从正确到卓越:昇腾CANN算子开发高级性能优化指南
前言
成功编写并验证一个功能正确的CANN算子,是踏入AI底层开发世界的重要一步。然而,这仅仅是旅程的开始。在商业部署和前沿研究中,算子的性能往往比功能正确性本身更具决定性。一个未经优化的算子,可能会成为整个神经网络的性能瓶瓶颈,浪费宝贵的计算资源;而一个经过精雕细琢的高性能算子,则能将昇腾NPU的潜力发挥到极致。
本文是一篇面向进阶开发者的性能优化指南。我们将超越“三段式流水线”的基础,深入探讨一系列高级优化技术。本文的核心思想是:优化并非凭空猜测,而是一门由数据驱动、基于硬件深刻理解的系统工程。 我们将学习如何使用性能分析工具(Profiler)来定位瓶颈,并针对性地应用双缓冲(Double Buffering)、数据重排与向量化、指令级并行等关键技术,将你的算子性能推向新的高度。
第一章:优化的第一性原理 —— Profiling驱动的决策
在修改任何一行代码以“优化”性能之前,必须牢记黄金法则:没有测量,就没有优化(No Measurement, No Optimization)。 任何未经性能数据验证的优化,都可能只是徒劳甚至起反作用的“微观骚扰”。
1.1 Ascend Profiler:你的性能“CT扫描仪”
CANN生态提供了强大的性能分析工具——Ascend Profiler。它是你的眼睛,能让你穿透软件的表象,直视硬件执行的每一个细节。在你开始优化之前,必须先对你“功能正确但未经优化”的算子版本进行一次完整的Profiling。
1.2 如何解读Profiler报告?
Profiler会生成一份详细的报告,你需要重点关注以下几个部分:
-
Timeline(时间线视图): 这是最直观的视图。它会展示Host(CPU)和Device(NPU)上所有任务的时间序列。你可以清晰地看到:
- Kernel执行时间: 你的核函数到底跑了多久?
- DMA传输时间: 数据在Global Memory和Local Memory之间的搬运耗时多少?
- 空闲间隙(Gaps): AI Core是否在某些时间段处于“空闲”状态?这些空闲,往往就是我们最大的优化空间。
-
硬件性能计数器(Hardware Counters): Profiler能提供AI Core底层的硬件指标,例如:
- AI Core Utilization: AI Core的计算单元在执行期间的繁忙程度。如果这个值很低,通常意味着它在等待数据,即你的算子是访存受限(Memory-bound)。
- Memory Bandwidth: 内存带宽的实际使用率。如果带宽已经接近饱和,而AI Core利用率仍不高,说明你的数据搬运效率可能存在问题。
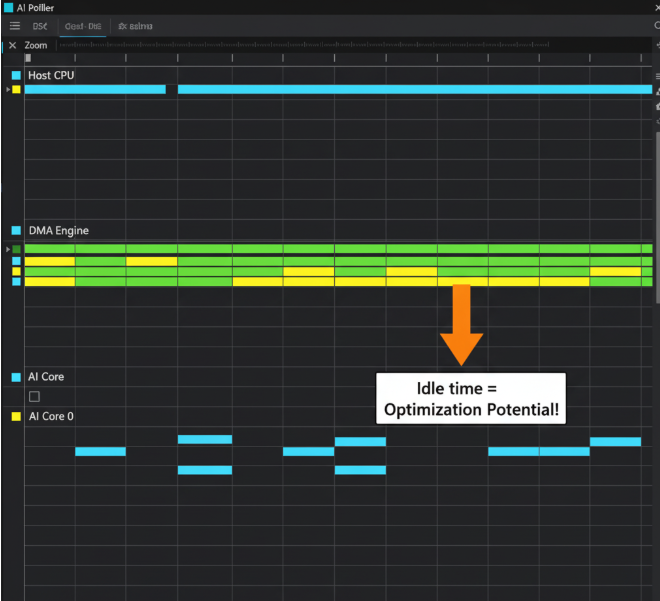
1.3 确定瓶颈:访存受限 vs. 计算受限
通过解读报告,你可以对你的算子进行初步诊断:
- 访存受限 (Memory-bound): Timeline上DMA传输时间占比很高,或者AI Core存在大量空闲间隙,且利用率低下。这说明算子的瓶颈在于数据供应跟不上计算的速度。这是绝大多数算子初始版本的状态。
- 计算受限 (Compute-bound): AI Core利用率非常高(接近100%),几乎没有空闲。这说明数据供应充足,算子的性能已经达到了当前计算逻辑的极限。
我们的优化之旅,通常是从解决“访存受限”问题开始的。
第二章:征服内存墙:高级数据搬运技术
如何填补AI Core的空闲间隙?答案是让数据搬运和计算并行起来。
2.1 双缓冲(Double Buffering):实现计算与访存的流水线并行
标准的“三段式”流水线是串行的:CopyIn -> Compute -> CopyOut。这意味着在CopyIn和CopyOut期间,AI Core是空闲的。双缓冲技术正是为了打破这种串行依赖。
核心思想: 在Local Memory中开辟两套缓冲区(例如buffer_A和buffer_B),让它们像乒乓球一样交替工作。
代码逻辑演进:
// --- 单缓冲 (Single Buffering) 代码 ---
class KernelSingleBuffer {__aicore__ inline void Process() {// ...for (int i = 0; i < loopCount; ++i) {// 串行执行:CopyIn_to_LocalBuffer(i); // AI Core等待Compute_on_LocalBuffer(); // DMA等待CopyOut_from_LocalBuffer(i); // AI Core等待}}
};// --- 双缓冲 (Double Buffering) 伪代码 ---
class KernelDoubleBuffer {__aicore__ inline void Init() {// 在Local Memory中声明两套缓冲区pipe.InitBuffer(buffer_A, ...);pipe.InitBuffer(buffer_B, ...);}__aicore__ inline void Process() {// ...// 1. 流水线启动:预取第一块数据到ACopyIn_to_BufferA(0);// 2. 主循环for (int i = 0; i < loopCount - 1; ++i) {// 在循环i,我们处理第i块数据,预取第i+1块if (i % 2 == 0) { // 使用A计算,预取到BCompute_on_BufferA();CopyIn_to_BufferB(i + 1);} else { // 使用B计算,预取到ACompute_on_BufferB();CopyIn_to_BufferA(i + 1);}}// 3. 流水线收尾:处理最后一块数据if ((loopCount - 1) % 2 == 0) {Compute_on_BufferA();} else {Compute_on_BufferB();}}
};
效果: 通过双缓冲,Compute操作和CopyIn操作可以在硬件层面并行执行(一个在AI Core,一个在DMA引擎),极大地隐藏了数据传输的延迟,从而填补了Timeline上的空闲间隙,提升AI Core利用率。
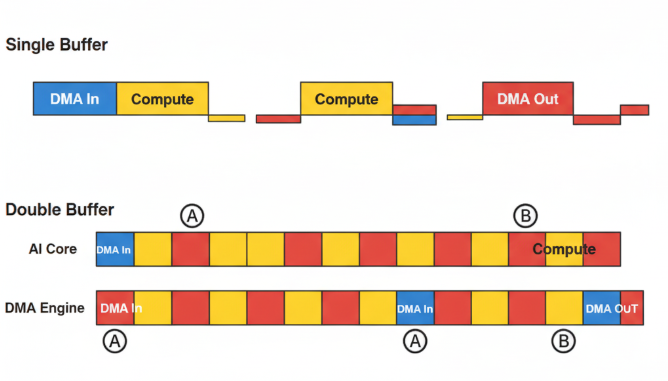
2.2 内存对齐与合并(Coalescing):提升DMA传输效率
DMA引擎传输数据时,并非一个字节一个字节地搬。它最高效的工作模式是一次性传输一块连续的、地址对齐的内存。
- 地址对齐: 如果你要搬运的数据块,其在Global Memory中的起始地址是硬件总线宽度(例如32字节)的整数倍,那么DMA的效率最高。
- 访问合并: 硬件会自动将多个小的、连续的内存访问请求,合并成一个大的、更高效的传输请求。
优化启示:
- 在进行Tiling设计时,
blockLength的选取,应尽量使其与数据类型大小的乘积是硬件对齐要求的整数倍(例如32字节)。 - 尽量避免对数据进行“跨步”(strided)的零散读取。如果算法必须进行跨步访问,可以考虑先用一个简单的核函数将非连续数据**重排(Re-layout)**成一块连续的临时内存,再由主计算核函数进行处理。这是一种“空间换时间”的优化。
第三章:释放计算潜能:核函数内的微观优化
当数据已经高效地载入Local Memory后,我们的焦点就转移到了Compute阶段本身。
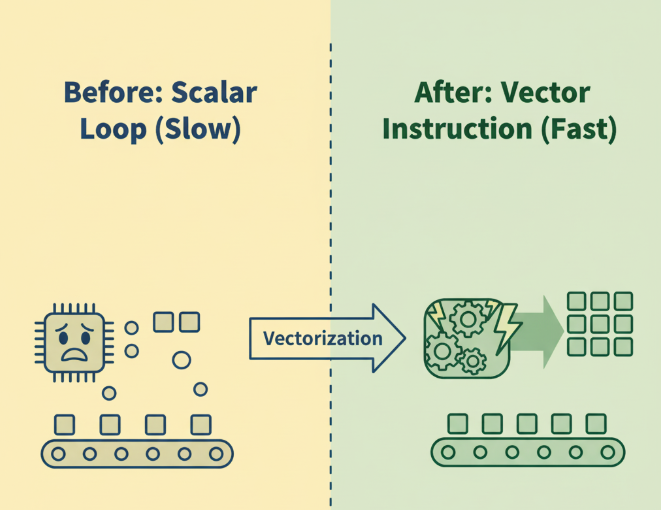
3.1 向量化(Vectorization):让单个指令干更多的活
AI Core内部的向量计算单元,可以在一个时钟周期内,对一整个向量(例如8个、16个float16数据)执行相同的操作。
- 反面教材(标量循环):
for (int i = 0; i < N; ++i) {y_local[i] = x_local[i] + bias; // 每次只算一个元素 } - 正面教材(向量指令):
// Ascend C提供了丰富的向量指令 Add(y_local, x_local, bias_broadcasted, N); // 一条指令完成整个向量的计算
优化启示: 充分利用Ascend C提供的向量化指令(Add, Mul, ReLU, Max等),避免手写标量循环。确保你的数据在Local Memory中是连续存放的,以便向量指令可以高效加载。
3.2 指令级并行(Instruction-Level Parallelism, ILP):榨干VLIW架构
Da Vinci架构是超长指令字(VLIW)架构,这意味着它的一个指令字可以同时包含标量、向量、立方单元的操作码。编译器会尽力将你的代码调度成可以并行的VLIW指令。
优化启示:
- 解开数据依赖: 编写独立的代码块,避免后一条指令的输入依赖于前一条指令的输出。这为编译器提供了更大的重排和并行化空间。
- 循环展开(Loop Unrolling): 对于循环次数不多但循环体简单的循环,可以手动展开。这减少了循环判断和跳转的开销,并增加了指令级并行的机会。
3.3 混合精度计算:速度与精度的平衡艺术
昇腾硬件对float16(半精度)的支持是原生的,其计算吞吐量通常是float32(单精度)的两倍。
- 优化启示: 在不影响模型最终精度的前提下,应优先使用
float16作为主要的计算和存储类型。对于需要更高精度的中间计算(如累加),可以使用float32进行,最后再转换回float16存储。这种混合精度的策略,是业界通用的性能优化方案。
结论:优化的迭代循环
高性能算子开发,是一个永无止境的迭代过程:
Profile -> Analyze Bottleneck -> Implement Optimization -> Re-profile
本文介绍的双缓冲、内存对齐、向量化等技术,是你工具箱中最强大的武器。但何时使用、如何组合使用这些武器,则需要你根据Profiler的精确“侦察报告”来决定。
从写出功能正确的代码,到创造出能将硬件性能压榨到极限的艺术品,这正是底层开发的魅力所在。这趟旅程,将磨练你作为工程师最宝贵的品质:对细节的极致追求,和对系统全局的深刻洞察。
开启你的“性能大师”之旅:
理论的深度需要反复的实践来巩固。2025年昇腾CANN训练营第二季的【码力全开特辑】和【开发者案例】正是你磨练这些高级优化技能的最佳战场。
- 系统化课程: 深入讲解复杂算子与性能调优。
- 免费云端环境: 在真实的昇腾硬件上,亲手实践并验证你的优化效果。
- 权威技能认证: Ascend C中级认证,是你掌握核心优化能力的有力证明。
- 丰富的实践激励: 完成任务更有机会赢取华为手机、平板、开发板等大奖。
如果你已不满足于“让它跑起来”,而是渴望“让它飞起来”,那么,是时候进入优化的深水区了。
报名链接: https://www.hiascend.com/developer/activities/cann20252