DMA 实践拾遗
1、简介
最近在学习 ARM 的 AMBA 总线架构时,补上了过去对 DMA 传输机制的一些理解空白。借此机会,把这部分内容做一个简单的整理与记录,算是学习笔记,也方便后续查阅。
ARM 总线技术 —— AHB
block DMA & scatter-gather DMA
2、DMA Diagram
芯片手册中,DMA 章节中的 Block Diagram,会详细的告诉我们,DMA 在整个 SOC 中所处的位置,这很重要!
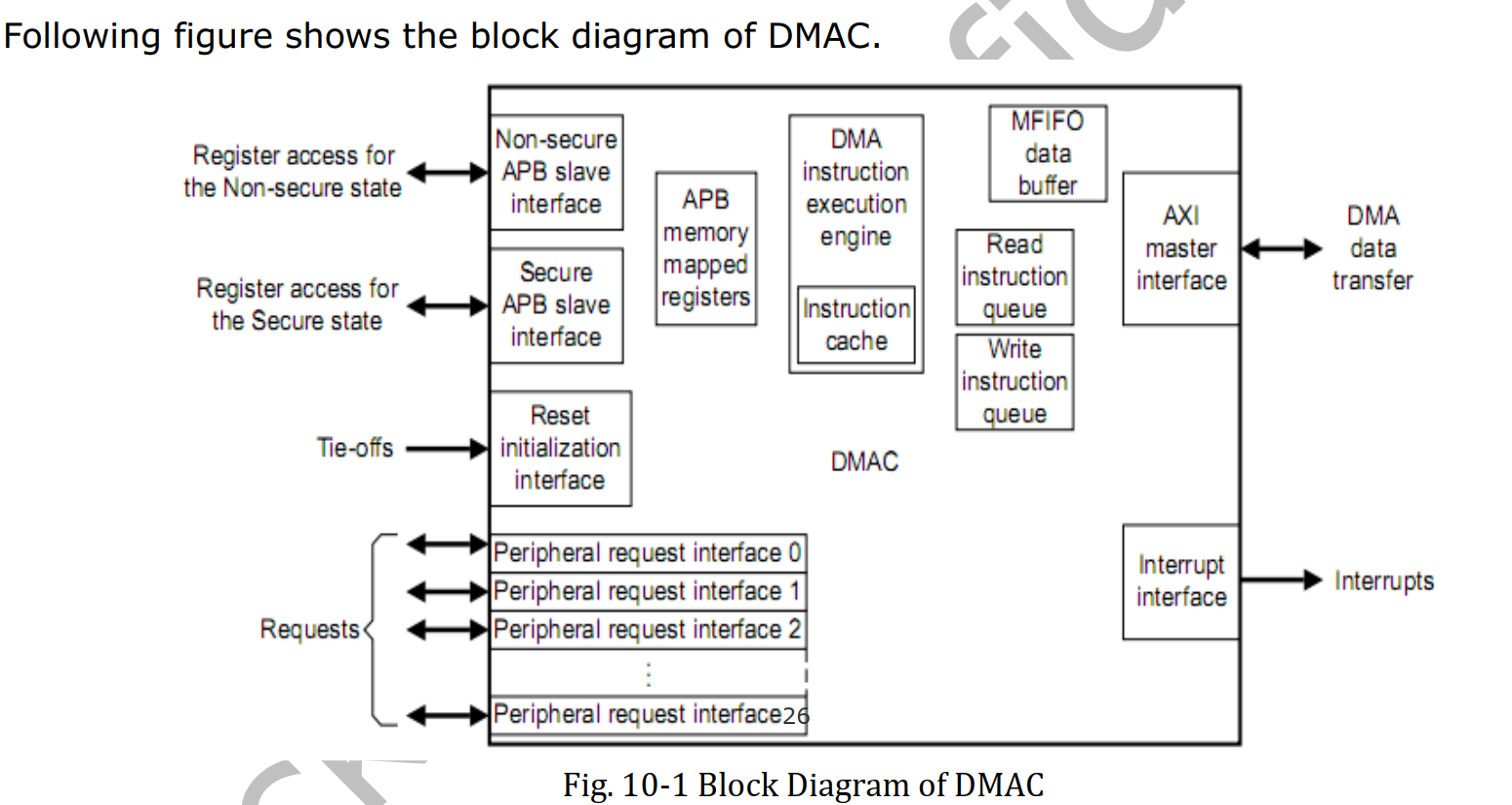
| 接口 | 功能 |
|---|---|
| APB Slave | 提供 DMA 控制寄存器的访问路径 |
| AXI Master | DMA 自己发起对内存或外设的读写传输 |
| Request | 外设向 DMA 控制器提出的要进行 DMA 操作的申请信号 |
以上只是一个示例。实际上,不同的 DMA 控制器,其 Master 和 Slave 接口可能都连接在 AHB 总线上。DMA 在 SoC 中所处的位置决定了它的性能上限,因为其配置能力受限于所连接总线协议所支持的最大规格。
3、DMA burst
当 DMA 发起 burst 传输时,DMA 作为总线的 Master 设备,控制该总线。对于软件开发人员来说,需要配置 burst 传输的相关参数。
struct dma_slave_config {......phys_addr_t src_addr;phys_addr_t dst_addr;enum dma_slave_buswidth src_addr_width;enum dma_slave_buswidth dst_addr_width;u32 src_maxburst;u32 dst_maxburst;......
}
- src_addr:源地址
- src_addr_width:源数据宽度,byte 整数倍(可以理解为 AHB 总线中的 beat,由 HBURST[2:0] 信号决定)
- src_maxburst:源突发长度,一共传输多少个 src_addr_width(可以理解为 AHB 总线中的 burst size,由 HSIZE[2:0] 信号决定)
src_addr_width、src_maxburst 等这些参数,决定着 DMA 控制器搬运数据的过程。
当我们在使用 DMA,进行内存与外设之间的数据搬运时, src_addr_width 的值不是随便设置的,而是要依赖设备的外设寄存器访问位宽。我们下面举几个例子:
UART 控制器:
![[图片]](https://i-blog.csdnimg.cn/direct/292fb1fa775b4c7c9e830358bf7bc962.png)

我们可以看到,串口的 RX Buffer Register 和 TX Buffer Register 都是 8 bit。其 “寄存器访问位宽” 为 1。我们在使用 DMA 搬运数据到该寄存器时,src_addr_width 大小只能为 1 字节。如果设置为其他大小,数据传输会出错。
drivers\tty\serial\8250\8250_dma.c
int serial8250_request_dma(struct uart_8250_port *p)
{....../* Default slave configuration parameters */dma->rxconf.direction = DMA_DEV_TO_MEM;dma->rxconf.src_addr_width = DMA_SLAVE_BUSWIDTH_1_BYTE;......
}
I2C 控制器:
![[图片]](https://i-blog.csdnimg.cn/direct/368b72157b6e47c8be39982e84ef557c.png)
同样的,I2C 的 RX Buffer Register 和 TX Buffer Register 都是 8 bit。所以其 “寄存器访问位宽” 为 1。我们在使用 DMA 搬运数据到该寄存器时,src_addr_width 大小只能为 1 字节。如果设置为其他大小,数据传输会出错。
drivers\twi\twi-sunxi.c
static int sunxi_twi_dma_init(struct sunxi_twi *twi, struct sunxi_twi_dma **_info, bool read)
{struct dma_slave_config dma_sconfig;......dma_sconfig.src_addr_width = DMA_SLAVE_BUSWIDTH_1_BYTE;dma_sconfig.dst_addr_width = DMA_SLAVE_BUSWIDTH_1_BYTE;dma_sconfig.src_maxburst = 16;dma_sconfig.dst_maxburst = 16;
}
SPI 控制器:
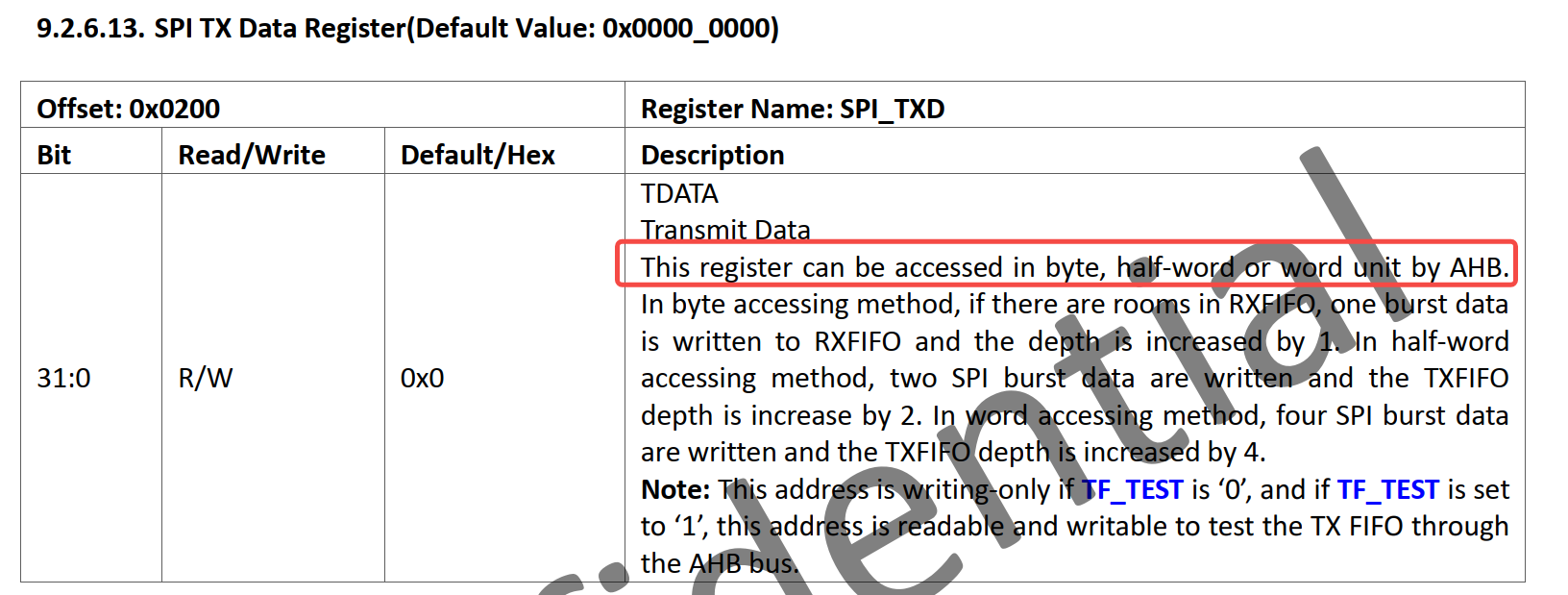
SPI 控制器有一些特殊。从协议上来看,SPI 实际上是没有帧和包的概念的。所以 SPI 的 “寄存器访问位宽” 可能不是固定的。从芯片手册中就可以看出,如上,SPI 控制器的 RX/TX Data Register 支持 1 字节、2 字节、4 字节的 “寄存器访问位宽” 。所以,如果使用 DMA 的话,src_addr_width 大小可以为 1 字节、2 字节、4 字节,选一个更能优化性能的即可。
drivers\spi-ng\spi-sunxi.c
static void sunxi_spi_config_dma(struct dma_slave_config *config, int len, u32 triglevel, bool dma_force_fixed)
{int width, burst;if (dma_force_fixed) {/* if dma is force fixed, use old configuration to make sure the stability and compatibility */if (len % DMA_SLAVE_BUSWIDTH_4_BYTES == 0)width = DMA_SLAVE_BUSWIDTH_4_BYTES;elsewidth = DMA_SLAVE_BUSWIDTH_1_BYTE;burst = 4;} else {if (len % DMA_SLAVE_BUSWIDTH_4_BYTES == 0) {width = DMA_SLAVE_BUSWIDTH_4_BYTES;if (triglevel < SUNXI_SPI_FIFO_DEFAULT)burst = 8;elseburst = 16;} else if (len % DMA_SLAVE_BUSWIDTH_2_BYTES == 0) {width = DMA_SLAVE_BUSWIDTH_2_BYTES;burst = 16;} else {width = DMA_SLAVE_BUSWIDTH_1_BYTE;burst = 16;}}config->src_addr_width = width;config->dst_addr_width = width;config->src_maxburst = burst;config->dst_maxburst = burst;
}
注意,有一些特殊的 SPI 控制器,其 “寄存器访问位宽” 是需要通过寄存器去配置的。
![[图片]](https://i-blog.csdnimg.cn/direct/581adfa741d74cb19652ee74db0af903.png#pic_center)
static int rockchip_spi_transfer_one(struct spi_controller *ctlr,struct spi_device *spi,struct spi_transfer *xfer)
{......rs->n_bytes = xfer->bits_per_word <= 8 ? 1 : 2;......
}static int rockchip_spi_prepare_dma(struct rockchip_spi *rs,struct spi_controller *ctlr, struct spi_transfer *xfer)
{......struct dma_slave_config rxconf = {.direction = DMA_DEV_TO_MEM,.src_addr = rs->dma_addr_rx,.src_addr_width = rs->n_bytes,.src_maxburst = rockchip_spi_calc_burst_size(xfer->len / rs->n_bytes),};......
}
Linux 中也提供了一个接口,用来向底层驱动传递 “寄存器访问位宽”。
struct spi_transfer {......u8 bits_per_word;......
}
4、DMA DRQ
在 DMA 传输中,CPU 只负责发起 DMA 配置和启动命令,而并不知道当前是否满足实际的数据传输条件——例如,源设备是否已有可读数据,或目标设备的 FIFO 是否空闲可写。这些状态只有具体的外设本身才知道。
因此,系统需要一种机制,让外设在“具备传输条件”时主动通知 DMA 控制器。这就是 DMA Request(DRQ)信号 的作用。外设通过硬件线路(DRQ 线)向 DMA 控制器发出请求,表示“我现在可以进行一次 DMA 传输”。
💡 重点:DMA 传输并非由 CPU 发起,而是由外设触发。CPU 只负责配置一次传输的参数。

在外设控制器中,通常可以通过寄存器来开启或关闭 DRQ 的产生。例如:


- 在使用 DMA 模式时,驱动会使能 TX_DRQ / RX_DRQ;
- 在使用 CPU 轮询或中断模式时,则会关闭这些 DRQ 信号,避免无效触发。需要注意的是,DRQ 的触发时机并不是固定的。它完全取决于外设的硬件设计与内部缓冲结构。例如:
- 对于某些 SPI 控制器,当发送寄存器为空时产生 TX DRQ;
- 对于带 FIFO 的控制器,可能在 FIFO 半空或达到设定阈值时才产生 DRQ。
因此,DRQ 的触发条件必须结合具体外设手册来确定,不同外设或不同芯片的实现可能各不相同。
4.1 一个简单的 DMA 传输案例

4.2 DMA 的传输通道
DMA 控制器可以同时进行的传输个数是有限的,每一个传输都需要使用到 DMA 物理通道。DMA 物理通道的数量决定了 DMA 控制器能够同时传输的任务量。
每个通道都有自己独立的描述符、控制寄存器和状态寄存器等。以 SPI 驱动为例,rx 和 tx 各占用一个 DMA 通道。
![[图片]](https://i-blog.csdnimg.cn/direct/9fc9c992281b480b93ed89ade691a67c.png#pic_center)
DMA 通道根据描述符中的 DRQ type 以及数据方向(memory -> device or device -> memory),去监听 RX/TX FIFO DMA Request。当接收到信号后,执行描述符中的源地址、目的地址之间的数据搬运。
5、Linux 下的 dma 传输相关函数
首先了解一下,对于 scatter-gather DMA 来说,中断模式可能有多种,具体由 DMA 控制器决定。以全志 T3 为例:
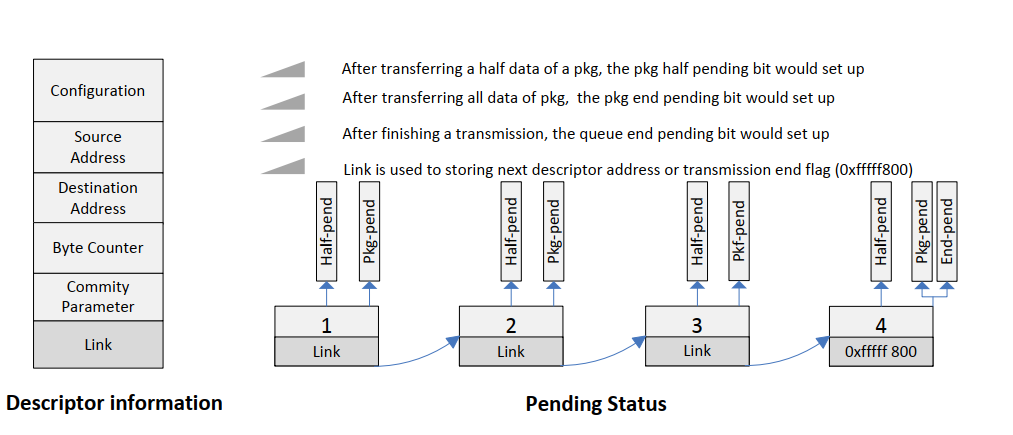
- Half package interrupt: 每传输半个 package,产生一次中断
- Package end interrupt:每个 package 传输完毕,产生一个中断
- Queue end interrupt:一个由 package 组成的队列,全部传输完毕,产生一个中断
Linux DMA 驱动中,常见的几个传输相关函数有:
pl330_probe(struct amba_device *adev, const struct amba_id *id)
{
......struct dma_device *pd;
.....pd->device_prep_dma_memcpy = pl330_prep_dma_memcpy;pd->device_prep_dma_cyclic = pl330_prep_dma_cyclic;pd->device_prep_slave_sg = pl330_prep_slave_sg;
......
}
struct dma_device {
......struct dma_async_tx_descriptor *(*device_prep_dma_memcpy)(struct dma_chan *chan, dma_addr_t dst, dma_addr_t src,size_t len, unsigned long flags);
......struct dma_async_tx_descriptor *(*device_prep_slave_sg)(struct dma_chan *chan, struct scatterlist *sgl,unsigned int sg_len, enum dma_transfer_direction direction,unsigned long flags, void *context);struct dma_async_tx_descriptor *(*device_prep_dma_cyclic)(struct dma_chan *chan, dma_addr_t buf_addr, size_t buf_len,size_t period_len, enum dma_transfer_direction direction,unsigned long flags);
......
}
- device_prep_dma_memcpy:用来实现 内存 -> 内存 传输
- 单一连续缓冲
- 该函数入参为源地址、目的地址、传输长度等
- device_prep_slave_sg:用来实现 内存 -> 设备、设备 -> 内存 传输、内存 -> 内存传输
- SG 列表(分散缓冲)
- 该函数入参是一个 scatterlist 链表,链表成员为一个 dma 传输的描述符。根据 DMA 硬件是否支持 scatter-gather,该函数实现不同(关于 scatter-gather, block DMA & scatter-gather DMA 文章中有详细讲解)
- device_prep_dma_cyclic:常见是 内存 -> 设备、设备 -> 内存
- 环形缓冲
- 在 I2S、音频、视频等连续数据流场景用的比较多
我们这里主要关心 device_prep_dma_cyclic 环形缓冲是什么意思呢?

device_prep_dma_cyclic 环形缓冲,通常会设置 DMA 的中断模式为 Package end interrupt。
我们以 I2S 音频驱动为例,对比使用环形缓冲区的好处。

device_prep_dma_cyclic 的最大价值,不是“可以传输”, 而是“可以连续传输 + 周期中断 + 无缝循环”。它的设计目标是:
- 保证数据流连续性
- 降低 CPU 负担(初始化一次,后台自动循环)
- 方便实时数据同步(周期中断通知)