【CUDA笔记】02 CUDA GPU 架构与一般的程序优化思路(上)
引言
前一节已经初步实现了一个入门的 cuda 程序, 向量加法。 这一节开始介绍让 Cuda 程序可以执行得更快的一般优化思路,以及结合 GPU的结构设计,介绍为什么是这样优化。
本节主要是对应视频课程的第 3 节
1.从 GPU 架构开始
1.0 基础概念
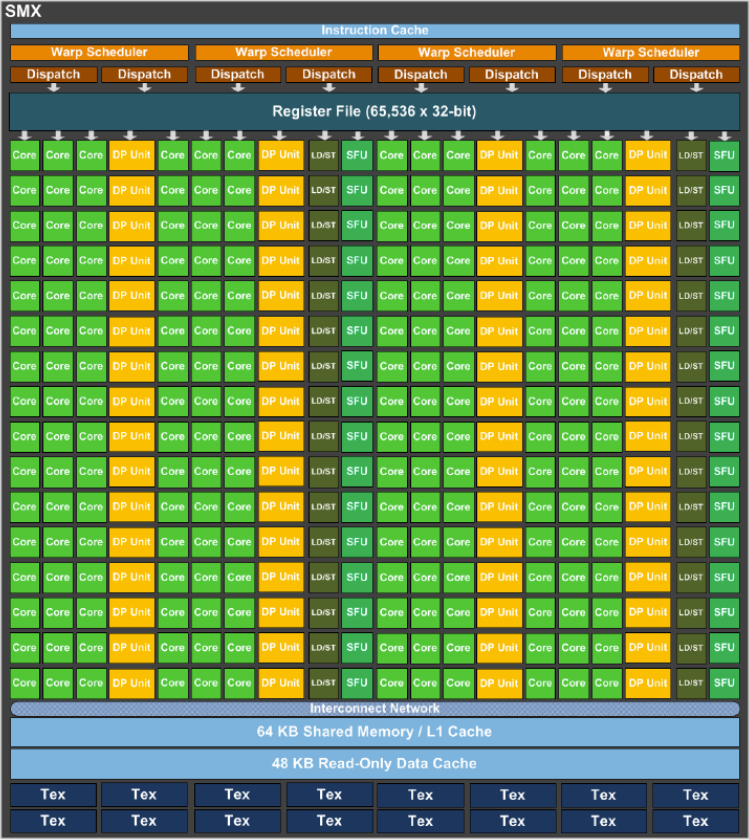
SM: streaming multiprocess(流式多处理器)缩写。 集成了多种专用计算单元、高速缓存, 寄存器,加载存储单元等的微型并行处理器。 了解 GPU 架构, 很大一部分是了解 GPU 的 SM 的结构。
SP unit: 单精度浮点数计算单元, 图形与 通用计算的主力。
DP unit: 双精度浮点数计算单元, 为需要数值精度的科学计算设计。DP 的数量一般比 SP 的数量少, 所以
LD/ST unit: 加载/存储单元, 负SM 的寄存器与 各种内存之间的数据传递
64 K registers: 寄存器
Warp Scheduler: 线程束调度器,集成在每个SM 内部的硬件单元,它的唯一任务就是,在正确的时机,将准备好执行的线程束发送到执行单元上。
AI 给出的比喻:
-
线程 是单个士兵。
-
Warp 是一个由 32 名士兵组成的方阵。所有士兵必须执行同一个命令(指令),但各自操作自己的武器(数据)。
-
Warp Scheduler 就是战场上的指挥官。他的职责是观察所有方阵的状态,然后对准备好的方阵高声下令:“第一方阵,开火!”、“第三方阵,前进!”
-
为什么需要 Warp Scheduler?—— 隐藏延迟
GPU 拥有成千上万个计算核心,但访问内存(尤其是全局显存)的延迟非常高(可能需要数百个时钟周期)。如果让一个核心傻等着数据从内存回来,那绝大部分时间它都在空转,效率极低。
Warp Scheduler 的解决方案是:快速切换。
- 当一个 Warp 的指令需要等待内存数据时(比如 LD/ST Unit 正在工作),Warp Scheduler 会立刻将这个 Warp 标记为 “未就绪”。
- 然后,它几乎不花费任何时间,立刻从一大堆“就绪”的 Warp 中选出下一个,将其指令发射到执行单元。
- 通过这种方式,当一些 Warp 在等待数据时,另一些 Warp 正在执行计算。从宏观上看,执行单元始终处于忙碌状态,从而隐藏了内存访问的延迟。
这种切换是硬件级别的,速度极快,不需要保存/恢复上下文(因为每个 Warp 的上下文(寄存器状态)本来就常驻在 SM 内),因此被称为 “零开销线程切换”。
后面一点的课程将会介绍到通过利用 有关线程束的机制 来提高程序的效率。
1.1 GPU 架构的演进
Kelper GPU 架构(2012)

MAXWELL(2014)/PASCAL CC6.1(2016) 架构
同一名称下的架构下也有不同的变体, 不同变体的架构也会存在差异, 深究的话需要看具体的版本。


PASCAL CC6.0(2016)/VOTAL(2017)
引入 Tensor Core 用于进行乘法运算, 常用于深度学习与人工智能领域


1.2 CUDA 的一些概念与硬件的大致对应关系

想象 Thread 概念大致与 SP 相关联。实际上因为除了计算指令, 还会有一些其他指令,所以这个关系只是大致关联。
Thread Block 大致与 SM 关联。
一个 GPU 内核中有多个 SM, 类比grid 中包含多个 block。
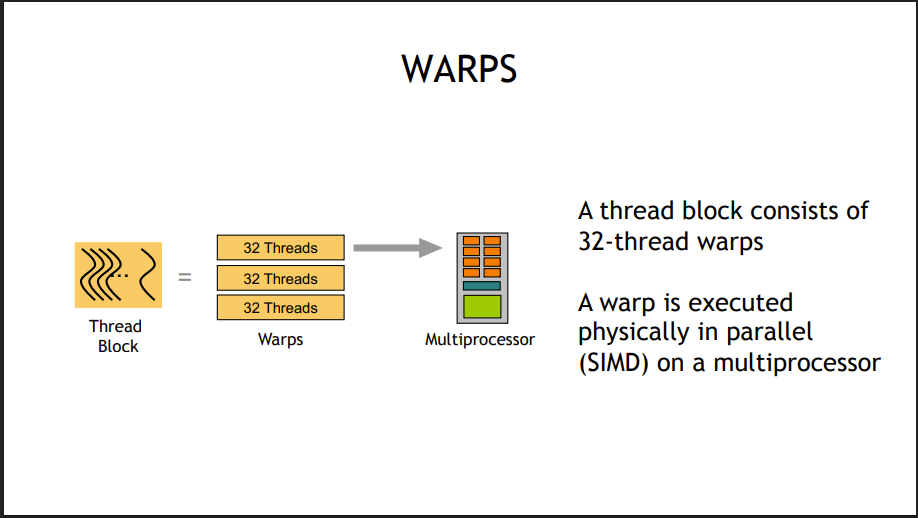
32 个线程组成一个 warp(线程束), 一个 warp 里的所有线程并行执行, 1 个block 由多个 warp 组成。
1.3 GPU 中的延迟
数据在GPU 中一个典型的传递路径是:
- 一个在 SM 上运行的线程需要数据。
- 该线程的 LD Unit 首先检查 L1 Cache/Shared Memory。
- 如果找到(命中),数据会以极低的延迟被加载到寄存器。
- 如果未命中,请求会被发送到 L2 Cache。
- 如果 L2 也未命中,请求最终会到达 显存,此时的延迟非常高。
这里举例,一个 SM 中执行如下的指令
In machine code:
I0: LD R0, a[idx];
I1: LD R1, b[idx];
I2: MPY R2,R0,R1

第一个 warp 发起从 global memory 加载数据的指令,由于数据加载需要等几个时钟周期,为节约时间,在下一个时钟周期,下一个 warp 先发起同样的数据加载指令,同理,之后,让后一个 warp 的加载指令先执行…
等到warp0 需要的数据加载完了, 再执行 warp0 的下一个指令。
当SM 中 执行的 warp 足够多,加载数据的耗时就能被尽可能的隐藏, 否则 处理器会有比较长的时间处于空闲状态, 等待数据的加载。
1.4 GPU 架构决定的代码优化思路

(1)在限定范围内,尽可能发起足够多的线程,让 GPU 保持繁忙。
至少 512 个, 可以以 2048 以上乃至最大数量个线程为目标。
至少 512 的原因是 据统计数据, 差不多到每个 SM 处理 512 个线程, 回报率开始稳定在最大值附近。

(2)每个 Thread Block 中的线程的数量最好是 warp size 的整数倍, 一般为 32的倍数。
因为 指令是一个warp 一个 warp 批量执行了, 一个线程块中如果 配置 48 个线程, 实际上也是会启动两个 warp(线程束), 第一个 warp 中有 32 个活跃线程, 第二个 warp 中有 16 个活跃线程, 导致第二个warp 中就有 16 个线程占用了 GPU 的资源, 但处于非活跃的状态。
建议一个 block 配置 128 - 256 个 线程, 当然具体配置要结合应用的实际情况。
当前每个 block 最多 分配1024 个线程。

(超出的话 CUDA API 也会返回如下报错)
Fatal error: kernel launch failure
2.本节练习
通过修改 blocks 与 threads 的数量配置, 观察向量加法函数运行时间
在 第一节课程 当中已经实现了一个向量加法的核函数, 其中 vecAdd 的 block thread 的数量配置为
vecAdd<<<(dataSize + block_size - 1) / block_size, block_size>>>(d_A, d_B, d_C, dataSize);
grid 中 block 数据量的大小由输入数组的 长度决定。 今日若想实现自由配置 blocks 与 threads 的数量,就需要先了解Cuda 中核函数加载数据的一个常用写法
grid-stride loop
for (int idx = threadIdx.x + blockDim.x * blockIdx.x; idx < dataSize; idx += blockDim.x * gridDim.x)
{Data[idx] = ...;
}
通过这样, 可以将启动线程的数量与输入数据的数量独立开。
这一次将数组长度 32 * 1048576 做一下测试; 修改前面的代码, 可得到测试代码如下
/** grid stride 方法实现向量加法*/
#include <stdio.h>
#include <stdlib.h>#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <algorithm>
#include <stdio.h>#include <chrono>#define cudaCheckErrors(msg) \do \{ \cudaError_t __err = cudaGetLastError(); \if (__err != cudaSuccess) \{ \fprintf(stderr, "Fatal error: %s (%s at %s:%d)\n", \msg, cudaGetErrorString(__err), \__FILE__, __LINE__); \fprintf(stderr, "*** FAILED - ABORTING\n"); \exit(1); \} \} while (0)const int DSIZE = 32 * 1048576;__global__ void vadd(const float *A, const float *B, float *C, int ds)
{for (int idx = threadIdx.x + blockDim.x * blockIdx.x; idx < ds; idx += gridDim.x * blockDim.x) // a grid-stride loop{C[idx] = A[idx] + B[idx];}
}int main()
{float *h_A, *h_B, *h_C, *d_A, *d_B, *d_C;h_A = new float[DSIZE];h_B = new float[DSIZE];h_C = new float[DSIZE];for (int i = 0; i < DSIZE; i++){h_A[i] = rand() / (float)RAND_MAX;h_B[i] = rand() / (float)RAND_MAX;h_C[i] = 0;}cudaMalloc(&d_A, DSIZE * sizeof(float));cudaMalloc(&d_B, DSIZE * sizeof(float));cudaMalloc(&d_C, DSIZE * sizeof(float));cudaCheckErrors("cudaMalloc failure");cudaMemcpy(d_A, h_A, DSIZE * sizeof(float), cudaMemcpyHostToDevice);cudaMemcpy(d_B, h_B, DSIZE * sizeof(float), cudaMemcpyHostToDevice);cudaMemcpy(d_C, h_C, DSIZE * sizeof(float), cudaMemcpyHostToDevice);cudaCheckErrors("cudaMemcpy H2D failure");int blocks = 160; // !!! modify this line for experimentationint threads = 1024; // !!! modify this line for experimentationauto t0 = std::chrono::high_resolution_clock::now();vadd<<<blocks, threads>>>(d_A, d_B, d_C, DSIZE);cudaDeviceSynchronize();auto t1 = std::chrono::high_resolution_clock::now();auto ms = std::chrono::duration_cast<std::chrono::milliseconds>(t1 - t0).count();printf("vadd with block:%d, thread: %d, elapsed: %lld ms\n", blocks, threads, static_cast<long long>(ms));cudaCheckErrors("kernel launch failure");cudaMemcpy(h_C, d_C, DSIZE * sizeof(float), cudaMemcpyDeviceToHost);cudaCheckErrors("kernel execution failure or cudaMemcpy H2D failure");printf("A[0] = %f\n", h_A[0]);printf("B[0] = %f\n", h_B[0]);printf("C[0] = %f\n", h_C[0]);return 0;
}
我这边是 NVIDIA GeForce RTX 2060 跑一下试试
block = 1, thread = 1
vadd with block:1, thread: 1, elapsed: 18141 ms
block = 1, thread = 256
vadd with block:1, thread: 256, elapsed: 193 ms
block = (dataSize + 256- 1) / 256, thread = 256 (grid 中block的数量可以设置的非常大)
vadd with block:131072, thread: 256, elapsed: 3 ms
block = 1, thread = 1024(thread 这里最大设置为 1024, 超过会报错)
vadd with block:1, thread: 1024, elapsed: 57 ms
block = 160, thread = 1024
vadd with block:160, thread: 1024, elapsed: 3 ms
block = 1024, thread = 1024
(这一步比前一步分配的更多资源, 收益已经小很多了)
vadd with block:1024, thread: 1024, elapsed: 2 ms
小结
本节主要通过配置 block 与 thread 来提升程序的执行效率。
并通过 gride-stride loop 启发我们来开独立线程与输入数据量的关系。
预告下节将从 GPU 的内存结构层面, 来优化CUDA 程序。