Kafka 消费者
Kafka 消费者
5.1 Kafka 消费方式(拉)
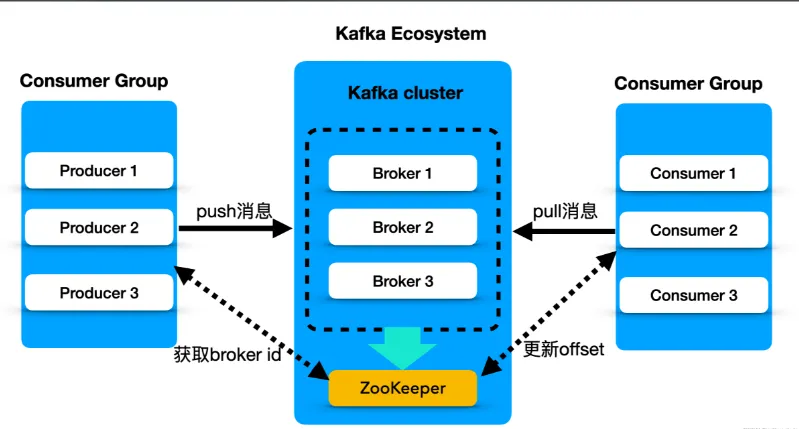
pull(拉)模式:
consumer采用从broker中主动拉取数据。Kafka采用这种方式。
push(推)模式:
Kafka没有采用这种方式,因为由broker决定消息发送速率,很难适应所有消费者的消费速率。例如推送的速度是50m/s,
Consumerl、Consumer2就来不及处理消息。
pull模式不足之处是,如果Kafka没有数据,消费者可能会陷入循环中,一直返回空数据。
Kafka 消费者是 Apache Kafka 平台中的一个核心组件,用于从 Kafka 主题(Topic)中读取和处理消息。它允许应用程序实时消费数据流,适用于日志处理、事件驱动架构等场景。下面我将逐步解释 Kafka 消费者的概念、工作原理、使用方式及注意事项,帮助您理解并应用。
1. Kafka 消费者的基本概念
Kafka 消费者通过订阅一个或多个主题来读取消息。每个主题被分成多个分区(Partition),消费者可以分配到这些分区上,并行处理消息。关键概念包括:
- 消费者组(Consumer Group):一组消费者实例共享一个组 ID,Kafka 会将主题的分区分配给组内的消费者,实现负载均衡。例如,如果一个主题有 $n$ 个分区,一个消费者组有 $m$ 个消费者,那么每个消费者可能负责 $ \frac{n}{m} $ 个分区(当 $n$ 可被 $m$ 整除时)。
- 偏移量(Offset):