象(*it是AA类型)
std::cout默认只支持内置类型(如int、double等)和标准库类型的输出,对于自定义结构体AA,必须显式重载operator<<,才能让cout知道如何打印它
这里有两种解决方案:第一种就是重载一个流插入运算符
struct AA
{int _a1 = 1;int _a2 = 1;AA(int a1 = 1, int a2 = 1) : _a1(a1), _a2(a2) {}
};// 重载输出运算符,让cout可以打印AA对象
std::ostream& operator<<(std::ostream& os, const AA& aa) {os << "(" << aa._a1 << ", " << aa._a2 << ")";return os;
}
第二种方案:既然不能直接输出自定义结构体AA的对象,那就通过迭代器访问结构体的成员变量_a1和_a2(这两个成员是int类型,cout可以直接输出int类型),从而绕开了 “需要重载operator<<来支持自定义类型输出” 的要求。这种方式的核心是直接操作结构体的内置类型成员
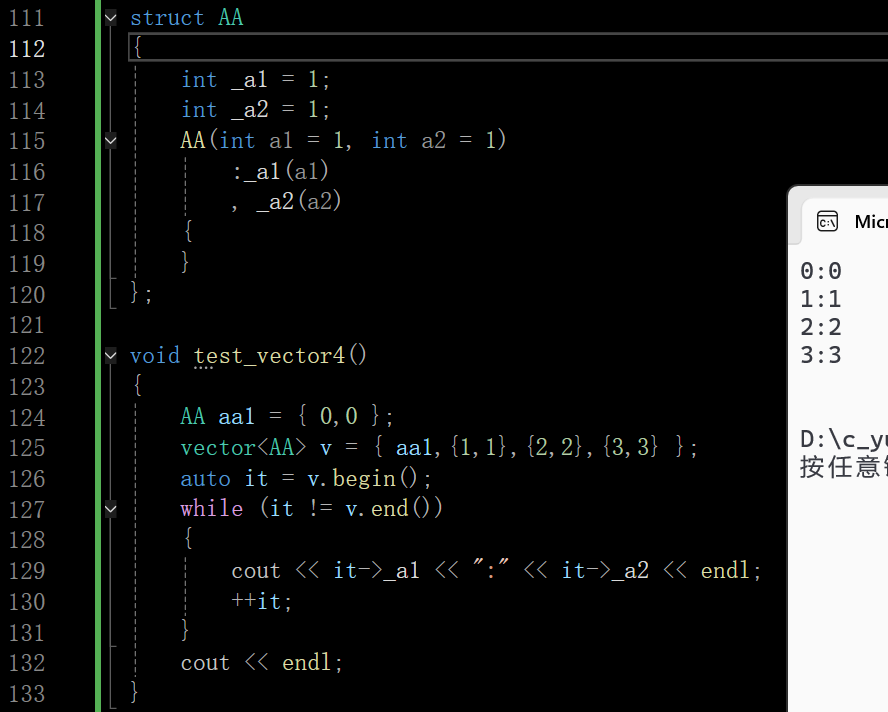
这里->能直接访问结构体的内置类型成员的原因如下:
vector< AA > 的迭代器(如代码中的 it)被设计为 **“行为类似指针” 的对象 **,标准库为迭代器重载了 -> 运算符。
当执行 it ->_a1 时,迭代器的 -> 运算符会返回一个指向其内部管理的 AA 对象的指针(相当于 &( *it)),然后通过这个指针访问 AA 的成员 _a1。
本质上等价于:( *it)._a1(先解引用迭代器得到 AA 对象,再通过 . 访问成员),而 -> 是这种操作的简化语法。
C++ 中,结构体(struct)的成员默认是公有(public)的(类 class 默认私有)
3.1 push_back和emplace_back的使用差异
二者的作用都是尾插
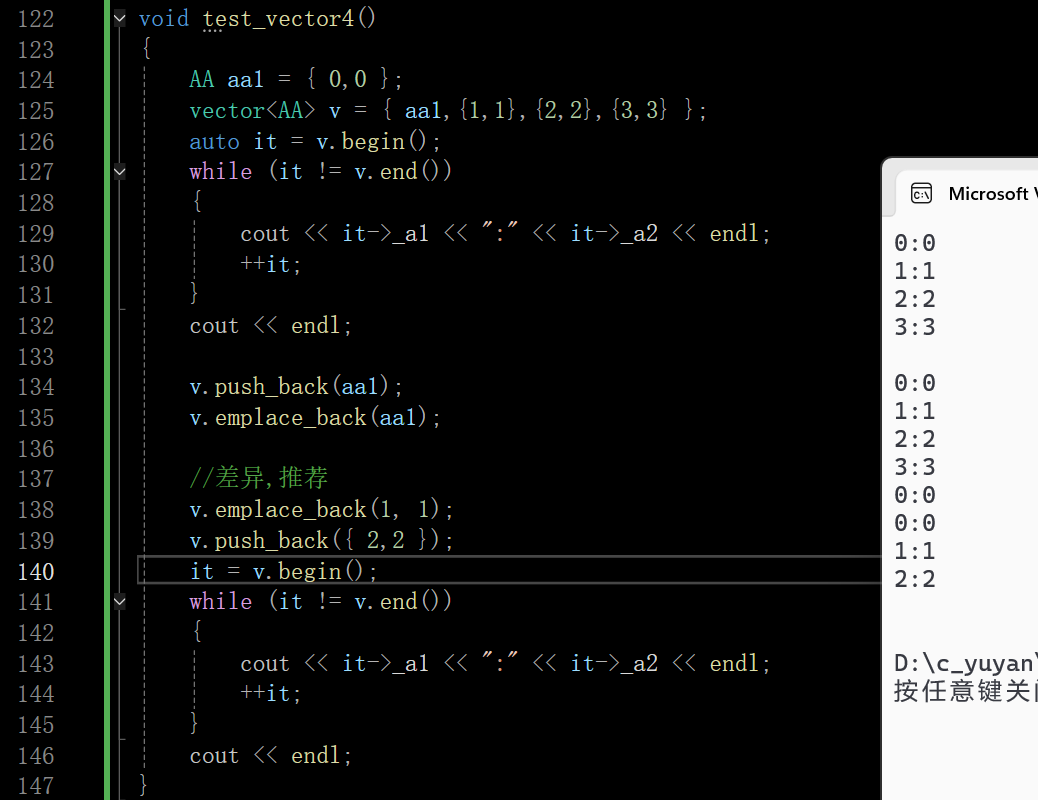
这里略微解释一下二者的区别:
- v.push_back(aa1):push_back 接收 AA 类型的对象 aa1,会先拷贝 aa1,再将拷贝后的对象添加到 vector 末尾。
- v.emplace_back(aa1):传入 AA 对象 aa1 时,emplace_back 会调用 AA 的拷贝构造函数,在 vector 末尾原地构造一个与 aa1 相同的对象(此场景下和 push_back 差异不明显,重点看下面的案例)。
- v.push_back({2,2}):{2,2} 会先隐式转换为 AA 对象(因为 AA 的构造函数未被 explicit 修饰),然后 push_back 将这个转换后的 AA 对象拷贝到 vector 末尾。
- v.emplace_back(1,1):传入 AA 构造函数的参数 1,1 时,emplace_back 会直接在 vector 末尾原地调用 AA(int, int) 构造函数,创建新的 AA 对象,无需提前构造临时 AA 对象。
简单来说,emplace_back 最大的优势是支持 “原地构造”—— 当传入构造参数(如 1,1)时,能直接在 vector 内部创建对象,省去了 “临时对象构造 + 拷贝” 的步骤,性能更优;而 push_back 更依赖 “先有对象,再拷贝入容器” 的逻辑

//且不支持交叉使用
//emplace_back的函数参数是个模板,推不出来
v.emplace_back({ 1,1 });
v.push_back(2,2);
四、vector 在OJ中的使用
4.1 只出现一次的数字
只出现一次的数字
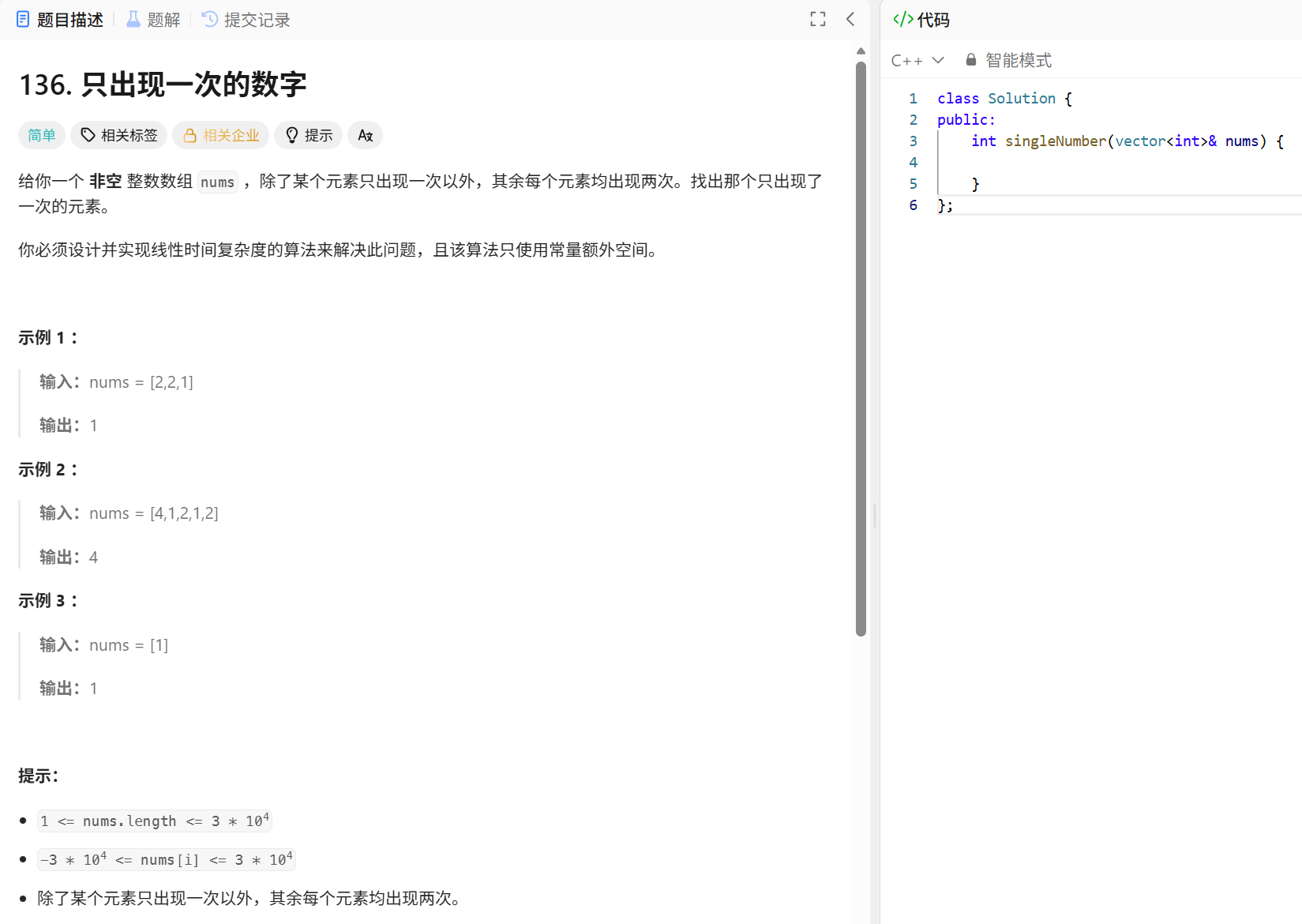
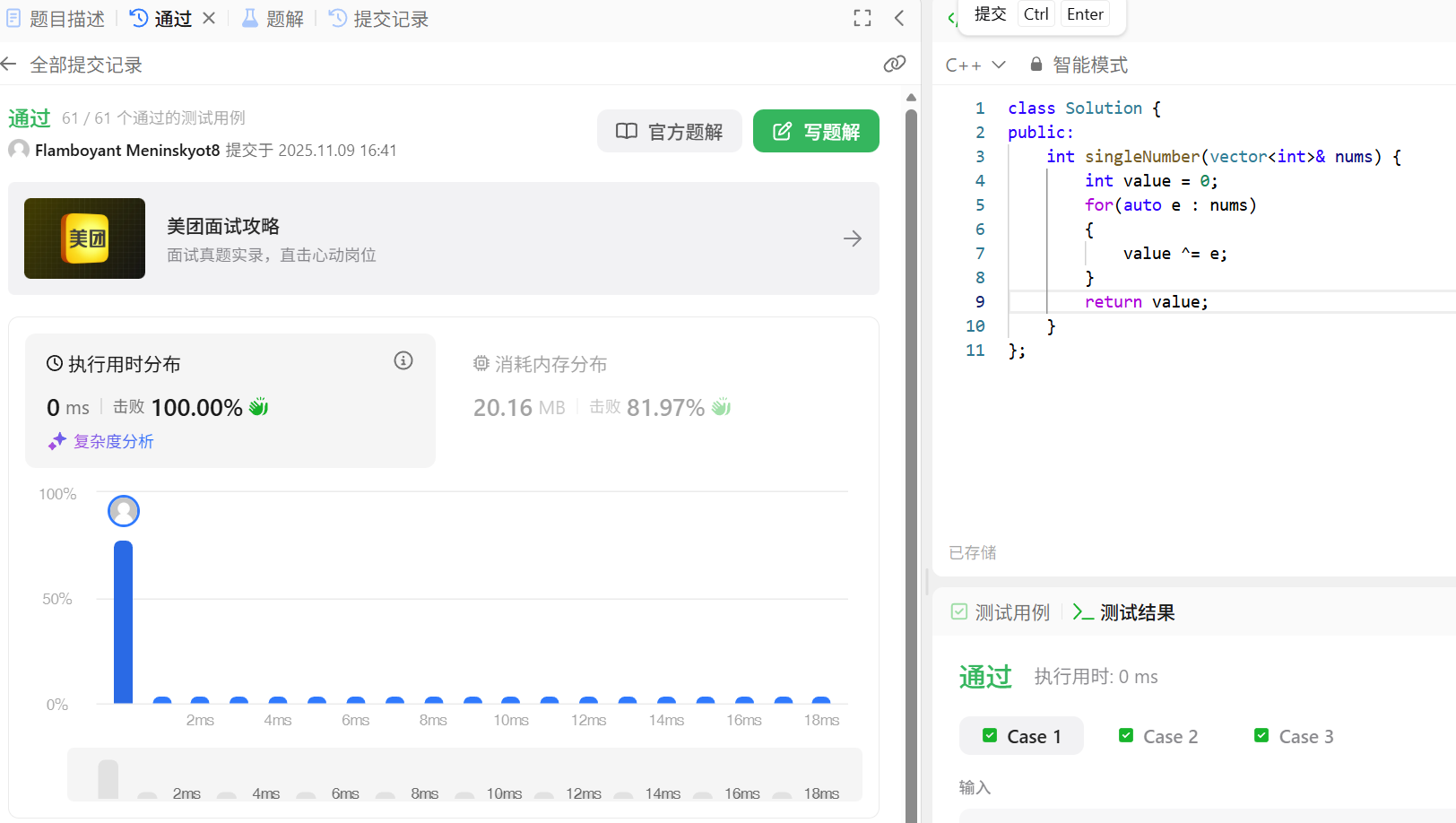
写这道题要清楚异或运算的特性:
异或运算(^)是基于二进制位的操作,规则是:对应二进制位相同则为 0,不同则为 1
3 的二进制:011(8 位表示为 00000011)
5 的二进制:101(8 位表示为 00000101)合并结果为 00000110,即十进制的 6。所以 3 ^ 5 = 6
性质 1:相同的数异或,结果为 0。例如 2 ^ 2 = 0,5 ^ 5 = 0。
性质 2:0 和任意数异或,结果为这个数本身。例如 0 ^ 3 = 3,0 ^ 99 = 99
异或元素还满足:
交换律:a ^ b = b ^ a(异或的顺序不影响结果)。
结合律:(a ^ b) ^ c = a ^ (b ^ c)(可以任意调整异或的组合顺序)
4 ^ 1 ^ 2 ^ 1 ^ 2 = (1 ^ 1) ^ (2 ^ 2) ^ 4 = 0 ^ 0 ^ 4 = 4
基于以上特性得出结论:只要元素是 “成对出现” 的,无论其数值是多少,异或后都会相互抵消(结果为 0);而唯一不成对的元素,会在最终异或中被保留下来
结语
