Redis入门 - 基本概念和九种数据类型
本文过一下基本的redis理论,系统性梳理知识。
介绍
Redis(Remote Dictionary Server)是一个开源的**、基于内存的键值对**存储系统。它通常被用作数据库、缓存和消息中间件。与 MySQL 等关系型数据库不同,Redis 是 NoSQL(非关系型)数据库,数据以键值对的形式存储,不支持 SQL 查询和复杂的关系模型。
redis 特性一览表:
| 特性 | 说明 | 带来的优势 |
|---|---|---|
| 基于内存存储 | 数据主要存储在内存中 | 极快的读写速度(读 11万次/秒,写 8.1万次/秒) |
| 单线程模型 | 核心网络与命令处理采用单线程 | 避免线程切换和锁竞争,简化并发控制 |
| I/O 多路复用 | 使用 **epoll**、**kqueue** 等技术 | 高效处理并发连接,单线程可应对大量客户端请求 |
| 丰富的数据结构 | 支持 String、List、Hash、Set、ZSet 等 | 适用于多种场景,如缓存、队列、排行榜等 |
| 持久化支持 | 提供 RDB 和 AOF 两种方式 | 保证数据安全,防止服务器重启后数据丢失 |
| 高可用与分布式 | 支持主从复制、哨兵和集群模式 | 提供高可用和水平扩展能力 |
为什么redis单线程能这么快?
因为它的数据全部存在内存,对数据的读取跟磁盘差了一个数量级,内存访问时间以ns为单位,磁盘访问时间以ms单位, 1ms = 1,000,000ns ,数据读写速度相差百万。
所以读写数据快,CPU处理速度更快,相当于redis单线程状态下全程在高速上跑,没有任何瓶颈,如果是多线程,反而慢了,因为多线程需要加锁(确保数据一致性),这会有性能消耗,还需要切换线程上下文,这就相当于本来好端端的在高速上跑,但被迫下高速,重新上来。所以redis基于内存设计,瓶颈不像mysql,需要多个线程慢吞吞的执行磁盘IO。
客户端上万个请求打过来,你redis凭啥单线程就能解决?
因为 I/O 多路复用有一个 epoll 技术, epoll 帮 Redis 监听所有 socket 事件 , redis就不用关心有多少请求,只关心epoll中有多少任务量,redis 快速的把epoll的任务拿来,并且在高速状态下,嗖一下执行完毕!假设epoll中有一万个任务都是找 Rediss 查数据, redis 不用1秒就能把一万条数据取出来,并且 Redis 是把结果写入 socket(通过内核),由 内核 + 网卡 负责发送给客户端。
Redis 的官方性能数据表明,一台普通的服务器上,Redis 可以轻松达到 每秒 5 万到 10 万次查询(QPS)。
唠一点操作系统原理:从物理设备可知,网络请求是由网卡接收,网卡接收数据后存储在操作系统内核中,在内核中这些数据就是一个一个socket,此时操作系统不能把请求直接推给用户进程,因为操作系统不了解用户进程的数据结构,盲目推送会破坏进程安全性。那么只能由用户进程来找内核取请求数据,早期使用select/poll 这样的技术,说白了就是轮询,假设连接了一万个数据,select/poll 要找一个万socket挨个问谁有数据,我要拿走,这种O(n)效率很低,而且select/poll在轮询时把用户进程阻塞了,对于单线程redis来说,就啥都做不了,进程卡死。epoll 技术是2002年提出的,epoll 是一个就绪队列,就理解成一个容器,用来装有数据的socket, epoll 厉害的地方不是epoll , 而是操作系统的事件推送,任何一个socket有数据了,操作系统立刻触发事件,推送到就绪队列,redis仅访问epoll就绪队列,有数据,立刻干活。**epoll** 的革命性在于它不再是用户进程主动去轮询,而是基于事件回调。tomcat底层也用到了 epoll 技术。
事件回调:当事件触发时,执行一个函数。比如 socket 有数据从不可读变可读,可以触发事件和回调函数,函数逻辑是往 epoll 容器插入可读 socket。
单线程全程高速 + IO多路复用监听上万个连接,就这种又快又稳的数据库,你还找得出第二个吗?
五种基本数据类型详解
1、String
最基本的数据类型,可以存储文本、JSON、序列化对象,甚至是图片二进制数据(最大 512MB)
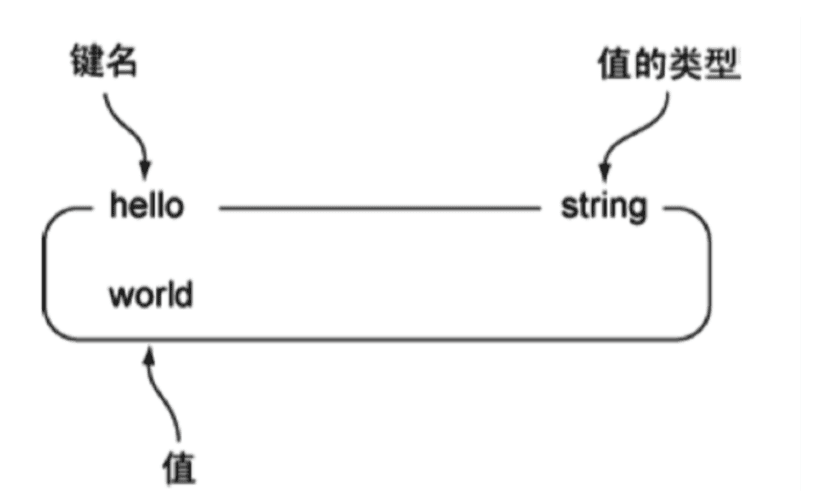
下图是一个String类型的实例,其中键为hello,值为world
- 命令使用
| 命令 | 简述 | 使用 |
|---|---|---|
| GET | 获取存储在给定键中的值 | GET name |
| SET | 设置存储在给定键中的值 | SET name value |
| DEL | 删除存储在给定键中的值 | DEL name |
| INCR | 将键存储的值加1 | INCR key |
| DECR | 将键存储的值减1 | DECR key |
| INCRBY | 将键存储的值加上整数 | INCRBY key amount |
| DECRBY | 将键存储的值减去整数 | DECRBY key amount |
127.0.0.1:6379> set hello world
OK
127.0.0.1:6379> get hello
"world"
127.0.0.1:6379> del hello
(integer) 1
127.0.0.1:6379> get hello
(nil)
127.0.0.1:6379> set counter 2
OK
127.0.0.1:6379> get counter
"2"
127.0.0.1:6379> incr counter
(integer) 3
127.0.0.1:6379> get counter
"3"
127.0.0.1:6379> incrby counter 100
(integer) 103
127.0.0.1:6379> get counter
"103"
127.0.0.1:6379> decr counter
(integer) 102
127.0.0.1:6379> get counter
"102"
- String 类型常用场景
缓存:用的最多了,把数据库的记录存在redis中,提升性能,保护脆弱的数据库。
计数器:此时 value 存储整数,有多个客户端请求 几乎同时到达,想要对redis内部的同一个计数器进行+1,由于redis是单线程设计,天生具备原子性,一个一个请求执行, 不会出现多线程编程中常见的“并发冲突”(比如 A 读到旧值、B 覆盖写)
session : 分布式 Spring Session , 缓存用户登录态,可以在spring应用停止后登录态依然存在。虽然在微服务下也可以实现所有服务共享登录态,但微服务不这么用,因为redis崩了没了登录态整个系统不是要瘫痪。Token才是更合理的微服务登录方案。
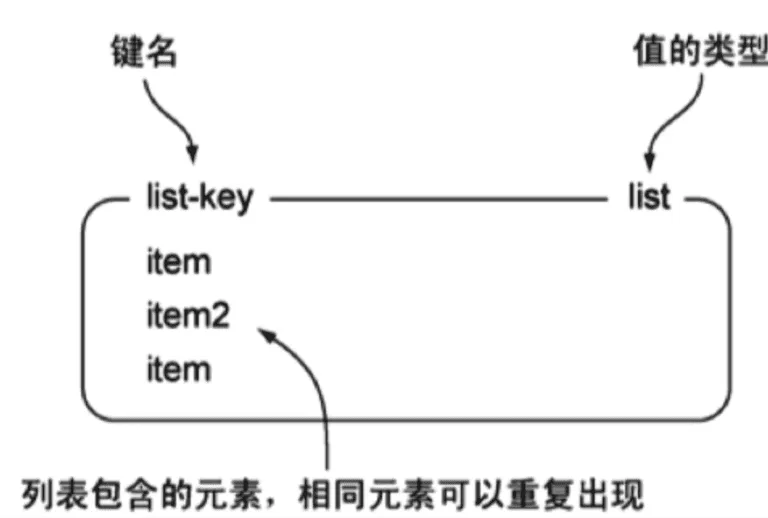
2、List列表
Redis 的 List(列表) 是一个 双向链表(linked list)结构。
- 可以在头部(left)或尾部(right)插入元素;
- 可以从头部或尾部弹出元素;
- 它按照插入顺序排序,并且允许元素重复
结构:
- 命令使用
| 命令 | 简述 | 使用 |
|---|---|---|
| RPUSH | 将给定值推入到列表右端 | RPUSH key value |
| LPUSH | 将给定值推入到列表左端 | LPUSH key value |
| RPOP | 从列表的右端弹出一个值,并返回被弹出的值 | RPOP key |
| LPOP | 从列表的左端弹出一个值,并返回被弹出的值 | LPOP key |
| LRANGE | 获取列表在给定范围上的所有值 | LRANGE key 0 -1 |
| LINDEX | 通过索引获取列表中的元素。你也可以使用负数下标,以 -1 表示列表的最后一个元素, -2 表示列表的倒数第二个元素,以此类推。 | LINDEX key index |
这个双端列表可以用来实现栈,队列,消息队列,我们一般把左边当做队列头,插入数据的入口。
-
lpush+lpop=Stack(栈)
-
lpush+rpop=Queue(队列)
-
lpush+ltrim=Capped Collection(有限集合)
-
lpush+brpop=Message Queue(消息队列)
-
命令使用
# 从左边插入 5 个元素给列表,元素的类型任意组合
127.0.0.1:6379> lpush mylist 1 2 ll ls mem
(integer) 5
# 获取范围内列表的值 , -1 一般表示最后
127.0.0.1:6379> lrange mylist 0 -1
1) "mem"
2) "ls"
3) "ll"
4) "2"
5) "1"
# 获取最后一个元素
127.0.0.1:6379> lindex mylist -1
"1"
# 获取不存在的索引,没有第 10 个元素,开头一共插入了 5 个而已
127.0.0.1:6379> lindex mylist 10
(nil)
- 常用场景
微博TimeLine: “按时间倒序排列,只展示最新内容”的列表,就是 TimeLine(时间线)。
例子如下:
# 1. 将新微博插入到用户 TimeLine 的头部
> LPUSH timeline:user:1001 "这是我的第N条微博!"
(integer) 101 # 返回当前列表长度,假设插入前是100# 2. 立即修剪列表,只保留最新的100条
> LTRIM timeline:user:1001 0 99
OK # 修剪成功
当用户打开微博刷新首页,我们只需要用 **LRANGE** 把最新的几条微博取出来就行。
# 获取用户 TimeLine 中最新的 10 条微博(索引 0 到 9)
> LRANGE timeline:user:1001 0 9
消息队列: redis 也可以实现消息队列。消息队列的核心模式是 生产者-消费者。
举例:消息队列先进先出FIFO
- 生产者用
**LPUSH**把消息塞进管道的一端。 - 消费者用
**RPOP**从管道的另一端取出消息。
生产:
# 生产者将订单ID推入名为 'order_queue' 的队列
> LPUSH order_queue "order_101"
(integer) 1 # 返回队列当前的长度> LPUSH order_queue "order_102"
(integer) 2
队列里的顺序是:**["order_102", "order_101"]**(**order_102** 在最左边)
消费:
# 消费者从队列右边弹出一个订单
> RPOP order_queue
"order_101" # 弹出的是最先进入的 order_101> RPOP order_queue
"order_102"
如果你也跟我一样这些写代码,那就跟我一样开始修bug吧!
上面的例子有一个致命问题:消费者会不断轮询,才能确保有消息立即消费,如果队列空了,**RPOP**命令也不会停歇,极大消耗内存。
改进:阻塞式弹出
Redis 提供了阻塞版本的弹出命令:**BLPOP** 和 **BRPOP**。
**BRPOP key timeout**:尝试从右边弹出一个元素。如果列表不为空,立即返回;如果为空,就阻塞等待,直到有新元素到来,或者等待超时。
# 一个优秀的消费者循环
while true:# 阻塞式弹出,如果队列为空,最多等待 30 秒# 30秒内一直没消息,会返回 nil,然后继续下一轮循环result = BRPOP order_queue 30if result != nil:# BRPOP 返回的是一个数组,如 [key, message]message = result[1]process_message(message)# 如果是超时返回 nil,循环会自动继续,无需额外 sleep
还要处理消息丢失,不支持广播,确认机制,内存积压等问题
消息丢失好处理,redis 可以用**RPOPLPUSH**(或其阻塞版本 **BRPOPLPUSH**)命令。它会将弹出的消息同时推入另一个“备份队列”(或叫“处理中队列”)。只有消息处理成功后,再手动从备份队列中移除。这提供了可靠性保障。
但是其它问题还是用专业的消息队列吧
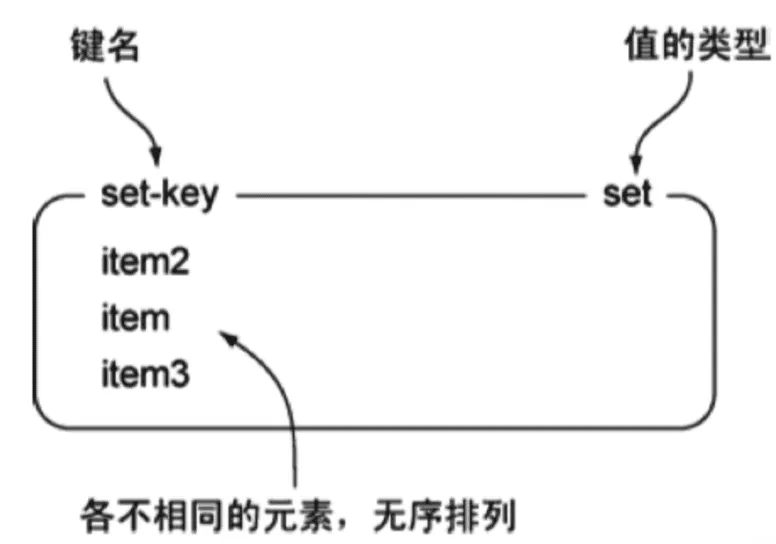
3、Set 集合
Redis 的 Set 是一个无序的、唯一的字符串集合。
- 键:就是一个普通的 Redis 字符串键,比如
**myset**、**user:1001:tags**。 - 值:是一个Set****集合数据结构,里面包含了多个唯一的字符串元素。
- 集合中的元素不允许重复。
- Set 的元素只能是 String 类型! Redis 中字符串可以包含文本、数字甚至二进制数据
图例:
- 命令使用
| 命令 | 简述 | 使用 |
|---|---|---|
| SADD | 向集合添加一个或多个成员 | SADD key value |
| SCARD | 获取集合的成员数 | SCARD key |
| SMEMBERS | 返回集合中的所有成员 | SMEMBERS key member |
| SISMEMBER | 判断 member 元素是否是集合 key 的成员 | SISMEMBER key member |
127.0.0.1:6379> sadd myset hao hao1 xiaohao hao
(integer) 3
127.0.0.1:6379> smembers myset
1) "xiaohao"
2) "hao1"
3) "hao"
127.0.0.1:6379> sismember myset hao
(integer) 1
- 实战场景
标签(tag),给用户添加标签,或者用户给消息添加标签,这样有同一标签或者类似标签的可以给推荐关注的事或者关注的人。
推荐功能实例:
为了实现推荐,我们需要双向索引:
- 用户 -> 标签:存储每个用户拥有哪些标签。
-
- 键设计:
**user:{user_id}:tags** - 值:一个 Set,包含所有标签字符串。
- 键设计:
- 标签 -> 用户:存储拥有某个标签的所有用户。
-
- 键设计:
**tag:{tag_name}:users** - 值:一个 Set,包含所有用户ID字符串。
- 键设计:
为什么需要双向? 只用 **user -> tags**,要找相似用户就得遍历所有用户,效率极低。有了 **tag -> users**,我们就能快速找到有共同标签的人群。
用户 **1001** 关注了 “Redis” 和 “数据库”, 这两个 tag 绑定用户 1001 , 为了实现推荐。
# 1. 将标签添加到用户的标签集合中
> SADD user:1001:tags "Redis" "数据库"
(integer) 2# 2. 同时,将用户ID添加到每个标签对应的用户集合中(反向索引)
> SADD tag:Redis:users "1001"
(integer) 1
> SADD tag:数据库:users "1001"
(integer) 1
用户 **1002** 关注了 “Redis” 和 “缓存”。
> SADD user:1002:tags "Redis" "缓存"
(integer) 2
> SADD tag:Redis:users "1002"
(integer) 1
> SADD tag:缓存:users "1002"
(integer) 1
现在,我们要为用户 **1001** 推荐与他最相似的用户 **1002**。
# 1. 获取用户1001的所有标签
> SMEMBERS user:1001:tags
1) "数据库"
2) "Redis"# 2. 找到与用户1001有共同标签的用户
# 方法:取他所有标签对应的用户集合的并集,然后排除他自己
> SUNION tag:数据库:users tag:Redis:users
1) "1001"
2) "1002"# 3. 从结果中移除用户1001自己
> SREM recommended_users_for_1001 "1001"
(integer) 1# 4. 查看最终推荐列表
> SMEMBERS recommended_users_for_1001
1) "1002"
注意:为了演示,我用了一个临时键 **recommended_users_for_1001**,实际中可以直接在应用逻辑里处理
**这里有坑:**小的数据集没什么问题,但标签或用户量大,集合就会很大,非常吃性能。
点赞,或点踩,收藏等,可以放到set中实现
点赞举例:
用户 **1001** 给文章 **post:123** 点赞。
# 将用户ID添加到文章的点赞集合中
> SADD post:123:likes "1001"
(integer) 1 # 返回1,表示成功添加
如果用户 **1001** 又点了一次(手滑了):
> SADD post:123:likes "1001"
(integer) 0 # 返回0,因为元素已存在,操作无效
看,Set 自动帮我们解决了重复点赞的问题!
用户 **1001** 取消点赞。
> SREM post:123:likes "1001"
(integer) 1 # 返回1,表示成功删除
检查用户 **1001** 是否已点赞:
> SISMEMBER post:123:likes "1001"
(integer) 0 # 返回0,表示没点赞
获取文章总点赞数:
> SCARD post:123:likes
(integer) 15
键的命名设计可真灵活,真有用。
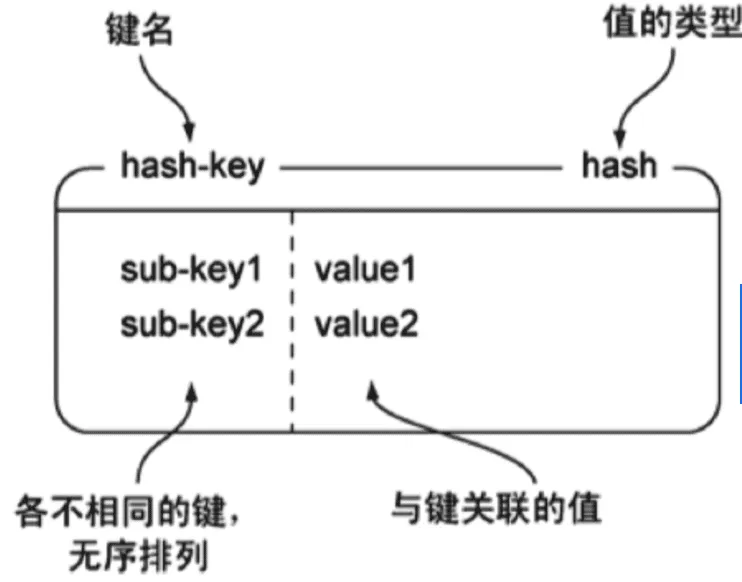
4、hash 散列表
Redis hash 是一个 string 类型的 field(字段) 和 value(值) 的映射表,hash 特别适合用于存储对象。
一个键,值内部可以是多个键值对,很像一个“小型对象”。
- 命令使用
| 命令 | 简述 | 使用 |
|---|---|---|
| HSET | 添加键值对 | HSET hash-key sub-key1 value1 |
| HGET | 获取指定散列键的值 | HGET hash-key key1 |
| HGETALL | 获取散列中包含的所有键值对 | HGETALL hash-key |
| HDEL | 如果给定键存在于散列中,那么就移除这个键 | HDEL hash-key sub-key1 |
127.0.0.1:6379> hset user name1 hao
(integer) 1
127.0.0.1:6379> hset user email1 hao@163.com
(integer) 1
127.0.0.1:6379> hgetall user
1) "name1"
2) "hao"
3) "email1"
4) "hao@163.com"
127.0.0.1:6379> hget user user
(nil)
127.0.0.1:6379> hget user name1
"hao"
127.0.0.1:6379> hset user name2 xiaohao
(integer) 1
127.0.0.1:6379> hset user email2 xiaohao@163.com
(integer) 1
127.0.0.1:6379> hgetall user
1) "name1"
2) "hao"
3) "email1"
4) "hao@163.com"
5) "name2"
6) "xiaohao"
7) "email2"
8) "xiaohao@163.com"
-
实战场景
-
- 缓存: 能直观,相比string更节省空间,的维护缓存信息,如用户信息,视频信息等。
5、Zset 有序集合
Redis 有序集合和set集合一样, 也是 string 类型元素的集合,且不允许重复的成员。不同的是每个元素都会关联一个 double 类型的分数。redis 正是通过分数来为集合中的成员进行从小到大的排序。
一个key下,有一个小型对象,字符串对象 + score 为一对,可以有多对,字符串对象是set集合的对象,不能重复。
- 图例
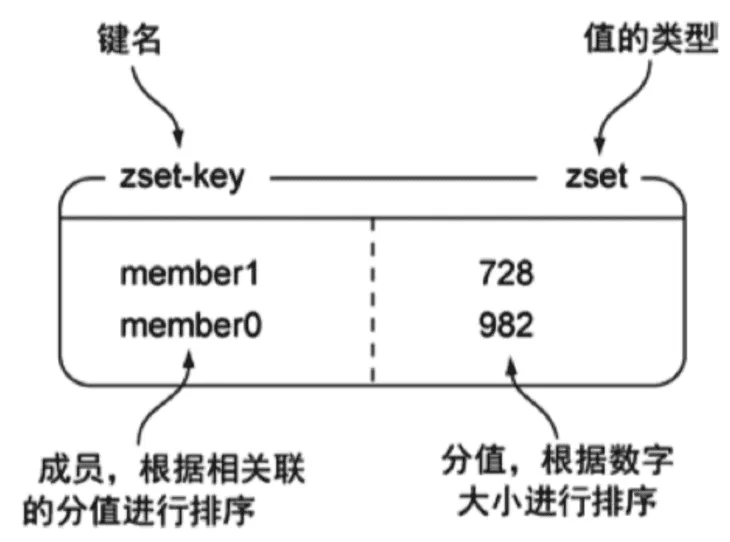
- 命令使用
| 命令 | 简述 | 使用 |
|---|---|---|
| ZADD | 将一个带有给定分值的成员添加到有序集合里面 | ZADD zset-key 178 member1 |
| ZRANGE | 根据元素在有序集合中所处的位置,从有序集合中获取多个元素 | ZRANGE zset-key 0-1 withccores |
| ZREVRANGE | 获取指定排名范围内的成员(从高分到低分) | 语法: ZREVRANGE key start stop [WITHSCORES]示例: ZREVRANGE leaderboard 0 2 WITHSCORES (获取Top 3) |
| ZSCORE | 获取指定成员的分数 | 语法: ZSCORE key member示例: ZSCORE leaderboard "player1" |
| ZREVRANK | 获取指定成员的排名(从高到低,0-based) | 语法: ZREVRANK key member示例: ZREVRANK leaderboard "player1" |
| ZRANK | 获取指定成员的排名(从低到高,0-based) | 语法: ZRANK key member示例: ZRANK leaderboard "player1" |
| ZREM | 如果给定元素成员存在于有序集合中,那么就移除这个元素 | ZREM zset-key member1 |
127.0.0.1:6379> zadd myscoreset 100 hao 90 xiaohao
(integer) 2
127.0.0.1:6379> ZRANGE myscoreset 0 -1
1) "xiaohao"
2) "hao"
127.0.0.1:6379> ZSCORE myscoreset hao
"100"
- 实战场景
排行榜:有序集合经典使用场景。例如小说视频等网站需要对用户上传的小说视频做排行榜,榜单可以按照用户关注数,更新时间,字数等打分,做排行。
**举例:**视频网站排行榜
数据结构设计
- Key:
**leaderboard:videos:daily**(表示每日视频排行榜) - Member:视频ID,如
**"video:101"** - Score:综合评分,可以是
**(点赞数 \* 1 + 播放量 \* 0.1)**,这样设计可以灵活调整权重。
假设视频 **video:101** 获得了 1000 个赞和 5000 次播放。我们计算它的分数为 **1000\*1 + 5000\*0.1 = 1500**。
# 使用 ZADD 命令添加或更新视频的分数
> ZADD leaderboard:videos:daily 1500 "video:101"
(integer) 1 # 返回1,表示新元素被添加
现在视频 **video:102** 更火,获得了 2000 个赞和 8000 次播放,分数为 **2000 + 800 = 2800**。
> ZADD leaderboard:videos:daily 2800 "video:102"
(integer) 1
查看排行榜:
# ZREVRANGE 按分数从高到低获取排名 0 到 9 的元素
# WITHSCORES 选项表示同时返回分数
> ZREVRANGE leaderboard:videos:daily 0 9 WITHSCORES
1) "video:102"
2) "2800"
3) "video:101"
4) "1500"
获取视频的排名和分数:
# ZREVRANK 获取成员的排名(从高到低,0-based)
> ZREVRANK leaderboard:videos:daily "video:101"
(integer) 1 # 返回1,表示排名第2(因为排名第1的索引是0)# ZSCORE 获取成员的分数
> ZSCORE leaderboard:videos:daily "video:101"
"1500"
三种特殊类型
1、 HyperLogLogs(基数统计)
基数(Cardinality)简单来说,就是一个集合中不重复元素的数量。举例:
给出一个数字集合 {1, 3, 5, 7, 5, 7, 8} , 你能找到几个不重复的数? 5个 {1, 3, 5, 7, 8},基数就是5.
基数的应用之一:统计网站独立访客数(UV) 就是一个典型的基数统计场景,同一个用户一天内多次访问只计一次
HyperLogLog(HLL)是一种用于基数统计的概率性数据结构,它能以极小的内存开销来估算一个集合中不重复元素的数量(即基数)。即使面对海量数据,它也能提供相当准确的近似值,非常适合大数据场景下的去重统计。
数据结构: key:string , value: 一个基数集合
为什么不用set去重?
Set 会把所有元素都存下来,占用内存非常大。
- 果你要统计上亿个用户,那
Set可能占几百 MB; - 而
HyperLogLog只需要 12 KB 就能统计上亿个不同元素!
注意: HyperLogLog 是一种 概率型数据结构,它的结果不是精确值,
存在 0.81% 左右的误差。
工作原理:前导零序列 + 哈希桶,设计到概率算法,非重点学习知识。
- 命令使用
PFADD , PFCOUNT , PFMERGE
127.0.0.1:6379> pfadd key1 a b c d e f g h i # 创建第一组元素
(integer) 1
127.0.0.1:6379> pfcount key1 # 统计元素的基数数量
(integer) 9
127.0.0.1:6379> pfadd key2 c j k l m e g a # 创建第二组元素
(integer) 1
127.0.0.1:6379> pfcount key2
(integer) 8
127.0.0.1:6379> pfmerge key3 key1 key2 # 合并两组:key1 key2 -> key3 并集
OK
127.0.0.1:6379> pfcount key3
(integer) 13
2、Bitmap (位存储)
Bitmap(位图)是一种非常节省空间的数据结构,它用二进制位(bit)来标记某个元素对应的值,每个 bit 位只能表示 0 或 1 两种状态。它特别适合用于海量数据下,对布尔状态(如存在/不存在、是/否、签到/未签到)的快速查询和统计。
数据结构:key: string , value : 一个二进制数组 。
# 语法
SETBIT key offset value# 设置value数组的第5位为1, 表示签到,登录,打卡等等含义
SETBIT login:2025-11-06 5 1
-
key:bitmap 名 -
offset:位的索引,从 0 开始 -
value:0 或 1 -
命令使用
使用bitmap 来记录 周一到周日的打卡! 周一:1 周二:0 周三:0 周四:1 …
127.0.0.1:6379> setbit sign 0 1
(integer) 0
127.0.0.1:6379> setbit sign 1 1
(integer) 0
127.0.0.1:6379> setbit sign 2 0
(integer) 0
127.0.0.1:6379> setbit sign 3 1
(integer) 0
127.0.0.1:6379> setbit sign 4 0
(integer) 0
127.0.0.1:6379> setbit sign 5 0
(integer) 0
127.0.0.1:6379> setbit sign 6 1
(integer) 0
查看某一天是否有打卡!
127.0.0.1:6379> getbit sign 3
(integer) 1
127.0.0.1:6379> getbit sign 5
(integer) 0
统计操作,统计 打卡的天数!
127.0.0.1:6379> bitcount sign # 统计这周的打卡记录,就可以看到是否有全勤!
(integer) 3
3、geospatial (地理位置)
Redis Geospatial 是一种用来存储地理位置信息(经纬度)并支持距离计算、范围查询的特殊数据结构。
数据结构:
| Zset 字段 | 含义 |
|---|---|
| key | 地理位置集合的名字(比如 city:shops) |
| member | 成员名(比如 beijing、guangzhou) |
| score | 经纬度转换后的编码值(一个浮点数) |
存一个天安门的经纬度
GEOADD city:shops 116.397 39.908 "Tiananmen"
- key:
city:shops - member:
"Tiananmen"(地点名字) - longitude:
116.397 - latitude:
39.908
取出来
127.0.0.1:6379> GEOPOS city:shops "Tiananmen"1) "116.39700025320053101"2) "39.90799967164979734"
内部工作原理:
底层数据结构是这样,本质上是基于 ZSet 实现,我们存入的经纬度,在通过geohash后,保存为一个 score 。
Redis Database
└── key: "city:shops" ← 这是一个 Zset├── member: "Beijing" → score: geohash(116.397, 39.908)├── member: "Shanghai" → score: geohash(121.4737, 31.2304)└── member: "Guangzhou" → score: geohash(113.264, 23.129)
Geohash 是一种把“经纬度 → 数字” 的编码方法 。
它会把地球划成很多网格(格子越细,位置越精确),然后把经纬度编码成一个可排序的数字(或字符串)。
同一地区的经纬度编码前缀相似。所以排序时,附近的点会靠得很近。
Redis 用的正是 52-bit 的 Geohash 整数 作为 score,因此可以复用 Zset 的范围查找、排序、距离计算等能力。
使用命令:
| 命令 | 作用 | 示例 |
|---|---|---|
| GEOADD | 添加地理坐标点(经纬度 + 名称) | GEOADD key longitude latitude member [longitude latitude member ...] |
| GEOPOS | 获取指定地点的经纬度 | GEOPOS key member [member ...] |
| GEODIST | 计算两个地点之间的距离 | `GEODIST key member1 member2 [m |
| GEOHASH | 获取地点的 Geohash 字符串 | GEOHASH key member [member ...] |
| GEORADIUS (新旧版本通用,但不推荐) | 搜索某个位置附近的点(半径或矩形) | |
| GEOSEARCH (redis版本 > 6.2) | 搜索某个位置附近的点(半径或矩形) | GEOSEARCH key FROMMEMBER member BYRADIUS radius km |
| GEOSEARCHSTORE(redis版本 > 6.2) | 搜索并把结果存入新 key | GEOSEARCHSTORE destkey sourcekey FROMMEMBER member BYRADIUS radius km |
| DEL | 删除key,支持多个key | DEL beijing:spots |
示例:
添加地理位置:天安门,紫禁城,北海公园,王府井,北京南站
GEOADD beijing:spots 116.397 39.908 "Tiananmen" 116.404 39.916 "ForbiddenCity" 116.379 39.924 "BeihaiPark" 116.417 39.915 "Wangfujing" 116.385 39.865 "BeijingSouthStation"
获取指定地标的经纬度
GEOPOS beijing:spots Tiananmen ForbiddenCity
计算两点之间的距离:
GEODIST beijing:spots Tiananmen ForbiddenCity km"1.0716"
表示天安门与故宫相距约 “1.07” 公里。
搜索半径范围内的地标:
从 “Tiananmen” 出发,查找 3km 范围内的地标,并返回距离与坐标。
GEOSEARCH beijing:spots FROMMEMBER Tiananmen BYRADIUS 3 km WITHDIST WITHCOORD# 6.2 以下的版本使用 ,WITHDIST:返回距离中心的距离,WITHCOORD:返回每个地点的经纬度
GEORADIUS beijing:spots 116.397 39.908 3 km WITHDIST WITHCOORD1) 1) "Tiananmen"2) "0.0000"3) 1) "116.39700001478195"2) "39.907999989665997"
2) 1) "ForbiddenCity"2) "0.94"3) 1) "116.40400001460314"2) "39.91599998955002"
3) 1) "Wangfujing"2) "1.94"3) 1) "116.41700000000000"2) "39.91500000000000"
4) 1) "BeihaiPark"2) "2.20"3) 1) "116.37900000000000"2) "39.92400000000000"
Stream - 更强大的redis消息队列
Redis5.0 中还增加了一个数据类型Stream,它借鉴了Kafka的设计,是一个新的强大的支持多播的可持久化的消息队列。
Stream 从字面上看是流类型,但其实从功能上看,应该是Redis对消息队列(MQ,Message Queue)的完善实现。
为什么redis需要添加Stream做消息队列?
大家很喜欢使用redis来做消息队列,因为实现简单,并且性能强悍,不用额外引入中间件,很多数据量小的场景,使用redis比主流消息队列是更明智的技术选型。
用过Redis做消息队列的都了解,基于Reids的消息队列实现有很多种,例如:
-
PUB/SUB,订阅/发布模式
-
- 但是发布订阅模式是无法持久化的,如果出现网络断开、Redis 宕机等,消息就会被丢弃;
-
基于List LPUSH+BRPOP 或者 基于Sorted-Set的实现
-
- 支持了持久化,但是不支持多播,分组消费等
为什么上面的结构无法满足广泛的MQ场景? 这里便引出一个核心的问题:如果我们期望设计一种数据结构来实现消息队列,最重要的就是要理解设计一个消息队列需要考虑什么?初步的我们很容易想到
-
消息的生产
-
消息的消费
-
- 单播和多播(多对多)
- 阻塞和非阻塞读取
-
消息有序性
-
消息的持久化
其它还要考虑啥嗯?借助美团技术团队的一篇文章,消息队列设计精要中的图
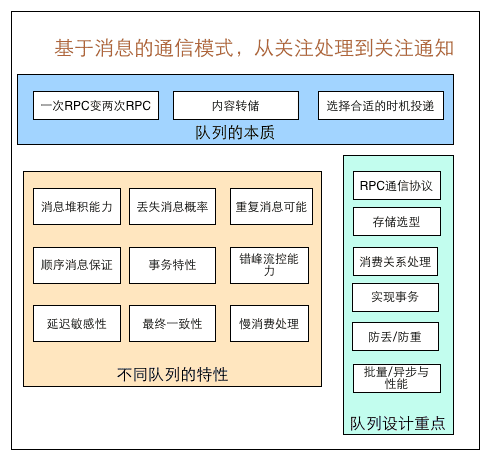
我们不妨看看Stream考虑了哪些设计?
- 消息ID的序列化生成
- 消息遍历
- 消息的阻塞和非阻塞读取
- 消息的分组消费
- 未完成消息的处理
- 消息队列监控
- …
这也是我们需要理解Stream的点,但是结合上面的图,我们也应该理解Redis Stream也是一种超轻量MQ并没有完全实现消息队列所有设计要点.
stream 数据结构和使用
先在脑中形成 Stream 的数据模型,假设你现在有一个普通 list , 存了三条消息:
[ msg1, msg2, msg3 ]
Stream 只是在这个基础上:
- 给每条消息 自动编号(时间戳-ID)
- 支持分组消费
- 支持确认机制(ACK)
- 支持阻塞等待新消息
于是它变成了:
mystream: {"1730862340000-0": { "user": "alice", "action": "login" },"1730862345000-0": { "user": "bob", "action": "logout" },"1730862348000-0": { "user": "carol", "action": "buy" }
}
| 层级 | 类型 | 说明 |
|---|---|---|
mystream | Stream 对象 | Redis 的特殊数据结构 |
| entry_id | 字符串(String), 前半部分是毫秒时间戳 , 后半部分是同一毫秒内的自增序号 | 格式为 时间戳-序列号,保证唯一、递增 |
| 消息体 | 消息内容在 Redis Stream 中是「字段:值(field:value)成对」出现的! | 实际上存储在一个 Radix Tree(压缩前缀树)中 |
- 使用示例
# * 表示让 Redis 自动生成消息的唯一 ID
# 消息体是成双成对的出现,内部结构是 user:alice , action:login
XADD mystream * user alice action login# 错误示例
XADD mystream * user alice loginERR wrong number of arguments for 'xadd' command
Stream 数据结构和消息队列的联系
Stream 数据结构很简单,一个Stream 内部多个 entry_id : { 消息体 } , 这跟消息队列有啥联系呢?
MQ 的核心特征:
- 顺序存储消息
- 消费者可以读取消息
- 支持消费确认/重试
- 支持多消费者协作(消费组)
stream 结构可以实现这些核心特征:
- 顺序存储:entry_id 保证消息按时间顺序排列
生产者使用命令:
(顺序生产消息)
| 命令 | 说明 | 示例 |
|---|---|---|
XADD | 往 Stream 添加一条消息 | XADD mystream * user alice action login |
stream 消费者读取消息命令:
| 命令 | 说明 | 示例 |
|---|---|---|
XREAD | 阻塞或非阻塞读取 Stream 消息 | XREAD COUNT 2 STREAMS mystream 0 |
XREADGROUP | 从消费者组读取消息 | XREADGROUP GROUP groupA consumer1 COUNT 2 STREAMS mystream > |
stream 消费者组管理命令:
| 命令 | 说明 | 示例 |
|---|---|---|
XGROUP CREATE | 创建消费者组 | XGROUP CREATE mystream groupA 0 |
XGROUP DESTROY | 删除消费者组 | XGROUP DESTROY mystream groupA |
XGROUP SETID | 设置消费者组起始 ID | XGROUP SETID mystream groupA $ |
消息确认命令:
| 命令 | 说明 | 示例 |
|---|---|---|
XACK | 确认消息已消费 | XACK mystream groupA 1730862340000-0 |
XPENDING | 查看 Pending List | XPENDING mystream groupA |
XCLAIM | 将未确认消息分配给其他消费者 | XCLAIM mystream groupA consumer2 5000 1730862340000-0 |
查询消息命令:
| 命令 | 说明 | 示例 |
|---|---|---|
XRANGE | 按 ID 范围查询消息 | XRANGE mystream - + |
XREVRANGE | 按 ID 逆序查询消息 | XREVRANGE mystream + - |
XLEN | Stream 消息条数 | XLEN mystream |
XDEL | 删除指定消息 | XDEL mystream 1730862340000-0 |
- 写入:
XADD - 读取:
XREAD/XREADGROUP - 消费者组管理:
XGROUP CREATE/DESTROY/SETID - 消费确认:
XACK+XPENDING+XCLAIM - 查询 & 管理:
XRANGE/XREVRANGE/XLEN/XDEL/XTRIM
这么看Stream 的数据结构 + 命令功能确实就是消息队列!
实在是难理解的话,就把 Steam 看成 List ,内部结构先不管,生产者是Spring应用,执行 XADD 往 stream 插入一条消息(不管消息结构),消费者也可以是Spring应用,使用命令 XGROUP 组成一个群组,使用 XREAD 命令消费。 这就形成了一个 生产-消费模型,实现了解耦。
不过肉眼也能看出来 stream 有 entry_id 保证消息顺序,还有 XACK 命令作为消息确认机制,就单单这两个优点,已经比 List 更适合做消息队列了。 再加上消费者群组管理,并且支持消息查询、消息管理, 直接碾压 List。
使用示例
增删改查熟悉命令
我们用一下 stream 的增删改查,来快速熟悉命令,这里不涉及任何消息队列的概念,思维切换过来,我们是在纯粹的玩耍增删改查:
----------
增加
----------
# *号表示服务器自动生成ID,后面顺序跟着一堆key/value
127.0.0.1:6379> xadd codehole * name laoqian age 30 # 名字叫laoqian,年龄30岁
1527849609889-0 # 生成的消息ID127.0.0.1:6379> xadd codehole * name xiaoyu age 29
1527849629172-0
127.0.0.1:6379> xadd codehole * name xiaoqian age 1
1527849637634-0
127.0.0.1:6379> xlen codehole
(integer) 3----------
查找
----------# -表示最小值, +表示最大值
127.0.0.1:6379> xrange codehole - +
1) 1) 1527849609889-01) 1) "name"1) "laoqian"2) "age"3) "30"
2) 1) 1527849629172-01) 1) "name"1) "xiaoyu"2) "age"3) "29"
3) 1) 1527849637634-01) 1) "name"1) "xiaoqian"2) "age"3) "1"
127.0.0.1:6379> xrange codehole 1527849629172-0 + # 指定最小消息ID的列表
1) 1) 1527849629172-02) 1) "name"2) "xiaoyu"3) "age"4) "29"
2) 1) 1527849637634-02) 1) "name"2) "xiaoqian"3) "age"4) "1"
127.0.0.1:6379> xrange codehole - 1527849629172-0 # 指定最大消息ID的列表
1) 1) 1527849609889-02) 1) "name"2) "laoqian"3) "age"4) "30"
2) 1) 1527849629172-02) 1) "name"2) "xiaoyu"3) "age"4) "29"----------
删除单条记录
----------
127.0.0.1:6379> xdel codehole 1527849609889-0
(integer) 1
----------
查询长度
----------
127.0.0.1:6379> xlen codehole # 长度不受影响# XDEL 只是标记删除消息,Stream 内部结构仍保留占位,这样有助于 消费组的偏移管理。(integer) 3
127.0.0.1:6379> xrange codehole - + # 被删除的消息没了
1) 1) 1527849629172-02) 1) "name"2) "xiaoyu"3) "age"4) "29"
2) 1) 1527849637634-02) 1) "name"2) "xiaoqian"3) "age"4) "1"127.0.0.1:6379> del codehole # 删除整个Stream
(integer) 1
单消费者独立消费
我们可以在不定义消费组的情况下进行Stream消息的独立消费,当Stream没有新消息时,甚至可以阻塞等待。Redis设计了一个单独的消费指令xread,可以将Stream当成普通的消息队列(list)来使用。使用xread时,我们可以完全忽略消费组(Consumer Group)的存在,就好比Stream就是一个普通的列表(list)。
# 从Stream头部读取两条消息 , 0-0 → 从 最早的消息开始读取(ID 从头开始)
127.0.0.1:6379> xread count 2 streams codehole 0-0
1) 1) "codehole"2) 1) 1) 1527851486781-02) 1) "name"2) "laoqian"3) "age"4) "30"2) 1) 1527851493405-02) 1) "name"2) "yurui"3) "age"4) "29"# 从Stream尾部读取一条消息,毫无疑问,这里不会返回任何消息, $ 表示只处理新添加的消息,消息队列内的消息我不管
127.0.0.1:6379> xread count 1 streams codehole $
(nil)# 从尾部阻塞等待新消息到来,下面的指令会堵住,直到新消息到来 , 只堵塞一次,有消息返回处理就不堵塞了。
127.0.0.1:6379> xread block 0 count 1 streams codehole $# 我们从新打开一个窗口,在这个窗口往Stream里塞消息
127.0.0.1:6379> xadd codehole * name youming age 60
1527852774092-0# 再切换到前面的窗口,我们可以看到阻塞解除了,返回了新的消息内容
# 而且还显示了一个等待时间,这里我们等待了93s
127.0.0.1:6379> xread block 0 count 1 streams codehole $
1) 1) "codehole"2) 1) 1) 1527852774092-02) 1) "name"2) "youming"3) "age"4) "60"
(93.11s)
消费者组示例
创建消费者组 cg1, 0 表示从最早的消费开始消费。cg2,$ 表示只消费新来的消息,旧的消息我不管
127.0.0.1:6379> XADD codehole * name laoqian age 30
"1762404547239-0"
127.0.0.1:6379> XADD codehole * name xiaoyu age 29
"1762404550572-0"
127.0.0.1:6379> XADD codehole * name xiaoqian age 1
"1762404554796-0"
127.0.0.1:6379> XGROUP CREATE codehole cg1 0
OK
127.0.0.1:6379>xgroup create codehole cg2 $
OK127.0.0.1:6379> xinfo stream codehole # 获取Stream信息1) length2) (integer) 3 # 共3个消息3) radix-tree-keys4) (integer) 15) radix-tree-nodes6) (integer) 27) groups8) (integer) 2 # 两个消费组9) first-entry # 第一个消息
10) 1) 1527851486781-02) 1) "name"2) "laoqian"3) "age"4) "30"
11) last-entry # 最后一个消息
12) 1) 1527851498956-02) 1) "name"2) "xiaoqian"3) "age"4) "1"127.0.0.1:6379> xinfo groups codehole # 获取Stream的消费组信息
1) 1) name2) "cg1"3) consumers4) (integer) 0 # 该消费组还没有消费者5) pending6) (integer) 0 # 该消费组没有正在处理的消息
2) 1) name2) "cg2"3) consumers # 该消费组还没有消费者4) (integer) 05) pending6) (integer) 0 # 该消费组没有正在处理的消息
消费者加入消费者组,并且开始消费:
消费者名字不用提前注册,只要你第一次用 **XREADGROUP** 指定了消费者名,这个消费者就自动加入了组。
这个消费者仅仅是一个名字,在实际应用中, 通常会用一个 应用实例或线程 对应一个消费者名 ,程序通过消费者名来执行消费命令,我们也可以手动写命令来操作消费者。
XREADGROUP GROUP <组名> <消费者名> COUNT <数量> BLOCK <毫秒> STREAMS <stream名> <消息ID># 消费组 cg1,消费者 consumer1
XREADGROUP GROUP cg1 consumer1 COUNT 1 BLOCK 5000 STREAMS codehole >
1) 1) "codehole"2) 1) 1) "1762404547239-0"2) 1) "name"2) "laoqian"3) "age"4) "30"
# 打印出已消费的数据。# 查看消费者
XINFO CONSUMERS codehole cg1
解释:
cg1→ 消费组consumer1→ 消费者名COUNT 1→ 每次读取 1 条BLOCK 5000→ 如果没有消息,阻塞 5 秒STREAMS codehole >→ 获取组内 新消息(未被任何消费者处理过的)
以上语句的意思是开始消费,如果 XREADGROUP 在Spring 应用运行,你就拿到了消息队列的消息,然后执行业务逻辑。
再次新增一个消费者:
XREADGROUP GROUP cg1 consumer2 COUNT 1 BLOCK 5000 STREAMS codehole ># 查看消费组状态
XINFO CONSUMERS codehole cg1
1) 1) "name"2) "consumer1"3) "pending"4) (integer) 15) "idle"6) (integer) 584233
2) 1) "name"2) "consumer2"3) "pending"4) (integer) 15) "idle"6) (integer) 13934
此时 Redis 会把新来的消息在 consumer1 和 consumer2 之间分配(负载均衡) 。
在第二个消费组中加一个消费者:
# 第二个消费者我们定义了 $,表示只消费新来的消息,原有stream的消息我不负责
XREADGROUP GROUP cg2 consumerA COUNT 1 BLOCK 5000 STREAMS codehole ># 所以我们在另一个窗口生产一条消息
127.0.0.1:6379> XADD codehole * name laoqian age 30# 主窗口就会看到消费了。
总结:
消费组声明: 可以声明0 , 从最早的消息开始消费,也可以声明$, 只消费新来的消息,已有消息我不管。
消费者仅是名字:每个线程或实例对应一个消费者名字,第一次 使用 XREADGROUP 就加入组。
消息分配 : 默认一条消息只分配给组内一个消费者 。
可靠消费 : 消息处理完必须 XACK 。
可以随时加消费者 : 组里可以随时启动新的消费者,Redis 会自动分配新消息给它 ,自动负载均衡。