PyTorch深度学习进阶(一)(经典卷积神经网络 LeNet)
前言
PyTorch深度学习基础部分可以参考之前的专栏:PyTorch深度学习基础笔记
本次进阶笔记将以b站up:跟李沐学AI为基础,主要针对特殊的深度学习网络结构(如Transformer等)与一些进阶操作并结合我自身需要,对基础版笔记起到提升和补充作用
LeNet
卷积神经网络中最为有名的网络之一,如下图所示
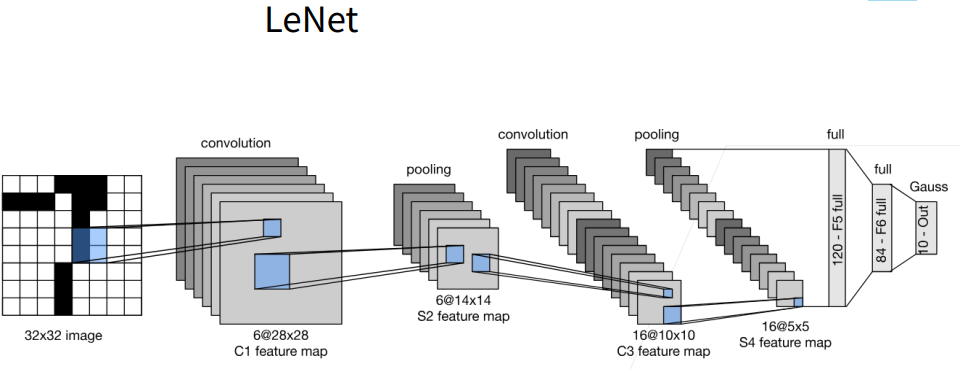
LeNet早期用来手写数字识别的应用

MNIST数据集作为知名度较高的简单的手写数字数据集,适合用来作为练习使用

总结来说
- LeNet是早期成功的神经网络
- 先使用卷积层来学习图片空间信息
- 然后使用全连接层来转换到类别空间
LeNet代码
LeNet由两个部分组成:卷积编码器和全连接层密集块
导入d2l包
from d2l import torch as d2ld2l库是一个与《动手学深度学习》(Dive into Deep Learning)一书配套的开源教学库,由李沐等人设计。这个库旨在帮助读者通过实践经验来理解和掌握深度学习的基础知识和核心算法,如神经网络、卷积神经网络(CNN)、循环神经网络(RNN)等。(注意截至2025.11.07,此包暂未适配python3.12,可以使用下列命令跳过版本审查强制安装或降级python版本)
pip install --no-deps d2l
定义Reshape类,因为后面要用Sequential
把x改为批量数(batch)自适应得到,通道数为1,图片为28X28。(-1即为根据其他参数自适应补齐)
class Reshape(torch.nn.Module):def forward(self, x):return x.view(-1, 1, 28, 28)使用Sequential定义网络结构
为了得到非线性性,在卷积后面添加Sigmoid激活函数
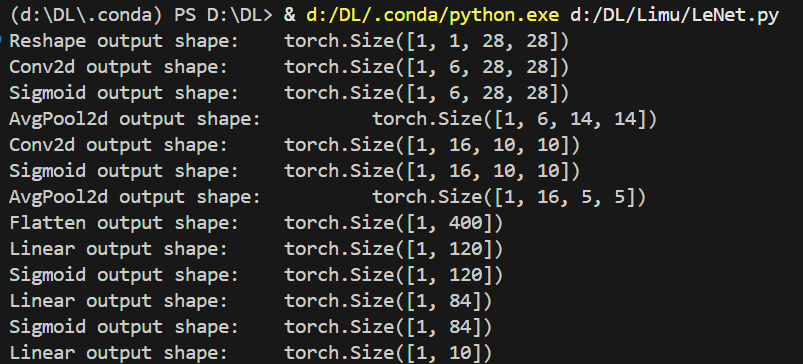
net = nn.Sequential(Reshape(),nn.Conv2d(1, 6, kernel_size=5, padding=2),nn.Sigmoid(),nn.AvgPool2d(kernel_size=2, stride=2),nn.Conv2d(6, 16, kernel_size=5),nn.Sigmoid(),nn.AvgPool2d(kernel_size=2, stride=2),nn.Flatten(),nn.Linear(16 * 5 * 5, 120),nn.Sigmoid(),nn.Linear(120, 84),nn.Sigmoid(),nn.Linear(84, 10))定义完成后,随机给一个x输入
x = torch.rand(1, 1, 28, 28, dtype=torch.float32)对网络中每一层进行一次迭代,即算一下x在每一层的输出并打印出来
for layer in net:x = layer(x)print(layer.__class__.__name__,'output shape: \t', x.shape)结果可以看出数据在每一层中的形状变化
LeNet在Fashion-MNIST数据集上的表现
- 加载 Fashion-MNIST 数据集(10类服装图片,28×28像素)
- 分成训练集迭代器 train_iter 和测试集迭代器 test_iter
- 每批次 256 张图片
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size=batch_size)对evaluate_accuracy函数进行轻微的修改,使用GPU计算模型在数据集上的精度
def evaluate_accuracy_gpu(net, data_iter, device=None):如果网络是torch.nn形式,net.eval()开启验证模式,不用计算梯度和更新梯度
if isinstance(net, torch.nn.Module):net.eval()如果device没有给定,则看net.parameters()中第一个元素的device为哪里
if not device:device = next(iter(net.parameters())).device累加器:[正确预测数, 总样本数]
metric = d2l.Accumulator(2)对每个data_iter的x和y,如果X是个List,则把每个元素都移到device上
for X, y in data_iter:if isinstance(X,list):X = [x.to(device) for x in X]如果X是一个Tensor,则只用移动一次,直接把X移动到device上
else:X = X.to(device)对y(标签)也同理
y = y.to(device)把x放到网络里,计算准确率,正确数 / 总数 = 准确率,y.numel() 为y元素个数
metric.add(d2l.accuracy(net(X),y),y.numel())
return metric[0]/metric[1]为了使用GPU,还需要一点小改动
使用train_ch6函数
def train_ch6(net, train_iter, test_iter, num_epochs, lr, device):初始化权重并移到设备
Xavier均匀初始化,只对全连接层(nn.Linear)和卷积层(nn.Conv2d)进行初始化
Xavier(也叫 Glorot)初始化:专为深度网络设计的权重初始化方法
- 均匀分布版本:从区间 [-a, a] 均匀采样,其中 a = sqrt(6 / (fan_in + fan_out))
- fan_in:输入神经元数量
- fan_out:输出神经元数量
为什么用 Xavier?
- 保持前向传播和反向传播时的方差稳定
- 避免梯度消失/爆炸问题
- 特别适合 Sigmoid、Tanh 激活函数
def init_weights(m):if type(m) == nn.Linear or type(m) == nn.Conv2d:nn.init.xavier_uniform_(m.weight) 对网络中每一层执行 init_weights
net.apply(init_weights) 将模型移到 GPU/CPU
print('training on', device)
net.to(device)创建SGD优化器(随机梯度下降)
net.parameters():
- 获取网络中所有可训练的参数(权重和偏置)
- 对于 LeNet,包括:2个卷积层的权重和偏置和3个全连接层的权重和偏置
lr=lr:
- 学习率(learning rate)
- 控制每次参数更新的步长
- 典型值:0.001 ~ 0.1
作用:
- 在训练过程中根据梯度更新参数
- 更新公式:参数 = 参数 - 学习率 × 梯度
optimizer = torch.optim.SGD(net.parameters(), lr=lr)定义损失函数(交叉熵损失函数(Cross Entropy Loss))
适用场景:
- 多分类任务(这里是 Fashion-MNIST 的 10 分类)
内部操作:
- 自动包含 Softmax + 负对数似然损失
- 输入:模型的原始输出(logits,未经 Softmax)
- 输出:标量损失值
数学公式:
为什么用交叉熵?
- 衡量预测概率分布与真实标签的差异
- 梯度特性好,训练稳定
loss = nn.CrossEntropyLoss()创建动画可视化器,设定x轴标签,x与y轴范围,画出三条曲线( 非Jupyter 环境中无法正常工作)
- 训练损失(train loss)
- 训练准确率(train acc)
- 测试准确率(test acc)
Animator:d2l 库提供的实时绘图工具
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0.3, 0.9],legend=['train loss', 'train acc', 'test acc'])创建训练计时器和获取批次数
timer, num_batches = d2l.Timer(), len(train_iter)神经网络标准训练循环,几乎所有神经网络训练都遵循这个模式,步骤包括以下部分
| 步骤 | 代码 | 作用 |
|---|---|---|
| 1. 清空梯度 | optimizer.zero_grad() | 避免梯度累加 |
| 2. 前向传播 | y_hat = net(X) | 计算预测值 |
| 3. 计算损失 | l = loss(y_hat, y) | 评估预测质量 |
| 4. 反向传播 | l.backward() | 计算梯度 |
| 5. 更新参数 | optimizer.step() | 根据梯度优化参数 |
| 6. 统计指标 | metric.add(...) | 累加损失和准确率 |
| 7. 可视化 | animator.add(...) | 实时绘制曲线 |
| 8. 评估 | evaluate_accuracy_gpu() | 测试集准确率 |
代码:
for epoch in range(num_epochs):metric = d2l.Accumulator(3)net.train()for i, (X,y) in enumerate(train_iter):timer.start()optimizer.zero_grad()X, y = X.to(device), y.to(device)y_hat = net(X)l = loss(y_hat, y)l.backward()optimizer.step()with torch.no_grad():metric.add(l * X.shape[0], d2l.accuracy(y_hat,y),X.shape[0]) timer.stop()train_l = metric[0] / metric[2]train_acc = metric[1] / metric[2]if(i+1) % (num_batches//5) == 0 or i == num_batches - 1:animator.add(epoch + (i+1) / num_batches,(train_l, train_acc, None))test_acc = evaluate_accuracy_gpu(net, test_iter)animator.add(epoch + 1, (None, None, test_acc))print(f'loss {train_l:.3f},train acc {train_acc:.3f},'f'test acc {test_acc:.3f}')print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec'f'on{str(device)}')训练和评估LeNet模型
设置学习率和训练轮数,调用定义的train_ch6()
lr, num_epochs = 0.9, 10
train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())结果:
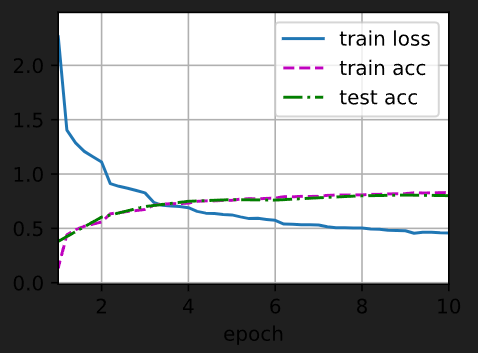
在Jupyter 环境中可视化表示:
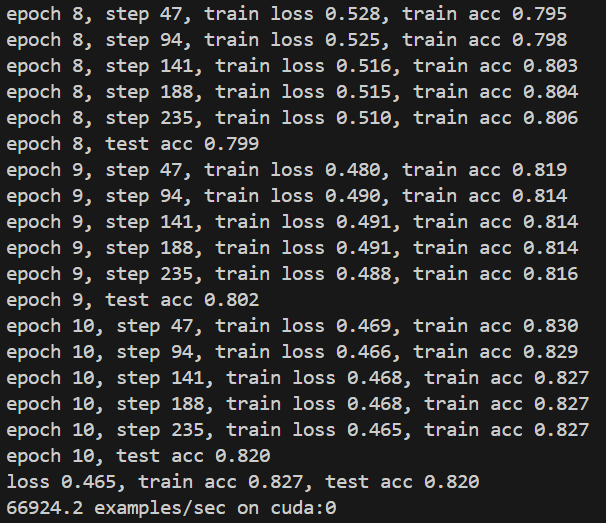
ide里终端输出:
完整代码
import torch
from torch import nn
from d2l import torch as d2lclass Reshape(torch.nn.Module):def forward(self, x):return x.view(-1, 1, 28, 28)net = nn.Sequential(Reshape(),nn.Conv2d(1, 6, kernel_size=5, padding=2),nn.Sigmoid(),nn.AvgPool2d(kernel_size=2, stride=2),nn.Conv2d(6, 16, kernel_size=5),nn.Sigmoid(),nn.AvgPool2d(kernel_size=2, stride=2),nn.Flatten(),nn.Linear(16 * 5 * 5, 120),nn.Sigmoid(),nn.Linear(120, 84),nn.Sigmoid(),nn.Linear(84, 10))def evaluate_accuracy_gpu(net, data_iter, device=None): if isinstance(net, torch.nn.Module):net.eval()if not device:device = next(iter(net.parameters())).devicemetric = d2l.Accumulator(2)for X, y in data_iter:if isinstance(X, list):X = [x.to(device) for x in X]else:X = X.to(device)y = y.to(device)metric.add(d2l.accuracy(net(X), y), y.numel())return metric[0] / metric[1]def train_ch6(net, train_iter, test_iter, num_epochs, lr, device):"""Train a model with CPU or GPU."""def init_weights(m):if type(m) == nn.Linear or type(m) == nn.Conv2d:nn.init.xavier_uniform_(m.weight)net.apply(init_weights)print('training on', device)net.to(device)optimizer = torch.optim.SGD(net.parameters(), lr=lr)loss = nn.CrossEntropyLoss()# animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0.3, 0.9],# legend=['train loss', 'train acc', 'test acc'])timer, num_batches = d2l.Timer(), len(train_iter)for epoch in range(num_epochs):metric = d2l.Accumulator(3)net.train()for i, (X, y) in enumerate(train_iter):timer.start()optimizer.zero_grad()X, y = X.to(device), y.to(device)y_hat = net(X)l = loss(y_hat, y)l.backward()optimizer.step()with torch.no_grad():metric.add(l * X.shape[0], d2l.accuracy(y_hat, y), X.shape[0])timer.stop()train_l = metric[0] / metric[2]train_acc = metric[1] / metric[2]if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
# animator.add(epoch + (i + 1) / num_batches, (train_l, train_acc, None))print(f'epoch {epoch + 1}, step {i + 1}, train loss {train_l:.3f}, train acc {train_acc:.3f}')test_acc = evaluate_accuracy_gpu(net, test_iter)print(f'epoch {epoch + 1}, test acc {test_acc:.3f}')
# animator.add(epoch + 1, (None, None, test_acc))print(f'loss {train_l:.3f}, train acc {train_acc:.3f}, test acc {test_acc:.3f}')print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec on {str(device)}')if __name__ == '__main__':# 测试网络结构x = torch.rand(1, 1, 28, 28, dtype=torch.float32)for layer in net:x = layer(x)print(layer.__class__.__name__,'output shape: \t', x.shape)# 加载数据batch_size = 256train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size=batch_size)# 开始训练lr, num_epochs = 0.9, 10train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())