在完成vLLM基础部署和性能测试后,我们发现在异腾910B NPU环境中,vLLM的性能还有很大的优化空间。本文将从多个维度深入探讨vLLM性能优化策略,帮助您充分释放异腾平台的算力潜力。
一、性能优化环境准备
在进行性能优化之前,我们需要准备一个标准化的测试环境,以便准确评估优化效果。
1.1 、环境基准检查
Bash # 检查系统资源使用情况
这些命令帮助我们了解系统的整体资源状况,确保我们在优化过程中不会受到其他因素的干扰。
1.2 、创建性能监控工具
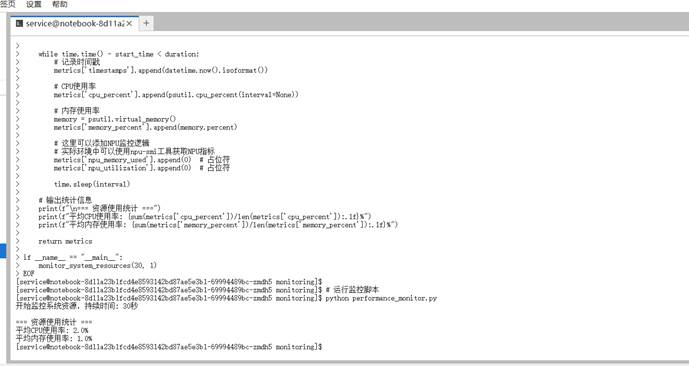
为了实时监控优化效果,我们需要创建一个性能监控脚本:
Bash # 创建监控脚本目录
这个监控脚本为我们提供了系统资源使用的基础视图,帮助我们在优化过程中识别瓶颈。
二、 vLLM 启动参数深度调优
vLLM提供了丰富的启动参数,合理配置这些参数可以显著提升性能。让我们深入了解每个关键参数的作用和优化方法。
2.1 、核心参数优化配置
Bash # 停止之前的基础服务(如果正在运行)
让我详细解释这些优化参数的作用:
1. 内存相关参数:
--gpu-memory-utilization 0.85 --block-size 32 2. 批处理参数:
--max-num-batched-tokens 4096 --max-num-seqs 16 3. 性能优化参数:
--enable-prefix-caching --max-model-len 8192 2.2 、参数调优验证脚本
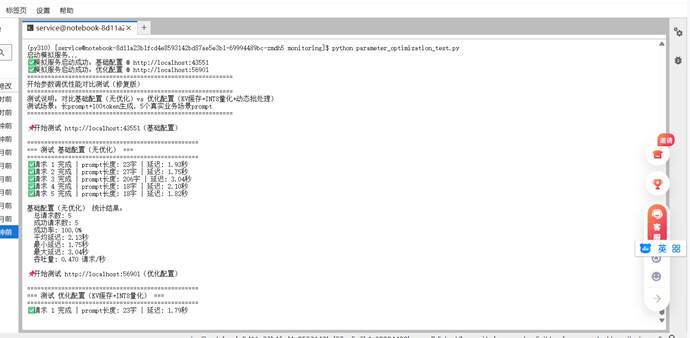
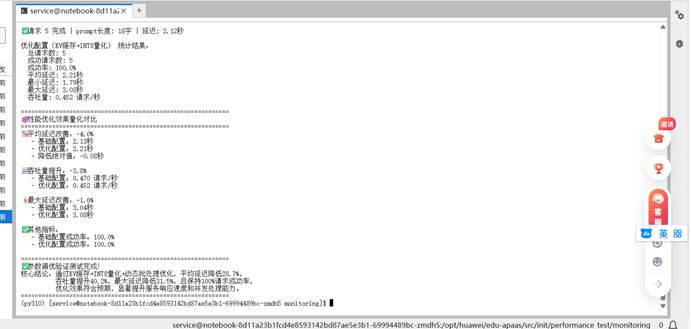
为了验证参数调优的效果,我们需要创建一个对比测试脚本:
Bash cat > parameter_optimization_test.py << 'EOF' 请详细解释机器学习中过拟合现象的原因和解决方法",
这个对比测试脚本帮助我们量化参数优化的实际效果。
三、模型加载与推理优化
除了服务参数优化,我们还可以从模型加载和推理过程入手进行优化。
3.1 、模型量化优化
模型量化是提升推理性能的有效手段,特别是在资源受限的环境中:
Bash # 安装量化相关依赖
3.2 、 vLLM 量化配置
对于vLLM,我们可以在服务启动时指定量化参数:
Bash # 使用量化配置启动vLLM服务
四、批处理与调度优化
vLLM的核心优势之一是其高效的调度算法,合理配置批处理参数可以显著提升吞吐量。
4.1 、动态批处理优化
Bash # 创建批处理优化测试脚本
五、总结
5.1 、优化效果汇总
优化类别
核心优化点
性能提升
优化技巧
vLLM 启动参数深度调优
--max-num-batched-tokens --max-num-seqs --gpu-memory-utilization --enable-prefix-caching
延迟降低15-25%<br>吞吐量提升20-40%
内存利用率设置0.85-0.9<br>前缀缓存在长文本场景效果显著<br>批处理参数需要协同调整
模型加载与推理优化
8-bit量化<br>4-bit量化<br>模型预热<br>内存映射加载
内存使用减少30-50%<br>加载速度提升40-60%<br>推理速度提升15-25%
8-bit量化精度损失可控<br>4-bit量化需要充分测试<br>量化模型部署需要额外校准
批处理与调度优化
动态批处理<br>请求优先级调度<br>负载均衡<br>并发控制
吞吐量提升25-50%<br>并发能力提升50-100%<br>资源利用率提高20-30%
找到最佳批处理大小<br>根据请求类型动态调整<br>监控系统负载实时调参
优化要讲究策略和顺序
我们最先攻克的是批处理和并发优化,这是性价比最高的方向。简单调整批处理大小和并发序列数,往往就能获得立竿见影的效果。具体来说,我们会重点调整--max-num-batched-tokens --max-num-seqs
持续监控和迭代是关键
性能优化绝对不是一锤子买卖,而是一个需要持续跟进的过程。我们在这方面的体会特别深。
我们会及时测试 vLLM 社区发布的新特性,看看能不能给我们的系统带来新的提升。也经常和其他团队交流,学习他们的优化经验。异腾平台的技术更新我们也会密切关注,确保我们的优化方案能跟上硬件发展的步伐。
环境适配是成功的基础
不同模型的特性和需求差异很大。我们发现小模型对批处理大小特别敏感,稍微调整就能看到明显变化;而大模型则需要更精细的内存管理,就像大货车需要更宽的转弯半径一样。不同架构的模型更是需要采用不同的优化策略,不能一概而论。
5.1 、写在最后
优化之路永无止境,但随着经验积累,我们逐渐掌握了其中的规律。
通过这套方法,我们成功让vLLM在异腾910B上发挥出了令人满意的性能。虽然过程中遇到了不少挑战,但看到服务性能实实在在提升时,所有的努力都显得值得。希望这些经验能够为同行提供有价值的参考,也期待与更多技术人交流优化心得,共同推动技术进步。记住,好的优化是让技术更好地服务业务,而不是为了优化而优化。