Kafka工作流程及文件存储机制
好的,我们来详细解释一下Kafka的工作流程及其文件存储机制。
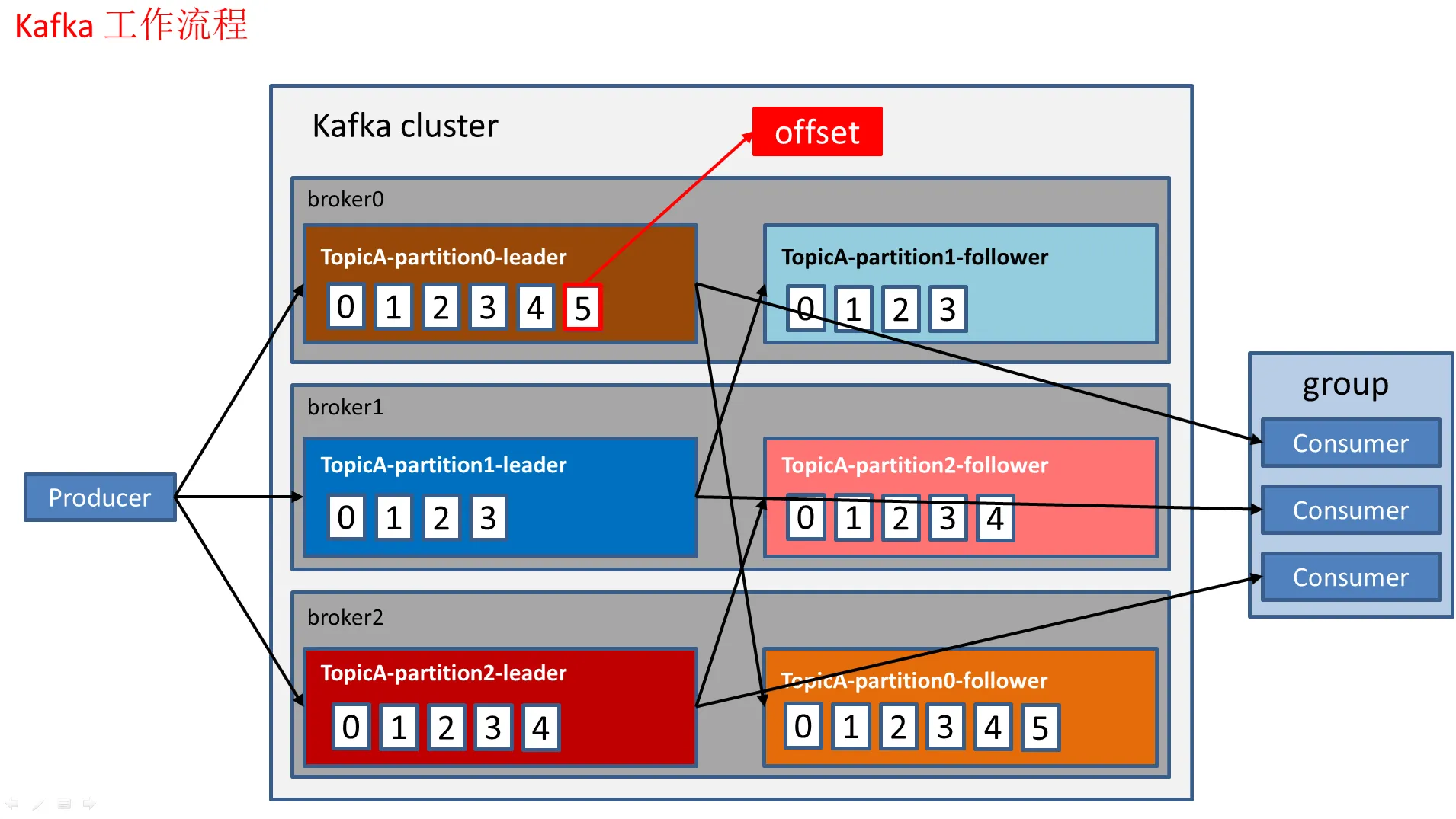
一、 Kafka 工作流程
Kafka中消息是以topic进行分类的,生产者生产消息,消费者消费消息,都是面向topic的。
Kafka 的核心工作流程主要涉及生产者、Broker(服务器)和消费者三个角色,以及主题和分区两个核心概念。
-
主题与分区
- 消息被发布到主题中,主题是消息的逻辑分类。
- 每个主题被划分为一个或多个分区。分区是消息存储和并行处理的基本单位。例如: $$ topic = { partition_0, partition_1, \dots, partition_{n-1} } $$
- 分区内的消息是有序的,但全局(跨分区)不保证顺序。
-
生产者流程
- 生产者将消息发送到指定的主题。
- 生产者需要指定消息应该发送到该主题的哪个分区。这可以通过:
- 直接指定分区号。
- 指定消息的 Key。Kafka 对 Key 进行哈希计算(默认),决定目标分区: $$ partition = hash(key) \mod numPartitions $$
- 不指定 Key 时,采用轮询或粘性分区策略。
- 生产者可以选择同步或异步发送消息,并可以配置确认机制(如
acks=all要求所有副本确认)。