yolo地裂缝(wsl+ubuntu)
yolov12:YOLOv12: 以注意力为中心的实时目标检测器 - GitCode --- yolov12:YOLOv12: Attention-Centric Real-Time Object Detectors - GitCode
一、环境
环境配置
YOLOv12保姆级教程(win系统和ubuntu系统均可使用)_yolov12代码-CSDN博客
git clone 代码
权重下载: 此处直接选择权重文件【YOLO12n】下载即可

wget https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.3/flash_attn-2.7.3+cu11torch2.2cxx11abiFALSE-cp311-cp311-linux_x86_64.whl
conda create -n yolov12 python=3.11
conda activate yolov12
在pycharm中添加解释器


pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
----------安装requirements.txt文件,后面加清华的镜像源效果更好。
pip install -e .
先检查下torch的版本以及cuda是否可用
搭建YOLOv8实现裂缝缺陷识别全流程教程:从源码下载到模型测试_python 3.12.3 yolo8-CSDN博客
根目录创建一个py文件,名为cuda检查.py,放置如下代码并且执行:
import torch
import numpy as np# 检查GPU、Cudaprint("numpy版本:"+np.__version__)
print("CUDA是否可用=>", torch.cuda.is_available())
print("pytorch版本=>"+torch.__version__)
print("是否支持CUDA=>"+str(torch.cuda.is_available()))
# 如果有 GPU 可用,打印 GPU 数量和名称
if torch.cuda.is_available():print("GPU设备数量=>", torch.cuda.device_count())print("当前使用GPU=>", torch.cuda.get_device_name(torch.cuda.current_device()))
else:print("没有GPU可用,当前将运行在CPU上")如果没问题,会显示如下

如果你的pytorch显示cpu版本的,且numpy提示报错了,看博客解决
二、数据集
【免费下载】 YOLO地面裂缝数据集-CSDN博客
搭建YOLOv8实现裂缝缺陷识别全流程教程:从源码下载到模型测试_python 3.12.3 yolo8-CSDN博客
我选择第二个链接的数据集,下载splitata,换成下图的结构
想将 project_old目录移动到 /home/username/workspace/目录下,并重命名为 project_new。
mv project_old /home/username/workspace/project_new

crack_segmentation.yaml

# 数据集路径
path: /home/qsl/3dgs-code/yolov12/splitData(3) # 数据集根目录
train: images/train # 训练集图像相对路径
val: images/val # 验证集图像相对路径
test: images/test # 测试集图像相对路径 (可选)# 类别信息
names:0: crack # 类别名称,索引从0开始
制作数据集
YOLOV9保姆级教程-CSDN博客
YOLOv5图像识别教程:成功识别桥墩缺陷详细步骤分享
三、运行
train.py
from ultralytics import YOLOif __name__ == '__main__':model = YOLO('/home/qsl/3dgs-code/yolov12/ultralytics/cfg/models/v12/yolov12n.yaml')# 代表使用yolov12n的神经网络结构model.load('/home/qsl/3dgs-code/yolov12/yolov12n.pt')# 代表使用yolov12n的预训练权重model.train(data='/home/qsl/3dgs-code/yolov12/splitData(3)/splitData/crack_segmentation.yaml', # 数据集yaml路径imgsz=640, # 输入图像的尺寸为 640x640 像素epochs=200, # 训练300轮batch=16, # 每一批样本的数量workers=8, # 同时32个线程device="0", #只使用第一张显卡进行训练project='/home/qsl/3dgs-code/yolov12/train',name='yolov12n',)python train.py ,运行了3小时,输出在 /home/qsl/3dgs-code/yolov12/train/yolov12n5
结果分析参考一条视频讲清楚yolo训练结果的含义 - Coding茶水间 - 博客园 - 愿你无忧yyyyyyy - 博客园


cmd打开终端,在终端输入nvidia-smi,回车执行命令就能看到GPU利用率66%:

如果电脑不太好的话,会出现GPU容量不足的情况,尽量调整数据输入量和线程,减少电脑负担,在train文件里调小workers、batch
报错Could not load library libcudnn_cnn_train.so.8
您遇到的错误,核心问题在于环境中的CUDA和cuDNN库版本存在冲突。从您提供的版本信息来看,PyTorch期望使用CUDA 12.1,但系统却错误地加载了来自CUDA 11.8路径下的旧版cuDNN库。
echo $LD_LIBRARY_PATH
echo $CUDA_HOME

- conda activate yolov12
- unset CUDA_HOME
- export LD_LIBRARY_PATH=
更稳妥的做法(每次激活环境自动生效)(可以试试):
- mkdir -p $CONDA_PREFIX/etc/conda/activate.d
- 创建文件 vim $CONDA_PREFIX/etc/conda/activate.d/cuda_clean.sh,内容:
- unset CUDA_HOME
- export LD_LIBRARY_PATH=
验证:
- python -c "import torch, os; print(torch.version, torch.version.cuda); print('CUDA_HOME=', os.environ.get('CUDA_HOME')); print('LD_LIBRARY_PATH=', os.environ.get('LD_LIBRARY_PATH'))"
predict.py
from ultralytics import YOLO
from PIL import Image
import cv2model = YOLO('train/yolov12n5/weights/best.pt')
results = model.predict(source='splitData(3)/images/test/1-59-_jpg.rf.88757267d8830b549d4b2eadb5febba9.jpg', save=True,save_txt=True, imgsz=640, conf=0.25)#单张图片,source也可以是文件夹# 结果可视化
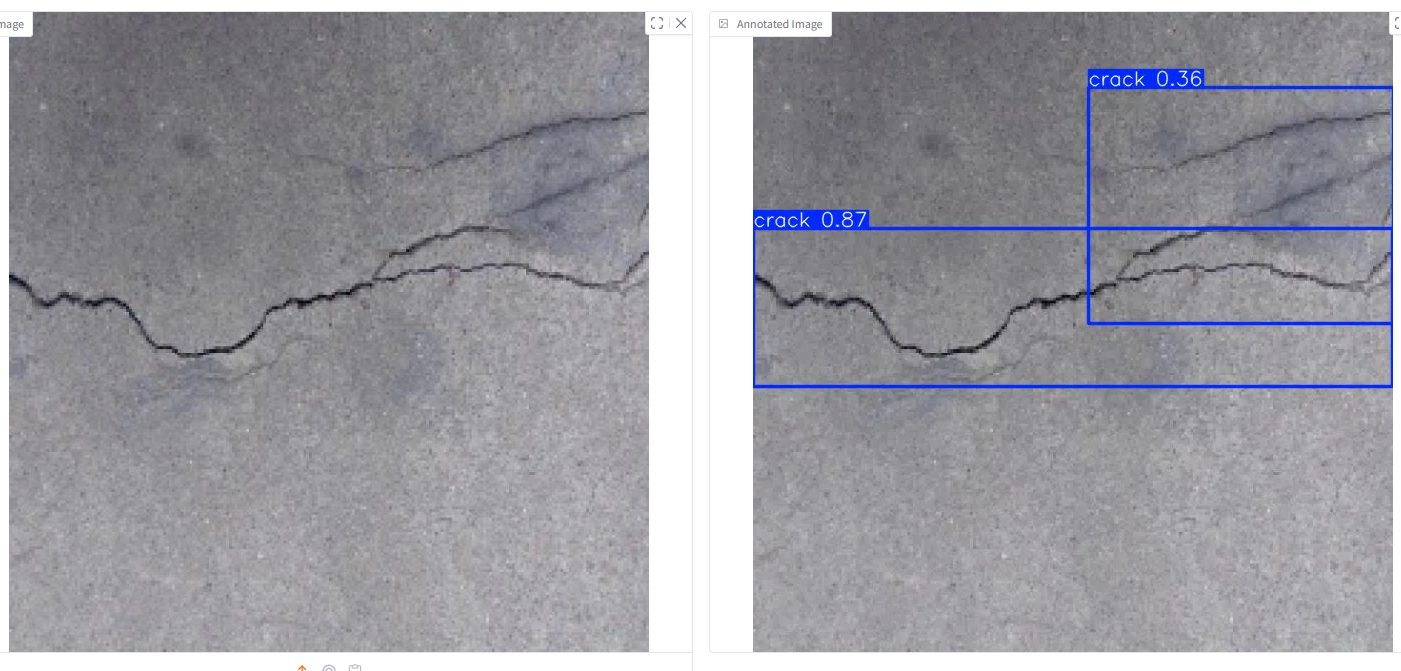
for r in results:# 方法1: 使用Ultralytics内置的plot方法 (快速显示)im_array = r.plot() # 绘制边界框、分割掩码、标签im = Image.fromarray(im_array[..., ::-1]) # BGR to RGBcv2.imshow('result', im_array) # 显示图像# 等待按键,0表示无限等待直到按键key = cv2.waitKey(0) # 程序会停在这里等待用户按键# 关闭所有OpenCV窗口cv2.destroyAllWindows()控制台提示识别的结果在runs\detect\predict目录下,发现图中出现多个裂缝时不能准确识别

【图像算法 - 14】精准识别路面墙体裂缝:基于YOLO12与OpenCV的实例分割智能检测实战(附完整代码)_crack500数据集宽度测量-CSDN博客
app.py
可选多种模型,但是这是没有经过裂缝数据集训练的权重,直接传入图片的话,输出的图片并不会标注,所以经过修改app.py做了一个可以上传pt权重文件的程序,代码如下demo.py:
demo.py(可上传pt权重文件)
# --------------------------------------------------------
# Based on yolov10
# https://github.com/THU-MIG/yolov10/app.py
# --------------------------------------------------------'import gradio as gr
import cv2
import tempfile
from ultralytics import YOLOdef yolov12_inference(image, video, model_path, image_size, conf_threshold):print("model_path: ", model_path)model = YOLO(model_path)if image:results = model.predict(source=image, imgsz=image_size, conf=conf_threshold)annotated_image = results[0].plot()return annotated_image[:, :, ::-1], Noneelse:video_path = tempfile.mktemp(suffix=".webm")with open(video_path, "wb") as f:with open(video, "rb") as g:f.write(g.read())cap = cv2.VideoCapture(video_path)fps = cap.get(cv2.CAP_PROP_FPS)frame_width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))frame_height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))output_video_path = tempfile.mktemp(suffix=".webm")out = cv2.VideoWriter(output_video_path, cv2.VideoWriter_fourcc(*'vp80'), fps, (frame_width, frame_height))while cap.isOpened():ret, frame = cap.read()if not ret:breakresults = model.predict(source=frame, imgsz=image_size, conf=conf_threshold)annotated_frame = results[0].plot()out.write(annotated_frame)cap.release()out.release()return None, output_video_pathdef yolov12_inference_for_examples(image, model_path, image_size, conf_threshold):annotated_image, _ = yolov12_inference(image, None, model_path, image_size, conf_threshold)return annotated_imagedef app():with gr.Blocks():with gr.Row():with gr.Column():image = gr.Image(type="pil", label="Image", visible=True)video = gr.Video(label="Video", visible=False)input_type = gr.Radio(choices=["Image", "Video"],value="Image",label="Input Type",)model_file = gr.File(label="Upload Model (.pt file)", file_types=[".pt"])image_size = gr.Slider(label="Image Size",minimum=320,maximum=1280,step=32,value=640,)conf_threshold = gr.Slider(label="Confidence Threshold",minimum=0.0,maximum=1.0,step=0.05,value=0.25,)yolov12_infer = gr.Button(value="Detect Objects")with gr.Column():output_image = gr.Image(type="numpy", label="Annotated Image", visible=True)output_video = gr.Video(label="Annotated Video", visible=False)def update_visibility(input_type):image = gr.update(visible=True) if input_type == "Image" else gr.update(visible=False)video = gr.update(visible=False) if input_type == "Image" else gr.update(visible=True)output_image = gr.update(visible=True) if input_type == "Image" else gr.update(visible=False)output_video = gr.update(visible=False) if input_type == "Image" else gr.update(visible=True)return image, video, output_image, output_videoinput_type.change(fn=update_visibility,inputs=[input_type],outputs=[image, video, output_image, output_video],)def run_inference(image, video, model_file, image_size, conf_threshold, input_type):if input_type == "Image":return yolov12_inference(image, None, model_file, image_size, conf_threshold)else:return yolov12_inference(None, video, model_file, image_size, conf_threshold)yolov12_infer.click(fn=run_inference,inputs=[image, video, model_file, image_size, conf_threshold, input_type],outputs=[output_image, output_video],)# gr.Examples(# examples=[# [# "ultralytics/assets/bus.jpg",# "yolov12s.pt",# 640,# 0.25,# ],# [# "ultralytics/assets/zidane.jpg",# "yolov12x.pt",# 640,# 0.25,# ],# ],# fn=yolov12_inference_for_examples,# inputs=[# image,# model_id,# image_size,# conf_threshold,# ],# outputs=[output_image],# cache_examples='lazy',# )gradio_app = gr.Blocks()
with gradio_app:gr.HTML("""<h1 style='text-align: center'>YOLOv12: Attention-Centric Real-Time Object Detectors</h1>""")gr.HTML("""<h3 style='text-align: center'><a href='https://arxiv.org/abs/2502.12524' target='_blank'>arXiv</a> | <a href='https://github.com/sunsmarterjie/yolov12' target='_blank'>github</a></h3>""")with gr.Row():with gr.Column():app()
if __name__ == '__main__':gradio_app.launch()
四、autodl部署
可尝试参考
YOLOv12快速复现部署&训练测试 - 知乎
01 YOLOv12快速复现部署&训练测试_哔哩哔哩_bilibili