全参数DeepSeek(671B)企业部署方案
1.1 项目背景
甲方需求开发一个ChatBI智能体,需要模型有Text2SQL的能力,经测试,DeepSeek-V3版本的代码能力超越GPT-4o,故需要本地部署DeepSeek全参数版大模型。
1.2 部署方案
1.2.1 方案选择
采用DeepSeek-v3+vLLM方案
1.2.2 资源评估
由于DeepSeek的框架原生采用 FP8 训练,因此仅提供 FP8 权重,预估仅700GB+显存便可轻松运行。当然也可以转换到BF16,在半精度下,需1400GB+,而量化到int4时需要450GB+。以下是半精度下显存占用情况:(占用 490G 显存,需要 7张 80G A100,租赁成本约1000元1天)
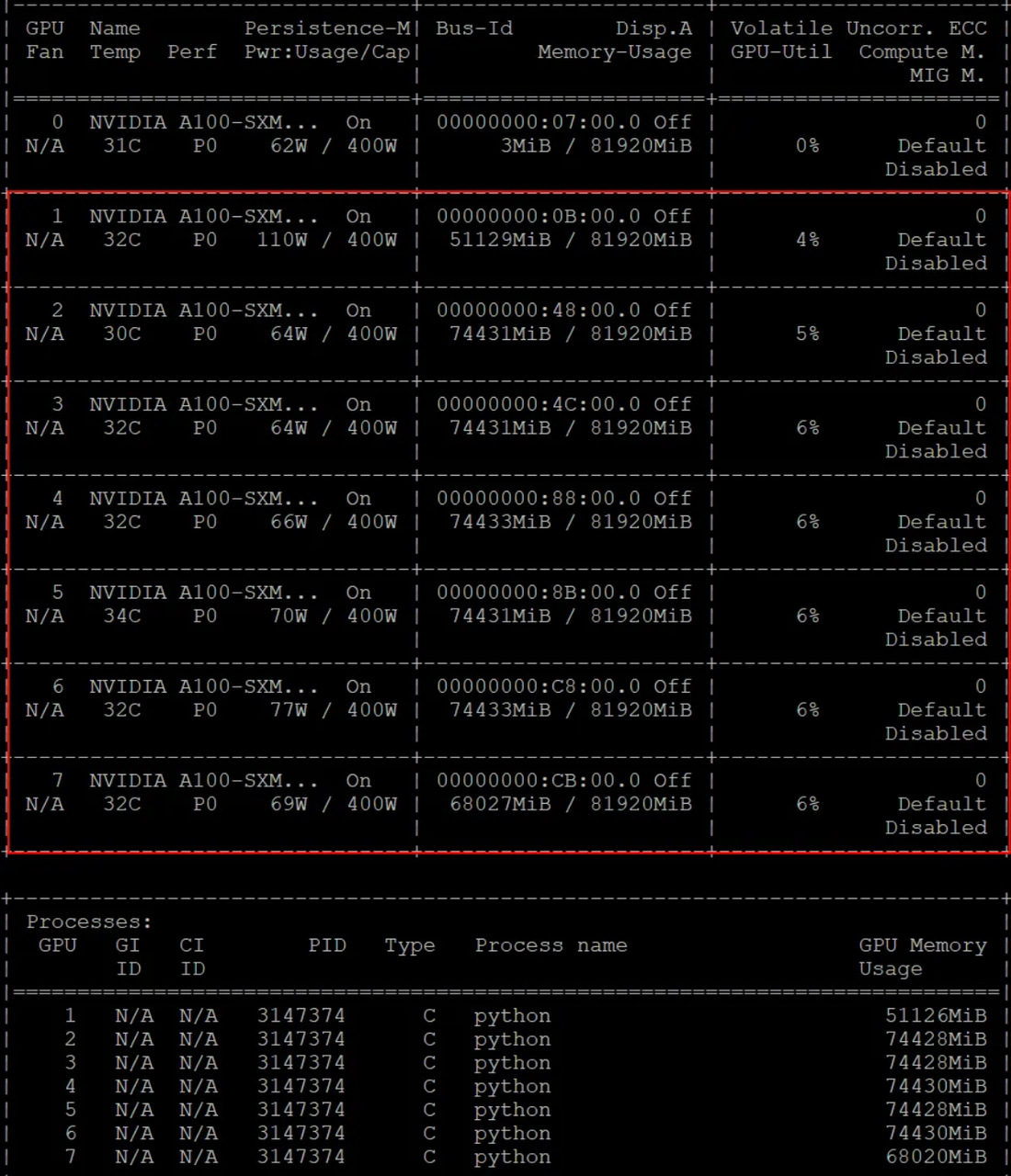
1.2.3 服务器准备
- 服务器硬件配置如下:
-
- GPU:Nvidia A100(80G) GPU * 8
- CPU:AMD EPYC 9K84 96-Core
- 桥接方式:NVLink(桥接)
- 内存:150G
- 存储:2T
- 深度学习环境配置如下:
-
- 操作系统:Ubuntu22.04
- PyTorch版本:2.5.1
- Python版本:3.12
- CUDA版本:12.4
- 其他软件包版本根据DeepSeek v3项目requirement决定。
(https://github.com/deepseek-ai/DeepSeek-V3)
- 多服务器部署方案(DeepSeek-V3+vLLM+RAY)
如果需要部署的是fp8,或者其它的量化版本,一台服务器就不够了。这个时候需要,Ray+vLLM进行部署

地址:https://github.com/ray-project/ray
2.3 部署流程
2.3.1 下载权重文件
到魔搭社区下载:https://www.modelscope.cn/
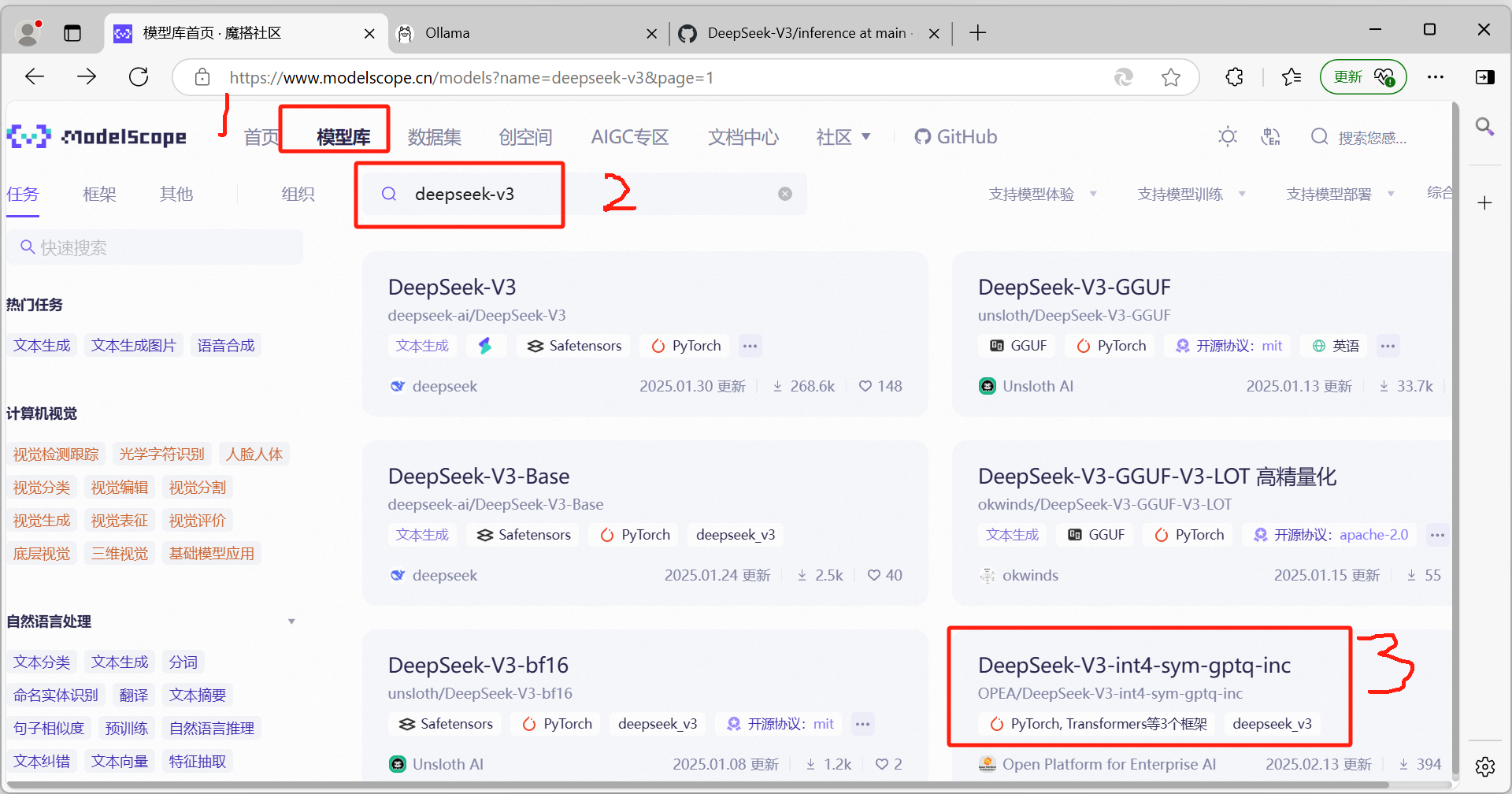
注,下载前需提前留出600G左右存储空间,用于保存模型权重
在服务器上安装依赖,用于下载模型权重文件
pip install modelscope执行命令,进行权重文件下载
mkdir ./deepseek
modelscope download --model OPEA/DeepSeek-V3-int4-sym-gptq-inc --local_dir ./deepseek需要经过漫长的等待,才能下载完!
2.3.2 代码访问
import torch
from modelscope import AutoTokenizer, AutoModelForCausalLM, GenerationConfig
model_name = "./deepseek"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.bfloat16, device_map="auto")
model.generation_config = GenerationConfig.from_pretrained(model_name)
model.generation_config.pad_token_id = model.generation_config.eos_token_idmessages = [{"role": "user", "content": "你好,请介绍下你自己!"}
]input_tensor = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt")
outputs = model.generate(input_tensor.to(model.device), max_new_tokens=100)
result = tokenizer.decode(outputs[0][input_tensor.shape[1]:], skip_special_tokens=True)
print(result)2.3.3 vLLm部署

地址:https://github.com/vllm-project/vllm
vLLM v0.6.6 支持在 NVIDIA 和 AMD GPU 上以 FP8 和 BF16 模式进行 DeepSeek-V3 推理。除了标准技术外,vLLM 还提供了管道并行性,允许你在
学习更多 AI 大模型大模型全栈技术 https://www.yuque.com/lhyyh/ai